




 本文深入介绍了循环神经网络的基础原理及其实现,涵盖了语言模型、RNN的数学模型、梯度计算、门控机制等核心内容,并探讨了GRU、LSTM等高级结构,最后讨论了RNN的深化和变种。
本文深入介绍了循环神经网络的基础原理及其实现,涵盖了语言模型、RNN的数学模型、梯度计算、门控机制等核心内容,并探讨了GRU、LSTM等高级结构,最后讨论了RNN的深化和变种。

第六章 循环神经网络
与之前介绍的多层感知机和能有效处理空间信息的卷积神经网络不同,循环神经网络是为更好地处理时序信息而设计的。
它引入状态变量来存储过去的信息,并用其与当前的输入共同决定当前的输出。
循环神经网络常用于处理序列数据,如一段文字或声音、购物或观影的顺序,甚至是图像中的一行或一列像素。因此,循环神经网络有着极为广泛的实际应用,如语言模型、文本分类、机器翻译、语音识别、图像分析、手写识别和推荐系统。
本章中的应用是基于语言模型的,所以我们将先介绍语言模型的基本概念,并由此激发循环神经网络的设计灵感。接着,我们将描述循环神经网络中的梯度计算方法,从而探究循环神经网络训练可能存在的问题。对于其中的部分问题,我们可以使用本章稍后介绍的含门控的循环神经网络来解决。最后,我们将拓展循环神经网络的架构。
一、语言模型:
语言模型(language model)是自然语言处理(NLP)的重要技术。自然语言处理中最常见的数据是文本数据。我们可以把一段自然语言文本看作一段离散的时间序列。假设一段长度为T的文本中的词依次为,那么在离散的时间序列中,
可看作在时间步(time step) t 的输出或标签。给定一个长度为T的词的序列
,语言模型将计算该序列的概率:
。
语言模型可用于提升语音识别和机器翻译的性能。
例如,在语音识别中,给定一段“厨房里食油用完了”的语音,有可能会输出“厨房里食油用完了”和“厨房里石油用完了”这两个读音完全一样的文本序列。如果语言模型判断出前者的概率大于后者的概率,我们就可以根据相同读音的语音输出“厨房里食油用完了”的文本序列。
在机器翻译中,如果对英文“you go first”逐词翻译成中文的话,可能得到“你走先”“你先走”等排列方式的文本序列。如果语言模型判断出“你先走”的概率大于其他排列方式的文本序列的概率,我们就可以把“you go first”翻译成“你先走”。
类似于分类softmax,哪个概率大,输出哪个类别。
1、语言模型的计算:
语言模型计算方法:假设序列中的每个词是依次生成的,我们有
。
一段含有4个词的文本序列的概率:。
为了计算语言模型,我们需要计算词的概率,以及一个词在给定前几个词的情况下的条件概率,即语言模型参数。设训练数据集为一个大型文本语料库,如维基百科的所有条目。词的概率可以通过该词在训练数据集中的相对词频来计算。例如,P(w1)可以计算为w1在训练数据集中的词频(词出现的次数)与训练数据集的总词数之比。因此,根据条件概率定义,一个词在给定前几个词的情况下的条件概率也可以通过训练数据集中的相对词频计算。例如,P(w2∣w1)可以计算为w1,w2两词相邻的频率与w1词频的比值,因为该比值即P(w1,w2)与P(w1)之比;而P(w3∣w1,w2)同理可以计算为w1、w2和w3三词相邻的频率与w1和w2两词相邻的频率的比值。以此类推。
2、n元语法:
当序列长度增加时,计算和存储多个词共同出现的概率的复杂度会呈指数级增加。n元语法通过马尔可夫假设(虽然并不一定成立)简化了语言模型的计算。这里的马尔可夫假设是指一个词的出现只与前面n个词相关,即n阶马尔可夫链(Markov chain of order n)。
一个词的出现只与前面n个词相关——马尔科夫假设。
切断长链,因为太长的链,前后关系不再紧密,或者说数值太小。只取与之最近的n个元素。
过长的链,需要运算和存储大量的词频和多词相邻频率。
如果n = 1,那么有。第三个值,只于第二个值有关。第T个值,只与T-1那个值有关。如果基于n-1阶马尔科夫链,我们可以将语言模型改写为
。以上也叫n元语法(n-grams)。它是基于n-1阶马尔科夫链的概率语言模型。当n分别为1、2和3时,我们将其分别称作一元语法(unigram)、二元语法(bigram)和三元语法(trigram)。
长度为4的序列w1,w2,w3,w4在一元语法、二元语法和三元语法中的概率分别为
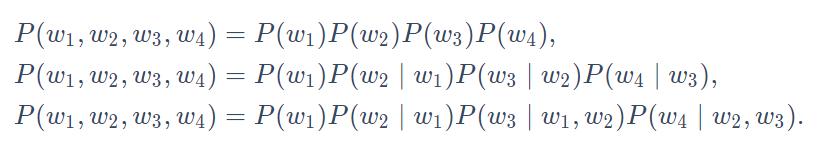
n元语法的Trade-off。
-
当n较小时,nnn元语法往往并不准确。例如,在一元语法中,由三个词组成的句子“你走先”和“你先走”的概率是一样的。
-
当n较大时,n元语法需要计算并存储大量的词频和多词相邻频率。
小结:
-
语言模型是自然语言处理的重要技术。
-
N元语法是基于n−1阶马尔可夫链的概率语言模型,其中n权衡了计算复杂度和模型准确性。
二、循环神经网络:
上一节介绍的n元语法中,时间步 t 的词 基于前面所有词的条件概率只考虑了最近时间步的 n−1 个词。如果要考虑比 t−(n−1) 更早时间步的词对
的可能影响,我们需要增大n。但这样模型参数的数量将随之呈指数级增长。
本节将介绍循环神经网络。它并非刚性地记忆所有固定长度的序列,而是通过隐藏状态来存储之前时间步的信息。首先我们回忆一下前面介绍过的多层感知机,然后描述如何添加隐藏状态来将它变成循环神经网络。
1、不含隐藏状态的神经网络
我们考虑一个含但隐藏层的多层感知机。隐藏层输出:。输出层输出为
。如果是分类问题,使用softmax(O)来计算输出类别的概率分布。
2、含隐藏状态的循环神经网络

现在我们考虑输入数据存在时间相关性的情况:
假设是序列中时间步为 t 的小批量输入,
是该时间步的隐藏变量。与多层感知机不同的是,这里我们保存上一步时间步的隐藏变量
,并引入一个新的权重参数
,该参数用来描述在当前时间步如何使用上一时间步的隐藏变量。
具体来说,时间步 t 的隐藏变量的计算由当前时间步的输⼊和上⼀时间步的隐藏变量共同决定:
。
与多层感知机相比,我们在这里添加了一项。
由上式中相邻时间步的隐藏变量 和
之间的关系可知,这里的隐藏变量能够捕捉截止至当前时间步的序列的历史信息,就像是神经网络当前时间步的状态或记忆一样。因此,该隐藏变量也称为隐藏状态。
由于隐藏状态在当前时间步的定义使用了上一时间步的隐藏状态,上式的计算是循环的。使用循环计算的网络即循环神经网络(recurrent neural network)RNN。
在时间步 t,输出层的输出和多层感知机中的计算类似:。
即便在不同时间步,循环神经网络也始终使用这些模型参数。因此,循环神经网络模型参数的数量不随时间步的增加而增长。
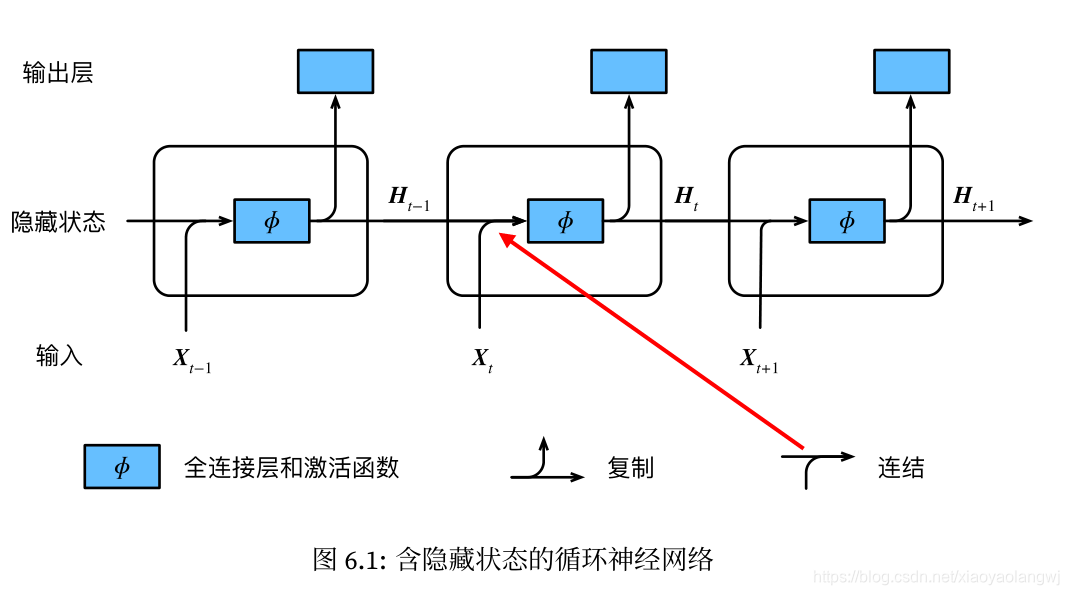
图6.1展示了循环神经网络在3个相邻时间步的计算逻辑。
在时间步t,隐藏状态的计算可以看成是将输入和前一时间步隐藏状态
连结后输入一个激活函数为 ϕ 的全连接层。该全连接层的输出就是当前时间步的隐藏状态
,且模型参数为
与
的连结,偏差为
。当前时间步t的隐藏状态
将参与下一个时间步t+1的隐藏状态
的计算,并输入到当前时间步的全连接输出层。
隐藏状态中的计算等价于
与
连结后的矩阵乘以
与
连结后的矩阵。
3、应用:基于字符级循环神经网络的语言模型
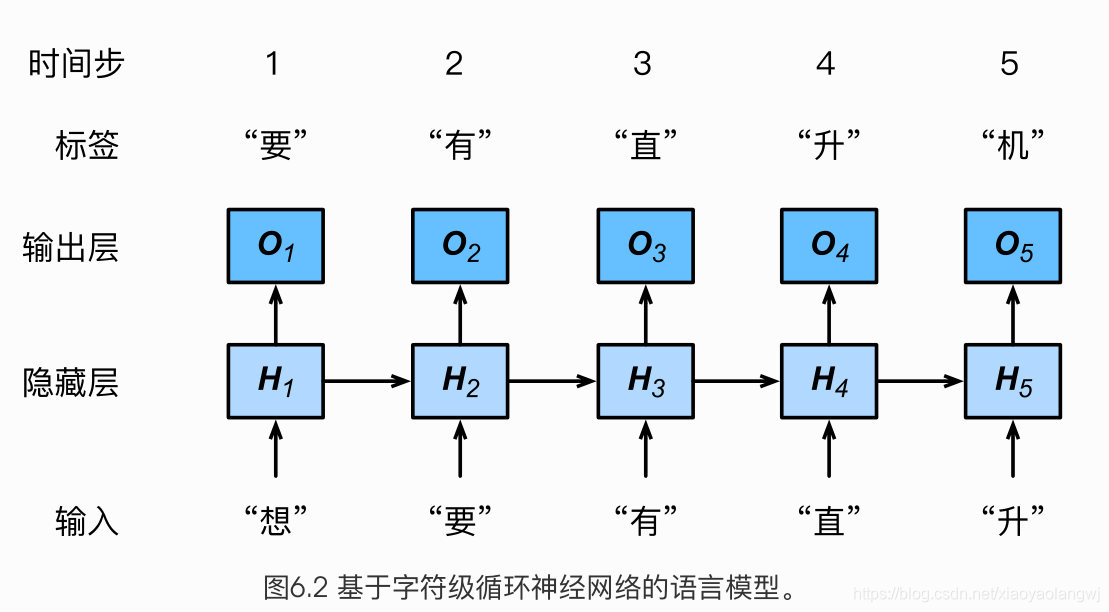
因为每个输入词是一个字符,因此这个模型被称为字符级循环神经网络(character-level recurrent neural network)。因为不同字符的个数远小于不同词的个数(对于英文尤其如此),所以字符级循环神经网络的计算通常更加简单。在接下来的几节里,我们将介绍它的具体实现。
小结:
-
使用循环计算的网络即循环神经网络。
-
循环神经网络的隐藏状态可以捕捉截至当前时间步的序列的历史信息。
-
循环神经网络模型参数的数量不随时间步的增加而增长。
-
可以基于字符级循环神经网络来创建语言模型。
三、语言模型数据集:
数据集准备周杰伦第一张专辑到第十张专辑的歌词。
1、读取数据集
import torch
import random
import zipfile
with zipfile.ZipFile('../../data/jaychou_lyrics.txt.zip') as zin:
with zin.open('jaychou_lyrics.txt') as f:
corpus_chars = f.read().decode('utf-8')
corpus_chars[:40]'想要有直升机\n想要和你飞到宇宙去\n想要和你融化在一起\n融化在宇宙里\n我每天每天每'这个数据集有6万多个字符。为了打印方便,我们把换行符替换成空格,然后仅使用前1万个字符来训练模型。
corpus_chars = corpus_chars.replace('\n', ' ').replace('\r', ' ')
corpus_chars = corpus_chars[0:10000]2、建立字符索引
我们将每个字符映射成一个从0开始的连续整数,又称索引,来方便之后的数据处理。为了得到索引,我们将数据集里所有不同字符取出来,然后将其逐一映射到索引来构造词典。接着,打印vocab_size,即词典中不同字符的个数,又称词典大小。
# 二、建立字符索引
# 每个字符映射成一个从0开始的连续整数,又称索引,来方便数据处理。为建立字符,将不同字符取出来,逐一映射到索引来构造词典。
idx_to_char = list(set(corpus_chars)) # 集合set的形式去重。得到最大索引值下的无序字符列表。此时,列表中字符的排序位置,就是索引。
char_to_idx = dict([(char, i) for i, char in enumerate(idx_to_char)])
vocab_size = len(char_to_idx) # 字典长度,即索引个数。一个字符一个数字。一一对应。
print(vocab_size)  最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 1528
1528

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









