




 本文解析了R_theta的梯度为何等于R(t^n)乘以p(a_t|s_t,theta)的概率梯度。通过交叉熵损失函数解释了这一公式背后的逻辑,并讨论了如何通过这种方式使得回报高的状态动作对被更多训练。
本文解析了R_theta的梯度为何等于R(t^n)乘以p(a_t|s_t,theta)的概率梯度。通过交叉熵损失函数解释了这一公式背后的逻辑,并讨论了如何通过这种方式使得回报高的状态动作对被更多训练。
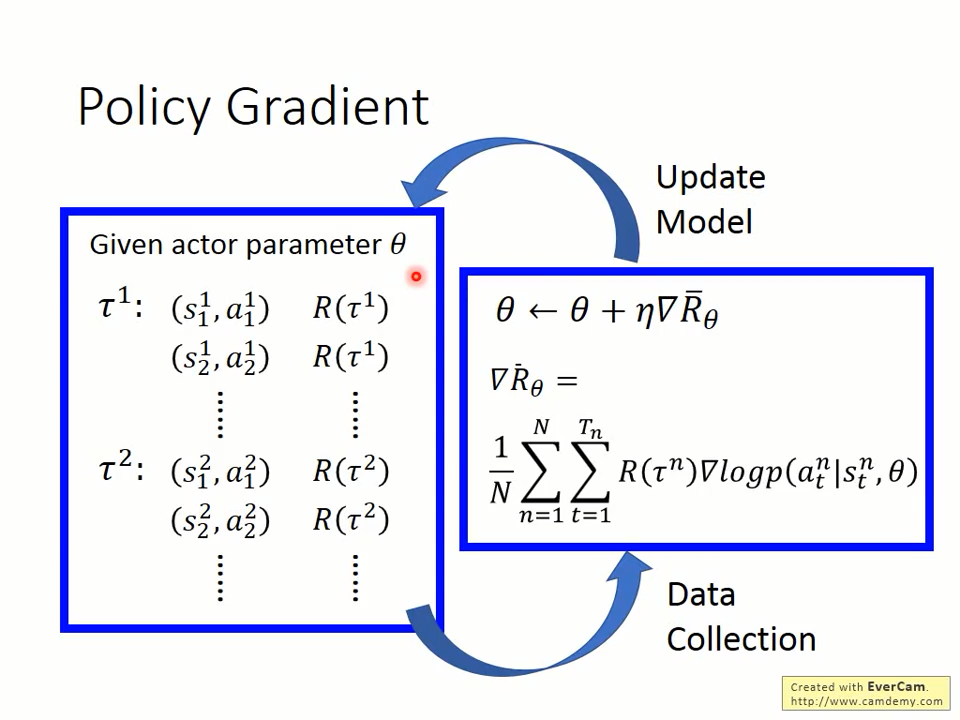
eta为学习率。
R_theta的梯度为什么是R(t^n)grad(p(a_t|s_t,theta)?
首先,我们来解释下grad(p(a_t|s_t,theta)是怎么来的。先看下面的一个分类问题。
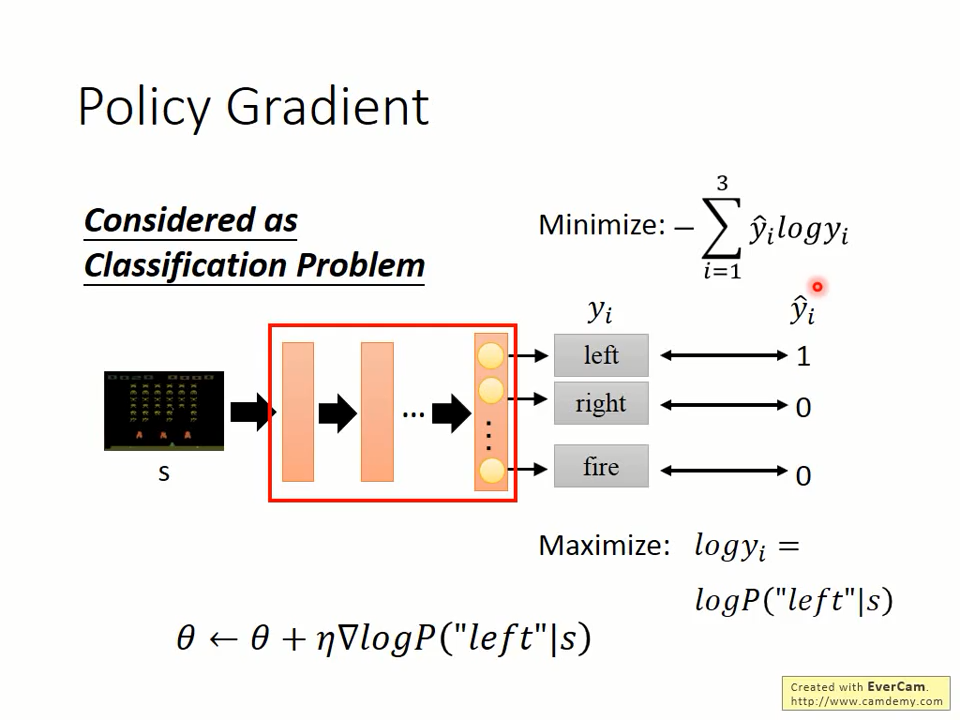
从上可知,分类的损失函数采用交叉熵,最小化交叉熵相当于最大化log(y_i)
再来看为什么要乘上一个R(t^n)。从下面可知,乘上一个R(t^n),说明回报越大的状态动作对将被训练的次数越多,即对策略theta的影响更多。
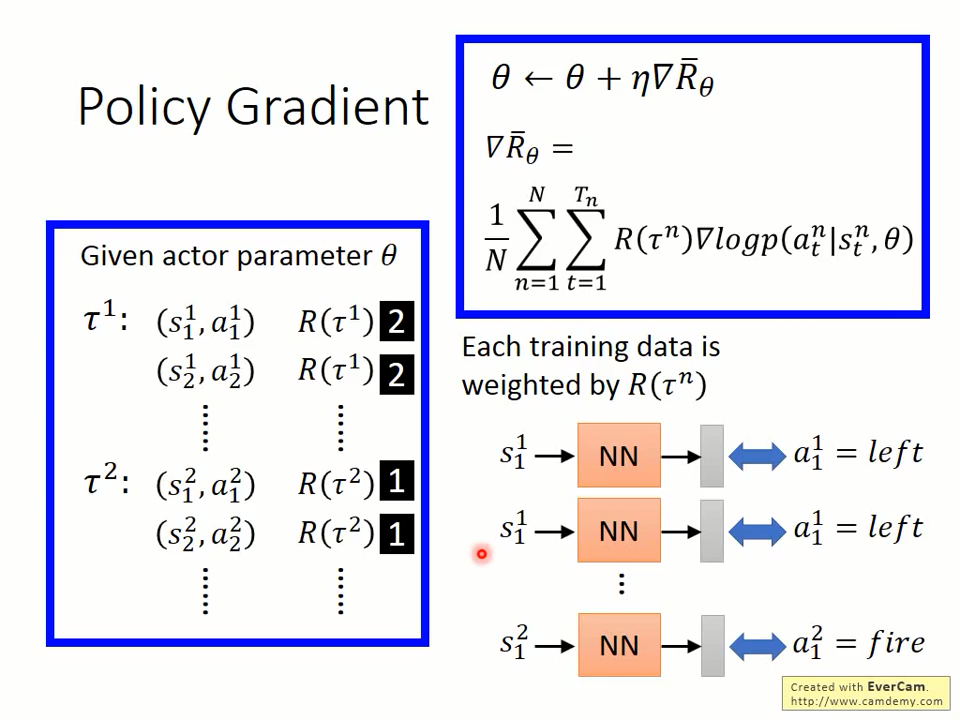
eta为学习率。
R_theta的梯度为什么是R(t^n)grad(p(a_t|s_t,theta)?
首先,我们来解释下grad(p(a_t|s_t,theta)是怎么来的。先看下面的一个分类问题。
从上可知,分类的损失函数采用交叉熵,最小化交叉熵相当于最大化log(y_i)
再来看为什么要乘上一个R(t^n)。从下面可知,乘上一个R(t^n),说明回报越大的状态动作对将被训练的次数越多,即对策略theta的影响更多。
 2万+
2万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言


























