







 本文介绍了常见的机器学习算法,包括支持向量机、Adaboost、决策树、随机森林、逻辑回归、K近邻、K均值、神经网络和马尔科夫链。这些算法在传统机器学习中扮演重要角色,而深度学习算法如经典网络框架(如RCNN、YOLO、SSD、LeNet、GoogLeNet、AlexNet、ResNet等)则代表了现代机器学习的发展方向。
本文介绍了常见的机器学习算法,包括支持向量机、Adaboost、决策树、随机森林、逻辑回归、K近邻、K均值、神经网络和马尔科夫链。这些算法在传统机器学习中扮演重要角色,而深度学习算法如经典网络框架(如RCNN、YOLO、SSD、LeNet、GoogLeNet、AlexNet、ResNet等)则代表了现代机器学习的发展方向。
机器学习发展到今天,大致可以分为以下两大类:传统的机器学习算法和深度学习算法
传统机器学习算法常用的有:(包括但不限于)
参考: https://blog.youkuaiyun.com/jrunw/article/details/79205322
1.SVM(支持向量机support vector machine)
要将两类分开,想要得到一个超平面,最优的超平面是到两类的 margin 达到最大,margin就是超平面与离它最近一点的距离;它主要应用于二分类问题,通过定位两类数据在几何空间中的边缘,来确定分类器。恰好能“最好地”将两类数据分开,这样的超平面(或曲面)就是SVM分类器。
这样的超平面在两类数据之间,同时应该具备如下两个条件:
- 最近距离最远:两类数据中,每类数据都有一个点距离该超平面的距离是最近的,而“最好的”超平面要这个两个最近距离的和尽可能的远;
- 等距:超平面距离两类数据最近的点的距离是相等的;
2.Adaboost(级联算法)
级联增强就是把若干个分类效果并不好的分类器综合起来考虑,会得到一个效果比较好的分类器。
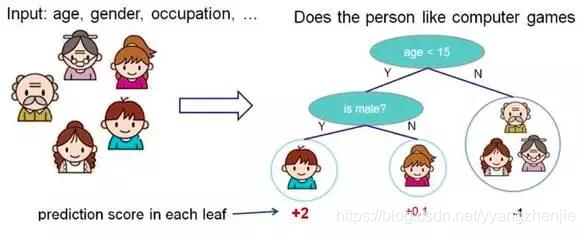
3.决策树
根据一些 feature 进行分类,每个节点提一个问题,通过判断,将数据分为两类,再继续提问。这些问题是根据已有数据学习出来的,再投入新数据的时候,就可以根据这棵树上的问题,将数据划分到合适的叶子上。
4.随机森林
在源数据中随机选取数据,组成几个子集,S 矩阵是源数据,有 1-N 条数据,A B C 是feature,最后一列C是类别,由 S 随机生成 M 个子矩阵,这 M 个子集得到 M 个决策树。
将新数据投入到这 M 个树中,得到 M 个分类结果,计数看预测成哪一类的数目最多,就将此类别作为最后的预测结果成 M 个子矩阵。
5.逻辑回归
当预测目标是概率这样的,值域需要满足大于等于0,小于等于1的,这个时候单纯的线性模型是做不到的,因为在定义域不在某个范围之内时,值域也超出了规定区间。
这个模型需要满足两个条件 大于等于0,小于等于1
大于等于0 的模型可以选择 绝对值,平方值,这里用 指数函数,也一定大于0
小于等于1 用除法,分子是自己,分母是自身加上1,那一定是小于1的了

 转存失败重新上传取消
转存失败重新上传取消 转存失败重新上传取消转存失败重新上传取消
转存失败重新上传取消转存失败重新上传取消
再做一下变形,就得到了 logistic regression 模型

 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章

















 1556
1556

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









