







基因组选择的流程:
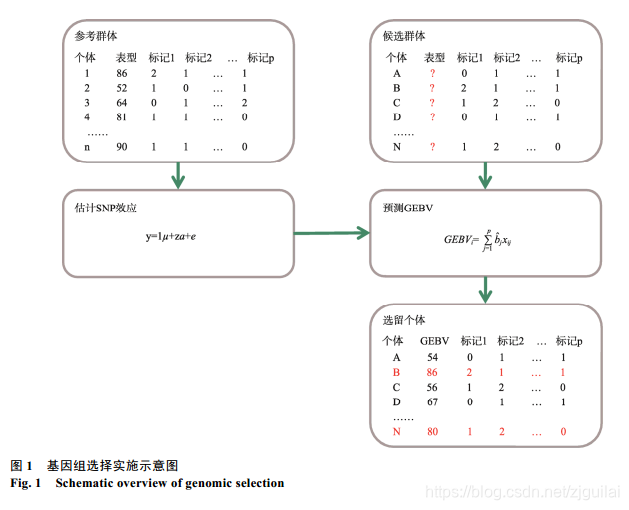
GS一般包括以下步骤(图1):首先建立参考群体(reference population),参考群体中每个个体都有已知的表型和基因型,通过合适的统计模型可以估计出每个SNP或不同染色体片段的效应值;然后对候选群体(candidate population)每个个体进行基因分型,利用参考群体中估计得到的SNP效应值来计算候选群体中每个个体的GEBV;最后,根据GEBV排名对个体进行选留,待选留个体(selected candidates)完成性能测定后,这些个体又可以被放入参考群体,用于重新估计SNP的效应值,如此反复。
研究目的:
基因组选择方法精准,快速的估计出基因组育种值,是通过高效的统计模型来完成,下面例举一下这些高效统计模型GS:
GS实质为全基因组范围的标记辅助选择,其理论基础是应用整个基因组的标记信息和各性状值来估计每个标记或染色体片段的效应值。然后将效应值累加和继而得到基因组育种值(GEBV),对GEBV值作出可靠的评估,弥补了在MAS中标记数量只能解释一部分遗传方差以及数量性状位点(QTL)定位难的问题。其中心任务是提升GEBV的准确性,并尽可能准确估计每个标记的效应。
GS方法分为两大类:直接型,间接型
2)直接型:参考群体和预测群体遗传信息构建的亲缘关系矩阵(G),作为随机效应的混合模型获取戴预测个体的估计育种值,如BLUP法,利用系谱信息构建个体间的亲缘关系矩阵作为随机效应,利用混合线性模型对随机效应进行预测BLUP,获得个体的估计育种值,相比于基于系谱构建的亲缘关系矩阵,G更能够反应个体间的遗传信息差异,我们称之为gBLUP
3)间接型:首先在参考群中估计标记效应,然后结合预测群的基因型信息将标记效应累加获得预测群的个体估计育种值,如代表性的方法:rrBLUP,Bayes系列(Lasso,Bayes
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章

















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









