







 本文介绍了字典树,它是一种树形结构、哈希树变种,用于统计、排序和保存大量字符串,有特定性质和插入、查询等基本操作,还阐述了其应用、复杂度。同时介绍了01字典树,适用于异或运算,并给出相关代码和例题。
本文介绍了字典树,它是一种树形结构、哈希树变种,用于统计、排序和保存大量字符串,有特定性质和插入、查询等基本操作,还阐述了其应用、复杂度。同时介绍了01字典树,适用于异或运算,并给出相关代码和例题。
什么是字典树:
字典树又称单词查找树,Trie树,是一种树形结构,是一种哈希树的变种。典型应用是用于统计,排序和保存大量的字符串(但不仅限于字符串),所以经常被搜索引擎系统用于文本词频统计。它的优点是:利用字符串的公共前缀来减少查询时间,最大限度地减少无谓的字符串比较,查询效率比哈希树高。
字典树有什么性质:
根节点不包含字符,除根节点外每一个节点都只包含一个字符; 从根节点到某一节点,路径上经过的字符连接起来,为该节点对应的字符串; 每个节点的所有子节点包含的字符都不相同。
字典树的基本操作:
(1)插入:对于一个单词,从根开始,沿着单词的各个字母所对应的树中的节点分支向下走,直到单词遍历完,将最后的节点进行标记,表示该单词已插入Trie树。
(2)查询:同样的,从根开始按照单词的字母顺序向下遍历trie树,一旦发现某个节点标记不存在或者单词遍历完成而最后的节点未被标记,则表示该单词不存在; 若最后的节点被标记了,表示该单词存在。
(代码就不在这放了 下面介绍01字典树的时候会放相关代码)
字典树的应用:
(1)字符串检索:事先将已知的一些字符串(字典)的有关信息保存到trie树里,查找另外一些未知字符串是否出现过或者出现频率。
(2)字符串最长公共前缀(LCP):Trie树利用多个字符串的公共前缀来节省存储空间,反之,当我们把大量字符串存储到一棵trie树上时,我们可以快速得到某些字符串的公共前缀。
(3)排序:Trie树是一棵多叉树,只要先序遍历整棵树,输出相应的字符串便是按字典序排序的结果。
时间与空间复杂度:
(1)时间复杂度:查找一个单词的时间复杂度为O(k),k为字符串长度。
(2)空间复杂度:每个节点都要开26的空间(26个字母 除了叶子节点),所以对空间的要求还是蛮大的。
举几个例子:
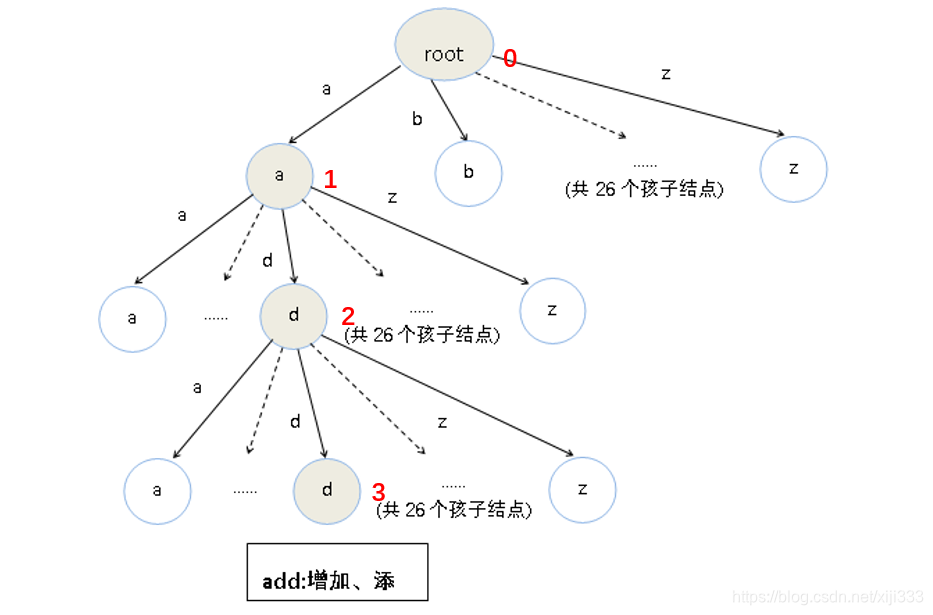
插入一个单词add后的字典树:
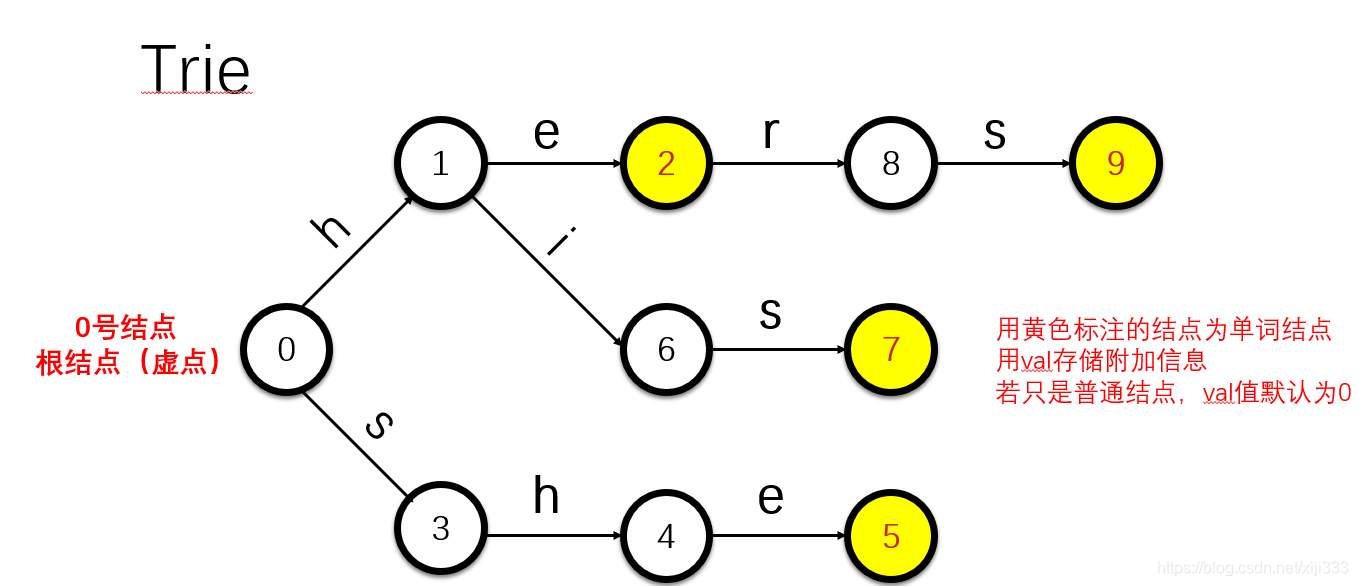
分别插入he、she、his、hers后的字典树:
01字典树:
01字典树的实现可以看成是把一个数的二进制字符化后插入到一棵一般的字典树中,该树显然是一个只由0和1构成的二叉树,即每个节点都有两个子节点(0和1 除了叶子节点)。
01字典树有什么用:
01字典树适用于执行异或运算,如查询一堆数中两个数的异或最大值。一般把数字的二进制形式从高位到低位插入到01字典树中,(高位补0 比如最大的数不超过32位整数 那么每个数的二进制形式都表示成32位的形式 然后从高位到低位插入)那么就可以利用贪心的思想来求异或最大值。
01字典树的相关代码:
这里的例子是:预先给出一些整数,然后有一些查询,每次查询给出一个数字n,找出原来的整数序列中与该数异或值最大的那个数。
void to2(int n)//把n转换成二进制的形式 高位为0
{
memset(a,0,sizeof(a));
int len=0;
while(n>0)
{
a[len++]=n&1;
n>>=1;
}
}
void Insert()
{
int root=0;
for(int i=31;i>=0;i--)//32为整数 从高位到低位插入
{
int id=a[i];
if(!tree[root][id])
tree[root][id]=++tot;
root=tree[root][id];
}
}
ll query()
{
int root=0;
ll temp=0;
for(int i=31;i>=0;i--)
{
int id=1-a[i];//贪心
if(tree[root][id])//存在我们要找的节点
{
if(id==1)
temp=temp<<1|1;
else
temp<<=1;
root=tree[root][id];
}
else//不存在
{
if(id==1)
temp<<=1;
else
temp=temp<<1|1;
root=tree[root][1-id];
}
}
return temp;
}字典树相关例题整理:
HDU 4825 01字典树 求异或最大值。
HDU 1251 统计出以某个字符串为前缀的单词数量。
HDU 2072 统计一篇文章里不同单词的总数。
POJ 2001 找到单词的唯一前缀。
POJ 3630 判断每一个单词是否是其他单词的前缀。
Light OJ 1224 求给定的序列中以某个字符串s作为前缀时使num*strlen(s)最大。(num:以s为前缀的数目 len:s的长度)
Light OJ 1269 求一段连续区间的异或最大值和异或最小值。(这题不错)

















 3万+
3万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









