




 本文详细介绍了无监督领域适应(UDA)在行人重识别(person re-ID)领域的研究进展。主要分为三类方法:基于聚类的方法,如交替分配标签和使用K-means优化网络;风格迁移方法,如SPGAN和PTGAN通过图像风格转换减少域差距;以及通过计算参考图像相似性优化目标域软标签的方法。这些方法旨在解决手工标注成本高和域间差异问题,通过不同的策略学习域不变特征,提高模型在无标签数据上的表现。
本文详细介绍了无监督领域适应(UDA)在行人重识别(person re-ID)领域的研究进展。主要分为三类方法:基于聚类的方法,如交替分配标签和使用K-means优化网络;风格迁移方法,如SPGAN和PTGAN通过图像风格转换减少域差距;以及通过计算参考图像相似性优化目标域软标签的方法。这些方法旨在解决手工标注成本高和域间差异问题,通过不同的策略学习域不变特征,提高模型在无标签数据上的表现。
Unsupervised domain adaptation (UDA) for person re-ID.
UDA methods have attracted much attention because their capability of saving the cost of manual annotations. There are three main categories of methods.
UDA方法由于节省了手工标注的花费而吸引了许多关注,这里主要有三种方法:
The first category of clustering-based methods maintains state-of-the-art performance to date
第一类集群时至今日也保持着最优的性能
- (Fan et al., 2018) proposed to alternatively assign labels for unlabeled training samples and optimize the network with the generated targets.
原文链接:https://arxiv.org/pdf/1705.10444.pdf
提出为未标记的训练样本交替分配标签(fine-tune与clustering交替的过程),并且用生成的目标优化网络。
1.解决的问题:
(1)用无标签数据(或 其他域有标签数据及无标签数据)训练模型。
(2)把K-means和CNN结合,减轻了cluster太过noisy的问题。
(3)用自步学习更加流畅地完成模型训练。
2.训练步骤:
step1: ImageNet上预训练的ResNet
step2: 用不相关的有标签数据对网络进行初始化
step3: 将无标签的数据喂给网络,进行聚类。(聚类到底是怎样的,如何初始化聚类中心)(觉得这个初始点的选择应该很重要吧)
step4: 选择离中心最近的几个点,加入“可靠训练集”。训练集的标签即为k-means的k。
step5: 将“可靠训练集”的数据喂给网络再次训练。因为模型会越来越好,所以接近聚类中心的样本会随着epoch增加,即本文的卖点之一。(为避免陷入局部最优,先从“可靠度”最高的样本训练起)
step6: 以上3,4,5环节周而复始。直到每次选择的个数稳定。
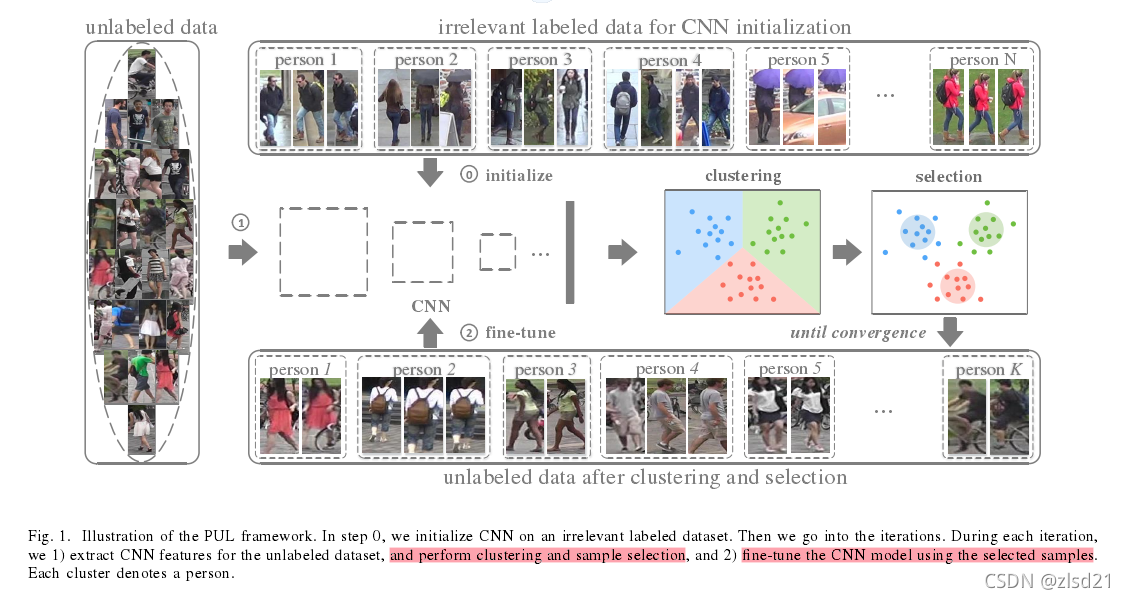
本文提出了一个关于self-paced learning(自步学习)方法,我查了一下,觉得这篇博客较为清晰,供大家参考 https://blog.youkuaiyun.com/weixin_37805505/article/details/79144854
- (Lin et al., 2019) proposed a bottom up clustering framework with a repelled loss.
提出了一种具有排斥损失的自顶向下的聚类框架
文章思想:作者的方法考虑到了行人再识别任务的两个基本的事实:不同人间的diversity和同一个人间的similarity。作者的算法最开始把每个人作为单独的一类,来最大化每类的dive
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 3214
3214

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









