







简介
感知机(Perceptron)由Rosenblatt在1957年提出,属于有监督学习,作为一种二分类的线性分类模型,它的目标是要将输入实例通过分离超平面将正负二类分离,并运用训练好的超平面模型预测新数据。
为何要学习这么“老”的感知机:
-
它是神经网络的基本单元。
-
与支持向量机有很多相通之处。
模型
定义:
感知机输入空间(特征空间) 为,输出空间为
从输入空间到输出空间的映射函数为,其中
,
为常数
符号函数
感知机的几何解释:
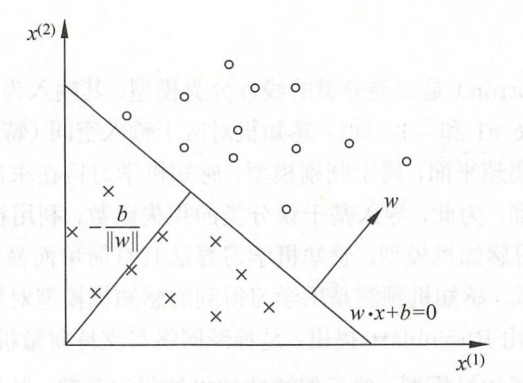
线性方程对应于特征空间中的一个超平面
,其中 w 是超平面的法向量,
是超平面的截距。这个超平面将特征空间分为了两个部分。位于两部分的点(即特征向量)分别被分为正、负两类。
也被称之为分离超平面(separating hyperplane)。
通过这个2维图形就很容易理解感知机的作用了,利用已知数据找到一条能准确划分它们的线,并运用这条线来预测新数据。
需要注意的是几何解释的问题域是符号函数里的线性方程,如果训练数据是2维的,整个问题域需要用3维空间表示。
线性不可分问题
感知机只能处理线性可分问题,对于线性不可分问题需要多感知机--神经网络、非线性函数--支持向量机核技巧来处理。
策略
模型定义中,我们的未知量为和
。因此我们的目标就是要确定一个学习策略,即定义损失函数,并通过训练样本使其最小化来确定
和
。
感知机的思想是把误分类点到超平面的总距离作为损失函数:
给定训练数据集,其中
为特征向量,
。任意点
到超平面
的距离公式为
,其中
,即为
范数。
由于误分类点满足:,即
。因此误分类点
到超平面距离可转化为:
。
假设超平面的误分类点集合为
,则误分类点到
的总距离为:
式中可以被忽略,因为感知机只需要得到正确分类,正确的超平面是个集合,感知机不关心这个集合里哪个更好,这种处理也会影响到迭代,但好的初值和学习率可以作为补偿,最主要的是忽略后可以简化计算,所以最终得到感知机的损失函数为:
损失函数的另一个自然选择是误分类点的总数,但是,通过这种方式定义的损失函数对参数,
来说不是连续可导函数,不易于优化;通俗来说就是没有告诉机器如何更新超平面。
算法
感知机的求解过程实际上是上述损失函数的最优化问题,可以通过随机梯度下降法来求解。
任选一个超平面,然后用梯度下降法不断地极小化目标函数(损失函数)。极小化过程中一次随机选取一个误分类点使其梯度下降。
优化目标:
随机梯度(SGD)下降过程:
首先对求偏导:
,
。
随机选取一个误分类点,对求解参数
进行更新:
,
式中
是步长,又称为学习率。
步骤流程:
(1) 初始化。
(2) 在训练集中选取数据
(3) 若(误分类点),则进行参数更新:
(4) 转至(2),直到训练集没有误分类点。
对于线性方程组另一个容易想到的方法是最小二乘法,但在高维问题上此方法不易求解。
对偶形式
对偶形式是对算法的时间复杂度和空间复杂度的优化。
过程与原始形式相似;将要求解的参数表示为
的线性组合形式,通过求解其系数从而求得
。 假设
,对于误分类点
通过
,
进行更新。假设更新
次,则
关于
的增量分别是
,
。其中
表示
样本修改了
次。令
,
可表示成:
。
误分类条件,参数更新:
。
对偶中的训练集仅以内积形式出现。可以预先将训练集中实例间的内积计算出来并以矩阵的形式存储,这个矩阵就是所谓的Gram矩阵,需要时直接取用。
收敛性
结论:
其中,为误分类次数, 即感知机算法的迭代次数。上式给出了迭代次数的上界。
,已知数据集线性可分,则
存在,
,即
是数据点
到超平面的最短距离。
,表示离原点最远的数据点
的距离。
线性不可分判定
二维、三维图形是否重合,推广到多维。
待续......
学习率、初值选择
待续......
仿真
使用MathLabTool进行感知机仿真![]() https://blog.youkuaiyun.com/xxyjskx1987/article/details/145545570
https://blog.youkuaiyun.com/xxyjskx1987/article/details/145545570

















 381
381

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









