






一.EM简介
EM算法算是一种迭代算法,1977年由Dempster等人提出,主要用于含有隐变量(间接变量)的概率模型参数的极大似然估计,其中E —求解期望(Expectation);M—求解极大似然函数(Maximization).个人认为EM算法在分类,回归中有着相对于其他回归来说有着极大的优势,在训练数据只有输入没有输出的情况下,EM算法可以用于生成模型。
二.EM推导
我们的目标是极大化观测数据YYY 关于参数θ\thetaθ 的对数似然函数,即极大化
L(θ)=lnP(Y∣θ)=ln∑ZP(Y,Z∣θ)L\left ( \theta \right )=lnP\left ( Y|\theta \right )=ln\sum_{Z}P\left ( Y,Z | \theta \right )L(θ)=lnP(Y∣θ)=lnZ∑P(Y,Z∣θ)=ln∑ZP(Y,Z∣θ)P(Z∣θ)=ln\sum_{Z}P\left ( Y,Z | \theta \right )P\left ( Z|\theta \right )=lnZ∑P(Y,Z∣θ)P(Z∣θ)
我们可以观察到这里主要的苦难就是极大化中包含着求和的对数。
在另一个角度来说,EM算法实际上就是通过迭代逐渐接近极大化似然函数L(θ)L\left ( \theta \right )L(θ) ,换句话说,就是通过不断找取通过其似然函数的下界的函数,进而再求取极大似然,使其逐渐逼近于所求的似然函数的全局最大值。
即假设在第i次迭代后θ\thetaθ 的估计值为θ(i)\theta ^{\left (i \right )}θ(i) ,我们所找取得第i+1i+1i+1 次的θ(i+1)\theta ^{\left (i+1 \right )}θ(i+1) ,使得L(θ)L\left ( \theta \right )L(θ) 增加,即L(θ)>L(θ(i))L\left ( \theta \right )> L\left ( \theta ^{\left ( i \right )} \right )L(θ)>L(θ(i)) ,从而通过逐步迭代达到最大值。
因此可以巧妙的运用两者的差进而找出其似然函数。即:
L(θ)−L(θ(i))=ln{∑ZP(Y∣Z,θ)P(Z∣θ)}−lnP(y∣θ(i))L\left ( \theta \right )- L\left ( \theta ^{\left ( i \right )} \right )=ln\left \{ \sum_{Z}P\left ( Y|Z,\theta \right )P\left ( Z|\theta \right ) \right \}-lnP(y|\theta ^{(i)})L(θ)−L(θ(i))=ln{Z∑P(Y∣Z,θ)P(Z∣θ)}−lnP(y∣θ(i))用Jensen不等式可以得到其下界:
注:
∀x,yϵdomf,0≤θ≤1,\forall x,y\epsilon domf,0\leq \theta \leq 1,∀x,yϵdomf,0≤θ≤1, 有f(θx+(1−θ)y)≤θf(x)+(1−θ)f(y)f\left ( \theta x+\left ( 1-\theta \right )y \right )\leq \theta f(x)+\left ( 1-\theta \right )f\left ( y \right )f(θx+(1−θ)y)≤θf(x)+(1−θ)f(y) ;即咋严格意义上的凸函数的定义;在概率论中则可以表示为:f(E(X))≤E(f(X))f\left ( E\left ( X \right ) \right )\leq E\left ( f\left ( X \right ) \right )f(E(X))≤E(f(X)) .
因此,我们可以在此表示为:L(θ)−L(θ(i))=ln{∑ZP(Y∣Z,θ(i))P(Y∣Z,θ)P(Z∣θ)P(Y∣Z,θi)}−lnP(Y∣θi)L\left ( \theta \right )-L\left ( \theta ^{\left ( i \right )} \right )=ln\left \{ \sum_{Z}P\left ( Y|Z,\theta^{\left (i \right )} \right )\frac{P\left ( Y|Z,\theta \right )P\left ( Z|\theta \right )}{P\left ( Y|Z,\theta ^{i} \right )} \right \}-lnP\left ( Y|\theta ^{i} \right )L(θ)−L(θ(i))=ln{Z∑P(Y∣Z,θ(i))P(Y∣Z,θi)P(Y∣Z,θ)P(Z∣θ)}−lnP(Y∣θi)≥∑ZP(Z∣Y,θ(i))lnP(Y∣Z,θ)P(Z∣θ)P(Y∣Z,θ(i))−lnP(Y∣θi)\geq \sum_{Z}P\left ( Z|Y,\theta ^{\left ( i \right )} \right )ln\frac{P\left ( Y|Z,\theta \right )P\left ( Z|\theta \right )}{P\left ( Y|Z,\theta ^{\left ( i \right )} \right )}-lnP\left ( Y|\theta ^{i} \right )≥Z∑P(Z∣Y,θ(i))lnP(Y∣Z,θ(i))P(Y∣Z,θ)P(Z∣θ)−lnP(Y∣θi)=∑ZP(Z∣Y,θ(i))lnP(Y∣Z,θ)P(Z∣θ)P(Y∣Z,θ(i))P(Y∣θ(i))= \sum_{Z}P\left ( Z|Y,\theta ^{\left ( i \right )} \right )ln\frac{P\left ( Y|Z,\theta \right )P\left ( Z|\theta \right )}{P\left ( Y|Z,\theta ^{\left ( i \right )} \right )P\left ( Y|\theta ^{\left ( i \right )} \right )}=Z∑P(Z∣Y,θ(i))lnP(Y∣Z,θ(i))P(Y∣θ(i))P(Y∣Z,θ)P(Z∣θ)
假设令:B(θ,θ(i))=L(θ(i))+∑ZP(Z∣Y,θ(i))lnP(Y∣Z,θ)P(Z∣θ)P(Y∣Z,θ(i))P(Y∣θ(i))B\left ( \theta ,\theta ^{\left (i \right )} \right )= L\left ( \theta ^{\left ( i \right )} \right )+\sum_{Z}P\left ( Z|Y,\theta ^{\left ( i \right )} \right )ln\frac{P\left ( Y|Z,\theta \right )P\left ( Z|\theta \right )}{P\left ( Y|Z,\theta ^{\left ( i \right )} \right )P\left ( Y|\theta ^{\left ( i \right )} \right )}B(θ,θ(i))=L(θ(i))+∑ZP(Z∣Y,θ(i))lnP(Y∣Z,θ(i))P(Y∣θ(i))P(Y∣Z,θ)P(Z∣θ)
则:L(θ)≥B(θ,θi)L\left ( \theta \right )\geq B\left ( \theta ,\theta ^{i} \right )L(θ)≥B(θ,θi)
也就是说等价函数B(θ,θi)B\left ( \theta ,\theta ^{i} \right )B(θ,θi) 是L(θ)L\left ( \theta \right )L(θ) 的一个下界,而且又因为θ(i)\theta ^{\left ( i \right )}θ(i) 为第i次后迭代的估计值,故L(θ(i))=B(θ(i),θ(i))L\left (\theta ^{\left ( i \right )} \right )=B\left ( \theta^{\left ( i \right )} ,\theta ^{\left ( i \right )} \right )L(θ(i))=B(θ(i),θ(i))
因此,任何可以使得B(θ,θ(i))B\left ( \theta ,\theta ^{\left ( i \right )} \right )B(θ,θ(i)) 增大的θ\thetaθ ,也可以使得L(θ)L\left (\theta \right )L(θ)增大,为了是似然函数尽可能的增大,我们选择θ(i+1)\theta ^{\left ( i+1 \right )}θ(i+1) 使B(θ,θ(i))B\left ( \theta ,\theta ^{\left ( i \right )} \right )B(θ,θ(i)) 达到极大,即对:θ(i+1)=argmaθxB(θ,θ(i))\theta ^{\left ( i+1 \right )}=argma_{\theta }xB\left ( \theta ,\theta ^{\left ( i \right )} \right )θ(i+1)=argmaθxB(θ,θ(i))
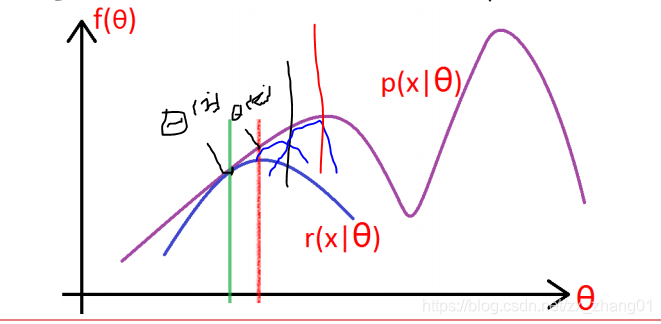
通过上图可看出,我们可已通过求取下界的极大似然函数无限的去逼近真是的似然函数的全局最大值。哈哈,是不是很完美的一个解释呢。
对 θ(i+1)\theta ^{\left ( i+1 \right )}θ(i+1) 求表达式,可以将常数项去掉,不会造成影响。因此可以进行下列转化:θ(i+1)=argmax{L(θ(i))+∑ZP(Z∣Y,θ(i))lnP(Y∣Z,θ)P(Z∣θ)P(Z∣Y,θ(i))P(Y∣θ(i))}\theta ^{\left ( i+1 \right )}=argmax\left \{ L\left ( \theta ^{\left ( i \right )} \right )+\sum_{Z}P\left ( Z|Y,\theta ^{\left ( i \right )} \right )ln\frac{P\left ( Y|Z,\theta \right )P\left ( Z|\theta \right )}{P\left ( Z|Y,\theta ^{\left ( i \right )} \right )P\left ( Y|\theta ^{\left ( i \right )} \right )}\right \}θ(i+1)=argmax{L(θ(i))+Z∑P(Z∣Y,θ(i))lnP(Z∣Y,θ(i))P(Y∣θ(i))P(Y∣Z,θ)P(Z∣θ)} =argmax{∑ZP(Z∣Y,θ(i))lnP(Y∣Z,θ)P(Z∣θ)P(Z∣Y,θ(i))P(Y∣θ(i))}=argmax\left \{ \sum_{Z}P\left ( Z|Y,\theta ^{\left ( i \right )} \right )ln\frac{P\left ( Y|Z,\theta \right )P\left ( Z|\theta \right )}{P\left ( Z|Y,\theta ^{\left ( i \right )} \right )P\left ( Y|\theta ^{\left ( i \right )} \right )}\right \}=argmax{Z∑P(Z∣Y,θ(i))lnP(Z∣Y,θ(i))P(Y∣θ(i))P(Y∣Z,θ)P(Z∣θ)} =argmax{∑ZP(Z∣Y,θ(i))lnP(Y∣Z,θ)P(Z∣θ)}=argmax\left \{ \sum_{Z}P\left ( Z|Y,\theta ^{\left ( i \right )} \right )ln{P\left ( Y|Z,\theta \right )P\left ( Z|\theta \right )}\right \}=argmax{Z∑P(Z∣Y,θ(i))lnP(Y∣Z,θ)P(Z∣θ)} =argmax{∑ZP(Z∣Y,θ(i))lnP(Y,Z∣θ)}=argmax\left \{ \sum_{Z}P\left ( Z|Y,\theta ^{\left ( i \right )} \right )ln{P\left ( Y,Z|\theta \right )}\right \}=argmax{Z∑P(Z∣Y,θ(i))lnP(Y,Z∣θ)}
由公式可看出:完全数据的极大似然函数P(Z∣Y,θ)P\left ( Z|Y,\theta \right )P(Z∣Y,θ)关于在给定观测数据Y和初始参数θ(i)\theta ^{\left ( i \right )}θ(i) 下对应的隐变量的条件概率分布P(Z∣Y,θ(i))P\left ( Z|Y,\theta ^{\left ( i \right )} \right )P(Z∣Y,θ(i)) 的期望即为所要求取的极大化的似然函数。

三.
上图为 小编的学习笔记,仅供参考。

















 3万+
3万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









