



踩坑很多次,并且重装多次系统后,含泪记录!!!!
云服务器申请下来,没有NVIDIA驱动,使用nvidia-smi验证。
nvidia-smi
如果未识别命令,那么证明你的系统没有NVIDIA支持的驱动。
查看你服务器支持的NVIDIA驱动版本,查看你的显卡型号就行了,下载驱动的时候需要你的显卡版本。
lspci | grep -i nvidia查看你的Linux版本号、gcc版本以及Ubantu版本。
cat /proc/version
安装NVIDIA驱动
NVIDIA驱动下载地址:GeForce® 驱动程序
进去界面后,按照之前获得的显卡型号、系统版本等填写,填写完成后,点击开始搜索,之后按需下载。
不要禁用nouveau!!!!!!!!!!!!
就是这个禁用,因为原先用的服务器都是实体机并且配备屏幕(有图形界面的那种),所以我依旧哼着小曲,按照收藏的教程一步一步操作,禁用nouveau最后一步要重启reboot,我也是丝毫不犹豫,输入命令按下回车,结果!!!!!!悲剧了,云服务器SSH连接断开了,而且重启之后还是连接不上,最后无奈重装系统才重新连上。
所以也是又学习到了,云服务器不要使用reboot进行重启,会导致数据丢失,或者系统崩溃。
所以在这部分在云服务器上是不用配置的。(至少不要重新启动,或者在控制台进行重启)
因为是云服务器所以也没有图形界面,禁用图形界面的操作也就省略了。
cd到你下载驱动的文件路径
给你下载的NVIDA驱动添加权限:
sudo chmod a+x NVIDIA-Linux-x86_64-525.105.17.run 安装,不需要X校验,不需要安装Opengl
sudo ./NVIDIA-Linux-x86_64-525.105.17.run -no-x-check -no-opengl-files–no-opengl-files 参数必须加否则会循环登录,也就是loop login
安装过程中会出现很多的选项页面,我只列出我遇到的,而且个人建议遇到没有见过的页面,直接去上网查看如何选择。
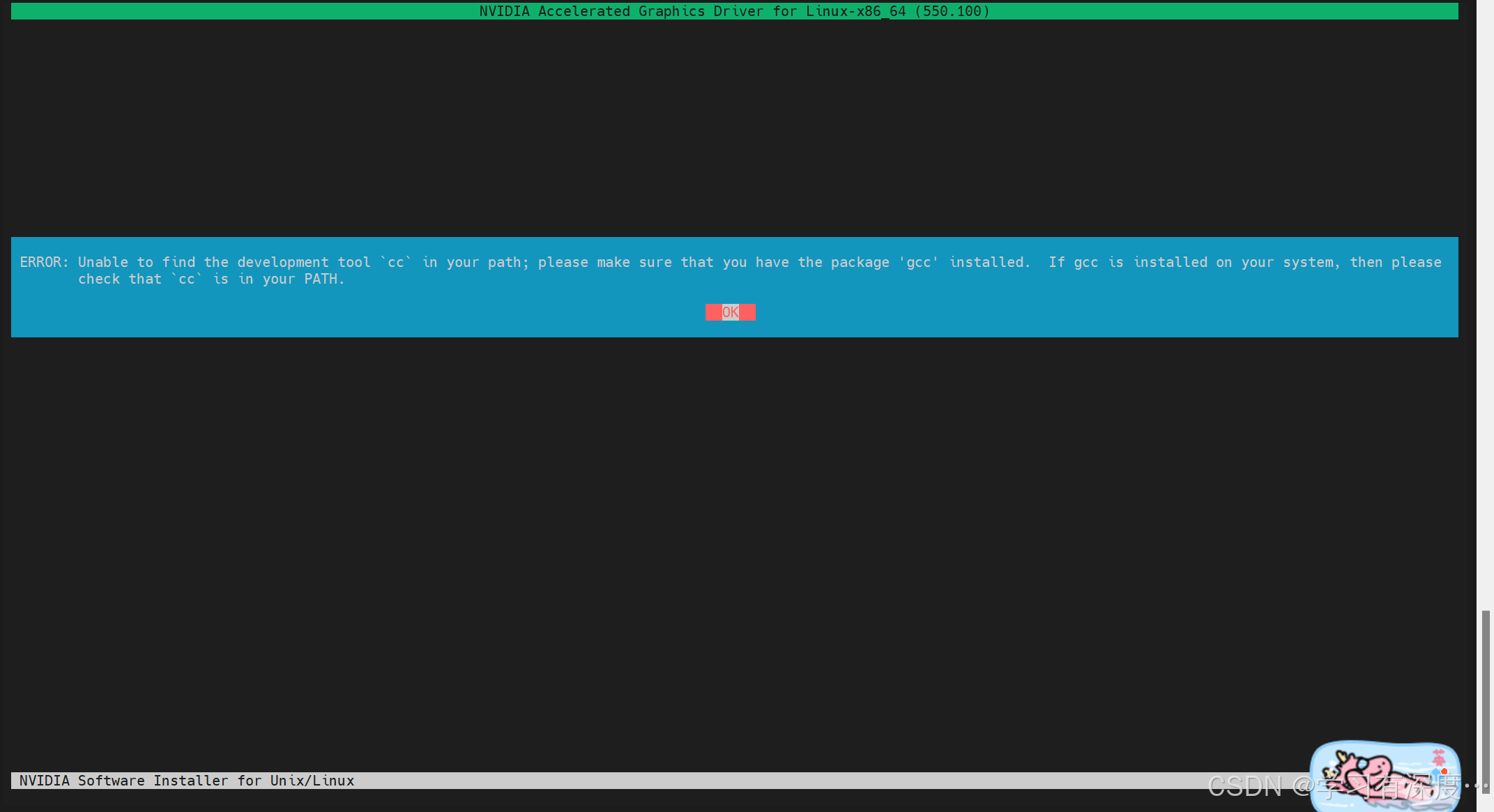
查看GCC是否安装
gcc --version
没有用反应,表示服务器未安装GCC
安装gcc
sudo apt install gcc
继续安装显示了
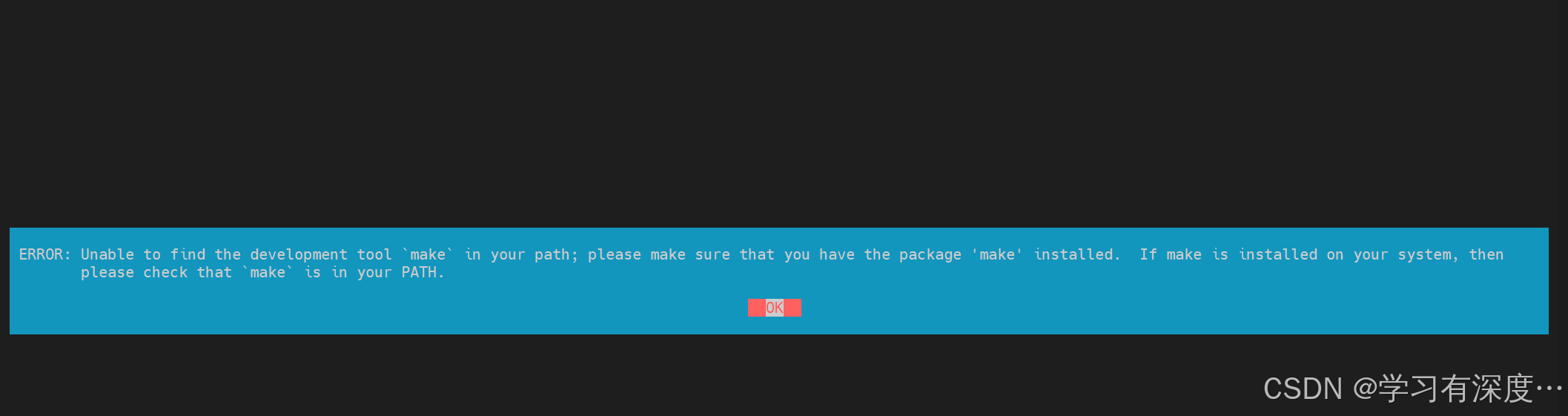
代表未安装make
sudo apt install make继续安装

选择OK

选择NO

选择 Rebuild initramfs

选择Yes

显示安装成功,选择OK
验证安装
nvidia-smi 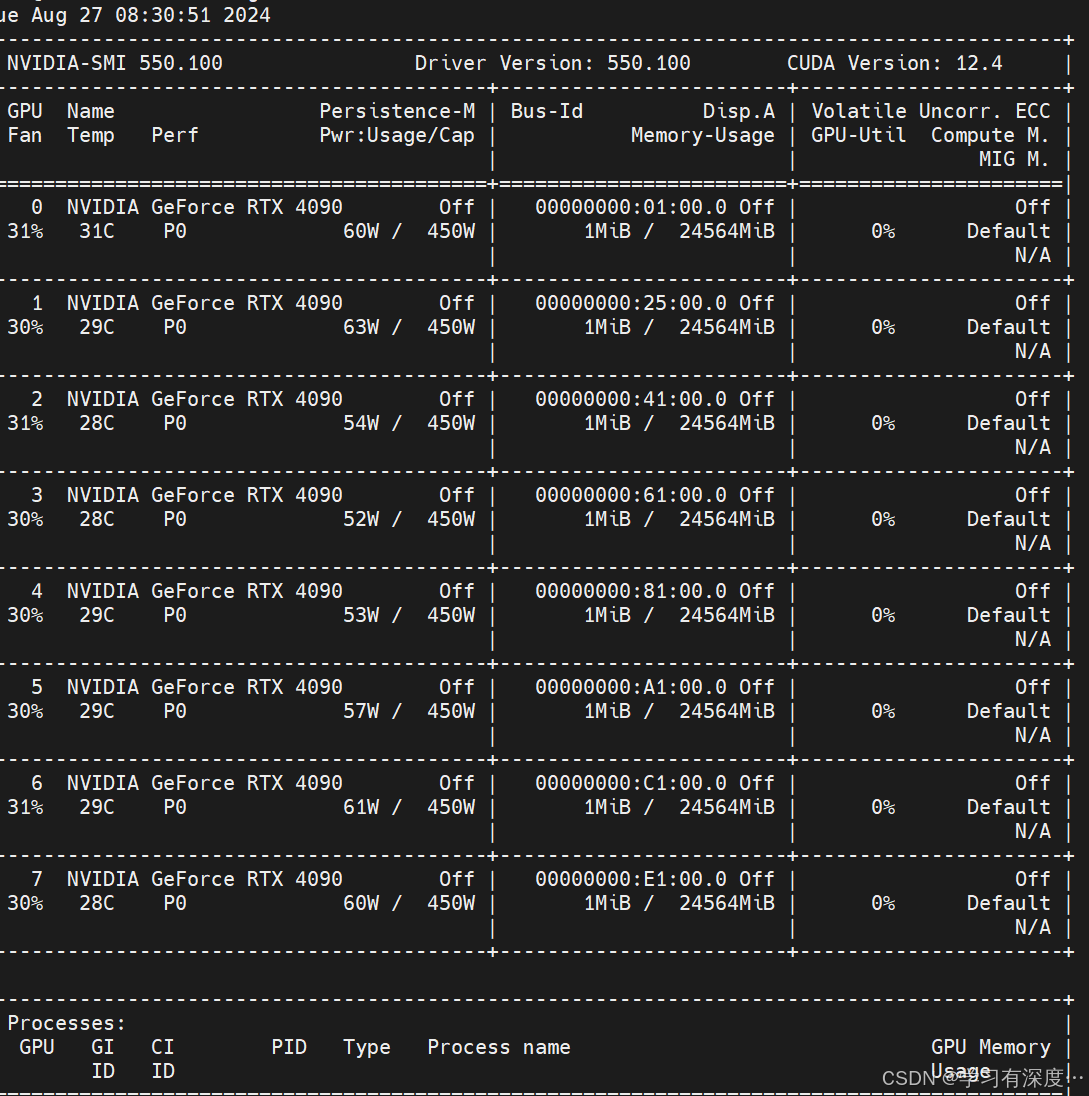
证明安装成功
安装 CUDA
我的项目需要再CUDA11.8环境下运行,所以安装CUDA11.8
进入CUDA官网:CUDA Toolkit Archive
选择你需要的版本,我这里选11.8
跳转到如下界面
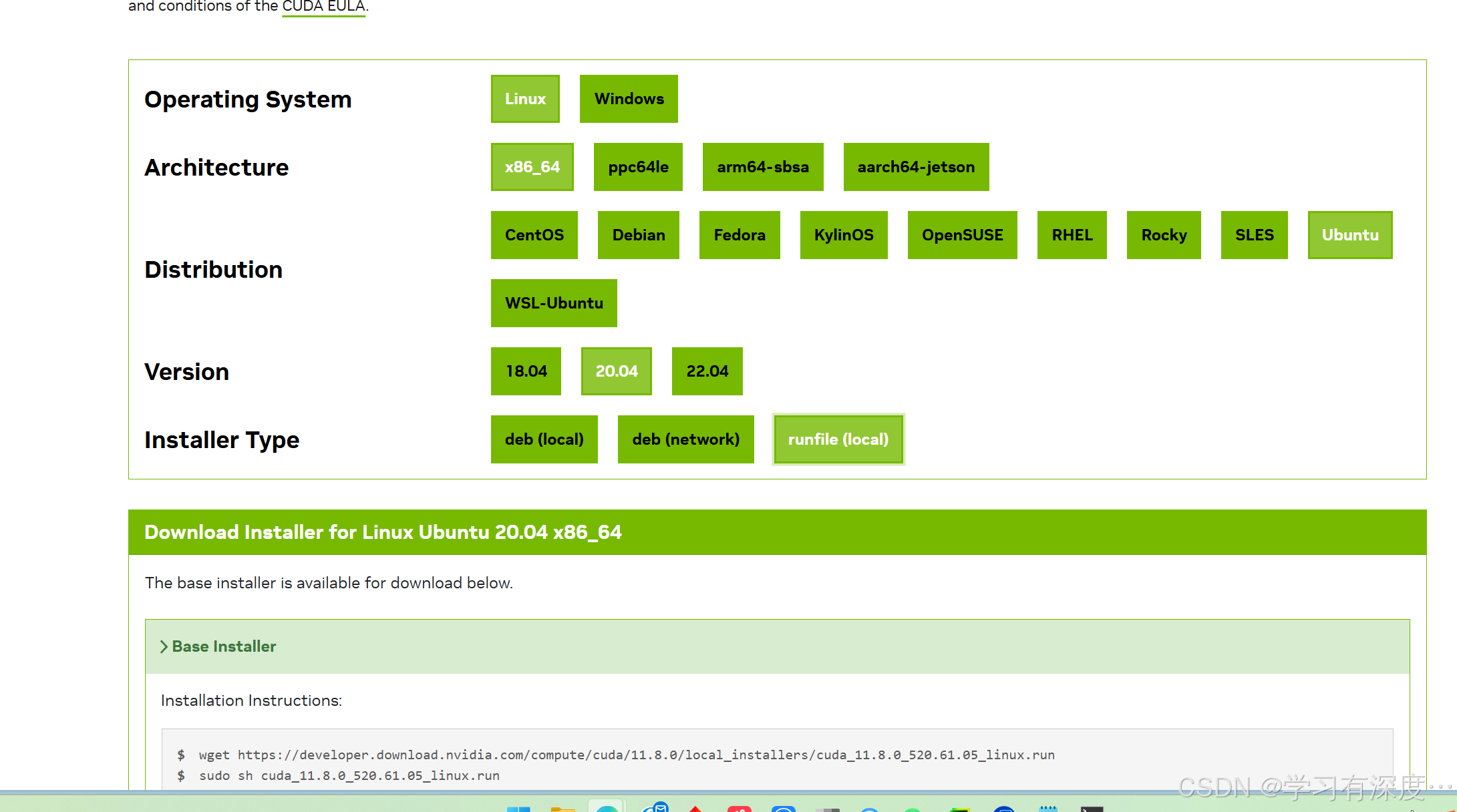
通过他给出的 Installation Instructions进行安装,这个连接的下载速度还是很快的,稍等一下就行可以下载成功。文件比较大,安装成功后可以移除。
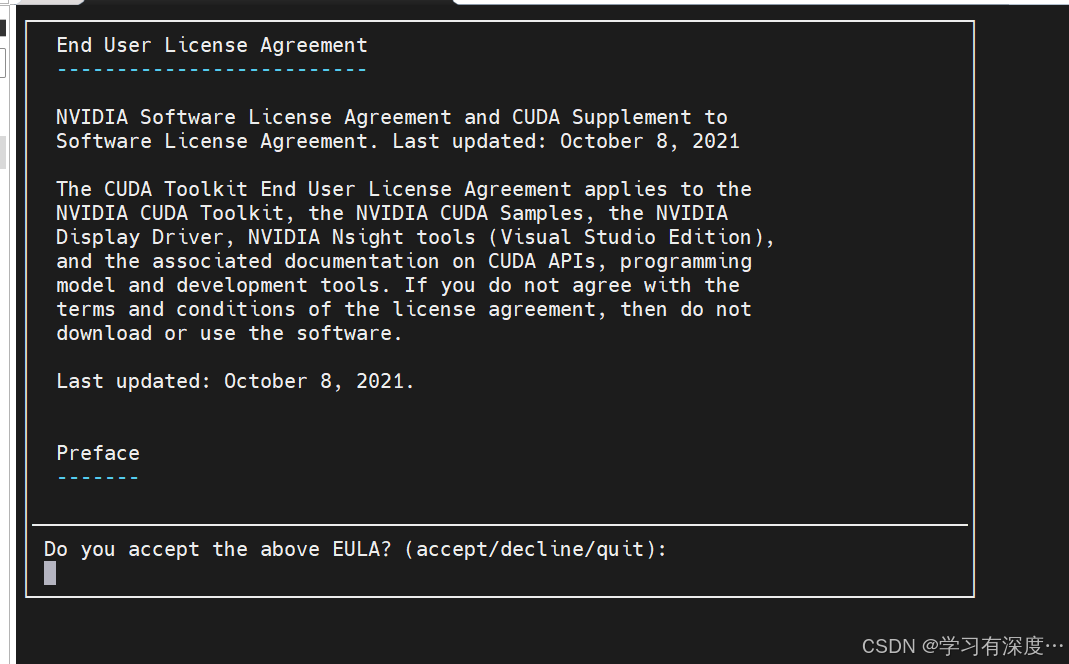
输入accept
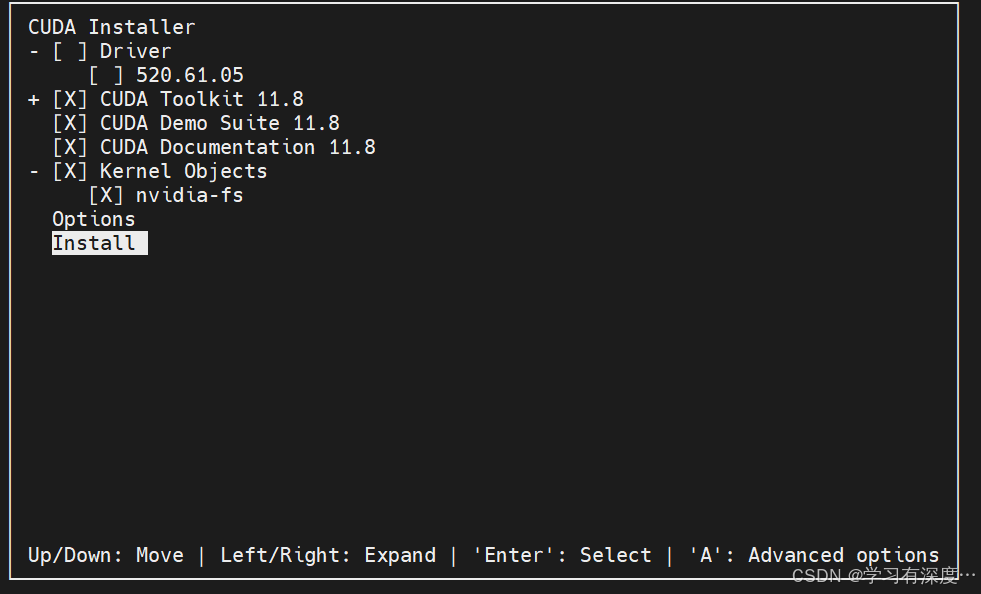
因为已经安装了驱动,所以不选则Driver,选择Install
验证CUDA安装
nvcc -V
未显示CUDA版本

添加系统路径
进入bashrc文件
sudo nano ~/.bashrc 在最后添加
#将下面两行插入到文件末尾
export PATH=/usr/local/cuda-11.8/bin:$PATH
export LD_LIBRARY_PATH=/usr/local/cuda/lib64:$LD_LIBRARY_PATHCtrl+X,按Y,按回车
source ~/.bashrc #更新文件再次验证CUDA安装
nvcc -V 
证明安装成功
安装cudnn
进入cudnn的官网:cuDNN Archive
选择CUDA的对应的版本和系统对应的版本下载
解压下载的文件
tar -xvf cudnn-linux-x86_64-8.9.7.29_cuda11-archive.tar.xz进入文件夹
cd cudnn-linux-x86_64-8.9.7.29_cuda11-archivesudo cp include /usr/local/cuda-11.8/include
sudo cp lib/libcudnn* /usr/local/cuda-11.8/lib64
sudo chmod a+r /usr/local/cuda-11.8/include/cudnn.h /usr/local/cuda-11.8/lib64/libcudnn*
验证是否安装成功
cat /usr/local/cuda-11.8/include/cudnn_version.h | grep CUDNN_MAJOR -A 2

安装成功
Anaconda安装
进入镜像网站下载:Anaconda版本
下载你需要的版本后设置权限
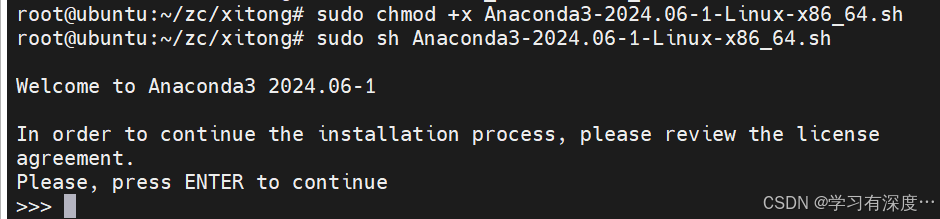
sudo chmod +x Anaconda3-2024.06-1-Linux-x86_64.sh
sudo sh Anaconda3-2024.06-1-Linux-x86_64.sh

输入yes
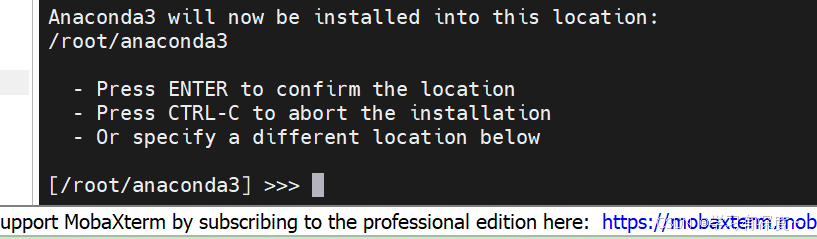
输入回车
输入回车
验证是否安装成功
conda activate
添加系统路径
sudo nano ~/.bashrc
在最后添加
export PATH="$HOME/anaconda3/bin:$PATH"
更新环境
source ~/.bashrc再次验证
conda activate
conda init 
source ~/.bashrc 
成功安装。
至此NVIDIA驱动、CUDA、 cudnn和Anaconda都已安装成功!!!!!!!!!

















 4万+
4万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









