 Transformer架构与大模型学习原理
Transformer架构与大模型学习原理







大模型必知基础知识:2、Transformer架构-大模型是怎么学习到知识的?
总目录
- 大模型必知基础知识:1、Transformer架构-QKV自注意力机制
- 大模型必知基础知识:2、Transformer架构-大模型是怎么学习到知识的?
- 大模型必知基础知识:3、Transformer架构-词嵌入原理详解
- 大模型必知基础知识:4、Transformer架构-多头注意力机制原理详解
- 大模型必知基础知识:5、Transformer架构-前馈神经网络(FFN)原理详解
- 大模型必知基础知识:6、Transformer架构-提示词工程调优
- 大模型必知基础知识:7、Transformer架构-大模型微调作用和原理详解
- 大模型必知基础知识:8、Transformer架构-如何理解学习率 Learning Rate
- 大模型必知基础知识:9、MOE多专家大模型底层原理详解
- 大模型必知基础知识:10、大语言模型与多模态融合架构原理详解
- 大模型必知基础知识:11、大模型知识蒸馏原理和过程详解
- 大模型必知基础知识:12、大语言模型能力评估体系
- 大模型必知基础知识:13、大语言模型性能评估方法
目录
大模型学习路径
学习的本质理解
大模型的学习过程可以类比为训练一只猴子。业界人士常常将这个过程称为"炼丹",这个比喻其实很形象,因为大模型究竟能学会哪些知识并不完全可控,需要多次尝试和一定的运气成分。
大模型学习知识的本质是什么呢?其实就是将文本转换成数字,然后将这些数字信息写入大模型的词汇表里面。词汇表本质上是一个巨大的空间矩阵,矩阵中的每一个维度(列)都代表了某个词的一个特定含义。
比如"苹果"这个词就有多种含义,既可以表示水果中的苹果,也可以表示苹果公司。大模型的学习过程就是通过大规模训练,将现实世界中词汇的各种含义逐步映射到这个高维词向量空间内。
ChatGPT这样的大模型拥有高达12500个维度,词汇空间矩阵庞大到难以想象。每一个词都被表示为一个包含数千个数字的向量。通过这样的高维表示,模型能够捕捉词汇之间的语义关系和深层的知识。
三阶段训练流程

目前业界主流的大模型训练分为三个关键阶段,每个阶段都有明确的目标和作用:
预训练阶段(Pre-training)
这是大模型学习的第一步,也是最基础的一步。完成预训练后,模型就能实现类似完形填空的效果,也就是说,模型学会了根据前面的文本预测下一个单词。
在这个阶段,模型需要处理海量的文本数据。这些数据涵盖了互联网上的各种内容,包括不同的领域、不同的写作风格和各种表达方式。通过在这些数据上的训练,模型能够接触到丰富的语法结构、句法规则和上下文关联等语言信息。
举个例子,模型可以学习到"猫"和"狗"都是常见的动物。更进一步,模型还能理解它们通常出现在相似的上下文中,比如"猫喜欢吃鱼"和"狗喜欢吃肉"这样的句子。通过这种学习,模型逐渐掌握了这些生物体的基本语义特征,以及它们与其他词汇之间的关系。
有监督微调阶段(SFT,Supervised Fine-Tuning)
预训练之后的模型虽然掌握了基本的语言知识,但还不能很好地进行问答对话。SFT阶段的目标就是让模型能够实现基本的问答效果,变成一个更实用的助手。
指令微调的核心是让模型在面对特定的任务时,能够根据给定的指令进行有效的理解和处理。在这个阶段,我们会给模型喂入大量的指令及其对应的正确答案,比如"请总结这段文章"、"翻译这句话"等具体的任务指令。
通过指令微调,模型不仅能更好地完成像问答、摘要生成、机器翻译等常见的任务,还能显著提高在对话式AI、个性化推荐等应用场景中的表现。简而言之,SFT是为了让模型在面对具体任务时,能够按照人类的期望提供更加精准和符合需求的结果。
强化学习与人类反馈阶段(RLHF)
这是大模型优化的最后一个关键阶段,目标是让模型的回答更符合人类的偏好和价值观。
基于人类反馈的强化学习(Reinforcement Learning from Human Feedback,RLHF)是一种将强化学习与人类反馈紧密结合的方法。通过这种方法,我们能够优化模型的行为和输出,使其更加符合人类的真实期望。RLHF帮助模型更好地理解人类的偏好,生成更自然、更符合人类意图的输出内容。
用一个很贴切的比喻来理解RLHF过程:它就像是一个高中生备战高考的全过程。首先,这个学生通过三年的日常学习积累了大量的基础知识,这相当于模型的预训练阶段。经过三年的打磨,学生已经掌握了各个科目的基本知识。
然后,这个学生进入高考专项备考阶段,通过做大量的模拟考试卷来针对性地提高应试能力,这对应于模型的有监督微调(SFT)阶段。模拟考试能够帮助学生发现自己的不足之处。
在强化学习阶段,学生需要根据模拟考试的反馈和教师的点评进行调整,优化答题的策略和方法。这个过程中,教师的评分和反馈就像是奖励模型,根据学生的表现给出具体的评分和改进建议。通过这种反馈机制,学生不断优化自己的答题方式,最终通过高考。同样地,模型在RLHF中根据人类的反馈不断优化自身的行为,使得输出结果越来越符合人类的期望,表现也越来越好。
当前训练的核心竞争力
现在各家的训练过程大同小异,每家都有自己独特的诀窍在里面。但有一个有趣的现象是,目前制约大模型效果的最大瓶颈并不是算法本身,而是数据的质量。
高精度、高质量的训练数据会显著提升模型的训练效果。这是因为"垃圾进,垃圾出"的原理在大模型中体现得淋漓尽致。一个模型无论多复杂、算法多精妙,如果训练数据质量不高,模型学到的知识就会存在问题。因此,数据已经成为了当前大模型竞争的核心竞争力。各大公司都在争夺高质量的数据资源,这些数据往往是通过巨大的人力成本标注和清洗获得的。
学习过程原理
现在让我们深入到大模型学习的具体机制,理解它是如何从原始文本一步步学到知识的。
数据输入与预处理
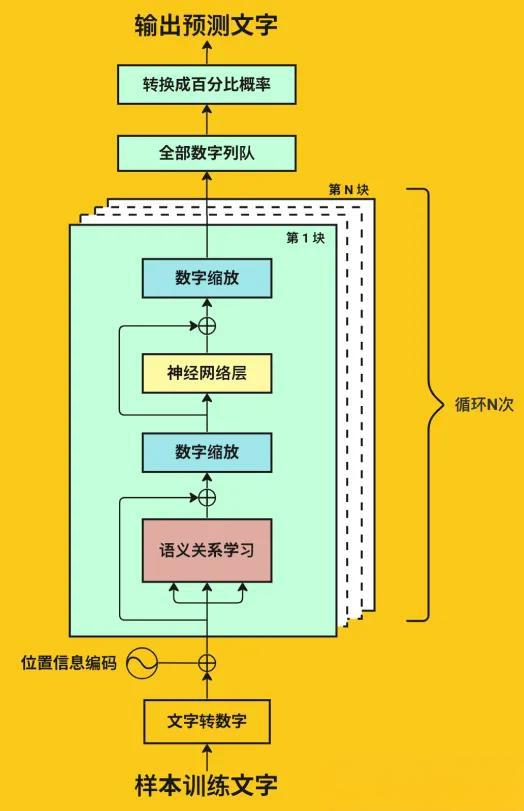
大模型的学习过程从数据开始。任何学习都需要先对数据进行预处理,主要任务是将海量的、长篇幅的文本拆分为固定长度的短句,然后再通过分词器和词嵌入技术,将这些文本转化为向量形式,使得计算机能够理解和处理。
例如,"苹果"这个词可能被转换为一个向量:[0.2, 0.4, 0.1, 0.7],其中每个数字都代表了这个词在某个维度上的特征值。
数据集来源与规模
模型通常在规模庞大的文本数据上进行训练,这些数据来自网页、书籍、学术论文、社交媒体对话等多个来源。这个数据集涵盖了多种不同的自然语言、不同的应用领域和各种不同的写作风格。这种多样性对模型的泛化能力至关重要。
分词过程
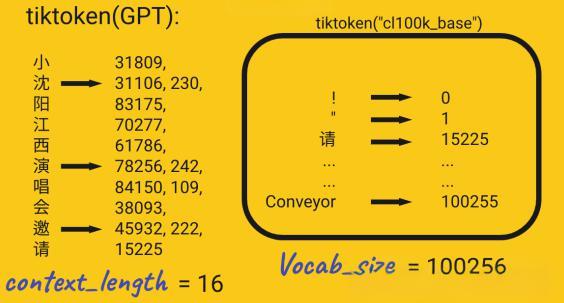
原始的文本无法直接被模型处理,需要经过分词处理。分词是将长文本序列分解为词、子词或字符的过程。业界常用的分词算法包括BPE(Byte-Pair Encoding)和WordPiece等。分词后的每个单元都被转换为一个对应的数字表示,这就是所谓的词嵌入(Embedding)。
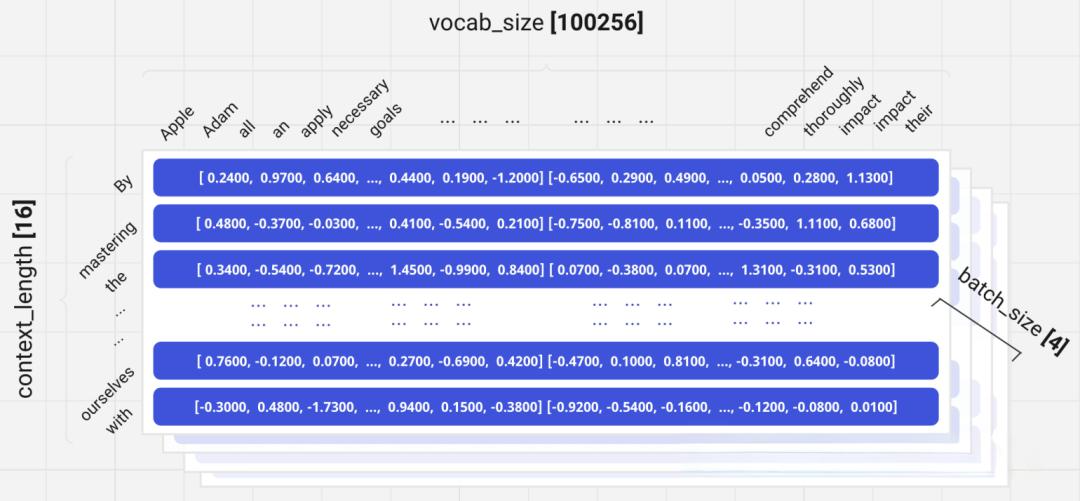
以tiktoken这样的GPT分词器为例,它将中文文本分解为不同的token。比如"小沈阳演唱会邀请"这样的文本,会被分解成多个token,每个token对应一个特定的数字ID。词汇表(Vocab)的大小决定了可能的token总数,比如基础的tiktoken词表包含100256个不同的token。
上下文窗口
Transformer模型以固定长度的序列来处理输入,这个固定长度被称为上下文窗口(Context Window)。例如,如果上下文窗口设置为16,那么模型一次处理包含16个token的序列。序列中的每个token都有对应的嵌入向量,这些向量将被传入模型的后续层进行处理。
自注意力机制计算
数据转化为向量后,进入模型的第一个关键计算环节,也就是自注意力机制(Self-Attention Mechanism)。这是Transformer架构的核心创新,也是现代大模型能够理解语境的关键所在。
捕捉词与词之间的关系
自注意力机制的主要任务是计算序列中每个词与其他所有词之间的相关性,最终生成一个加权表示。这使得模型能够理解词与词之间的上下文关系,从而实现对语义的正确理解。
比如,"苹果"这个词在不同的句子中可能有完全不同的含义。在"我买了一个苹果"中,它指的是水果;而在"苹果公司发布了新产品"中,它指的是公司。自注意力机制正是通过计算"苹果"与周围词汇的相关性来判断它的具体含义。模型会自动学会关注那些提供上下文线索的词汇,从而正确地理解"苹果"的含义。
多头注意力机制
为了让模型能够同时捕捉多个不同层次的关系,Transformer引入了多头注意力机制。通过多个注意力头的并行处理,模型能够同时关注不同维度的语义关系,比如语法关系、语义关系、逻辑关系等,从而提取出更加丰富和全面的特征。
想象一下,如果一个人只能从一个角度看东西,那他的理解会很片面。但如果这个人有多个视角来同时观察,就能获得更全面的理解。多头注意力机制正是这个原理的应用。
前馈网络与层堆叠
经过自注意力机制的处理,数据还需要进一步的处理。每一层的全连接前馈网络会对自注意力机制的输出进行非线性变换,进一步提取和整合特征信息。
特征转换
前馈网络通常由多层的全连接层组成,采用激活函数(如ReLU)引入非线性。这种非线性变换能够让模型学习到更复杂的特征,而不仅仅是线性的组合。
多层堆叠
现代的大模型通常包含数十层到数百层的Transformer层。ChatGPT这样的超大模型可能包含100层以上的Transformer层。这种深层堆叠的设计是有深意的。信息从输入层逐层向上传递的过程中,会不断地被抽象和转化。
低层处理的是词级别的特征,比如某个词的具体特性;中间层可能捕捉短语和句子级别的信息;而高层则开始处理段落、主题和更高层次的语义。这种逐层递进的抽象过程,使得模型能够建立一个从低层具体信息到高层抽象概念的完整的知识体系。
反向传播与参数更新
上面介绍的是模型的前向过程,但大模型的学习发生在反向过程中。这是深度学习的核心机制,也是模型能够"学习"知识的根本原因。
前向传播过程
首先,输入数据(经过分词和embedding后的文本序列)经过Transformer的各个层,包括自注意力层、前馈网络等,最终生成一个输出。对于语言模型,这个输出通常是下一个词的概率分布。
为了让模型学习,我们需要一个参考标准。这个标准就是真实标签(Ground Truth)。比如,如果输入是"今天是星期",那么真实标签应该是"二"。模型的输出与真实标签进行比较,计算损失函数(通常使用交叉熵损失),这个损失值衡量了模型预测的错误程度。
反向传播过程
现在,我们需要找出哪些模型参数导致了这个错误。这就需要计算损失函数对每一个参数的梯度(导数)。通过链式法则,从输出层逐层向输入层反向传播,计算每一层参数的梯度。
在这个反向传播的过程中,自注意力机制的权重矩阵会得到梯度,词嵌入矩阵也会得到梯度,前馈网络的权重也会得到梯度。每一个参数都会"知道"自己对最终错误有多大的影响。
参数更新与优化
一旦得到了梯度,就可以更新参数了。通常使用优化算法如Adam来执行这个更新。更新的方向总是与梯度相反,目标是最小化损失函数。更新公式是:
新参数 = 旧参数 - 学习率 × 梯度
这里的学习率是一个关键的超参数,它控制着每次更新的步长。如果学习率太大,模型可能会在最优解附近来回震荡;如果学习率太小,训练会进行得非常缓慢。
这个过程需要反复迭代很多次,通常是数百万次。每一次迭代,模型都在朝着正确的方向调整自己的参数。经过足够多的迭代和优化,模型会逐步逼近数据的真实分布,学习到越来越多的语言模式和知识。
具体例子
让我们看一个具体的例子来理解这个过程:
- 输入句子:“今天是星期_”
- 模型经过前向传播,预测输出是"五"
- 但真实答案应该是"二",这产生了一个错误
- 损失函数计算这个错误的大小,比如交叉熵损失可能是0.8
- 通过反向传播,计算损失函数对所有参数的梯度
- 自注意力层中,负责关注"星期"这个词的权重可能需要增加
- 词嵌入中,与"二"相关的向量需要微调
- 使用Adam优化器更新所有参数
- 再次计算损失函数,这次可能降低到0.6
- 经过数百万次这样的迭代,模型逐渐学会了正确预测"星期二"
知识的存储:模型参数
那么,大模型究竟是如何存储它所学到的知识的呢?
答案是:通过参数。
参数存储形式
大模型学到的所有知识都存储在一个叫做safetensor的文件中。这个文件的大小随着模型的复杂度而增加。一个小的模型可能只有几百MB,而一个超大的模型(如GPT-3.5)可能高达几百GB甚至超过1TB。
参数的具体组成
Transformer模型包含数十亿到数千亿个参数,这些参数的具体构成如下:
词嵌入矩阵(Embedding Matrix)
这是最直观的知识存储形式。词嵌入矩阵将每个词或子词映射到一个高维向量空间中。比如,词汇表中有100256个不同的token,每个token被映射到一个4096维的向量(这只是一个例子)。这些向量编码了每个词的语义特征和语法信息。当模型需要理解一个词的含义时,它就查询这个矩阵中对应的向量。
自注意力层的权重矩阵
这些矩阵包括查询(Query)矩阵、键(Key)矩阵和值(Value)矩阵。这些矩阵的参数直接影响模型如何理解上下文关系。通过这些矩阵,模型学会了哪些词应该相互关注,哪些信息应该被强调,哪些可以被忽视。在整个训练过程中,这些矩阵经过多次更新,最终编码了模型对语言结构的理解。
前馈神经网络权重
每一层的前馈网络都包含多组权重矩阵。这些矩阵负责特征的非线性变换和整合。通过这些矩阵,模型能够学会识别和提取越来越高层次的特征,从词级别的特征到句子、段落、甚至文档级别的特征。
偏置和层归一化参数
除了上述的权重矩阵,模型还包含许多偏置向量和层归一化的参数。虽然这些参数的数量相对较少,但它们对于稳定模型的训练和提高模型的表现都很重要。偏置向量可以让模型进行更灵活的特征转换,而层归一化参数帮助稳定梯度的流动,防止训练过程中的数值问题。
参数与知识的关系
我们可以把大模型的参数理解为人脑中的神经元连接。人脑中的知识不是存储在某个特定的位置,而是分布在神经元之间的连接强度中。同样地,大模型的知识也不是集中在某个地方,而是分散在数十亿个参数中。一个关于"苹果"的完整知识不仅仅存储在词嵌入矩阵中,还分散在注意力机制、前馈网络等各个部分中。这种分布式存储的特点使得大模型具有很强的鲁棒性和泛化能力,但也使得我们很难通过直接查看参数来理解模型的具体知识。
总结
大模型是怎么学习知识的?简而言之,就是通过以下几个步骤:
- 数据预处理:将文本转换为数字向量
- 前向传播:数据通过自注意力层、前馈网络等多层处理
- 计算损失:将模型输出与真实答案进行比较
- 反向传播:计算梯度,找出哪些参数需要调整
- 参数更新:根据梯度调整参数,使模型越来越准确
- 重复迭代:数百万次重复上述过程,直到模型学会了足够的知识
- 知识存储:最终的知识以参数的形式保存在safetensor文件中
这个过程既简单又复杂。简单在于基本原理不难理解,复杂在于实际实现中涉及的细节、数据处理、超参数调优等都是超级复杂的、超级专业的。
大模型学习知识,数据的质量比算法的优化更能决定模型的效果。这也是为什么各大科技公司都在争夺高质量数据资源。未来,如何高效地获取和处理数据,如何更好地利用人类反馈来优化模型,这些都将成为大模型发展的关键方向。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









