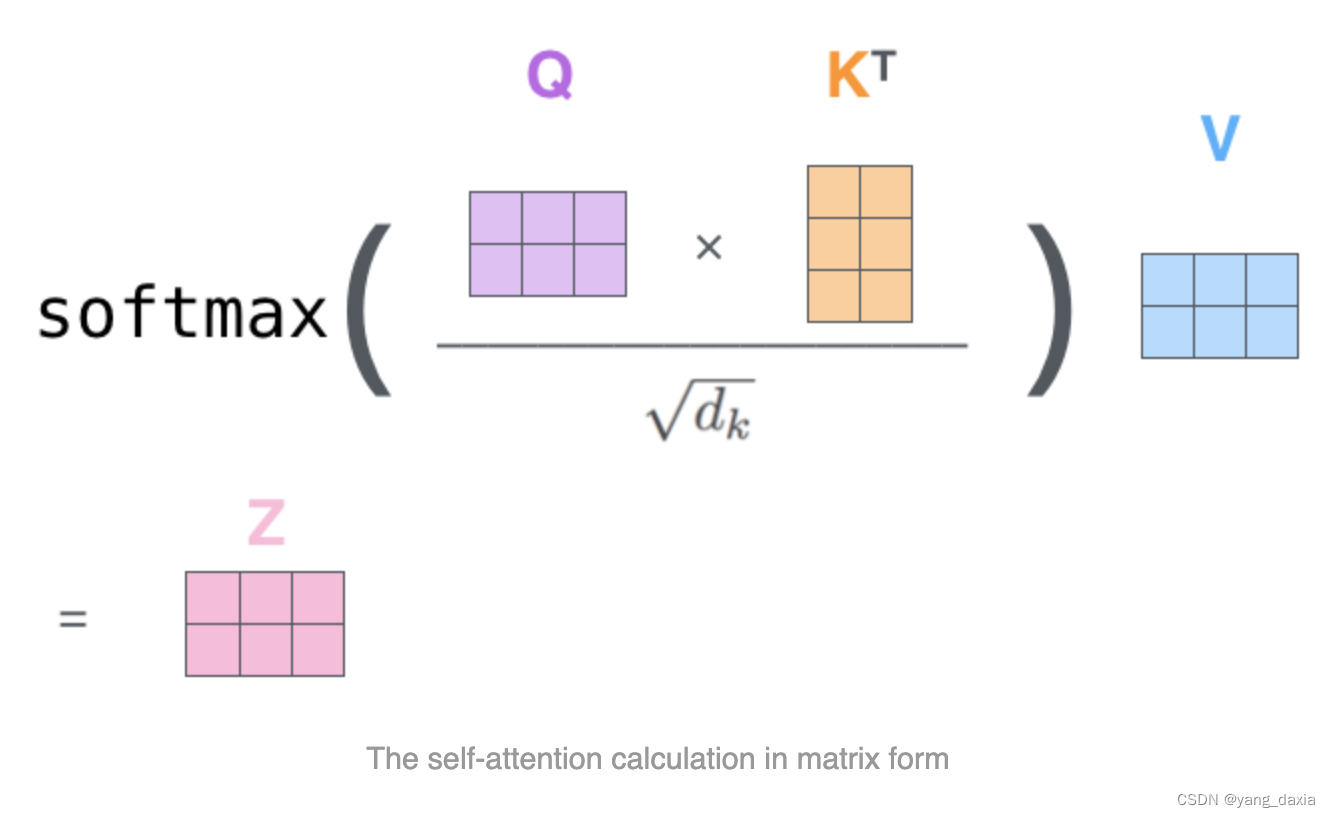
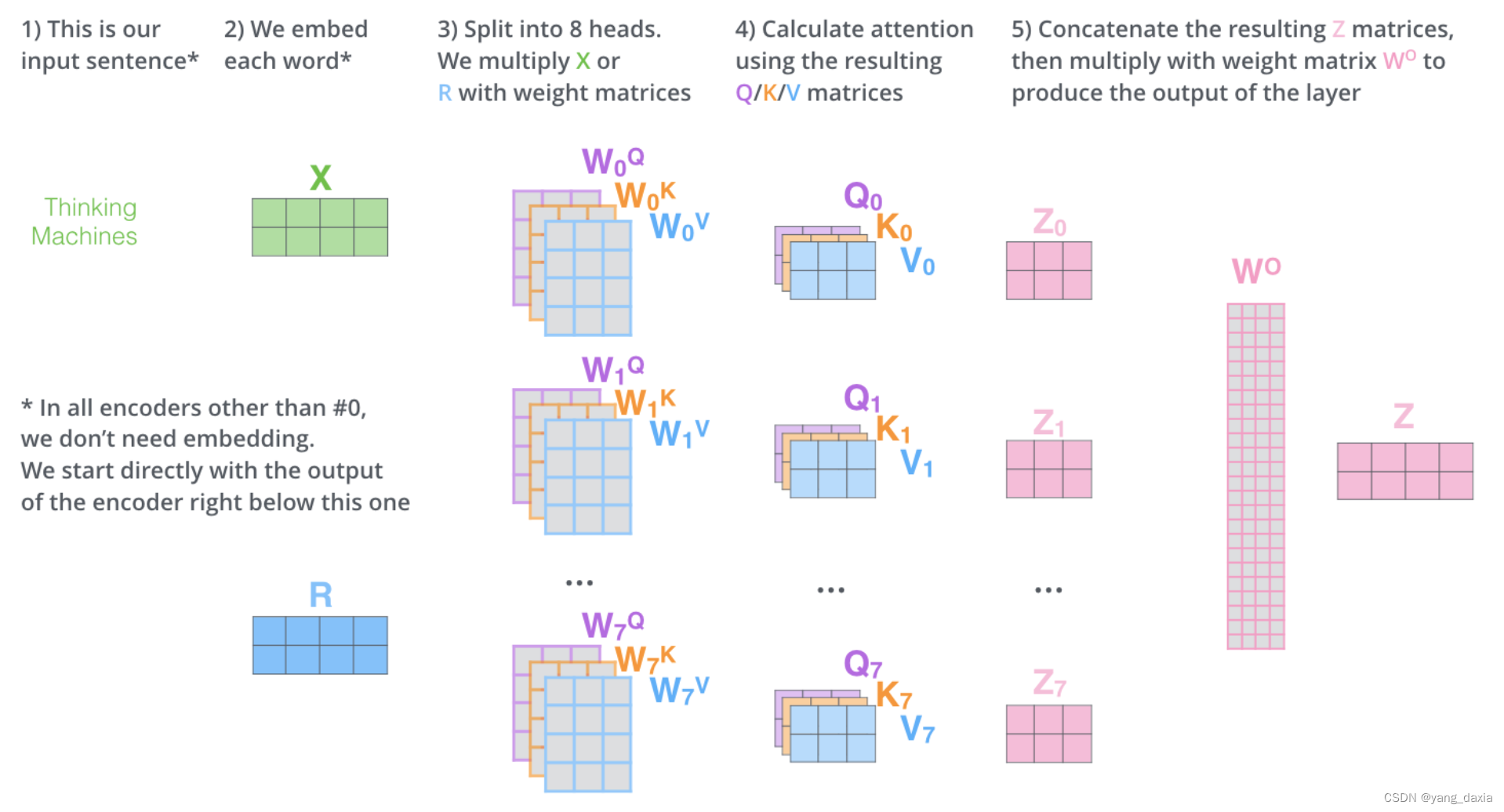
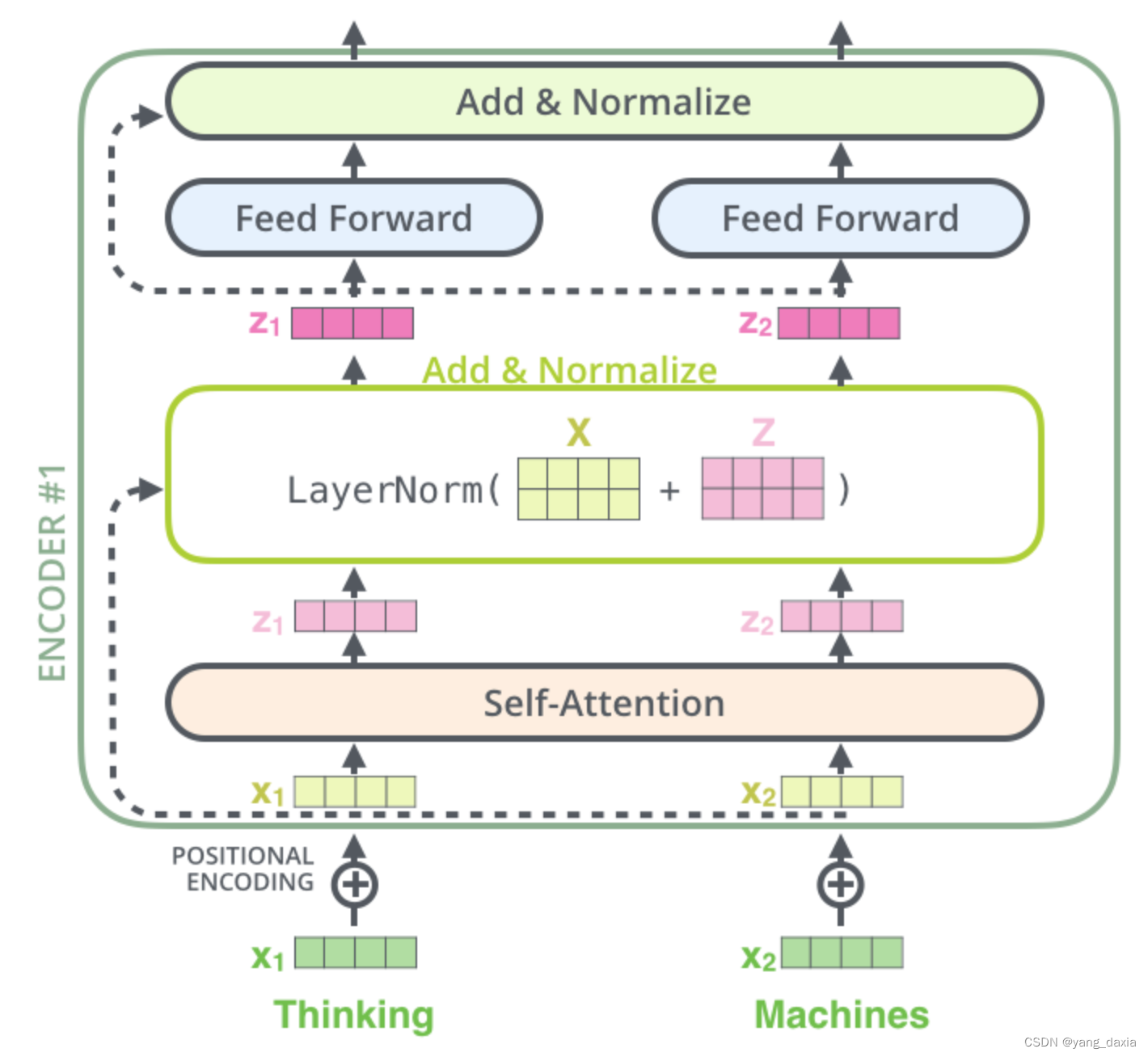
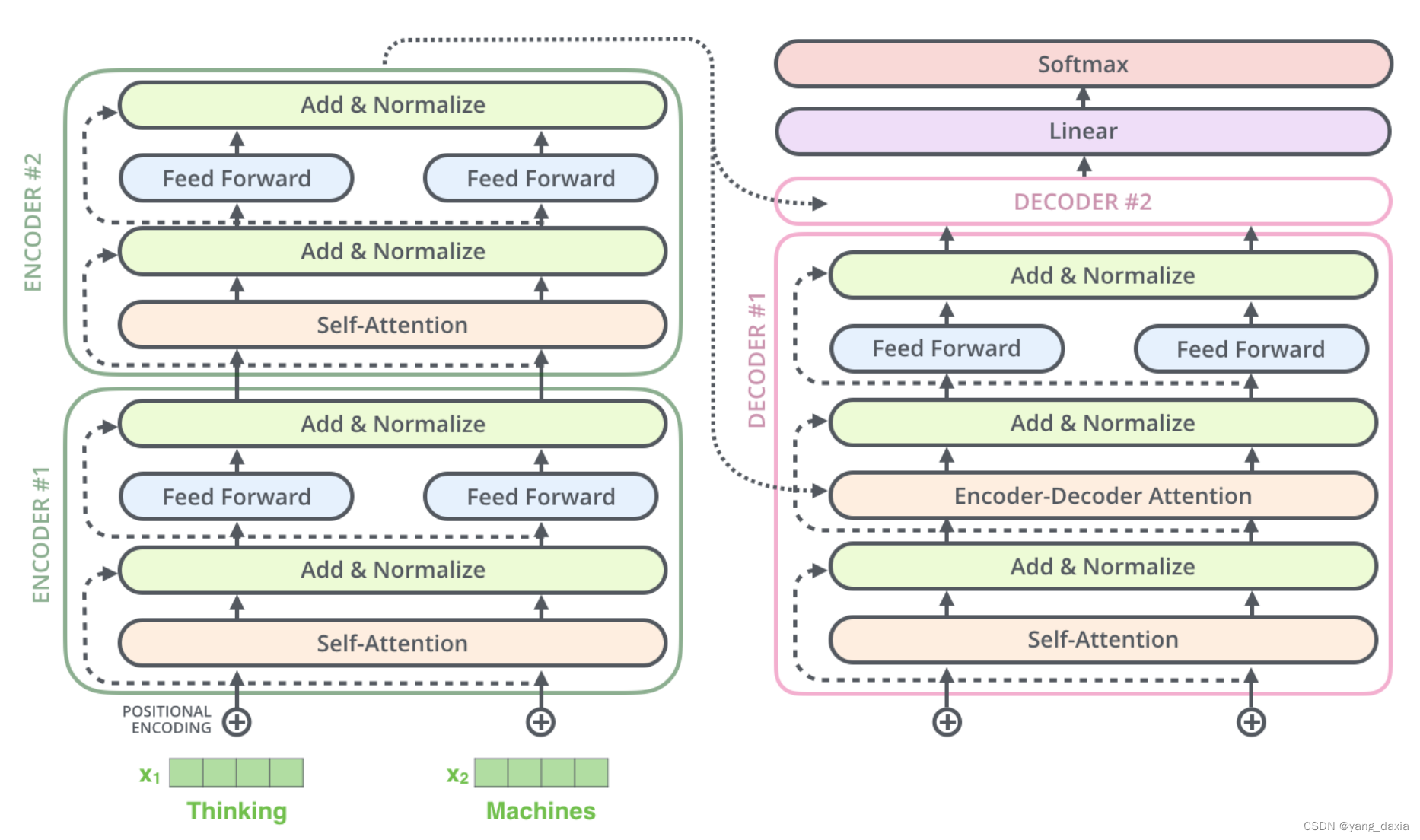
transformer的理解 Q、K、V的理解 核心是自注意力机制。即每个位置的结果为所有位置的加权平均和。为了得到每个位置的权重,需要Q*K得到。 整个多头的self-attention过程 单个encoder encoder-decoder encoder中的K和V会传到decoder中的encoder-decoder attention中。








 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言






 超级会员免费看
超级会员免费看

 本文深入探讨Transformer模型,重点解释了Q、K、V在自注意力机制中的作用,以及为何需要位置编码。通过多头自注意力和Encoder-Decoder结构的分析,展示了Transformer的工作原理。同时,提到了位置编码的不同方案,如三角函数方式,以弥补模型中丢失的位置信息。
本文深入探讨Transformer模型,重点解释了Q、K、V在自注意力机制中的作用,以及为何需要位置编码。通过多头自注意力和Encoder-Decoder结构的分析,展示了Transformer的工作原理。同时,提到了位置编码的不同方案,如三角函数方式,以弥补模型中丢失的位置信息。

 订阅专栏 解锁全文
订阅专栏 解锁全文



















 328
328







