









声明:此为个人学习总结,如果有理解错误或者有争议的内容,欢迎大家指出,感谢。
目录
1.“CUDA out of memory"

数据并行Data Parallelism(DP)就是为了解决这个问题。用通信换内存。
原理上,每台GPU都会有一个独立的模型,我们只是利用了集群的单节点的算力。
2.显存如何分配?
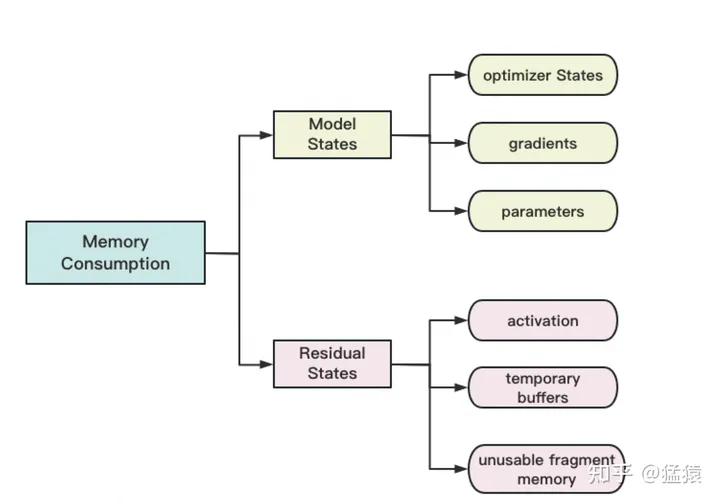
存储主要分为两大块:Model States和Residual States
Model States指和模型本身息息相关的,必须存储的内容
Residual States指并非模型必须的,但在训练过程中会额外产生的内容,activition是计算fwd时每层的Tensor
下面就引出了Deepspeed的内存优化方案-Zero:
- Zero-DP: Model Status切分成m份,每个GPU上存一份,当前GPU需要用到时再从其他GPU上传送过来
- Zero-R:activition(FWD各层Tensor)切分成m份,每个GPU上存一份,用到时从其他GPU上传过来,组成一个完整的输入。
GPipe纵向切分模型的层,对于中间结果,采用”重算”才降低内存。
3.梯度累积方式:Ring-AllReduce
数据并行时,在各个GPU上都拷贝一份完整模型,各自吃一份数据,算一份梯度,最后对梯度进行累加来更新整体模型。
如:优化器中使用的随机梯度下降算法SGD中,更新参数的公式:参数 = 参数 - 学习率 * 梯度
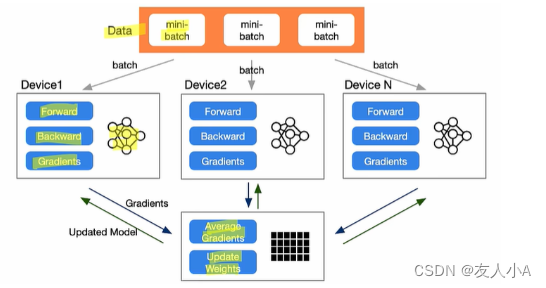
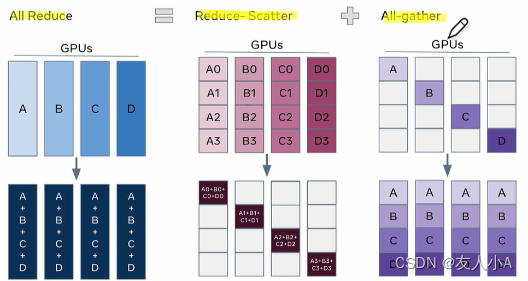
(此图来自B站李沐或者zomi酱的视频,忘记具体是谁了)
3.1 reduce-scatter
scatter是一种常用的数据分布操作,通常用于将一个大的数据集合分散到多个计算节点上进行并行计算。
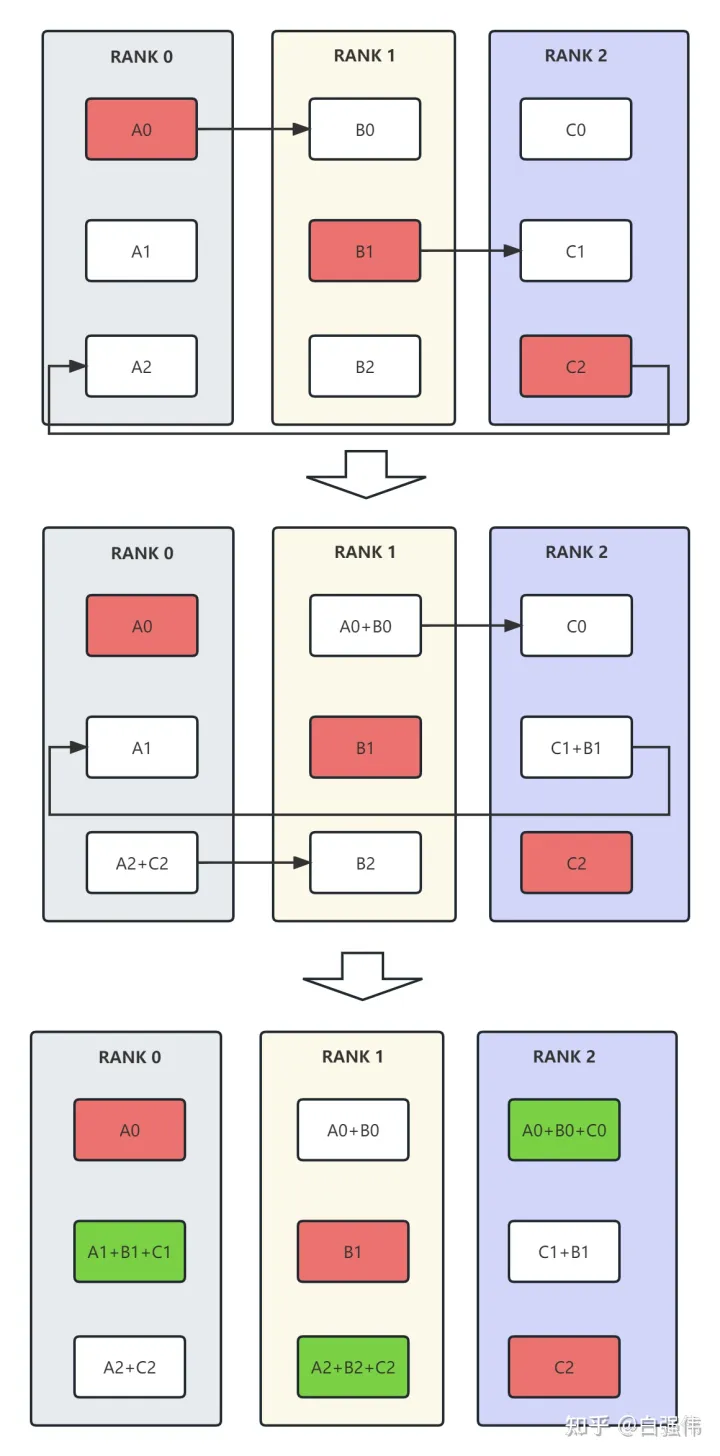
各个显卡从红色的数据开始传输,经过2次reduce-scatter后,reduce的结果存储在了绿色的位置。
通信量:假如总通信量为 Ψ, 每张卡上存储了 Ψ/3的数据量,则一次reduce-scater的通信量(即单卡通信量)= Ψ/3*3=Ψ
3.2 all-gather

在经过reduce-scatter后,reduce的数据分布在绿色的数据块上。all-gather从绿色的数据块开始,目标是把绿色块的数据广播到其余GPU对应的位置上。
经过2次all-gather后,所有的显卡都有了完整的reduce结果。
通信量:假如总通信量为 Ψ, 每张卡上存储了 Ψ/3的数据量,则一次all-gather的通信量(即单卡通信量)= Ψ/3*3=Ψ
4. Deepspeed 方案
4.1 Zero-DP 例图分析
ZeRO-DP能够对模型状态(权重、梯度和优化器状态)进行划分(不像标准DP那样进行复制),然后通过动态通信调度来最小化通信开销。ZeRO-DP能够在保持整体通信开销接近标准DP的同时,线性地降低模型的单显卡显存占用。
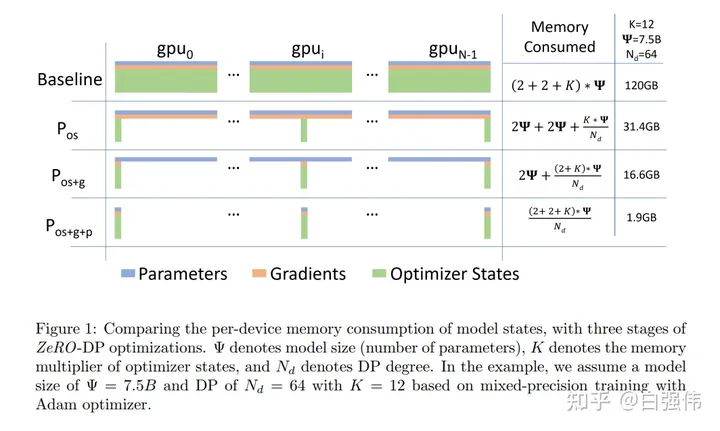
这个图中是混合精度训练,优化器=Adam(K=12)的一个示例:
- Ψ是模型参数量,”乘以2“是指FP16训练,FP16=2Bytes,因此显存=2Ψ Bytes;
- K=12
Adama优化器状态要保存两个参数:momentum, variance。
optimizer.step()更新梯度时计算类型是FP32,因为梯度更新不停累加。如果是FP16类型计算,有两种情况:(1)0附近的数字多次累加仍不会变化;(2)较大数字累加后很容易inf
因此 Optimizer States保存的是FP32的数据:weight, momentum, variance → 3*4=12Ψ - 120GB
需要的总显存 = (参数+梯度+优化器状态) = 16Ψ Bytes
若 Ψ=7.5B, 则显存=16*7.5=120 Billion Bytes = 120GB (G=10亿)
4.2 Zero-DP分割方案比较
首先说一下标准的数据并行(这段来自参考链接):
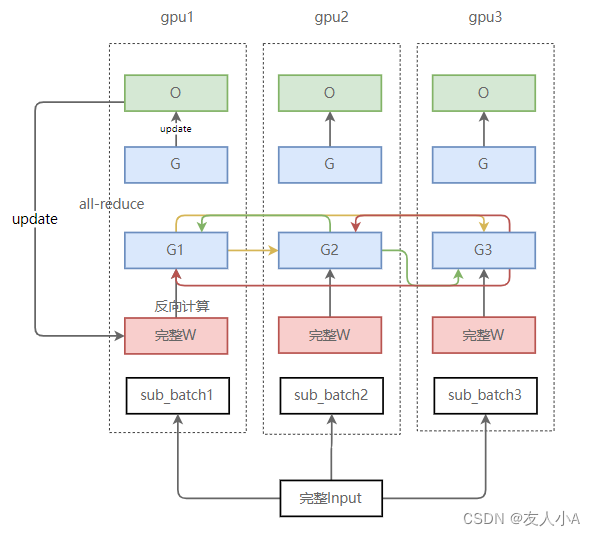
- 标准的数据并行会将模型参数拷贝至各个显卡上,也就是上图中各个Rank都拥有相同的模型参数。
- 随后,将采样的batch均等划分至各个显卡上;
- 各个显卡独立完成前向传播和反向传播,得到对应的梯度(此时,各个显卡上的梯度并不相同);
- 通过AllReduce操作,将各个显卡上的梯度进行平均,并将平均后的梯度返还给各个显卡(此时,各个显卡上的梯度完全相同);
- 各个显卡独自更新模型参数;
| 切分内容 | 显存降低倍数(K=12,N=64) | 单卡通信量 | 解释(请结合示意图看) | |
|---|---|---|---|---|
| DDP | 参数W | (4+K)/(2/N+2+K)=1.06 | 2Ψ | 对反向计算后得到的梯度做一次完整的AllReduce。 基于全局梯度信息来更新参数,通常都能得到更好的训练效果。 |
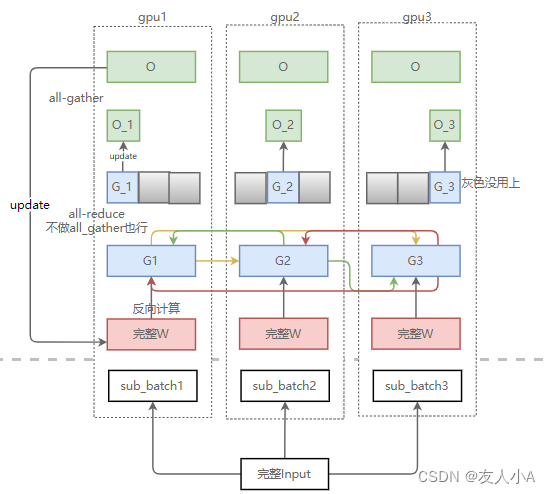
| Zero1(Pos) | 优化器状态 | (4+K)/(4+K/N) = 3.8 ≈ 4 | 2Ψ | 实际使用中,因为优化器状态切片,灰色部分没有用到,所以梯度没有做完整的AllReduce,只做了reduce-scatter。
|
| Zero2(Pops+g,) | 优化器状态+梯度G | (4+K)/(2+2/N+K/N)=7.2 ≈ 8 | 2Ψ | 因为Zero1已经对优化器状态切片,所以没有必要保留完整的Grad信息,Zero2就是增加对Grad的切片
|
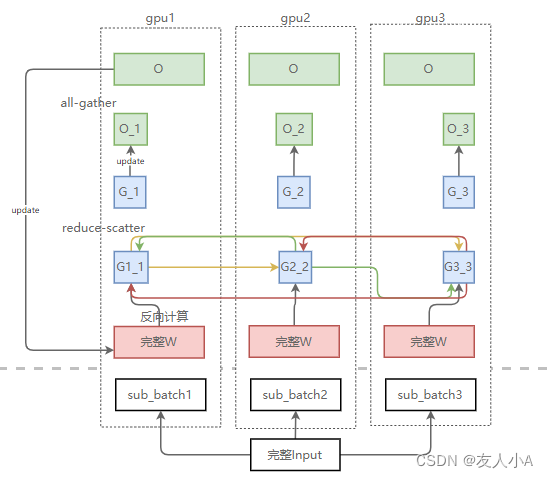
| Zero3(Pops+g+p) | 优化器状态+梯度G+参数W | (4+K)/(2/N+2/N+K/N)=N = 64 | 3Ψ | 既然Grad切片只能更新对应的优化器状态切片和参数切片,那么我们就把参数也切了吧——Zero3 两个all-gather + 一个reduce-scatter = 3Ψ
Zero3用1.5倍的通信开销,换回了64(N)倍的显存。 Zero3形式上虽然切分了W,但是在forward和backward的过程中,通过all-gath er获得了完整的W,所以不是模型并行。 |
DDP示意图
Zero1(Pos)示意图
Zero2(Pops+g,)示意图
Zero3(Pops+g+p)示意图
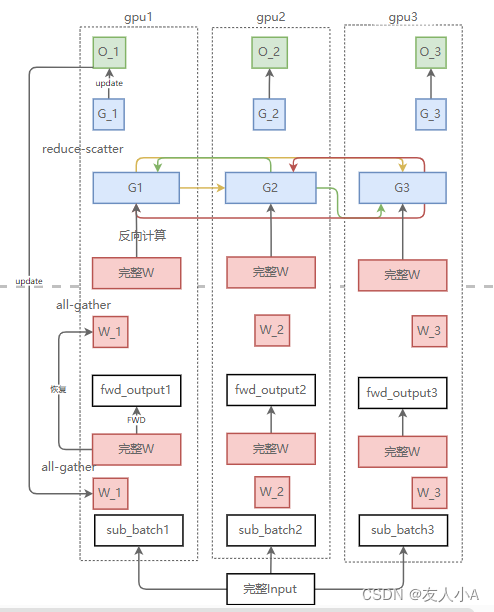
备注:反向计算要用到完整W,反向计算结束后各GPU上的其他部分W会被释放,图上忽略了这步

















 3803
3803

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









