







大模型必知基础知识:3、Transformer架构-词嵌入原理详解
总目录
- 大模型必知基础知识:1、Transformer架构-QKV自注意力机制
- 大模型必知基础知识:2、Transformer架构-大模型是怎么学习到知识的?
- 大模型必知基础知识:3、Transformer架构-词嵌入原理详解
- 大模型必知基础知识:4、Transformer架构-多头注意力机制原理详解
- 大模型必知基础知识:5、Transformer架构-前馈神经网络(FFN)原理详解
- 大模型必知基础知识:6、Transformer架构-提示词工程调优
- 大模型必知基础知识:7、Transformer架构-大模型微调作用和原理详解
- 大模型必知基础知识:8、Transformer架构-如何理解学习率 Learning Rate
- 大模型必知基础知识:9、MOE多专家大模型底层原理详解
- 大模型必知基础知识:10、大语言模型与多模态融合架构原理详解
- 大模型必知基础知识:11、大模型知识蒸馏原理和过程详解
- 大模型必知基础知识:12、大语言模型能力评估体系
- 大模型必知基础知识:13、大语言模型性能评估方法
目录
什么是Transformer
想象你有一个超级聪明的翻译机器人,它能在瞬间将中文翻译成英文,能写出连贯的文章、回答复杂的问题、生成创意内容。Transformer就是这个机器人的"大脑",是现代大型语言模型(如ChatGPT、Claude、Qwen、Deepseek、Grok等)的核心架构。
Transformer由Google Brain团队在2017年的标志性论文《Attention Is All You Need》中首次提出,彻底改变了自然语言处理的游戏规则。相比传统的循环神经网络(RNN),Transformer具有更强的并行计算能力、更优秀的长距离依赖捕捉能力,已成为支撑现代AI的重要基石。
这个架构不仅在语言处理领域表现卓越,还被广泛应用于图像处理、多模态学习等复杂数据处理任务,证明了其设计的通用性和高效性。
Transformer的核心理念
Transformer的厉害之处在于它能"理解"一句话的整体意思,而不是一个词一个词地机械式地处理。它通过一种叫"注意力机制"(Attention)的技术,快速而精准地抓住句子中哪些词更重要、哪些词之间的关系更紧密。
这种全局视角是Transformer相比RNN最大的优势。传统的RNN必须按照时间序列一步步处理输入数据,而Transformer可以并行处理所有位置的数据,通过注意力权重来建立任意两个位置之间的关系。
打个具体的比方:
你读这句英文"Tom ate an apple in the kitchen",传统的逐词处理方式会这样进行:先看"Tom",再看"ate",再看"an",依次进行到"kitchen"。
而Transformer不会这样傻傻地逐词处理。它会瞬间扫描整个句子,立刻注意到"ate"和"apple"的关系最紧密(因为吃的对象就是苹果),"Tom"是吃的主体,"in the kitchen"是次要的背景信息。
通过这种**"全局观察"和"重点关注"的能力**,Transformer能更准确地理解句子的真实含义和上下文关系。
这种从全局角度理解语义的方式,就是Transformer的精髓所在。
Transformer的整体架构
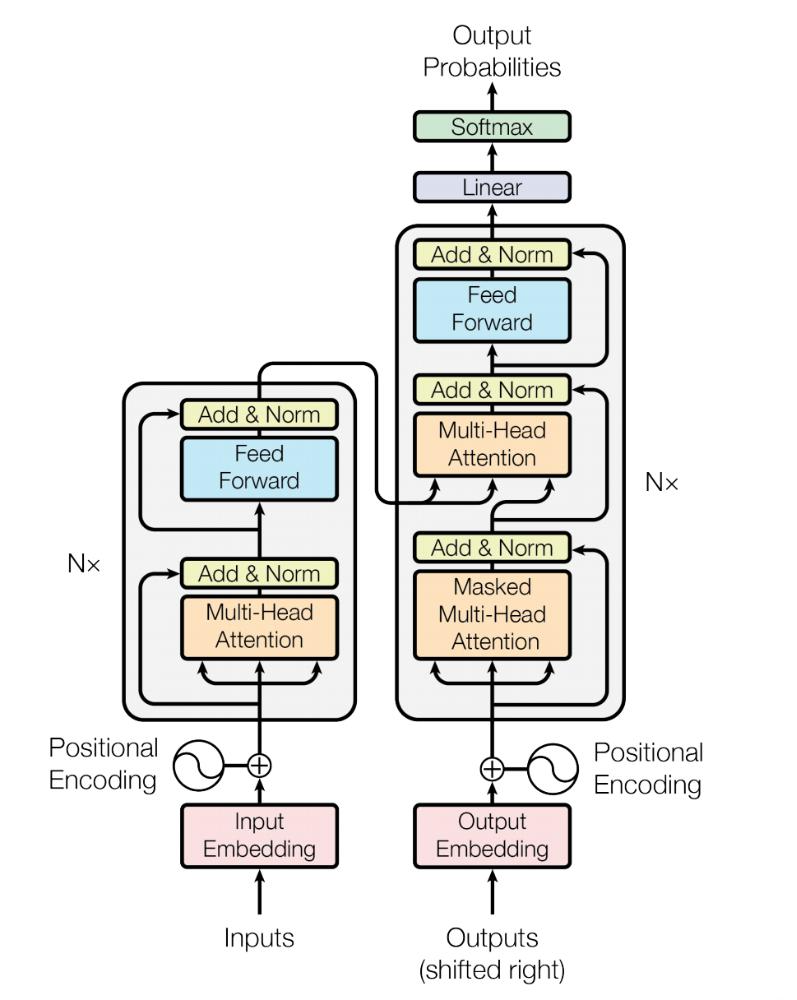
可以简单将Transformer理解为一个函数:y = f(x),其中输入X经过复杂的数学计算得到输出Y。具体来说,Transformer就像一个"加工厂":
- 输入端: 接收原始文本数据(比如一句中文或英文)
- 处理车间: 经过多个层级的处理工序,每层都对数据进行深层的语义提取和特征转换
- 输出端: 生成处理好的结果(比如翻译、文本摘要、问题回答)
Transformer的核心组件包括:
- 词嵌入与位置编码层:将文本转换为数字向量
- 自注意力机制:理解词与词之间的关系
- 多头注意力机制:从多个角度理解文本
- 前馈神经网络:对特征进行非线性转换
- 多层堆叠的编码器或解码器:逐层提升理解能力
- 层归一化与残差连接:保证训练稳定性
这些部分相互配合,形成了一个完整的、强大的神经网络架构。
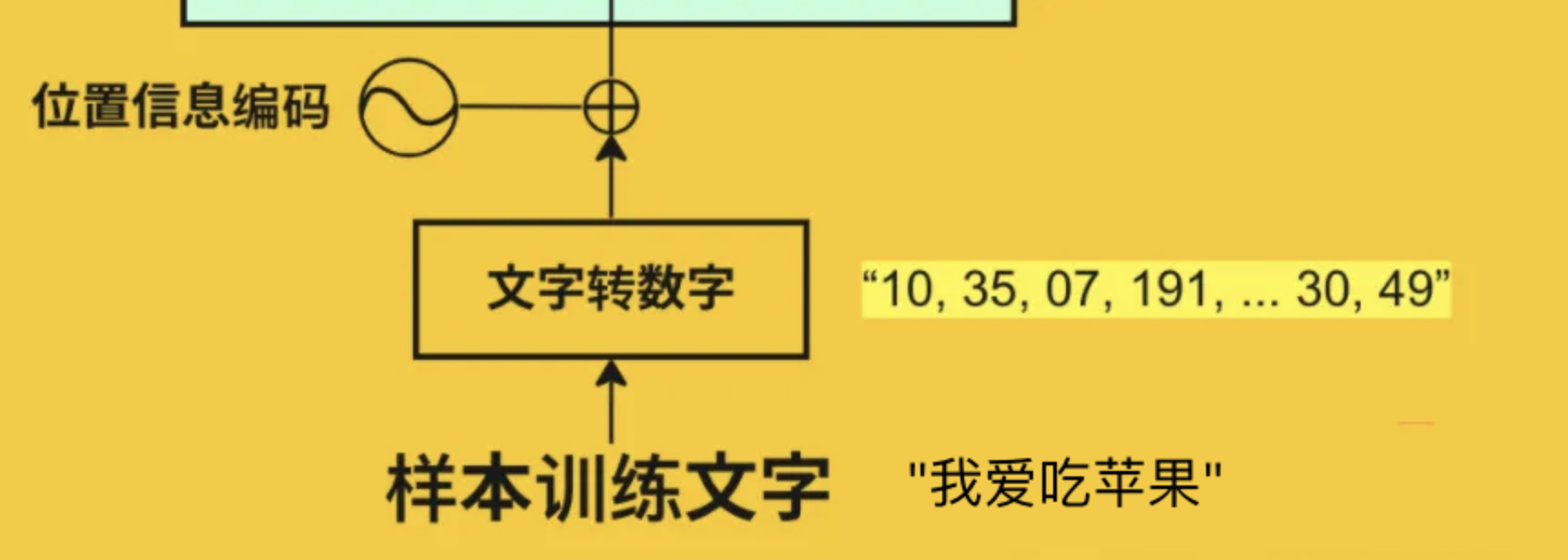
输入层:词嵌入技术详解
计算机本质上只能理解数字。无论是中文、英文还是任何其他语言,计算机都无法直接理解文字的语义。因此,Transformer的第一步工作就是把文本转换成计算机能够处理的数字形式。这个过程分为三个关键步骤:分词、词嵌入和位置编码。
分词(Tokenization)
什么是分词?
分词是将一段连续的文本分解成更小的、意义明确的单元的过程。每个单元被称为一个"token"(令牌)。这个概念特别重要,因为现在许多收费的大模型都按tokens来计费。
分词的作用
计算机不能直接理解"苹果"、"机器学习"这样的词。分词的作用是将句子拆解成一个个离散的、有明确身份的小单位,便于后续的数学处理。
分词的方式
分词方式有多种,适用于不同的语言和场景:
1. 词级别分词(Word-level Tokenization)
这是最直观的方式。比如句子"我爱吃苹果",按词级别分词可以得到:["我", "爱", "吃", "苹果"]。每个词被视为一个独立的token。
优点: 直观易懂,符合人类的语言习惯
缺点: 词汇表庞大,难以处理生僻词和新词
2. 子词级别分词(Subword Tokenization)
这是现代大模型普遍采用的方式。子词分词能更灵活地处理生词、复合词等情况。同样的句子可能被分解为:["我", "爱", "吃", "苹", "##果"],其中"##"表示这是前一个词的延续。
流行的子词分词方法包括:
- BPE(Byte Pair Encoding):GPT系列常用
- WordPiece:BERT系列常用
- SentencePiece:多语言模型常用
优点: 平衡词汇表大小和表达能力,能处理未见过的词
缺点: 需要预先训练分词器
语言差异
英文处理相对直接,通常一个英文单词对应一个token。但中文处理更复杂:常见词汇(如"我"、“爱”、“苹果”)可能被识别为一个token,但较冷门的汉字可能按偏旁部首拆分。这导致相同的汉字数在被token化后,token总数往往会大幅增加,通常是汉字数的1.5到3倍。
Token ID分配
每个token被分配一个唯一的数字ID,这个ID通过查询模型的词汇表(vocabulary)得到。
举个具体的例子:
原始句子:"我爱吃苹果"
步骤1:分词
["我", "爱", "吃", "苹果"]
步骤2:查询词汇表,转换为ID
[100, 101, 102, 103]
这些数字ID就是计算机能够处理的形式
词嵌入(Word Embedding)
什么是词嵌入?
词嵌入是将每个token ID转换为一个高维向量的过程。这个向量不是随机的,而是经过训练学习到的,能够捕捉词的语义信息。
为什么需要词嵌入?
简单的数字ID(如100, 101)只是一个标识符,不包含任何语义信息。词嵌入将这些ID映射到一个连续的向量空间,使得语义相近的词在向量空间中距离也相近。
词嵌入的数学表示
假设我们的词汇表大小为V(比如50,000个词),嵌入维度为 d m o d e l d_{model} dmodel(比如512维),那么词嵌入矩阵 E E E的维度就是 V × d m o d e l V \times d_{model} V×dmodel。
对于token ID为 i i i的词,其嵌入向量为:
embedding i = E [ i ] ∈ R d m o d e l \text{embedding}_i = E[i] \in \mathbb{R}^{d_{model}} embeddingi=E[i]∈Rdmodel
词嵌入的直观理解
想象一个512维的空间(虽然我们无法直接可视化),在这个空间中:
- "国王"和"王后"的向量距离很近
- "男人"和"女人"的向量有特定的方向关系
- “苹果”(水果)和"苹果"(公司)可能在不同的区域
这种空间分布使得模型能够理解词与词之间的语义关系。
经典的词嵌入关系
词嵌入有一个著名的特性:向量运算能够反映语义关系
King - Man + Woman ≈ Queen
(国王 - 男人 + 女人 ≈ 王后)
Paris - France + Italy ≈ Rome
(巴黎 - 法国 + 意大利 ≈ 罗马)
这种"语义代数"是词嵌入最神奇的特性之一。
位置编码(Positional Encoding)
为什么需要位置编码?
Transformer的注意力机制本身是位置无关的。也就是说,如果不添加位置信息,模型无法区分"猫吃鱼"和"鱼吃猫"这两句话——它只能看到三个词,但不知道它们的顺序。
位置编码就是为了解决这个问题,让模型知道每个词在句子中的位置。
位置编码的设计原则
一个好的位置编码应该满足:
- 每个位置有唯一的编码
- 不同位置之间的距离应该一致可衡量
- 能够泛化到训练时未见过的序列长度
- 编码值应该有界,不会随位置无限增长
正弦位置编码(Sinusoidal Positional Encoding)
原始Transformer论文使用的是正弦位置编码,公式如下:
P E ( p o s , 2 i ) = sin ( p o s 1000 0 2 i / d m o d e l ) PE_{(pos, 2i)} = \sin\left(\frac{pos}{10000^{2i/d_{model}}}\right) PE(pos,2i)=sin(100002i/dmodelpos)
P E ( p o s , 2 i + 1 ) = cos ( p o s 1000 0 2 i / d m o d e l ) PE_{(pos, 2i+1)} = \cos\left(\frac{pos}{10000^{2i/d_{model}}}\right) PE(pos,2i+1)=cos(100002i/dmodelpos)
其中:
- p o s pos pos 是位置索引(0, 1, 2, …)
- i i i 是维度索引(0到 d m o d e l / 2 d_{model}/2 dmodel/2)
- 偶数维度使用sin函数,奇数维度使用cos函数
位置编码的直观理解
可以把位置编码想象成时钟的指针:
- 不同的维度就像不同速度转动的指针
- 低频维度(慢指针)捕捉大范围的位置关系
- 高频维度(快指针)捕捉精细的位置差异
这种设计使得模型能够学习相对位置关系,比如"相邻的词"、"距离k个位置的词"等。
最终的输入表示
最终输入到Transformer的向量是词嵌入和位置编码的相加:
Input = WordEmbedding + PositionalEncoding \text{Input} = \text{WordEmbedding} + \text{PositionalEncoding} Input=WordEmbedding+PositionalEncoding
这个简单的相加操作,就让模型同时获得了"这是什么词"和"这个词在哪里"的信息。
核心机制:注意力机制
注意力机制是Transformer的灵魂,也是其名称"Attention Is All You Need"的由来。这个机制让模型能够动态地关注输入序列中的不同部分。
自注意力机制(Self-Attention)
注意力机制的核心思想
当人类阅读一句话时,我们不会平等地对待每个词。比如在"我昨天在北京的故宫博物院看到了很多珍贵的文物"这句话中,如果我们要理解"文物",我们会自动关注"故宫博物院"、“珍贵"等相关词,而不太关注"昨天”。
自注意力机制就是让模型学会这种"选择性关注"的能力。
自注意力的数学表示
自注意力机制包含三个核心矩阵:Query(查询)、Key(键)和Value(值)。
对于输入序列 X ∈ R n × d m o d e l X \in \mathbb{R}^{n \times d_{model}} X∈Rn×dmodel(n是序列长度),我们通过三个权重矩阵得到Q、K、V:
Q = X W Q , K = X W K , V = X W V Q = XW^Q, \quad K = XW^K, \quad V = XW^V Q=XWQ,K=XWK,V=XWV
其中 W Q , W K , W V ∈ R d m o d e l × d k W^Q, W^K, W^V \in \mathbb{R}^{d_{model} \times d_k} WQ,WK,WV∈Rdmodel×dk是可学习的参数。
注意力的计算公式为:
Attention ( Q , K , V ) = softmax ( Q K T d k ) V \text{Attention}(Q, K, V) = \text{softmax}\left(\frac{QK^T}{\sqrt{d_k}}\right)V Attention(Q,K,V)=softmax(dkQKT)V
注意力计算的步骤详解
让我们用一个具体例子来理解这个过程。假设句子是"猫吃鱼":
步骤1:计算相似度得分
对于"吃"这个词(Query),计算它与所有词(Key)的相似度:
"吃"与"猫"的得分:0.3
"吃"与"吃"的得分:0.8
"吃"与"鱼"的得分:0.7
这通过 Q K T QK^T QKT计算得到,除以 d k \sqrt{d_k} dk是为了数值稳定。
步骤2:归一化得到注意力权重
通过softmax将得分转换为概率分布:
"吃"对"猫"的注意力:0.15
"吃"对"吃"的注意力:0.40
"吃"对"鱼"的注意力:0.45
步骤3:加权求和得到输出
用注意力权重对Value进行加权求和:
"吃"的输出 = 0.15 × "猫"的value + 0.40 × "吃"的value + 0.45 × "鱼"的value
这个输出向量融合了所有相关词的信息,其中"鱼"的信息占比最大。
为什么除以 d k \sqrt{d_k} dk?
当维度 d k d_k dk很大时, Q K T QK^T QKT的值可能很大,导致softmax函数的梯度非常小(饱和区)。除以 d k \sqrt{d_k} dk可以将方差归一化为1,避免这个问题。
多头注意力(Multi-Head Attention)
为什么需要多头?
单个注意力头只能从一个角度理解句子。就像看一个物体,从一个角度看可能看不全,需要从多个角度观察。
多头注意力让模型能够:
- 从不同的语义空间关注不同的信息
- 同时捕捉多种类型的依赖关系(语法关系、语义关系等)
多头注意力的计算
多头注意力将 d m o d e l d_{model} dmodel维度分成 h h h个头,每个头的维度为 d k = d m o d e l / h d_k = d_{model}/h dk=dmodel/h:
head i = Attention ( Q W i Q , K W i K , V W i V ) \text{head}_i = \text{Attention}(QW_i^Q, KW_i^K, VW_i^V) headi=Attention(QWiQ,KWiK,VWiV)
MultiHead ( Q , K , V ) = Concat ( head 1 , . . . , head h ) W O \text{MultiHead}(Q, K, V) = \text{Concat}(\text{head}_1, ..., \text{head}_h)W^O MultiHead(Q,K,V)=Concat(head1,...,headh)WO
其中 W O W^O WO是输出投影矩阵。
多头注意力的直观理解
假设有8个注意力头,对于句子"银行卡在桌子上":
- 头1可能关注"银行卡"的整体语义
- 头2可能关注"卡"和"在"的位置关系
- 头3可能关注"在"和"桌子上"的语法关系
- 头4可能捕捉长距离依赖
- …
不同的头学习到不同的关注模式,然后将这些信息拼接起来,形成更全面的理解。
总结与展望
Transformer的革命性意义
Transformer架构自2017年问世以来,已经彻底改变了自然语言处理乃至整个人工智能领域。它的核心创新在于用注意力机制完全替代了传统的循环结构,实现了:
1. 并行化计算
相比RNN的顺序处理,Transformer可以并行处理整个序列,极大提升了训练效率。
对比示例:
RNN处理"我爱吃苹果":
时间步1: 处理"我" → 输出h1
时间步2: 处理"爱"(依赖h1) → 输出h2
时间步3: 处理"吃"(依赖h2) → 输出h3
时间步4: 处理"苹果"(依赖h3) → 输出h4
(必须顺序执行)
Transformer处理"我爱吃苹果":
同时处理所有词,计算注意力矩阵
所有位置可以并行计算
(可以在GPU上高效并行)
2. 长距离依赖建模
注意力机制能直接建立任意两个位置的关系,不受距离限制,而RNN在处理长序列时会出现梯度消失问题。
示例:
句子:"那个在1998年我第一次去过的城市真的很美"
RNN: "城市"到"美"需要经过多个时间步,信息衰减严重
Transformer: "城市"和"美"可以直接建立注意力连接,距离不是问题
3. 可解释性
注意力权重可以可视化,让我们能够理解模型"在看什么"。
示例:
翻译"The cat sat on the mat"为"猫坐在垫子上"
可视化注意力权重发现:
- "猫"高度关注"cat"
- "坐"高度关注"sat"
- "垫子"同时关注"mat"和"the"
4. 通用性强
Transformer不仅在NLP领域成功,还被成功应用于:
- 计算机视觉:Vision Transformer (ViT)
- 多模态学习:CLIP、GPT-4
- 蛋白质结构预测:AlphaFold
- 代码生成:Codex、GitHub Copilot
- 音乐生成:MuseNet
- 药物发现:AlphaFold、ESMFold
结语
Transformer不仅仅是一个技术架构,更是人工智能从"专用工具"向"通用智能"迈进的重要里程碑。理解Transformer的原理,就是理解现代AI如何"思考"的基础。
附录:关键术语对照表
| 中文术语 | 英文术语 | 简要说明 | 公式/符号 |
|---|---|---|---|
| 词嵌入 | Word Embedding | 将词转换为向量表示 | E ∈ R V × d E \in \mathbb{R}^{V \times d} E∈RV×d |
| 位置编码 | Positional Encoding | 为token添加位置信息 | P E p o s , 2 i = sin ( p o s / 1000 0 2 i / d ) PE_{pos,2i} = \sin(pos/10000^{2i/d}) PEpos,2i=sin(pos/100002i/d) |
| 自注意力 | Self-Attention | 序列与自身的注意力计算 | A t t e n t i o n ( Q , K , V ) = s o f t m a x ( Q K T d k ) V Attention(Q,K,V) = softmax(\frac{QK^T}{\sqrt{d_k}})V Attention(Q,K,V)=softmax(dkQKT)V |
| 多头注意力 | Multi-Head Attention | 并行的多个注意力头 | M u l t i H e a d = C o n c a t ( h e a d 1 , . . . , h e a d h ) W O MultiHead = Concat(head_1,...,head_h)W^O MultiHead=Concat(head1,...,headh)WO |
| 查询 | Query (Q) | 注意力机制的查询向量 | Q = X W Q Q = XW^Q Q=XWQ |
| 键 | Key (K) | 注意力机制的键向量 | K = X W K K = XW^K K=XWK |
| 值 | Value (V) | 注意力机制的值向量 | V = X W V V = XW^V V=XWV |
| 前馈网络 | Feed-Forward Network | 全连接的神经网络层 | F F N ( x ) = R e L U ( x W 1 + b 1 ) W 2 + b 2 FFN(x) = ReLU(xW_1+b_1)W_2+b_2 FFN(x)=ReLU(xW1+b1)W2+b2 |
| 残差连接 | Residual Connection | 跨层的直接连接 | O u t p u t = I n p u t + S u b L a y e r ( I n p u t ) Output = Input + SubLayer(Input) Output=Input+SubLayer(Input) |
| 层归一化 | Layer Normalization | 归一化技术 | L N ( x ) = γ x − μ σ + β LN(x) = \gamma\frac{x-\mu}{\sigma}+\beta LN(x)=γσx−μ+β |
| 编码器 | Encoder | 理解输入的组件 | 多层self-attention + FFN |
| 解码器 | Decoder | 生成输出的组件 | 多层masked self-attention + cross-attention + FFN |
| 因果掩码 | Causal Masking | 防止看到未来信息的掩码 | 下三角矩阵 |
| 交叉注意力 | Cross Attention | 不同序列间的注意力 | Q来自目标,K/V来自源 |
| Softmax | Softmax函数 | 归一化为概率分布 | s o f t m a x ( x i ) = e x i ∑ j e x j softmax(x_i) = \frac{e^{x_i}}{\sum_j e^{x_j}} softmax(xi)=∑jexjexi |
| 嵌入维度 | Model Dimension | 模型的隐藏层维度 | 通常512或768 |
| 注意力头数 | Number of Heads | 多头注意力的头数 | 通常8或16 |
| 束搜索 | Beam Search | 保留多个候选的搜索策略 | beam_size控制候选数 |
| 温度参数 | Temperature | 控制输出随机性的参数 | T<1更确定,T>1更随机 |
| Top-k采样 | Top-k Sampling | 在前k个最可能的词中采样 | k通常为40-50 |
| Top-p采样 | Nucleus Sampling | 累积概率达到p的采样 | p通常为0.9-0.95 |
| 预训练 | Pre-training | 在大规模数据上训练 | MLM, CLM等任务 |
| 微调 | Fine-tuning | 在特定任务上调整 | 使用小学习率 |
| 零样本学习 | Zero-shot Learning | 无示例的任务执行 | GPT系列能力 |
| 少样本学习 | Few-shot Learning | 少量示例的任务学习 | In-context learning |
| 提示 | Prompt | 输入给模型的指令或示例 | “翻译成英文:” |
| Token | Token | 文本的最小单位 | 可以是词、子词或字符 |
| 词汇表 | Vocabulary | 所有可能token的集合 | 大小通常3万-10万 |
希望这篇文章成为你深入大模型世界的起点。无论你是研究者、工程师,还是对AI充满好奇的学习者,掌握Transformer都将为你打开通往智能未来的大门。
愿同学们在大模型相关工作的道路上,不断前行!

















 1114
1114

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









