




 本文介绍了优化算法在深度学习中的应用,包括梯度下降、随机梯度下降、小批量随机梯度下降、动量法、AdaGrad、RMSProp、AdaDelta和Adam算法的原理、实现和特点。通过比较和总结,阐述了这些方法如何解决目标函数复杂性带来的挑战,以及如何适应不同维度梯度的动态调整.
本文介绍了优化算法在深度学习中的应用,包括梯度下降、随机梯度下降、小批量随机梯度下降、动量法、AdaGrad、RMSProp、AdaDelta和Adam算法的原理、实现和特点。通过比较和总结,阐述了这些方法如何解决目标函数复杂性带来的挑战,以及如何适应不同维度梯度的动态调整.

第七章 优化算法
本文最后是梳理。可以直接看梳理。
一、优化与深度学习
在一个深度学习问题中,我们通常会预先定义一个损失函数。然后使用优化算法试图将其最小化。在优化中,这样的损失函数通常被称作优化问题的目标函数。
解析解和数值解。
深度学习模型的目标函数可能有若干局部最优值。当一个优化问题的数值解在局部最优解附近时,由于目标函数有关解的梯度接近或变成零,最终迭代求得的数值解可能只令目标函数局部最小化而非全局最小化。
由于深度学习模型参数通常都是高维的,目标函数的鞍点通常比局部最小值更常见。
二、梯度下降和随机梯度下降
学习率过大或过小都有问题。一个合适的学习率通常是需要通过多次实验找到的。
当训练数据集的样本较多时,梯度下降每次迭代的计算开销较大,因而随机梯度下降通常更受青睐。
三、小批量随机梯度下降
- 在每一次迭代中,梯度下降使用整个训练数据集来计算梯度,因此它有时被称为批量梯度下降(batch gradient descent)。
- 而随机梯度下降在每次迭代中只随机采样一个样本来计算梯度。
- 我们还可以在每轮迭代中随机均匀采样多个样本来组成一个小批量,然后使用这个小批量来计算梯度。小批量随机梯度下降。
小批量随机梯度下降随机均匀采样一个由训练数据样本索引组成的小批量:重复采样(sampling with replacement)或者不重复采样(sampling without replacement)。
小批量随机梯度下降对自变量的迭代如下:
。
其中
为学习率,正数。
当批量大小为1时,该算法即为随机梯度下降;当批量大小等于训练数据样本数时,该算法即为梯度下降。
- 当批量较小时,每次迭代中使用的样本少,这会导致并行处理和内存使用效率变低。这使得在计算同样数目样本的情况下比使用更大批量时所花时间更多。
- 当批量较大时,每个小批量梯度里可能含有更多的冗余信息。为了得到较好的解,批量较大时比批量较小时需要计算的样本数目可能更多,例如增大迭代周期数。
1、小批量随机梯度下降从零开始实现:
%matplotlib inline
import numpy as np
import time
import torch
from torch import nn, optim
import sys
sys.path.append("./Dive-into-DL-PyTorch/code/")
import d2lzh_pytorch as d2l
def get_data_ch7():
data = np.genfromtxt("./Dive-into-DL-PyTorch/data/airfoil_self_noise.dat", delimiter="\t")
data = (data - data.mean(axis=0)) / data.std(axis=0)
return torch.tensor(data[:1500, :-1], dtype=torch.float32), torch.tensor(data[:1500, -1], dtype=torch.float32)
features, labels = get_data_ch7()
print(features.shape)
print(labels.shape)
print(labels[:10])
print(features[0])我们将在训练函数里对各个小批量样本的损失求平均,因此优化算法里的梯度不需要除以批量大小。
def sgd(params, states, hyperparams):
for p in params:
p.data -= hyperparams['lr'] * p.grad.data训练函数:初始化一个线性回归模型。
# 本函数已保存在d2lzh_pytorch包中方便以后使用
def train_ch7(optimizer_fn, states, hyperparams, features, labels,
batch_size=10, num_epochs=2):
# 初始化模型
net, loss = d2l.linreg, d2l.squared_loss
w = torch.nn.Parameter(torch.tensor(np.random.normal(0, 0.01, size=(features.shape[1], 1)), dtype=torch.float32),
requires_grad=True)
b = torch.nn.Parameter(torch.zeros(1, dtype=torch.float32), requires_grad=True)
def eval_loss():
return loss(net(features, w, b), labels).mean().item()
ls = [eval_loss()]
data_iter = torch.utils.data.DataLoader(
torch.utils.data.TensorDataset(features, labels), batch_size, shuffle=True)
for _ in range(num_epochs):
start = time.time()
for batch_i, (X, y) in enumerate(data_iter):
l = loss(net(X, w, b), y).mean() # 使用平均损失
# 梯度清零
if w.grad is not None:
w.grad.data.zero_()
b.grad.data.zero_()
l.backward()
optimizer_fn([w, b], states, hyperparams) # 迭代模型参数
if (batch_i + 1) * batch_size % 100 == 0:
ls.append(eval_loss()) # 每100个样本记录下当前训练误差
# 打印结果和作图
print('loss: %f, %f sec per epoch' % (ls[-1], time.time() - start))
d2l.set_figsize()
d2l.plt.plot(np.linspace(0, num_epochs, len(ls)), ls)
d2l.plt.xlabel('epoch')
d2l.plt.ylabel('loss')当batch_size为1500时,为梯度下降。
def train_sgd(lr, batch_size, num_epochs=2):
train_ch7(sgd, None, {'lr': lr}, features, labels, batch_size, num_epochs)
train_sgd(1, 1500, 6)当batch_size为1时,为随机梯度下降。
train_sgd(0.005, 1)当批量大小为10时,优化使用的是小批量随机梯度下降。
train_sgd(0.05, 10)2、简洁实现
# 本函数与原书不同的是这里第一个参数优化器函数而不是优化器的名字
# 例如: optimizer_fn=torch.optim.SGD, optimizer_hyperparams={"lr": 0.05}
def train_pytorch_ch7(optimizer_fn, optimizer_hyperparams, features, labels,
batch_size=10, num_epochs=2):
# 初始化模型
net = nn.Sequential(
nn.Linear(features.shape[-1], 1)
)
loss = nn.MSELoss()
optimizer = optimizer_fn(net.parameters(), **optimizer_hyperparams)
def eval_loss():
return loss(net(features).view(-1), labels).item() / 2
ls = [eval_loss()]
data_iter = torch.utils.data.DataLoader(
torch.utils.data.TensorDataset(features, labels), batch_size, shuffle=True)
for _ in range(num_epochs):
start = time.time()
for batch_i, (X, y) in enumerate(data_iter):
# 除以2是为了和train_ch7保持一致, 因为squared_loss中除了2
l = loss(net(X).view(-1), y) / 2
optimizer.zero_grad()
l.backward()
optimizer.step()
if (batch_i + 1) * batch_size % 100 == 0:
ls.append(eval_loss())
# 打印结果和作图
print('loss: %f, %f sec per epoch' % (ls[-1], time.time() - start))
d2l.set_figsize()
d2l.plt.plot(np.linspace(0, num_epochs, len(ls)), ls)
d2l.plt.xlabel('epoch')
d2l.plt.ylabel('loss')train_pytorch_ch7(optim.SGD, {"lr": 0.05}, features, labels, 10)小结:
- 小批量随机梯度每次随机均匀采样一个小批量的训练样本来计算梯度。
- 在实际中,(小批量)随机梯度下降的学习率可以在迭代过程中自我衰减。
- 通常,小批量随机梯度在每个迭代周期的耗时介于梯度下降和随机梯度下降的耗时之间。
四、动量法
1、梯度下降的问题
目标函数有关自变量的梯度代表了目标函数在自变量当前位置下降最快的方向。因此,梯度下降也叫作最陡下降(steepest descent)。在每次迭代中,梯度下降根据自变量当前位置,沿着当前位置的梯度更新自变量。然而,如果自变量的迭代方向仅仅取决于自变量当前位置,这可能会带来一些问题。
考虑一个二维向量输入:。目标函数为
。
%matplotlib inline
import sys
sys.path.append("..")
import d2lzh_pytorch as d2l
import torch
eta = 0.4 # 学习率
def f_2d(x1, x2):
return 0.1 * x1 ** 2 + 2 * x2 ** 2
def gd_2d(x1, x2, s1, s2):
return (x1 - eta * 0.2 * x1, x2 - eta * 4 * x2, 0, 0)
d2l.show_trace_2d(f_2d, d2l.train_2d(gd_2d))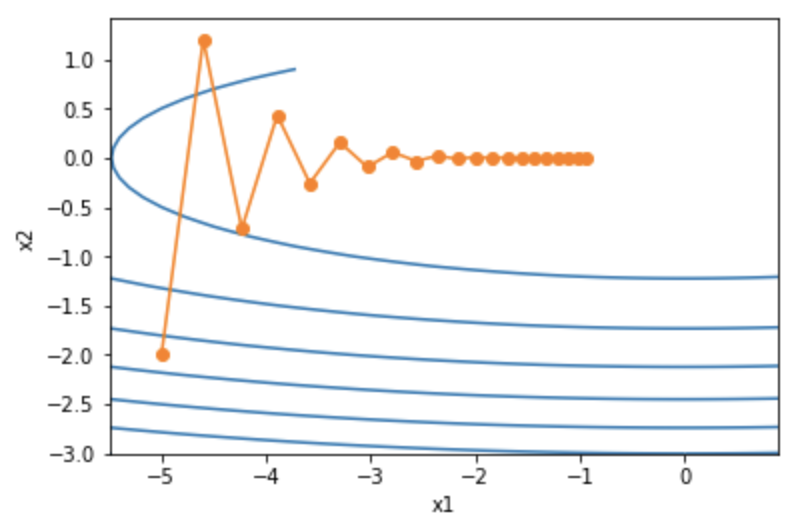
发现问题:同一位置上,目标函数在竖直方向(x2轴方向)比在水平方向(x1轴方向)的斜率的绝对值更大。 因此,给定学习率,梯度下降迭代自变量时会使自变量在竖直方向比在水平方向移动幅度更大。那么,我们需要一个较小的学习率从而避免自变量在竖直方向上越过目标函数最优解。然而,这会造成自变量在水平方向上朝最优解移动变慢。
2、动量法
动量法的提出是为了解决梯度下降的上述问题。
沿用上一节(小批量随机梯度下降)中时间步 t 的小批量随机梯度的定义
设时间步 t 的自变量为,学习率为
。在时间步0,动量法创建速度变量
,并将其元素初始化成0。在时间步
,动量法对每次迭代的步骤做如下修改:
其中,动量超参数满足
。当
时,动量法等价于小批量随机梯度下降。
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 6982
6982

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









