










25年2月来自上海AI实验室、上海交大、香港中文大学和香港生成AI研发中心(HKGAI)的论文“Exploring the Limit of Outcome Reward for Learning Mathematical Reasoning”。
推理能力,特别是解决复杂数学问题的能力,是通用智能的重要组成部分。 OpenAI 的 o 系列模型,在推理任务上取得了令人瞩目的进展。然而,完整的技术细节仍未披露,人们认为肯定会采用的技术只有强化学习 (RL) 和长链思维。本文提出一种 RL 框架,称为 OREAL,追求通过基于结果奖励的强化学习在数学推理任务中可以达到的性能极限,其中只有二元结果奖励易于获取。从理论上证明,从N-中-最佳 (BoN) 采样正轨迹上的行为克隆,足以学习二元反馈环境中的 KL 正则化最优策略。该公式进一步说明应该重塑负样本的奖励,以确保正样本和负样本之间的梯度一致性。为了缓解强化学习中奖励稀疏带来的长期困难,(推理任务长思维链(CoT)的部分正确性会进一步加剧这个困难),所以本文进一步应用 token-级奖励模型来采样推理轨迹中的重要 token 进行学习。在 OREAL 中,7B 模型首次通过强化学习在 MATH-500 上获得 94.0 pass@1 的准确率,与 32B 模型持平。OREAL-32B 还超越之前通过蒸馏训练的 32B 模型,在 MATH-500 上获得 95.0 pass@1 的准确率。
用推理能力解决复杂问题是人类认知的基石之一,也是通用人工智能最终必须掌握的认知能力 [1, 2]。在各种问题领域中,数学问题成为人工智能研究特别引人注目的实验范式 [3–6],因为它具有相对明确的结构,并且可以根据可验证的最终答案提供精确的二进制正确性反馈。
大语言模型 (LLM) 的最新进展,通过思维链技术在数学推理方面取得了显著进展 [7–9],其中 LLM 抽出以产生一系列中间推理步骤,然后提供问题的最终答案。然而,由于大多数有能力的模型(例如 OpenAI 的 o 系列模型 [10])都是由专有公司开发的,因此没有明确的途径来开发最先进的推理模型。
使用思维链激发推理。在数学推理任务中,思维链 (CoT) [7] 被认为是增强大语言模型 (LLM) 推理能力的关键技术,可以通过少样本示例 [7] 或零样本提示工程 [9] 来实现。自洽性 (SC) [8] 被进一步提出来通过多个 CoT 生成和投票。除了简单的 CoT 之外,人们还探索各种同时考虑多个潜在 CoT 的搜索方法,例如思维树 (ToT) [51] 和思维图 (GoT) [52],它们将思维扩展到树或图结构,为开发 CoT 和回溯提供更大的灵活性。然而,这些方法主要通过提示来刺激 LLM 的推理能力,而没有参数更新,这些推理-时间技术并没有从根本上提高 LLM 的底层能力。
通过监督微调增强推理能力。为了让 LLM 真正获得推理能力,许多研究 [5, 53–57] 探索合成高质量数据以对 LLM 进行监督微调 (SFT)。但这种方法严重依赖于高质量的训练数据和现有的高性能模型 [15]。因此,许多现有研究 [11, 12] 已转向从强大的大模型中提取知识来合成数据,并取得良好的效果。然而,基于提取的方法受到教师模型的局限性。对 SFT 的一个批评是其有限的泛化能力 [58]。一些研究认为,SFT 只是将模型转变为知识检索器,而不是真正的推理器 [59]。
LLM 的强化学习。与 SFT 相比,强化学习 (RL) 提供更好的泛化能力,因此被认为是一种更基本的训练方法 [58]。之前将 RL 应用于 LLM 的尝试主要旨在使 LLM 与人类偏好保持一致 [27]。后来,一些研究 [5, 6, 15, 60] 尝试利用它来增强模型的推理能力,并获得不错的结果。最近,o1 模型系列 [10] 的出现以及一系列类似 o1 的研究 [13, 20, 44, 45] 使得大规模强化学习对于推理的重要性更加明显。目前,强化学习的主流方法涉及使用结果奖励信号 [13, 18, 44],而对于如何使用该奖励信号,社区中存在不同的看法。ReSTEM [61] 和 RFT [23] 只是根据二值信号选择正样本,并仅将其用于行为克隆。GRPO [6]、RLOO [35, 62]、REINFORCE [50] 同时使用正样本和负样本进行策略更新,但面临长序列中奖励稀疏的挑战。PPO [19] 在序列级进行偏好建模。
现有的方法试图通过搜索[17,18]或基于价值函数的信用分配[19,20]来估计推理步骤的优势或价值,但与蒸馏模型[13]相比,它们的性能仍然不令人满意。
本文旨在克服上述挑战,并提出一个简单的框架,称为 OREAL,以突破基于结果奖励的强化学习在数学推理任务中的极限。OREAL 以数学推理任务的独特特征为基础,即二元结果反馈创造一个所有正向轨迹都同样有效的环境。
当采用大语言模型(LLM)进行数学推理时,LLM 策略的输入是一个文本数学问题,促使 LLM 输出由多个 token 作为动作组成的多步推理轨迹。在 RL 训练期间,常见的做法 [6, 23] 是对 LLM 进行采样以产生多个推理轨迹,仅根据其最终答案的正确性分配二元反馈(0/1 奖励),并使用带有奖励的采样轨迹进行相应的策略优化。
策略优化。考虑由元组 (S, A, P, r, γ) 定义的马尔可夫决策过程 (MDP),其中 S 是有限状态空间(例如,数学推理中的上下文步骤),A 是动作空间(即 LLM 的token空间),P (s′ |s, a) 指定状态转换动态,r : S × A → R 是奖励函数,γ ∈ [0, 1) 表示折扣因子。
KL 正则化的策略优化,最大化预期累积回报,同时将策略 π_θ(·|s) 正则化为一个参考策略 π_0(·|s)。目标函数公式为:
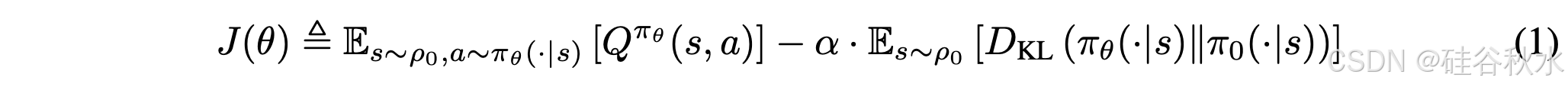
使用原始策略 π 下状态-动作的价值函数 Q_π(s, a):
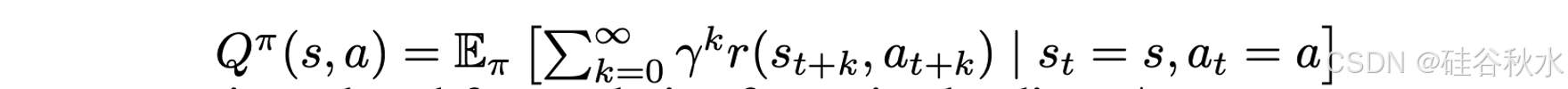
此目标承认最优策略 π∗ 的闭式解:
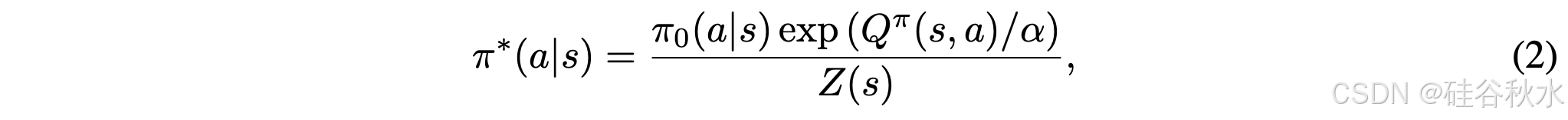
其中 Z (s) 是确保正则化的分区函数:
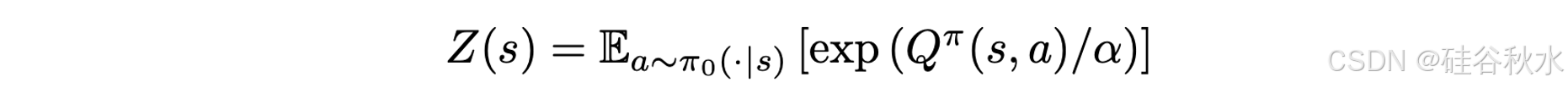
N -中-最佳 (BoN) 采样。作为从 LLM 中采样多个推理轨迹常见且有效的策略,N- 中-最佳采样从 π_0 的 n 个独立展开中选择具有最大奖励的轨迹以增强策略性能。正式地,给定候选动作 {a(i)} ∼ π_0(·|s),所选动作为 a∗ = arg max_a(i) Q(s, a^(i))。该策略通过并行采样有效地利用探索-开发的权衡 [24, 25]。
结果监督下的二元反馈。虽然推理轨迹通常包含多个推理步骤和数千个 token,但在数学推理任务中,缺乏一种有效的方法来自动标记每个 token 或推理步骤的正确性。因此,一种实用的方法是从推理轨迹中解析出最终答案 [13, 26],根据规则或模型评估其正确性,然后在轨迹结束时提供结果奖励,如下所示:
R(s_t) = {1, 0},如果 t 是结束步骤并且答案正确,其为 1,否则为 0。
其将正确的轨迹平等地用于学习。此外,与数千个 token 相比,奖励信号非常稀疏,并且不提供任何进展信号或中间步骤的正确性。由此产生的轨迹奖励分布,也不同于传统 RL 中通过偏好对为大语言模型构建的密集奖励函数 [27],这为数学推理任务如下引入一个更合适的优化框架。
正样本的学习
基于上述结果奖励的等价原理,首先形式化 BoN 采样的一个关键概率特征:
引理 1. 令 π(θ, s) 为参数 θ 和轨迹 s 的分布,其中每个 s 与二元奖励 R(s) ∈ {0, 1} 相关联。定义 p ≜ E_s∼π(θ,·)[R(s) = 1] > 0。考虑 BoN 采样:n = n_0 → ∞ 并从 π_θ 中独立同分布地采样 {s_1, s_2, . . . , s_n}。BoN 从 R(s_i) = 1 的子集中均匀地选择 s^∗。选择 s^∗ 的概率收敛到 π(θ,s)/p,独立于 n 。
其证明直接来自 BoN 采样的联合定律 (BoN_n+m = BoN_2(BoN_m, BoN_n)) 和 0 − 1 奖励的可区分性。该结果表明,对于可获得正响应的问题,用具有任意采样预算的 BoN 生成器来构建正训练样本。
为了量化 BoN 采样引起的分布差异,先前的研究 [28–30] 分析 BoN 分布 π_BoN 与原始策略 π 之间的 KL 差异。对于连续轨迹空间 S,BoN 分布具有显式形式:
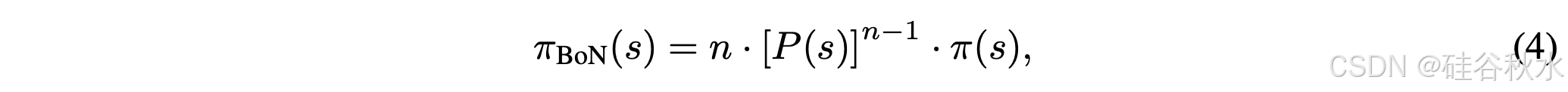
其中 P(s) 表示与 π(s) 相关的累积分布函数 (CDF)。相应的 KL 散度由以下公式给出
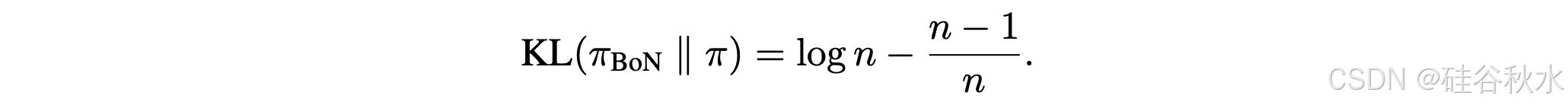
BoN [31] 经验表明,BoN 抽样通过对正样本进行穷举搜索,在固定 KL 约束下实现最佳胜率。因此,对 BoN 选择的正样本进行行为克隆直接学习目标函数(1)的解析解。直观地说,由于每个正确答案在结果监督意义上的偏好相同,只需要抽样直到得到一个正样本,其生成概率分布将与从任意大量样本中随机抽取的概率分布相同。
基于已建立的理论理解,将 KL 约束的最大似然目标纳入通过抽样获得的正样本中,可制定 OREAL 中学习目标的第一个组成部分:
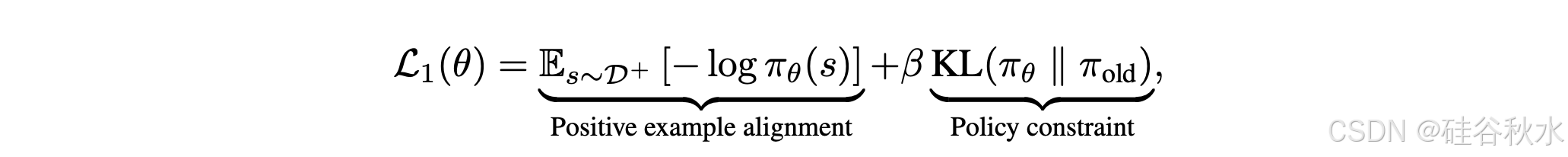
负样本的学习
虽然 BoN 分布公式(4)与 最优策略公式(2)在结构上相似,但将其应用于具有二元反馈的数学推理任务需要重新表述。具体而言,变换后的 BoN 分布可以表示为
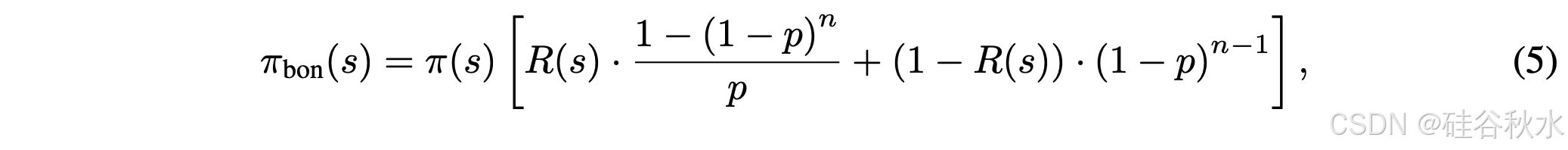
这揭示 BoN 分布与原始采样分布之间的根本区别。考虑这样一种情况,即采样两个正确解决方案和两个错误解决方案,得出的经验准确率为 50%。然而,在 Best-of-4 下选择负样本的概率变为 (0.5)^4 = 6.25%,明显低于原始分布。这种差异需要奖励塑造,以保持优化目标与 BoN 分布下预期回报之间的一致性。
基于 BoN-RLB [34] 对 BoN 感知策略梯度的对数似然技巧的应用,分析负样本的奖励塑造技术,以保持梯度一致性。期望回报 p 遵循引理 1 中的定义。BoN 分布下的策略梯度可以推导出为
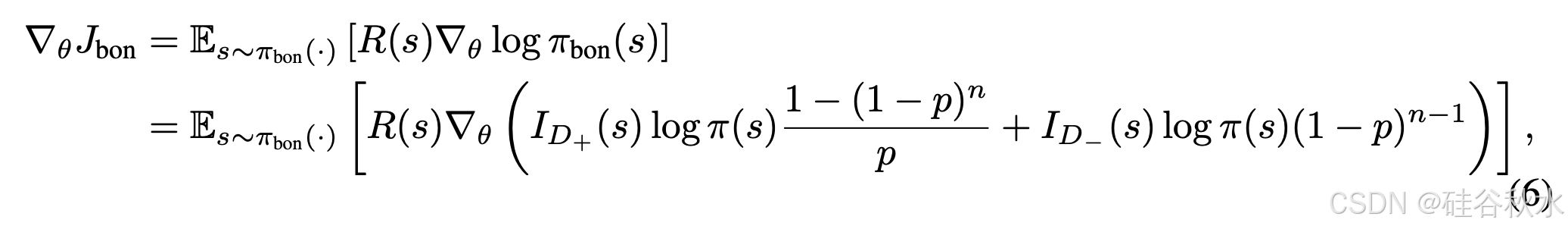
给定 E_s∼π_bon [ID+ (s)] = 1 − (1 − p)^n,推导梯度分量如下
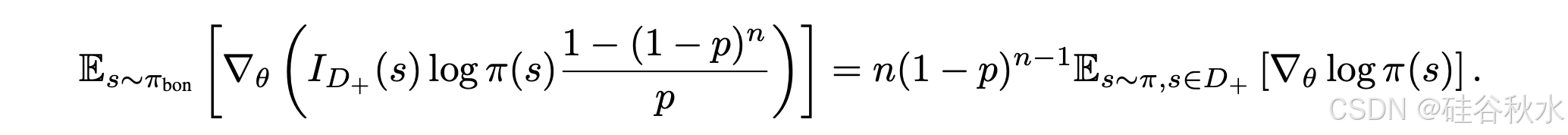
这个推导表明,当奖励(R(s) = 1)分配给正样本时,梯度一致性需要将负样本奖励重塑为 R^⋆(s) ≜ (1 − p)R(s)。基于这种奖励塑造,可以在正样本和负样本上构建策略优化,以获得最优策略。
为了获得可与蒙特卡罗 (MC) 优势估计相关联的参数 1 − p,可以通过计算少量响应来计算样本空间的预期准确度,从而简单地估计该概率。应用与 RLOO [35] 类似的设置,即
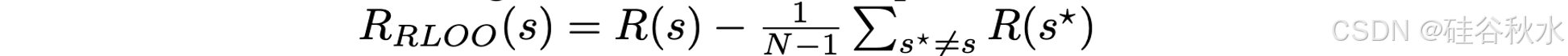
获得无偏平均奖励并使用策略梯度进行训练。这样 OREAL 学习目标的第二部分如下:
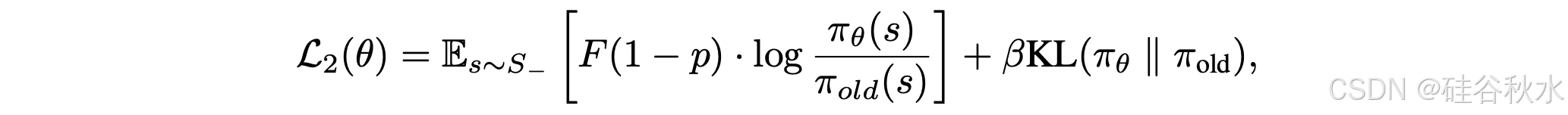
处理长推理链
由于前面结果监督仅在序列级别提供反馈,因此这种建模本质上会简化为上下文强盗,而 MDP 中没有内部奖励建模。一个常见的反例是 PPO,它利用单独的批评模型来估计价值函数。然而,这样的解决方案似乎既昂贵又复杂,这引发了关于如何稳定 PPO 训练的大量探索。
在数学推理中,情况略有不同,模型可以自发地修改中间步骤中的遗漏以获得正确的最终答案。因此,结果监督是首选,价值函数更像是一个简单的信用分配,以确定流程步骤对结果奖励的贡献程度。考虑到效率和性能权衡,选择使用一些低成本的替代方案进行序列级重新加权。
考虑到数学推理中的确定性动态(s_t+1 = f(s_t, a_t)),状态动作函数 Q^π(s_<t, π(s_t)) 简化为策略 π 的累积折扣奖励:
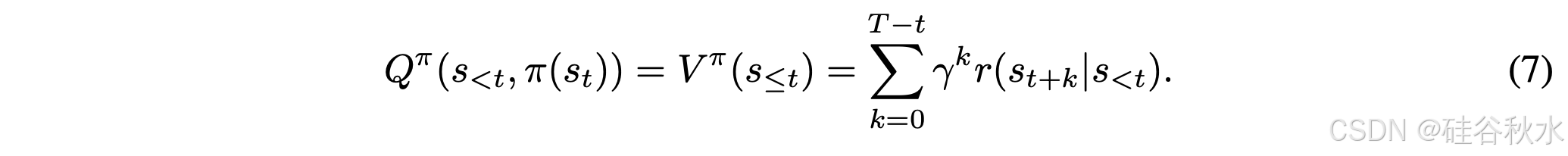
由于数学推理任务不提供中间奖励,故仅根据结果反馈定义一个优势函数:
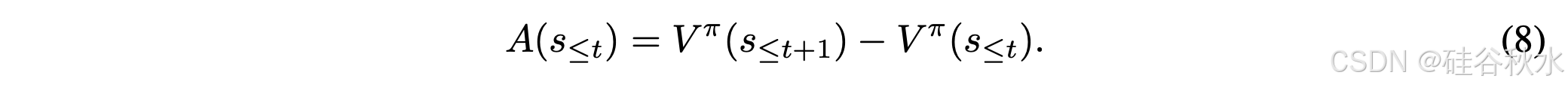
该公式将 A(s_≤t) 视为一种基于 token 的信用分配机制,估计每个 token 对最终结果的贡献。
对于同一查询的一对响应 y_1 和 y_2,它们的初始值保持一致 V1_0 = V^2_0。它们之间的胜率满足:
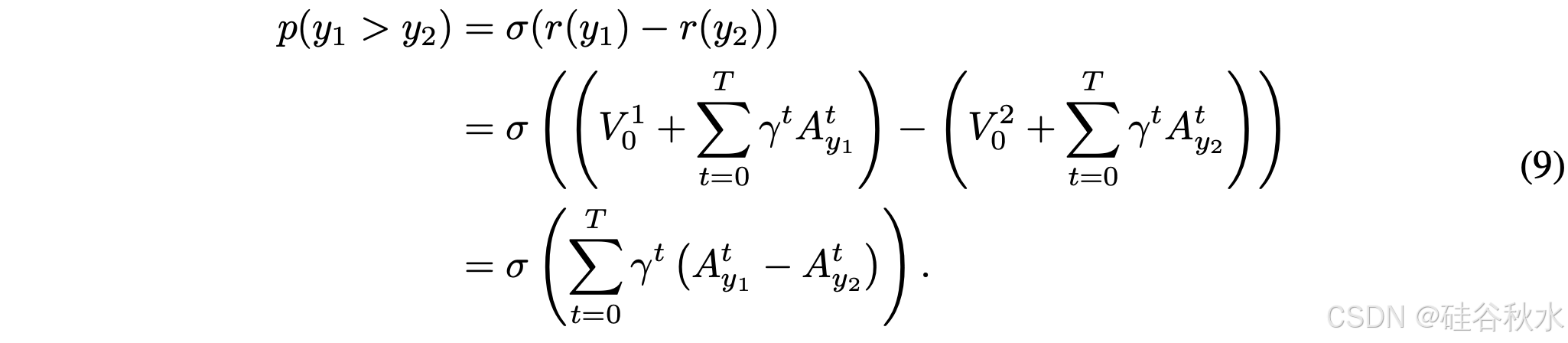
该公式表明,对于任何函数族 A = {A(s_≤t)},都可以通过序列聚合构建累积奖励函数来模拟奖励:
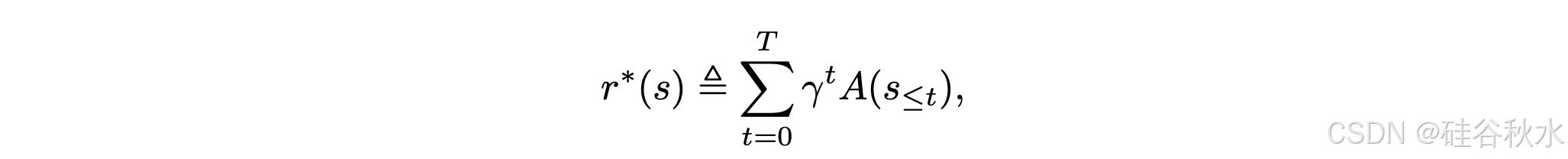
通过拟合结果反馈,可以通过偏好对{(y_w,y_l)}进行训练。学习的A(s_≤t)作为信用分配的加权函数,用于重加权原始训练损失,强调关键推理步骤或错误。一个类似的实现是r2Q∗ [36,37],通过定义A = log π(y_i)/π_ref(y_i),PRIME [20] 应用此公式来提高RLOO的性能。遵循[38]中的做法,本文直接训练一个token级的奖励函数,其满足
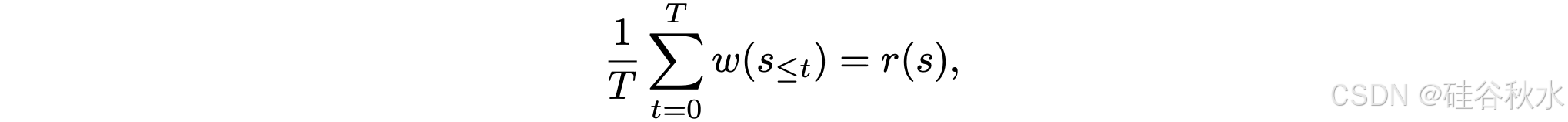
在奖励模型训练中,无需将 KL 散度限制在参考模型上。这些连续的奖励,可以作为思考步骤对结果准确率贡献的智体。假设一对前缀一致的正确和错误样本,由于 token 级奖励模型的因果推理性质,对这些样本的偏好优化将只作用于具有不同内容的步骤,从而对影响最终结果的核心推理步骤,产生更高的信用。
在实践中,分解正样本和负样本的输出权重 w(s),并在正轴上进行裁剪,以防止反转优化梯度的方向,表示为 ω+ 和 ω^−:
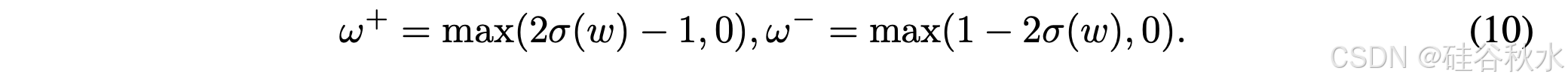
这样,给定输入查询 d,总体损失如下:
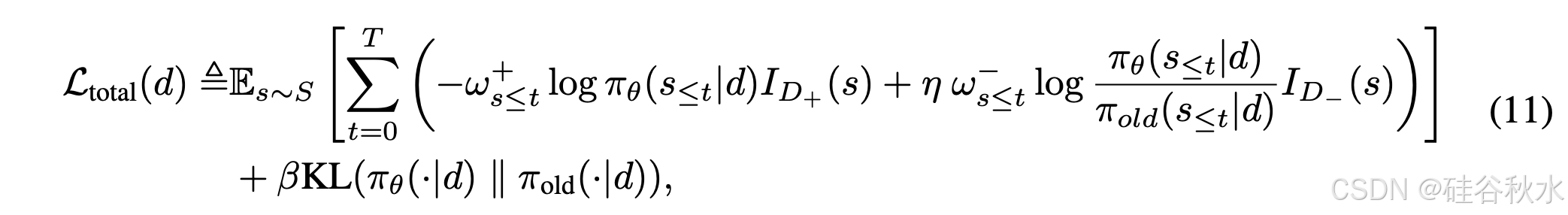
策略初始化
用 Qwen2.5-7B 和 Qwen2.5-32B [39] 作为基础模型。最初,使用通过拒绝采样获得的长链思维数据对基础模型进行微调 [23]。然后,此拒绝采样微调 (RFT) [23] 模型用作 RL 框架中策略模型的初始化。
还探索使用 DeepSeek-R1-Distill-Qwen-7B [13] 作为初始策略模型并对其执行 OREAL。RFT 模型的训练数据包括 OpenDataLab [40] 支持的内部数据集和开源数据集,包括 Numina [41] 和 MATH [21] 的训练集。
强化学习
数据准备。在基于策略的强化学习过程中,利用来自 Numina、MATH 训练集和历史 AMC/AIME(不包括 AIME2024)竞赛的问题。对于每个问题,从 RFT 模型中独立抽取 16 条轨迹。然后对每条轨迹的正确性取平均值,以估计每个查询的正确率。为了增加训练查询的难度,只有正确率在 0 到 0.8 之间的问题才会被保留以供进一步训练。
结果奖励信号。用 Qwen2.5-72B-Instruct [39] 作为生成验证器,结合基于规则的验证器,评估模型输出的正确性并提供二元奖励。这种组合增强正确性评估的稳健性,缓解与基于规则验证器的假阴性相关问题。
训练token-级的奖励模型。对于 token 级奖励模型,直接使用验证器提供的二元结果奖励,并使用交叉熵损失进行优化:
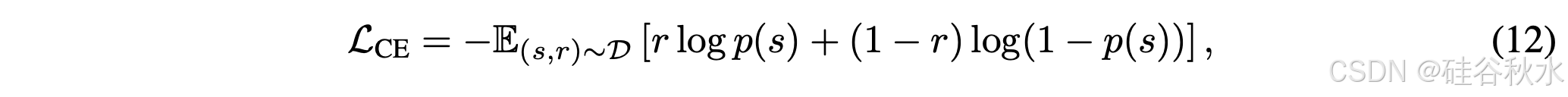
为了进一步分析 token-级奖励模型的行为,在基于策略的 RL 训练过程中可视化其输出分布 w(s_t)。在此训练范例中,w(s_t) 在整个思维推理过程中分配 token-级重要性分数,捕获每个 token 对生成响应的最终正确性贡献。因此,这样能够在优化过程中利用 w(s_t) 进行重要性采样,从而更有原则地选择信息性 token。
训练算法。策略模型的损失函数如上定义。完整的 RL 训练过程在如下算法中描述。

超参数。策略模型从 RFT 模型初始化。类似地,token-级奖励模型也使用相同的权重初始化,但其输出层被替换为产生一维标量的线性层。此层的权重初始化为零,以确保在训练开始时无偏重要性采样权重。
在训练迭代期间,每个批次包含 64 个问题,每个问题有 16 个展开。每个展开轨迹的最大长度设置为 16384 个 token。然后对每个答案的正确性取平均值以计算通过率,丢弃总体通过率为 0 或 1 的问题。对于剩余的轨迹,每个问题只保留一个正确答案和一个错误答案,确保用于 token-级奖励模型训练的正负样本分布均衡。
对于优化,策略模型的学习率为 5e−7,而 token-级奖励模型的学习率为 2e−6。后者在训练开始前经过 10 步的预热阶段。两个模型都采用余弦退火学习率调度,随着时间的推移衰减到初始学习率的 1/5。用 AdamW 优化器优化这两个模型。总训练步骤数为 80,每 10 步进行一次评估。 KL 系数 β 设置为 0.01。选择由评估指标确定的性能最佳的模型。
基于技能的增强
在 RL 训练过程中,模型在某些类型的问题上始终存在困难,尤其是涉及特定知识和技能领域的问题,例如三角常数变换、概率统计、级数变换等。这是由于基础模型在预训练或 RFT 阶段对这些概念的学习不足造成的。
为了解决这个问题,实施一种基于技能的增强方法,使用 MATH 数据集来降低技能注释的高成本。具体来说,用相应的核心技能注释训练集中的每个问题。对于模型在 RL 阶段反复无法正确回答的问题,从训练集中包含具有相同技能的类似问题来执行数据增强。然后在 RFT 阶段将这些增强的问题添加到训练数据中,以帮助模型更好地内化这些技能。

















 691
691

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









