




 本文介绍深度卷积生成对抗网络(DCGAN)的原理及其实现,包括批归一化的重要性、卷积神经网络的基础知识,以及如何用Keras构建并训练DCGAN生成MNIST手写数字。
本文介绍深度卷积生成对抗网络(DCGAN)的原理及其实现,包括批归一化的重要性、卷积神经网络的基础知识,以及如何用Keras构建并训练DCGAN生成MNIST手写数字。

第四章 深度卷积生成对抗网络(DCGAN)
生成器和鉴别器都使用卷积神经网络,这种GAN架构称为深度卷积生成对抗网络(DCGAN)。
DCGAN复杂架构在实践中变为可行的关键性突破之一:批归一化(Batch Normalization)。
一、卷积神经网络
1、卷积滤波器
卷积是通过在输入层上滑动一个或多个滤波器(filter)来执行的。每个滤波器都有一个相对较小的感受野(宽乘高),但它贯穿输入图像的全部深度。
2、参数共享
滤波器参数被其所有输入值共享,这具有直观和实用的优点。直观地讲,参数共享能够有效地学习视觉特征和形状(如线条和边缘),无论它们在输入图像中位于何处。(位置无关性。)
二、批归一化
就像对网络输入进行归一化一样,每个小批量训练数据通过网络时,对每个层的输入进行归一化。
1、理解归一化
归一化(Normalization)是数据的缩放,使它具有零均值和单位方差。这是通过取每个数据点x减去平均值,然后除以标准偏差得到的。
归一化有几个优点:最重要的一点或许是:使得具有巨大尺度差异的特征之间的比较变得更容易。从而使训练过程对特征的尺度不那么敏感。
归一化通过将每个特征值缩放到一个标准化的尺度上解决了这个问题,这样一来每个数据点都不表示为其实际值,而是以一个相对的“分数”表示给定数据点与平均值的标准偏差。
在处理具有多层的深度神经网络时,仅规范化输入可能还远远不够。当输入值经过一层又一层网络时,他们将被每一层中的可训练参数进行缩放。当参数通过反向传播得到调整时,每一层输入的分布在随后的训练中都容易发生变化,从而影响学习过程的稳定性。在学术界,这个问题称为:协变量偏移(covariate shift)。批归一化通过按每个小批量的均值和方差缩放每个小批量中的值来解决该问题。
2、计算批归一化
批归一化的计算方式与之前介绍的简单归一化方程在几个方面有所不同。
令为小批量B的平均值,
为小批量B的方差(均方误差)。归一化值
的计算公式
增加项是为了保持数值稳定性,主要是为了避免被零除,一般设置为一较小的正常数。例如0.001。
同时,在批归一化中,不直接使用这些归一化值,而是将它们乘以并加上
后,再作为输入传递到下一层。
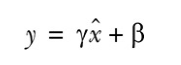
重要的是:和
是可训练的参数,就像权重和偏置一样在网络训练期间进行调整。这样做有助于将中间的输入值标准化,使其均值在0附近(但非0)。方差也不是1。
和
是可训练的,因此网络可以学习哪些值最有效。
Keras中的函数
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 9530
9530

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









