



本文从零实现,基于Ollama、FastGPT、Deepseek在本地环境中打造属于自己的专业知识库,与大家分享~
本地部署Ollama
Ollama是一个开源的本地大语言模型运行框架,专为在本地机器上便捷部署和运行大语言模型(LLM)而设计,无需依赖云端服务。它提供简单易用的界面和优化的推理引擎,帮助我们轻松加载、管理和运行各种AI模型。
下载Ollama
要使用Ollama,首先需要下载并安装它。访问以下链接:
https://ollama.com/download
找到适合你操作系统的版本进行下载,默认安装即可。这里笔者以Windows系统为例。
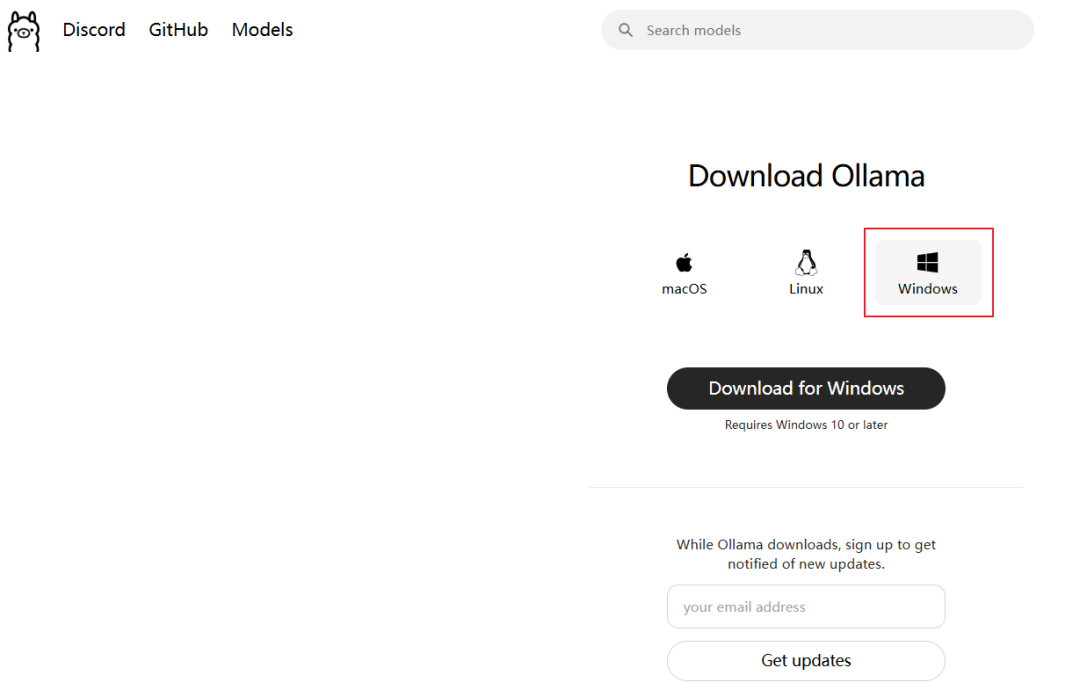
注:Ollama官网提供的地址下载速度很慢,而且中途崩溃很容易下载失败,着急的小伙伴也可以从 https://ollama.zhike.in/ 下载,亲测好用!
部署DeepSeek R1模型
接下来,我们来安装一个具体的语言模型——DeepSeek-R1。
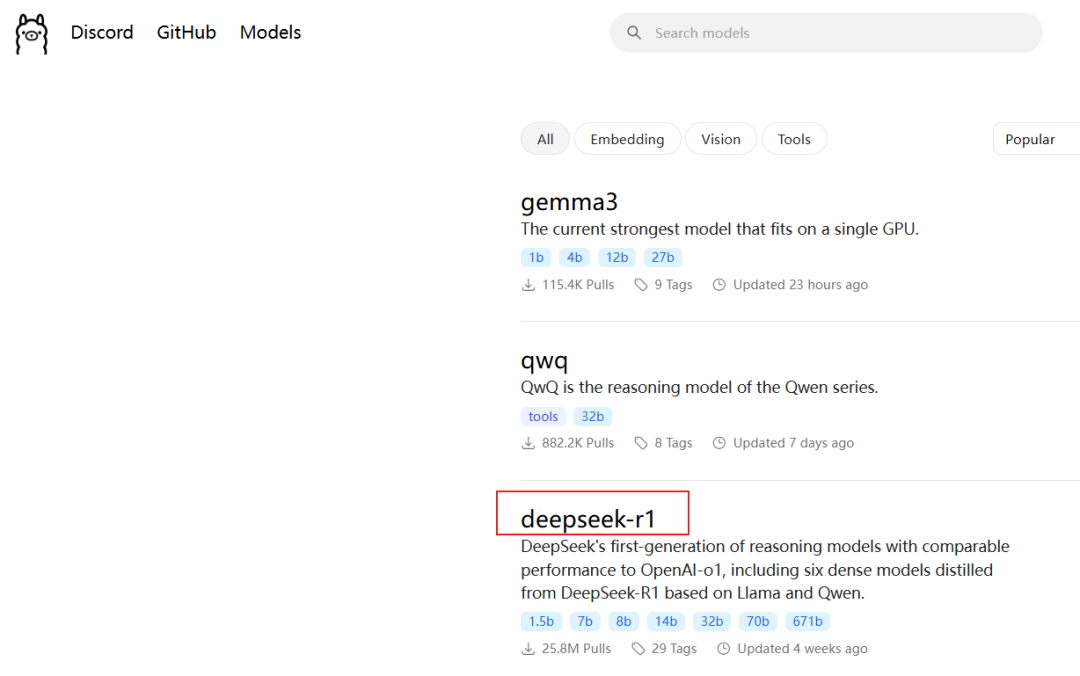
打开Ollama官网,点击Models菜单,选择进入deepseek-r1模型详情页面。
根据自己的需求选择合适的版本,并复制对应的ollama安装命令。这里以deepseek-r1:1.5b为例,其中1.5b表示模型参数量为1.5亿。
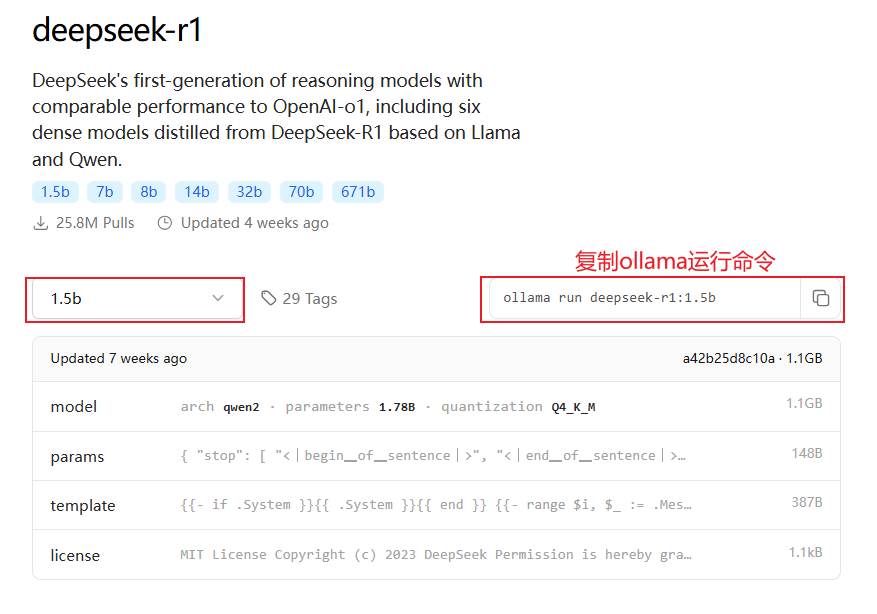
打开终端(Windows用户可以用CMD或PowerShell),输入刚刚复制的命令并回车。

等待运行完成,如果看到success提示,说明安装成功了!
测试一下模型是否正常工作,输入 “请问你是谁?”,看看模型能否正确回答。

部署Embedding模型
为了后续搭建知识库,我们还需要安装一个嵌入模型。Embedding Model的作用是将文本转换成向量形式,方便进行搜索和匹配。
在Ollama官网的Models页面,找到一个Embedding Model。这里选择一个比较小的模型:nomic-embed-text。
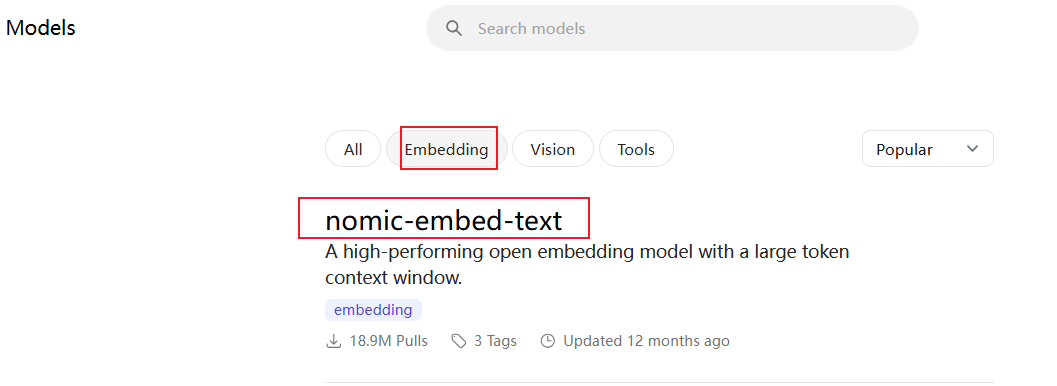
复制对应的安装命令:
ollama pull nomic-embed-text
在终端中运行该命令,等待安装完成。如果看到 success 提示,说明安装成功了!

最后,输入ollama list命令,查看ollama是否部署成功。

下载并安装ubuntu
为了更好地运行FastGPT,官方建议将源代码和其他数据存储在Linux文件系统中,而不是Windows文件系统中。因此,这里我们使用Microsoft Store中的Ubuntu来安装FastGPT。
打开Microsoft Store,在搜索框中输入“Ubuntu”,选择下载并安装 Ubuntu 22.04.5 LTS 版本。
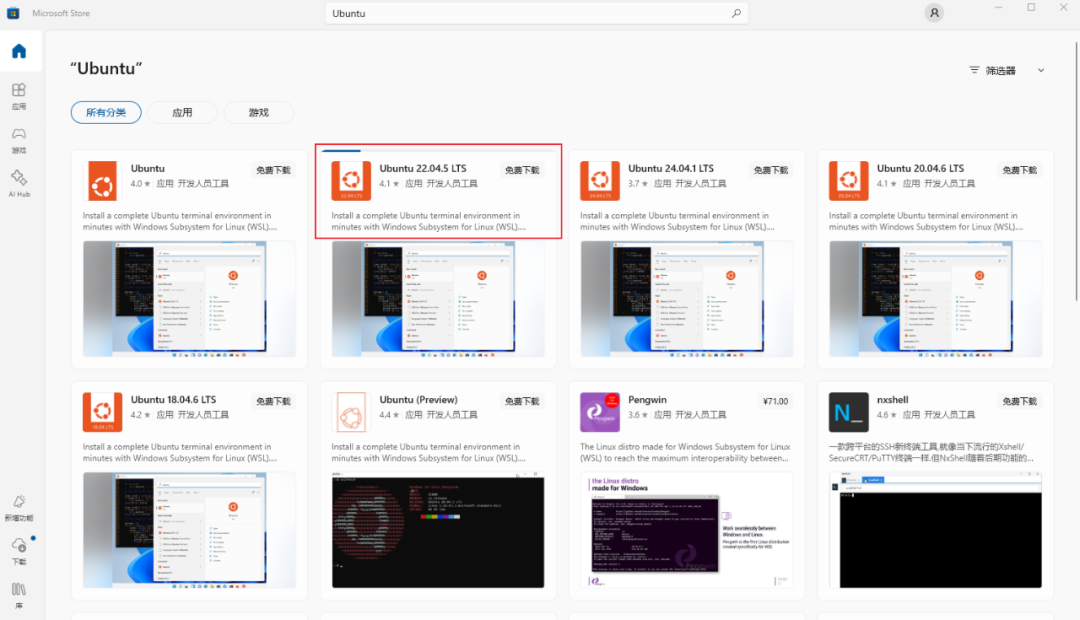
安装完成后,打开Ubuntu应用,进入初始配置界面。按照提示设置一个用户名和密码。
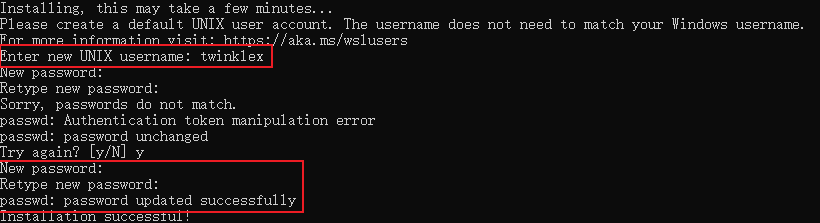
「注意」:安装完成后,Ubuntu会自动挂载到Windows的WSL(Windows Subsystem for Linux)环境中,后续我们可以通过Windows资源管理器访问Ubuntu的文件系统。
Ubuntu准备docker环境
安装Docker,运行以下命令通过阿里云镜像安装Docker,并启动Docker服务并设置为开机自启。
curl -fsSL https://get.docker.com | bash -s docker --mirror Aliyun
sudo systemctl enable --now docker
安装Docker-compose。运行以下命令下载Docker-compos二进制文件,并赋予执行权限。
curl -L https://github.com/docker/compose/releases/download/v2.20.3/docker-compose-`uname -s`-`uname -m` -o /usr/local/bin/docker-compose
chmod +x /usr/local/bin/docker-compose
验证安装。
docker -v
docker-compose -v
部署FastGPT
创建FastGPT目录并下载配置文件
接下来,我们需要在Ubuntu中创建一个目录用于存放FastGPT的相关文件,并下载必要的配置文件。
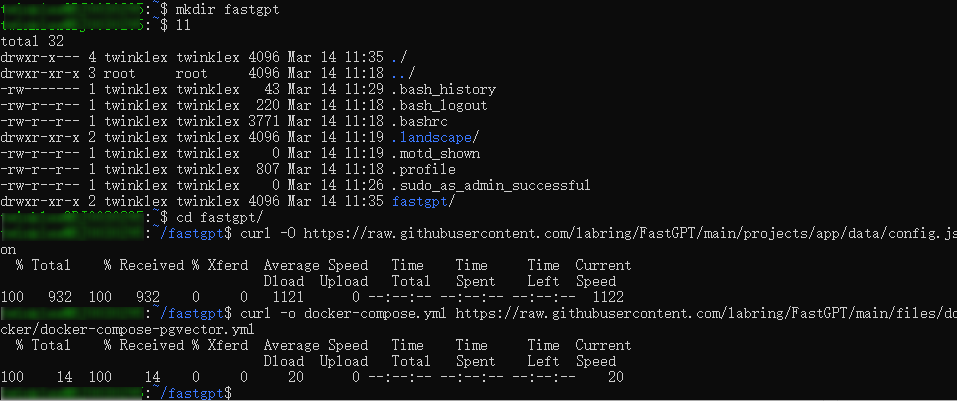
打开Ubuntu终端,执行以下命令创建 fastgpt 目录:
mkdir fastgpt
进入刚创建的目录:
cd fastgpt
下载FastGPT的配置文件config.json和docker-compose.yml:
curl -O https://raw.githubusercontent.com/labring/FastGPT/main/projects/app/data/config.json
curl -o docker-compose.yml https://raw.githubusercontent.com/labring/FastGPT/main/deploy/docker/docker-compose-pgvector.yml
其中,
- config.json是FastGPT的核心配置文件,包含了项目的基本设置。
- docker-compose.yml 是Docker容器的配置文件,用于定义FastGPT所需的运行环境。
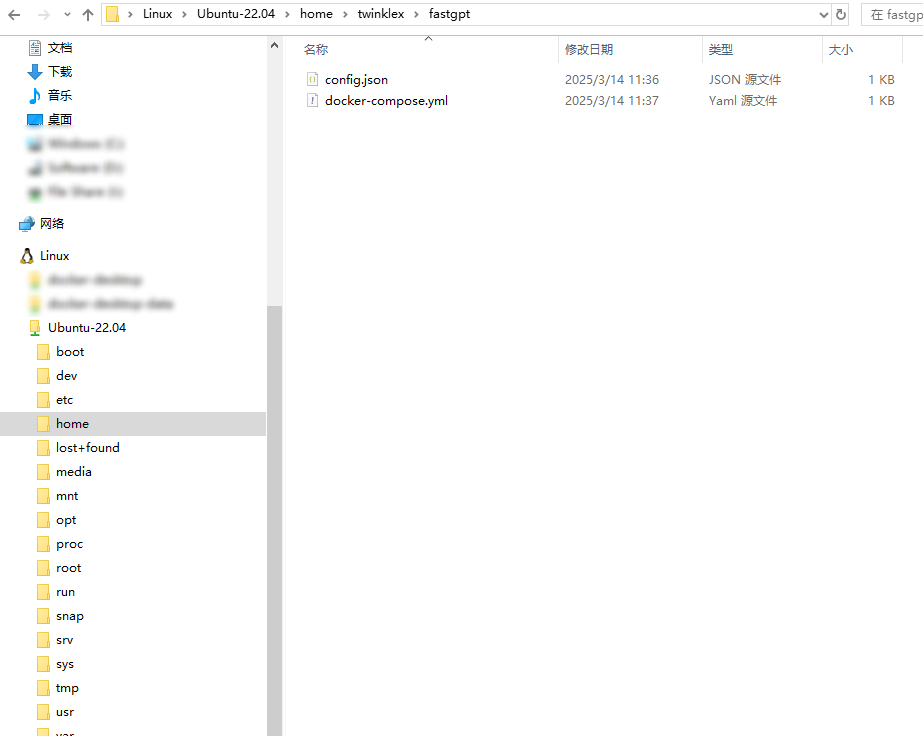
通过WSL,Ubuntu的文件系统会被挂载到Windows中,我们可以直接在Windows资源管理器中访问这些文件。
打开Windows资源管理器,在地址栏输入以下路径,将看到刚刚在Ubuntu中创建的fastgpt文件夹,以及其中下载的两个文件:config.json 和 docker-compose.yml。
\\wsl.localhost\Ubuntu-22.04\home\username\fastgpt
修改配置文件docker-compose.yml
使用文本编辑器打开 docker-compose.yml 文件,这里以 vim 为例:
vim docker-compose.yml
找到 FE_DOMAIN 和 OPENAI_BASE_URL 两个配置项,并进行如下修改:
- FE_DOMAIN:设置前端访问地址为 http://localhost:3000。
- OPENAI_BASE_URL:设置AI模型的API地址为 http://host.docker.internal:3001/v1。
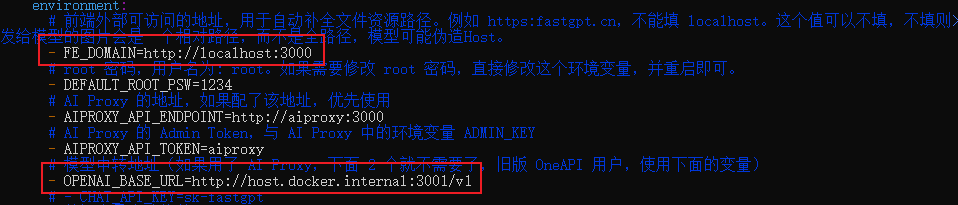
修改完成后,关闭当前终端并重新打开一个新终端,以确保配置生效。
启动容器
在fastgpt目录下,运行以下命令启动容器:
docker-compose up -d
如报错:
The command ‘docker-compose’ could not be found in this WSL 2 distro. We recommend to activate the WSL integration in Docker Desktop settings,需启用Docker Desktop的WSL 2集成。
启动成功后会在Docker中看到fastgpt及其组件。

配置OneAPI
登录OneAPI
打开OneAPI地址:
http://localhost:3001/
首次登录默认密码是root/123456。登录后根据提示修改密码。
添加渠道
在OneAPI的管理页面中,点击“渠道”选项,然后选择“添加新的渠道”。
填写以下信息:
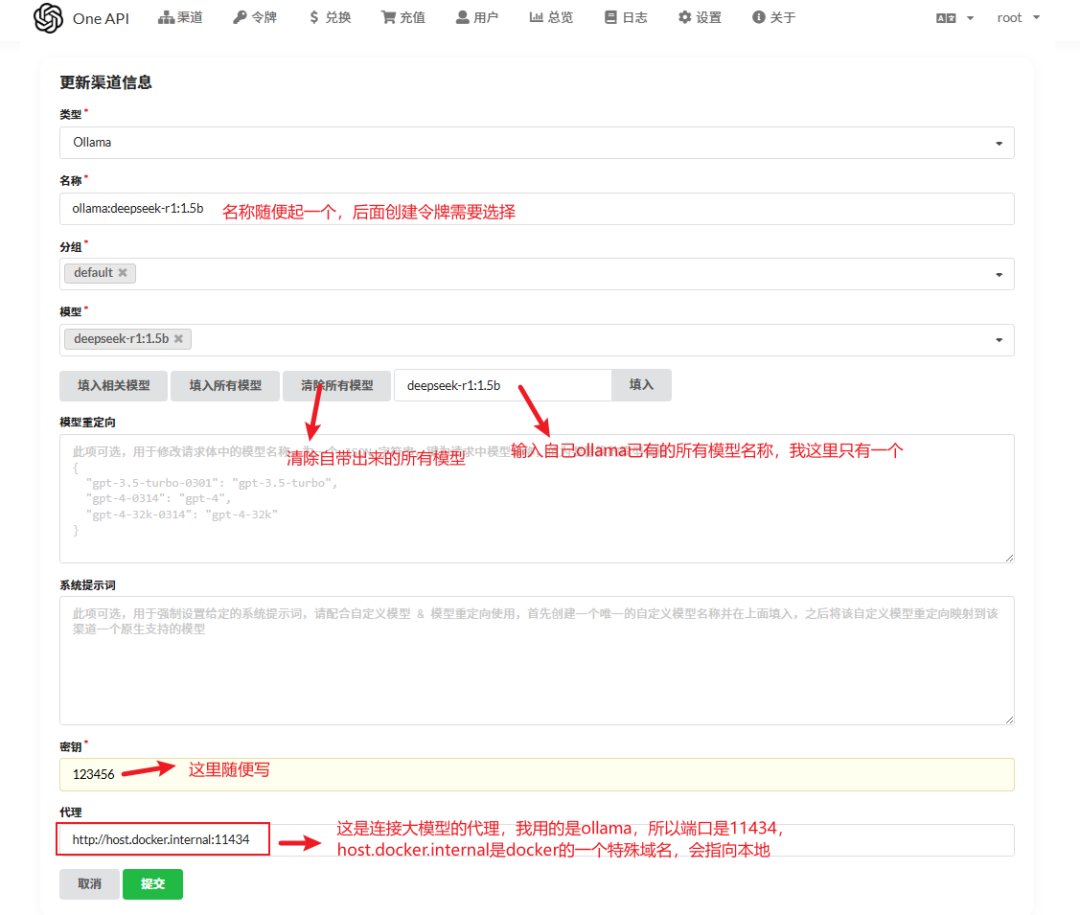
- 渠道类型:选择Ollama。
- 名称:随便填写,例如 ollama:deepseek-r1:1.5b。
- 模型:先清空默认模型列表,然后手动输入deepseek-r1:1.5b并确认添加。
- 密钥:随意填写一个字符串(例如123456)即可。
- 代理地址:填写 http://host.docker.internal:11434。
完成填写后,点击“提交”按钮保存配置。
提交完成后,再点击“渠道->测试”,开始测试模型,确保渠道能够正常工作。如果显示“测试成功”,说明配置正确。
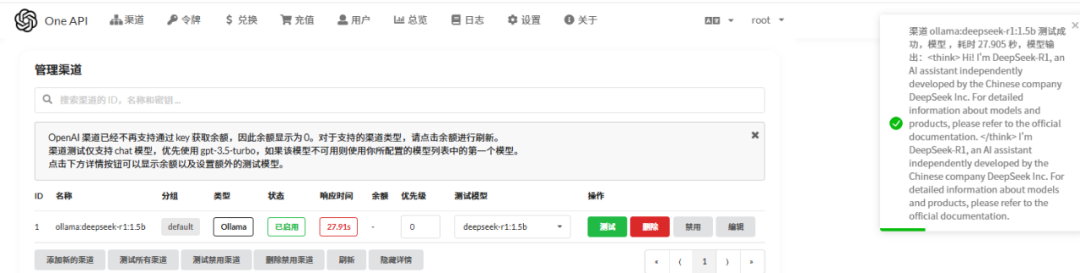
同样在“渠道”页面,点击“新增渠道”,填写以下信息,添加嵌入模型渠道,并测试。
添加令牌
在 OneAPI 的管理页面中,点击“令牌”菜单,然后选择“添加新的令牌”。
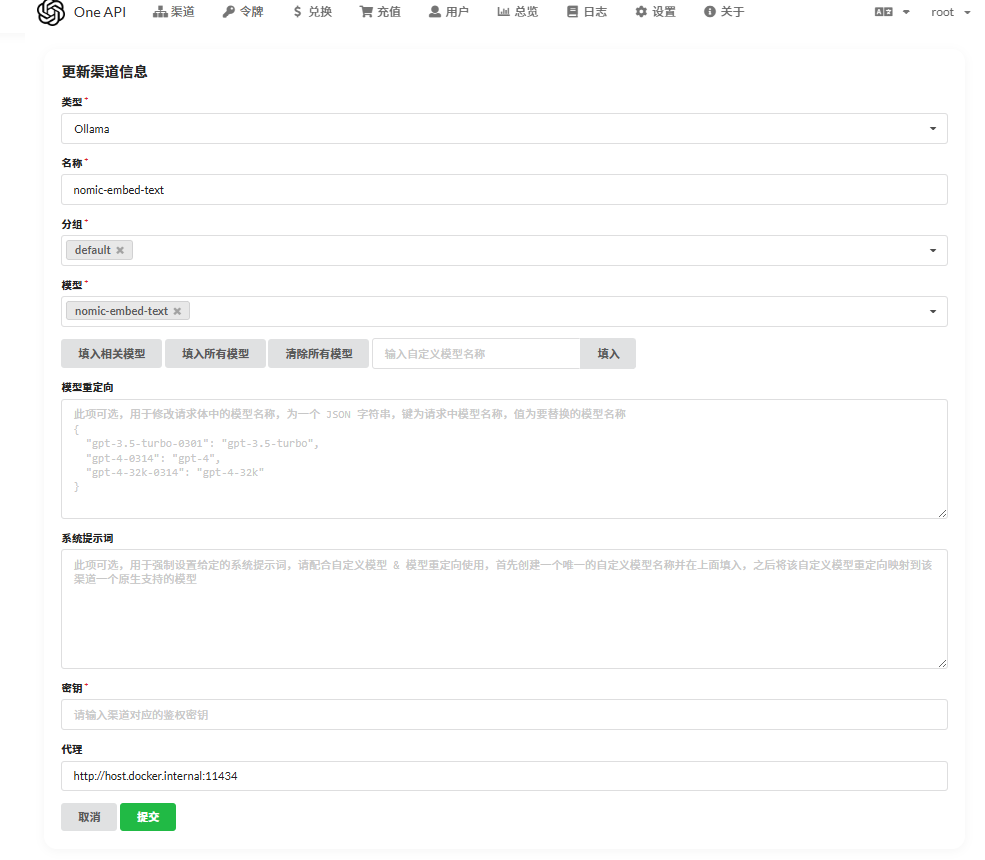
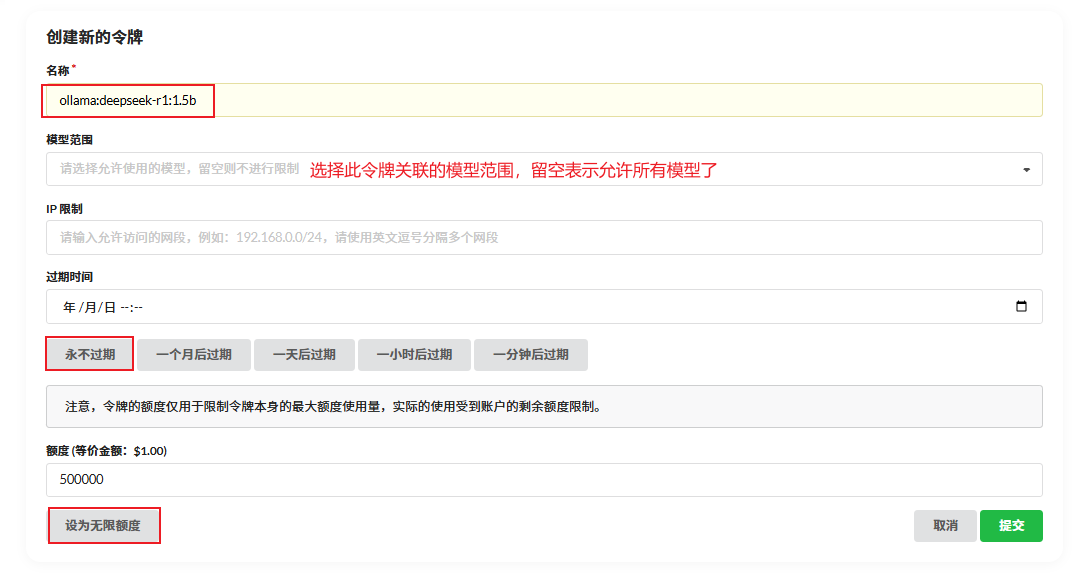
填写以下信息:
- 令牌名称:随便填写一个容易识别的名字,例如ollama:deepseek-r1:1.5b。
- 关联模型:留空。
- 过期时间:选择“永不过期”。
- 额度:选择“设为无限额度”。
完成填写后,点击“提交”按钮生成令牌。
生成后,系统会自动显示新的令牌值,请点击“复制”按钮保存起来,后续配置中需要用到该令牌。
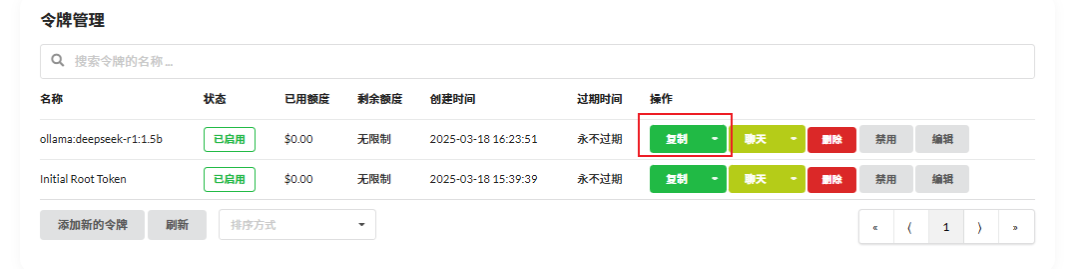
修改docker-compose.yml配置文件
将上述复制的令牌密钥添加到CHAT_API_KEY变量。

配置fastgpt
在Docker Desktop中找到并点击fastgpt容器,打开FastGPT的管理页面。

默认的登录账号和密码是:
- 用户名:root
- 密码:1234
登录后,你会看到如下界面:
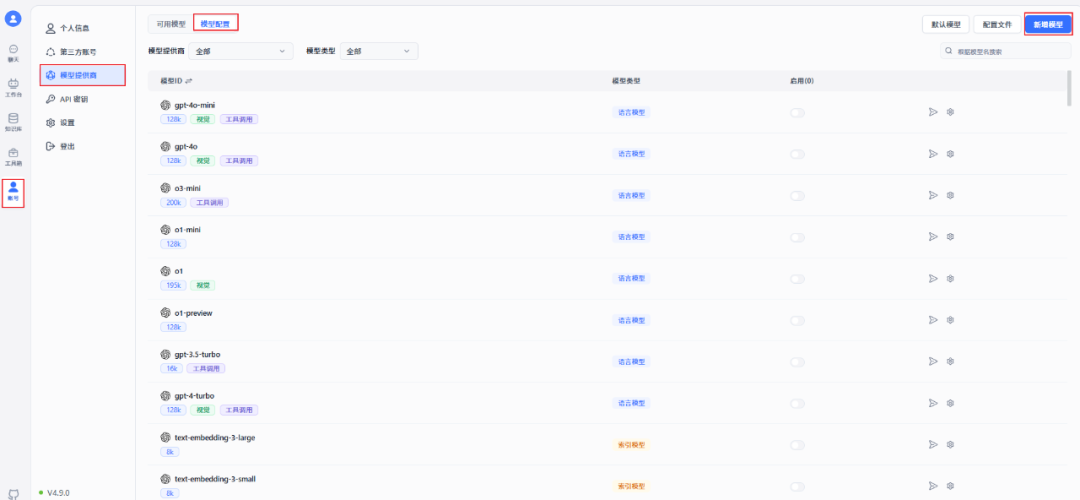
配置模型
打开 FastGPT 的工作台,点击“账号”选项,然后选择“模型提供商”。在模型提供商页面中,找到并点击“模型配置”,再点击右上角的“新增模型”按钮。
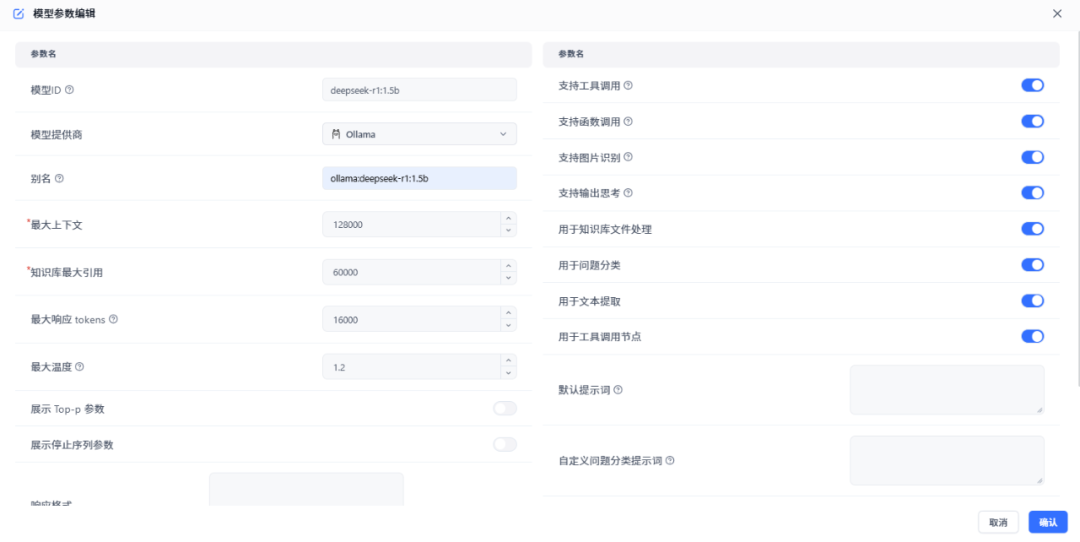
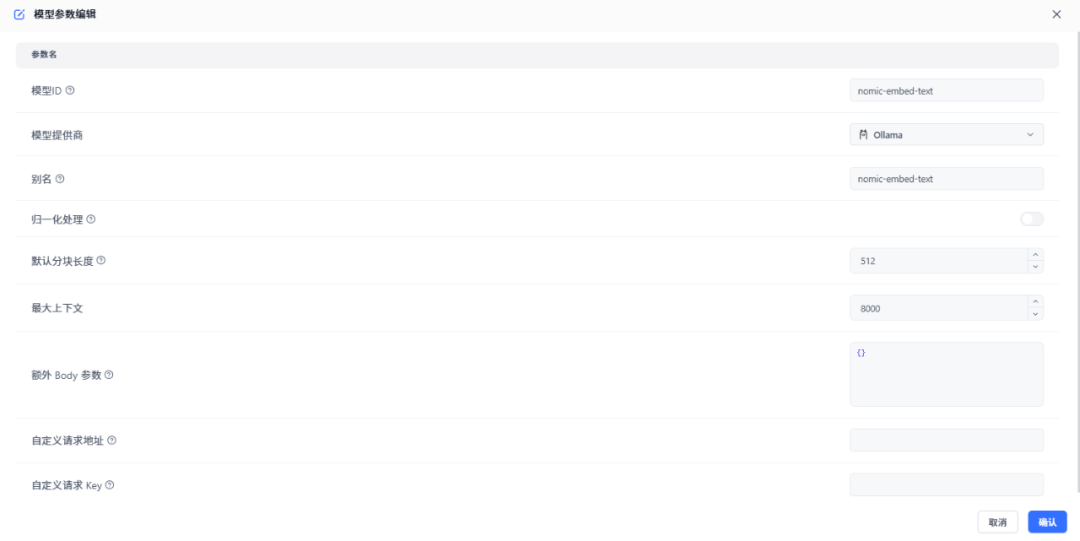
添加语言模型deepseek,在弹出的窗口中填写以下信息:
- 模型ID:这个ID必须与OneAPI中的ID一致。
- 模型提供商:选择Ollama。
- 别名:给模型起一个便于识别的名字,比如ollama:deepseek-r1:1.5b。
填写完成后,点击“确认”保存。
添加索引模型,同样点击“新增模型”,这次我们添加一个索引模型:
- 模型ID:可以是任意有效的ID,这里同样的与OneAPI中的ID一致。
- 模型提供商:选择Ollama。
- 别名:nomic-embed-text。
填写完成后,点击“确认”保存。
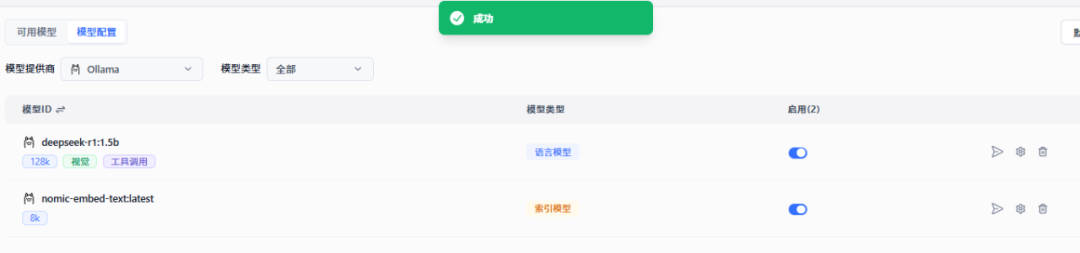
模型添加好后,在模型列表中找到你刚添加的语言模型和索引模型,点击旁边的“测试”按钮。

如果一切正常,系统会显示“成功”的提示信息。这说明模型已经正确配置并且可以正常使用了。
创建应用
打开FastGPT的工作台,点击“新建->简易应用”按钮,准备创建一个简单的应用。
给应用起个名字,比如我这里随便起了个名字叫fastgpt_test。选择“空白应用”选项,然后点击“确认”创建。
在应用的设置页面中,找到AI模型的选择项。从下拉菜单中选择我们之前配置好的模型:Ollama->deepseek。
配置完成后,可以在右侧的聊天区域进行测试。试着输入一个问题,比如:“请问你是谁?”“你来自哪里?”
如果一切正常,系统会很快返回答案,说明我们的应用已经可以正常使用了!
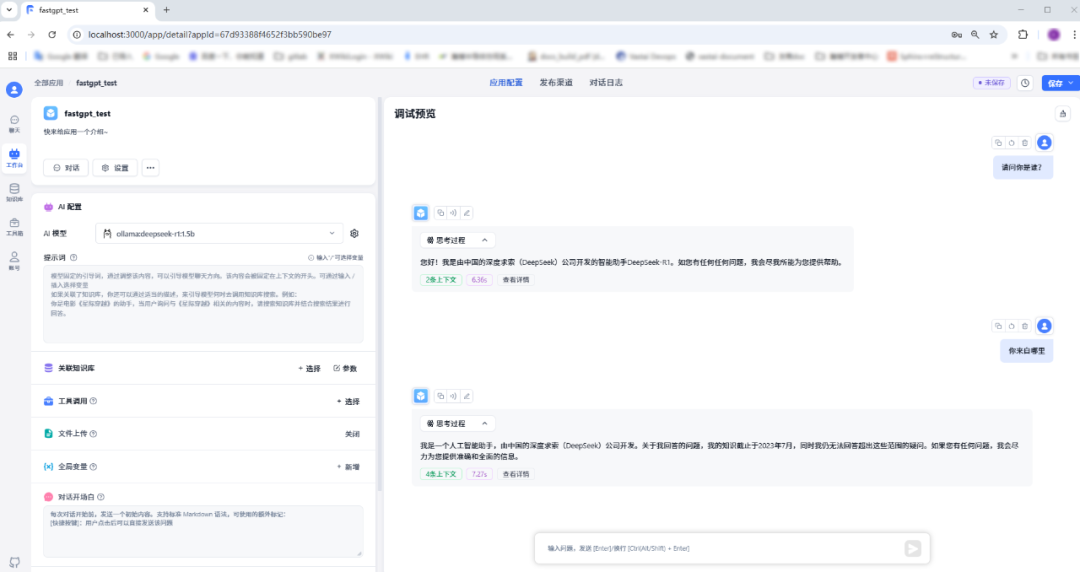
添加本地知识库
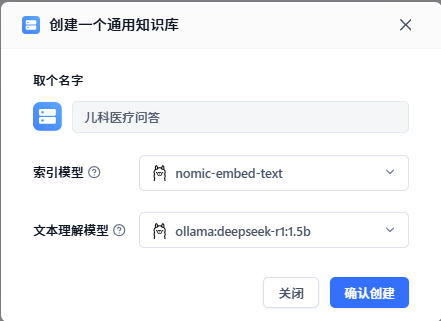
首先新建知识库,在左侧菜单栏找到“知识库”选项,点击右上角的“新建”按钮。选择“通用知识库”。

填入知识库的名称,然后选择索引模型和文本理解模型。这两个模型我们之前已经在Ollama中配置好了,直接选择即可。最后点击“确认”创建。
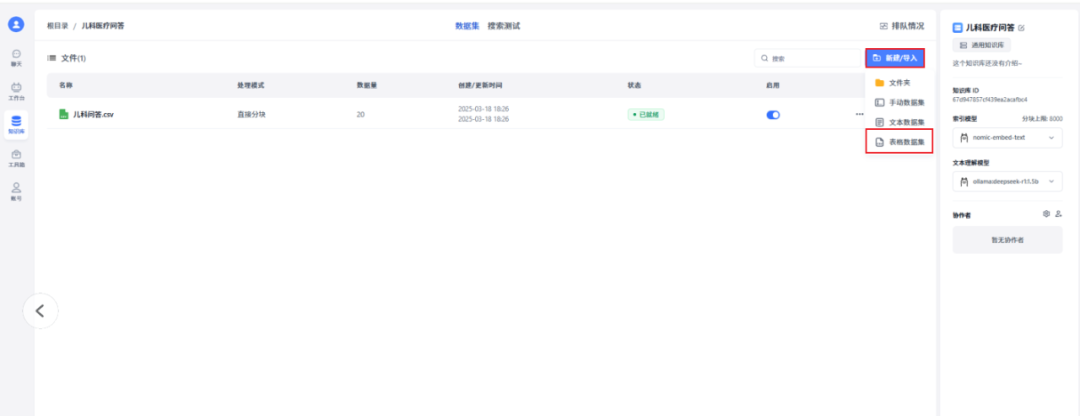
进入创建的知识库中,点击“新建/导入”->“表格数据集”,以新建一个表格数据集。
从本地上传需要的知识库文件。(注:这里笔者选择的是csv文件,我们也可以选择上传txt等格式。)
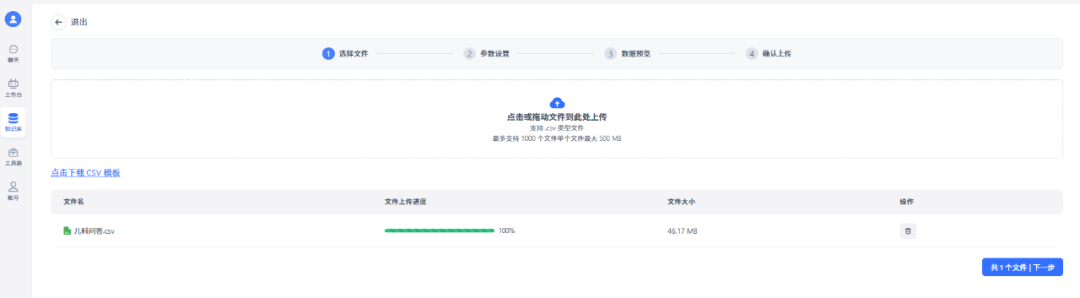
上传完成后,点击“下一步”,进行参数设置,默认使用直接分块方式分割内容。当页面显示“已就绪”,说明知识库已经成功搭建好了。

点击进入知识库,可以看到系统已经将文档内容分段处理成了一个个问答对。

测试知识库
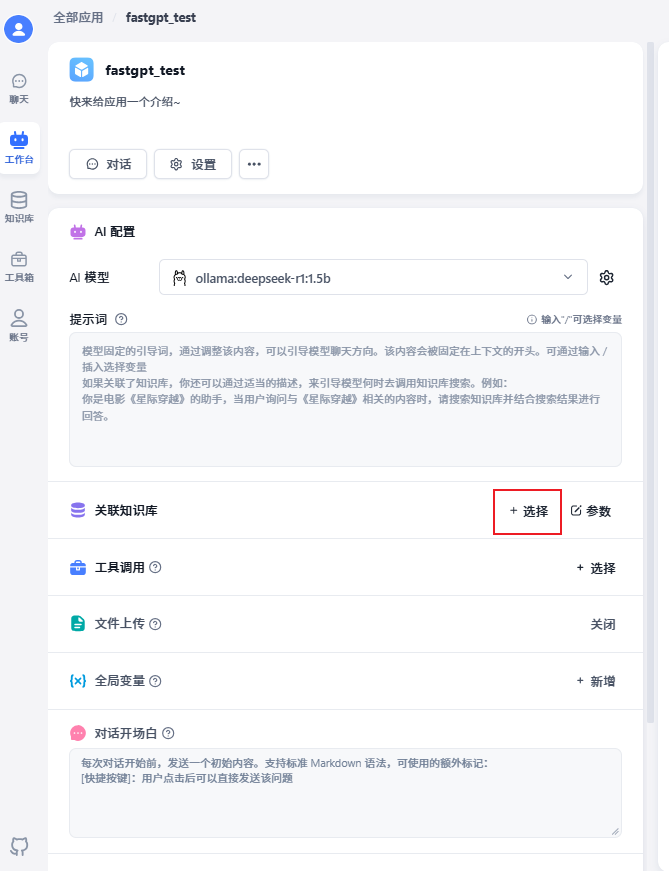
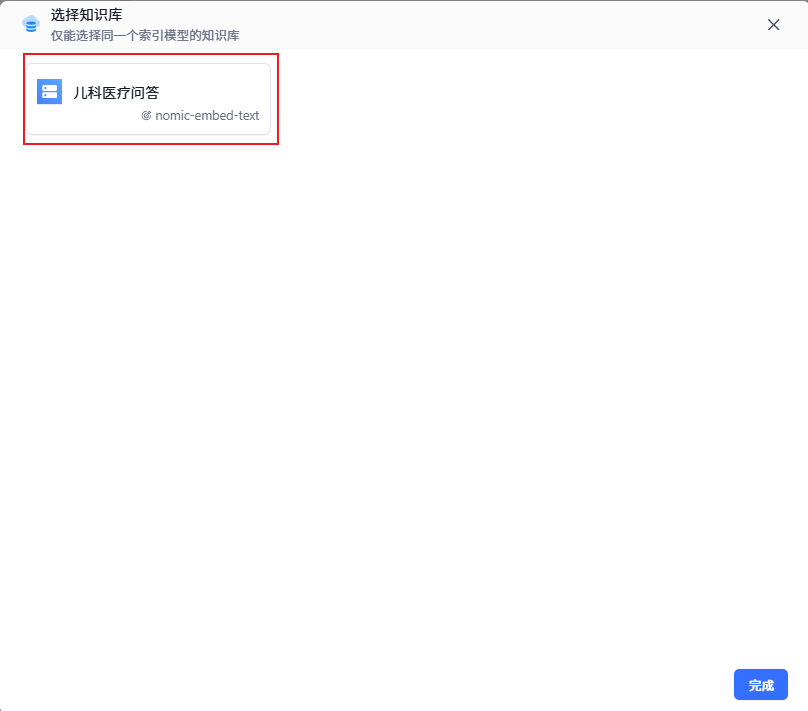
回到工作台,打开之前创建好的应用fastgpt_test,在应用的设置中找到“关联知识库”选项,点击“选择”,然后选中刚刚创建的本地知识库(比如“儿科医疗问答”),最后点击“完成”。
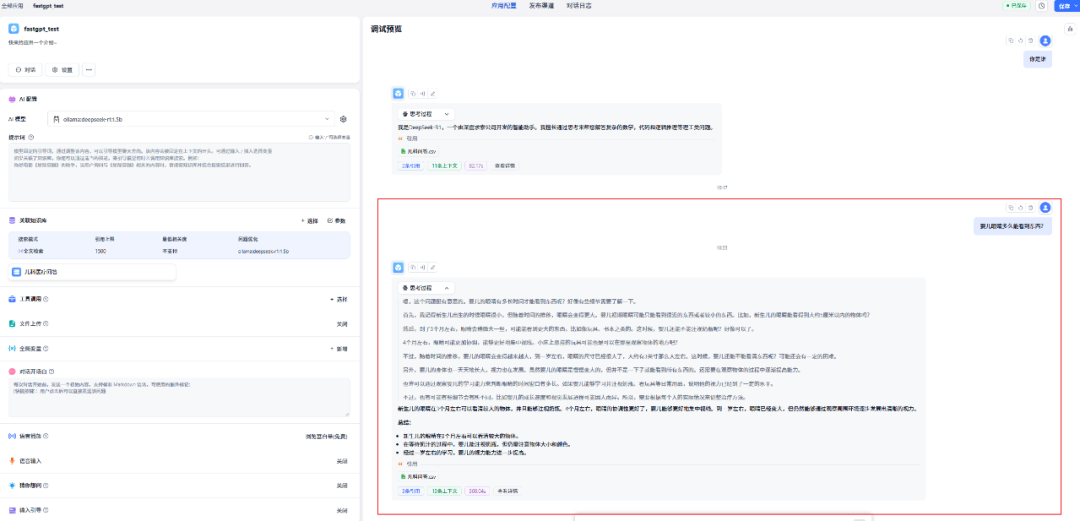
输入一个问题试试效果,比如:“婴儿眼睛多久能看到东西?”系统会给出答案,并显示引用的知识库文档内容,还会提供处理时间和详细信息。
至此,我们已经成功搭建了一个本地知识库,并将其与应用关联起来。
如何零基础入门 / 学习AI大模型?
大模型时代,火爆出圈的LLM大模型让程序员们开始重新评估自己的本领。 “AI会取代那些行业?”“谁的饭碗又将不保了?”等问题热议不断。
不如成为「掌握AI工具的技术人」,毕竟AI时代,谁先尝试,谁就能占得先机!
想正式转到一些新兴的 AI 行业,不仅需要系统的学习AI大模型。同时也要跟已有的技能结合,辅助编程提效,或上手实操应用,增加自己的职场竞争力。
但是LLM相关的内容很多,现在网上的老课程老教材关于LLM又太少。所以现在小白入门就只能靠自学,学习成本和门槛很高
那么我作为一名热心肠的互联网老兵,我意识到有很多经验和知识值得分享给大家,希望可以帮助到更多学习大模型的人!至于能学习到多少就看你的学习毅力和能力了 。我已将重要的AI大模型资料包括AI大模型入门学习思维导图、精品AI大模型学习书籍手册、视频教程、实战学习等录播视频免费分享出来。
这份完整版的大模型 AI 学习资料已经上传优快云,朋友们如果需要可以微信扫描下方优快云官方认证二维码免费领取【保证100%免费】

👉 福利来袭优快云大礼包:《2025最全AI大模型学习资源包》免费分享,安全可点 👈
全套AGI大模型学习大纲+路线
AI大模型时代的学习之旅:从基础到前沿,掌握人工智能的核心技能!

640套AI大模型报告合集
这套包含640份报告的合集,涵盖了AI大模型的理论研究、技术实现、行业应用等多个方面。无论您是科研人员、工程师,还是对AI大模型感兴趣的爱好者,这套报告合集都将为您提供宝贵的信息和启示。




👉学会后的收获:👈
• 基于大模型全栈工程实现(前端、后端、产品经理、设计、数据分析等),通过这门课可获得不同能力;
• 能够利用大模型解决相关实际项目需求: 大数据时代,越来越多的企业和机构需要处理海量数据,利用大模型技术可以更好地处理这些数据,提高数据分析和决策的准确性。因此,掌握大模型应用开发技能,可以让程序员更好地应对实际项目需求;
• 基于大模型和企业数据AI应用开发,实现大模型理论、掌握GPU算力、硬件、LangChain开发框架和项目实战技能, 学会Fine-tuning垂直训练大模型(数据准备、数据蒸馏、大模型部署)一站式掌握;
• 能够完成时下热门大模型垂直领域模型训练能力,提高程序员的编码能力: 大模型应用开发需要掌握机器学习算法、深度学习框架等技术,这些技术的掌握可以提高程序员的编码能力和分析能力,让程序员更加熟练地编写高质量的代码。
👉 福利来袭优快云大礼包:《2025最全AI大模型学习资源包》免费分享,安全可点 👈

这份完整版的大模型 AI 学习资料已经上传优快云,朋友们如果需要可以微信扫描下方优快云官方认证二维码免费领取【保证100%免费】
作为普通人,入局大模型时代需要持续学习和实践,不断提高自己的技能和认知水平,同时也需要有责任感和伦理意识,为人工智能的健康发展贡献力量。

















 2163
2163



 到【灌水乐园】发言
到【灌水乐园】发言








