



最近有朋友说,想转行ai赛道,做大模型之类的工作,不知道有哪些岗位。今天就来聊聊,AI大模型有哪些方向,新人怎么转行大模型赛道,让大家少走弯路,早日在AI领域如鱼得水!
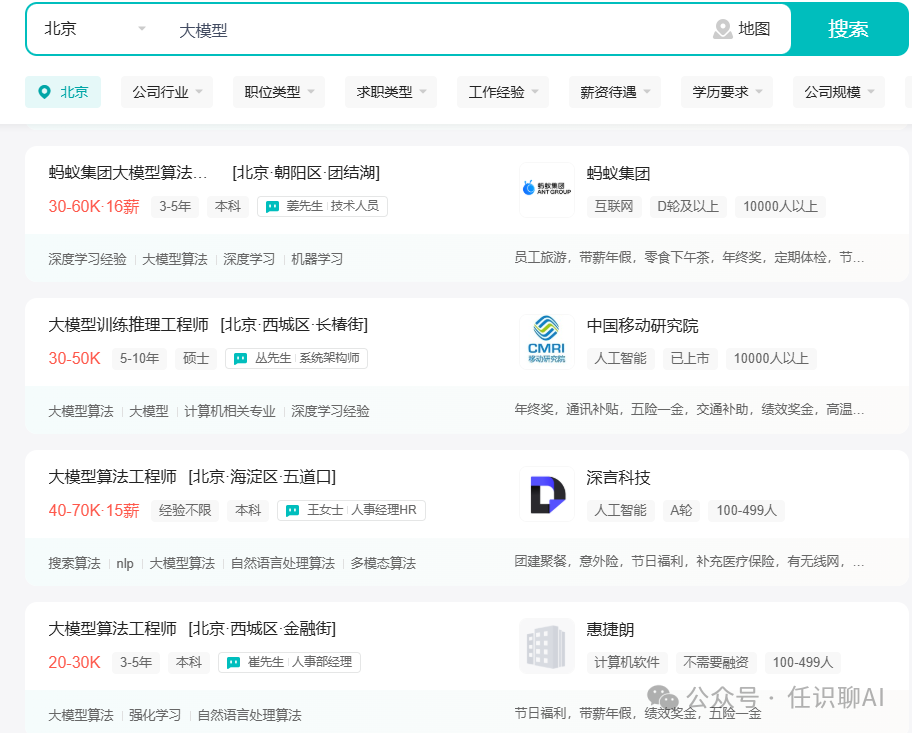
其实,在招聘网站上搜搜 “大模型”,看看那些招聘要求,就能大概了解大模型工程师都有哪些方向了。主要分为下面这四类:
-
数据治理方向:大模型数据工程师,主要负责爬虫、数据清洗、ETL、Data Engine、Pipeline 这些工作。简单说,就是要把数据整理得妥妥当当,让模型能 “吃” 得好。
-
平台搭建方向:大模型平台工程师,负责分布式训练、大模型集群以及工程基建等。他们就像是大模型的 “建筑工人”,打造出能让模型高效运行的平台。
-
模型算法方向:大模型算法工程师,主要涉及搜、广、推、对话机器人、AIGC 这些领域。听起来是不是超酷,一听能做出很厉害的产品!
-
部署落地方向:大模型部署工程师,负责推理加速、跨平台、端智能、嵌入式这些工作。他们要确保模型能顺利在各种设备上运行起来。
下面分别对这四个方向的工作内容进行展开。
1、数据治理 —— 被轻视的宝藏领域
很多人可能觉得自己学了好多算法知识,再去做数据工作有点大材小用了。其实不然!对于很多转行大模型的同学来说,做数据可是更容易上岸的途径呢!
现在国外的大模型技术比国内领先不少,虽然国内有很多 “大模型”,但真正厉害的没几个。为啥呢?除了一些技术没突破,数据和工程技巧也很关键。
就拿数据来说,通用大模型训练的数据来源、采集、质量把控、有毒信息过滤、语言筛选与比例、去重和规范化处理,还有评测集构建,这些都是技术活,也是体力活。
在垂直领域,像金融、电商、法律、车企这些,数据构建更难了。业务数据从哪来?数据不够怎么办?怎么构建高质量微调数据?要是能把这些问题解决好,模型就成功一大半啦!所以现在有经验又有能力的数据工程师是比较稀缺的。
2、平台搭建——保障高性能计算
要是你以前是做工程的,或者对工程感兴趣,那大模型平台工程师这个方向很适合你。
这个方向其实就是为大模型业务服务的,打造大模型的基础设施,让模型训练得更好、跑得更快,有分布式计算、并行计算,总之就是保障高性能计算。
具体都做些啥呢?
-
硬件层面,要搞大模型训练集群,像 GPU 集群、CPU/GPU 混部集群,得管理好几百上千张卡,还要关注它们的利用率和健康状况。中小公司通常开发和运维都得干。
-
平台层面,要做 LLMOps,也就是 pipeline,把数据 IO、模型训练、预测、上线、监控都整合起来,跟着业务团队走,造些好用的工具,给业务团队省时间。
3、模型算法——传说中的算法工程师
好多小伙伴一看到大模型算法岗,可能立马就被吸引了,觉得能做出超厉害的产品,站在行业前沿。
但是,在 AI 这行,模型算法应用是很需要业务经验的。如果你本来就是做算法相关的,比如 NLP、语音助手或者对话机器人,那继续做这个方向的大模型算法工程师是合适的。
但如果你是 CS 方向的实习生、应届毕业生,或者其他 IT 行业转过来的,这不一定是最好的选择。
别以为大模型算法工程师就是调调模型、改改超参、做做预训练和 finetune 这些简单活儿。实际上,一个团队里干这些核心算法优化的没几个人,大部分新人进去都是先干些配环境、搭链路、清洗和分析数据、调研、写函数工具这些基础工作。
等这些干熟练了,才有可能跑些模型实验,表现好的同学才有机会接触线上业务。有些同学干了好几年,还在做些边角料的活儿,根本接触不到核心业务呢!
所以刚入行的小伙伴,如果学历背景好,可以去大公司实习争取转正;背景一般的话,去中小公司积累业务经验也是不错的。
4、部署落地——实现AI价值最后一公里
大模型部署主要有两个方向:云端部署和端侧部署。
-
云端部署,可以做推理加速平台,给特定模型做定制化加速,像 Qwen - 7b 的加速,也可以做大模型推理引擎,在高并发用户场景下,保证用户体验的同时优化延迟和吞吐量。
-
端侧部署,就是要在消费级 GPU/NPU 和边端设备上把模型部署好,还要让领域大模型小型化,实现工程落地。
这个岗位对工程、系统和硬件方面的能力都有要求,虽然现在有各种推理框架降低了点难度,但还是挺有挑战性的,不太建议新人直接做,可以先从平台方向入手,再慢慢转到部署方向。
最后,给新人的一些小建议
-
别光盯着 finetune、SFT、RLHF 这些,虽然系统学习是必要的,但不需要花太多精力哦。
-
想做应用方向的小伙伴,建议聚焦在某个垂直领域,比如对话机器人、问答系统,或者金融、医疗、教育这些方向,选一个具体场景好好做,做深做透。
-
一定要多关注数据,像 data pipeline,高质量训练 / 测试集的构建经验,还有对数据的敏感度,这些在未来工作中非常有用。
-
记住,大模型不只有算法,工程也很重要。大公司都在拼基建,好的平台对业务支撑作用可大了,是大模型产品成功的关键因素!
好啦,小伙伴们,希望这些能对你们入行大模型有所帮助,祝大家都能在这个领域发光发热!
那么,如何系统的去学习大模型LLM?
我在一线互联网企业工作十余年里,指导过不少同行后辈。帮助很多人得到了学习和成长。
作为一名热心肠的互联网老兵,我意识到有很多经验和知识值得分享给大家,也可以通过我们的能力和经验解答大家在大模型的学习中的很多困惑,所以在工作繁忙的情况下还是坚持各种整理和分享。
但苦于知识传播途径有限,很多互联网行业朋友无法获得正确的资料得到学习提升,故此将并将重要的AI大模型资料包括AI大模型入门学习思维导图、精品AI大模型学习书籍手册、视频教程、实战学习等录播视频免费分享出来。
所有资料 ⚡️ ,朋友们如果有需要全套 《AI大模型入门+进阶学习资源包**》,扫码获取~

篇幅有限,部分资料如下:
👉LLM大模型学习指南+路线汇总👈
💥大模型入门要点,扫盲必看!

💥既然要系统的学习大模型,那么学习路线是必不可少的,这份路线能帮助你快速梳理知识,形成自己的体系。
路线图很大就不一一展示了 (文末领取)

👉大模型入门实战训练👈
💥光学理论是没用的,要学会跟着一起做,要动手实操,才能将自己的所学运用到实际当中去,这时候可以搞点实战案例来学习。

👉国内企业大模型落地应用案例👈
💥两本《中国大模型落地应用案例集》 收录了近两年151个优秀的大模型落地应用案例,这些案例覆盖了金融、医疗、教育、交通、制造等众多领域,无论是对于大模型技术的研究者,还是对于希望了解大模型技术在实际业务中如何应用的业内人士,都具有很高的参考价值。 (文末领取)

👉GitHub海量高星开源项目👈
💥收集整理了海量的开源项目,地址、代码、文档等等全都下载共享给大家一起学习!

👉LLM大模型学习视频👈
💥观看零基础学习书籍和视频,看书籍和视频学习是最快捷也是最有效果的方式,跟着视频中老师的思路,从基础到深入,还是很容易入门的。 (文末领取)

👉640份大模型行业报告(持续更新)👈
💥包含640份报告的合集,涵盖了AI大模型的理论研究、技术实现、行业应用等多个方面。无论您是科研人员、工程师,还是对AI大模型感兴趣的爱好者,这套报告合集都将为您提供宝贵的信息和启示。

👉获取方式:
这份完整版的大模型 LLM 学习资料已经上传优快云,朋友们如果需要可以微信扫描下方优快云官方认证二维码免费领取【保证100%免费】
😝有需要的小伙伴,可以Vx扫描下方二维码免费领取🆓

















 1069
1069

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









