




一、cuda/gpu线程模型
1、cuda线程模型
核函数调用方法如下:
xxx_xxx_xxx<<<grid_size, block_size>>>(函数参数);
以上核函数调用会在gpu中创建grid_size * block_size个线程并行执行核函数内容
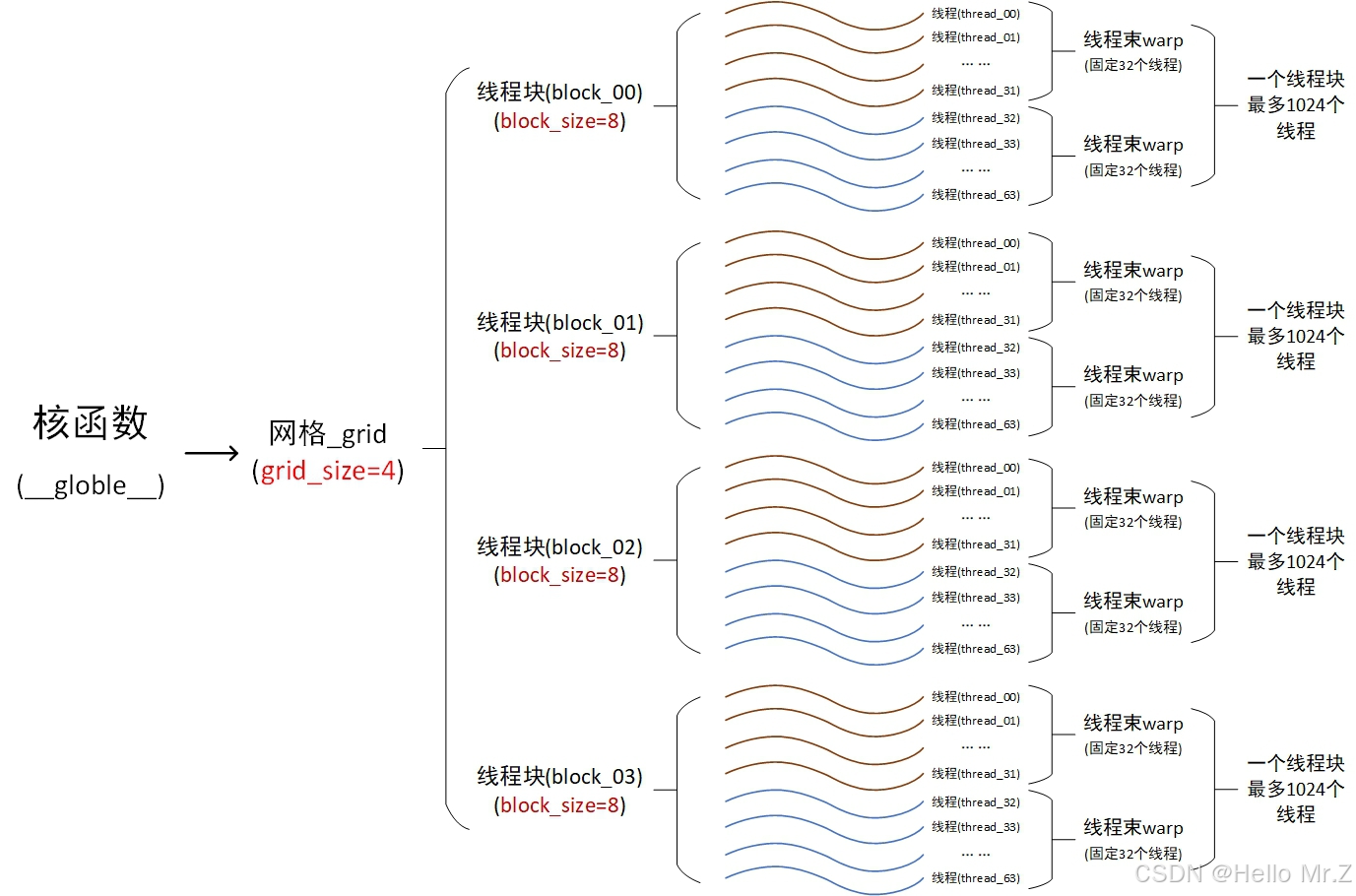
- 一维时:grid_size为一维时最大值
 ,block_size最大值1024;
,block_size最大值1024; - 三维时:grid_size.x/grid_size.y/grid_size.z最大值/65535/65535,block_size.x/block_size.y/block_size.z最大值1024/1024/64,且block_size.x*block_size.y*block_size.z不能大于1024。
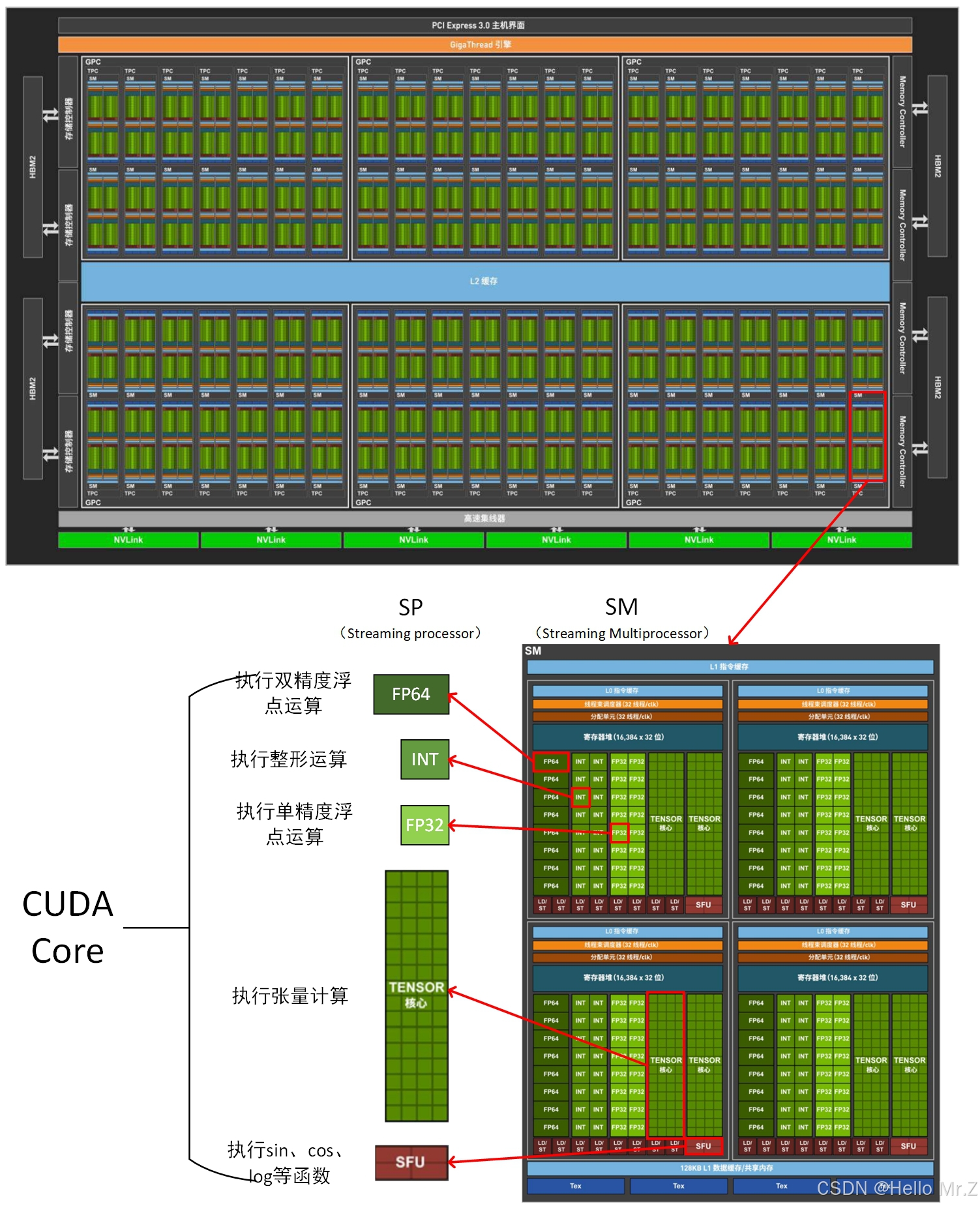
2、GPU线程模型
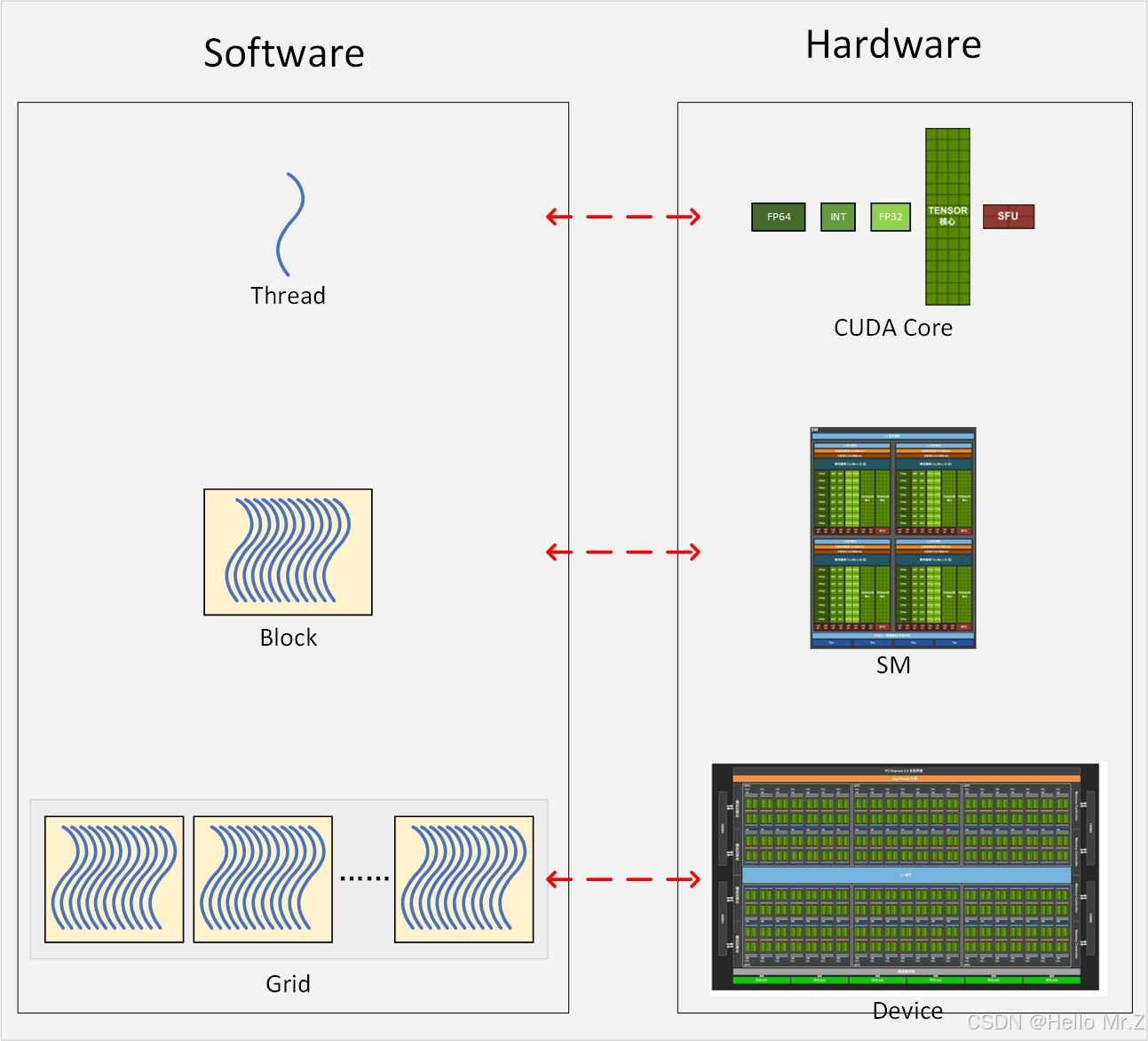
3、cuda线程模型与GPU线程模型对应关系
二、cuda/gpu内存模型
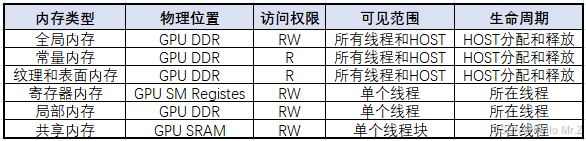

1、PageableMemory(HOST分页内存,位于HOST DDR):
1、主机使用malloc()/free();
2、主机使用,GPU不能使用;
3、在stream中如果使用了异步数据传输,不能使用该类型的Memory。
2、PinnedMemory(固定内存,位于HOST DDR):
1、使用cudaMallocHost()/cudaHostAlloc()/cudaFreeHost();
2、GPU可通过DMA访问的Host Memory;
3、在stream中如果使用了异步数据传输,需要使用该类型的Memory。
3、GlobalMemory(全局内存,位于GPU DDR):
1、全局内存:cudaMallc()/cudaFree();
2、静态全局内存变量:核函数外__device__;
3、常量内存:核函数外__constant__;
4、纹理内存/表面内存;
5、局部内存:在核函数内定义的不加任何修定符的变量在寄存器内存装不下时。
6、全局内存的合并传输?
4、SharedMemory(共享内存,位于GPU SM SRAM):
1、类似于寄存器内存,区别是整个线程块可见;
2、静态共享内存使用__shared__修饰,声明时需要指定大小;
3、动态共享内存使用extern __shared__修饰,声明时不能指定大小,在调用核函数时指定每个线程使用的共享内存大小:
xxx_xxx_xxx<<<grid_size, block_size, SharedMemorySize>>>(函数参数);
4、共享内存因为更靠近计算单元,所以访问速度更快;
5、共享内存通常可以作为访问全局内存的缓存使用;
6、可以利用共享内存实现线程间的通信;
7、通常与__syncthreads同时出现,这个函数是同步block内的所有线程,全部执行到这一行才往下走;
8、使用方式,通常是在线程id为0的时候从global memory取值,然后syncthreads,然后再使用。
9、共享内存bank冲突问题?
5、RegisterMemory(寄存器内存,位于GPU SM):
1、在核函数内定义的不加任何修定符的变量。
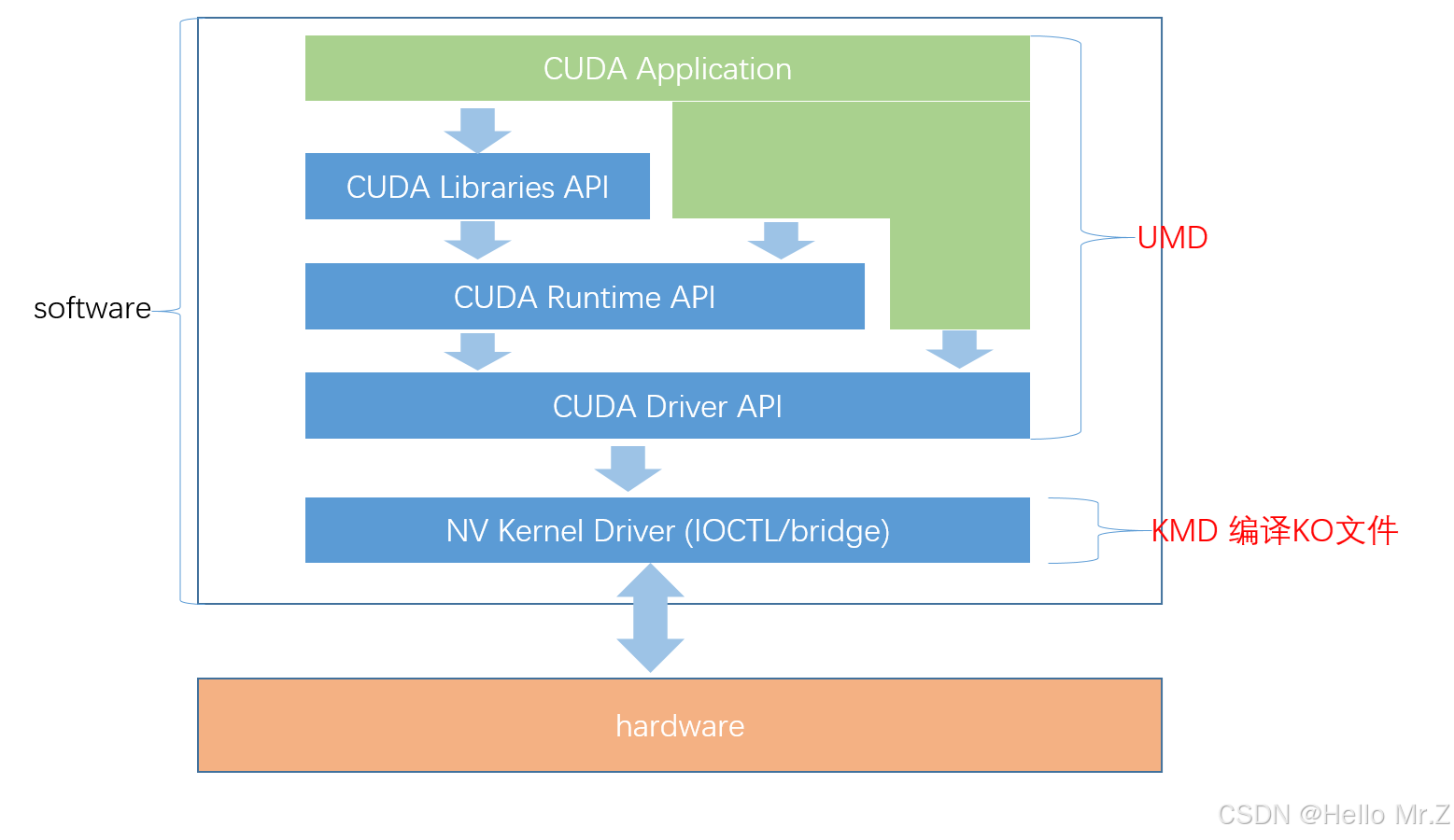
三、cuda runtime api
以cuda为前缀:CUDA Runtime API
四、cuda driver api
以cu为前缀:CUDA Driver API
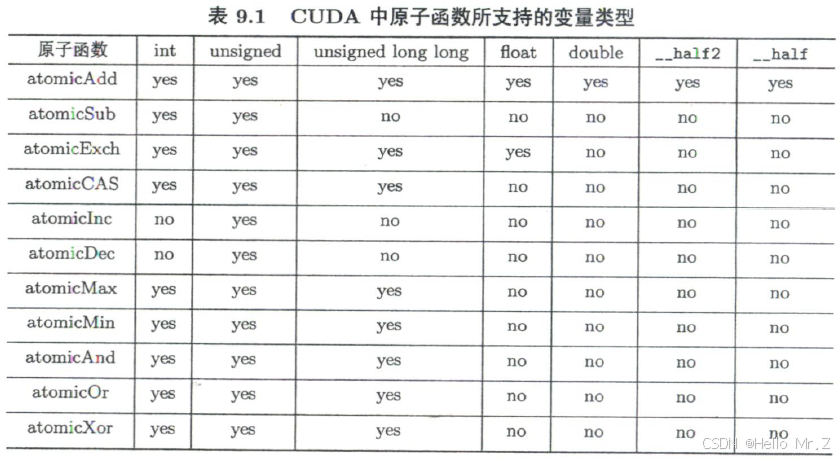
五、原子函数
atomicAdd、atomicSub、atomicExch、atomicCAS、atomicInc、atomicDec、atomicMax、atomicMin、atomicAnd、atomicOr、atomicXor
六、线程束
- SM按照线程束(包括32个线程)进行运算,一个线程块只能调度到一个SM,如一个线程块有128个线程,那就是4个线程束,这时会被调度到一个SM上,这个SM多度执行这4个线程束,一个SM最多可以驻留32个线程束,即最多32*32=1024个线程;
- 一个SM可以运行多个线程块,如线程块有16个线程,那么一个SM可以同时运行两个线程块。
1、线程束内基本函数
- unsigned __ballot_sync(unsigned mask, int predicate);
- int __all_sync(unsigned mask, int predicate);
- int __any_sync(unsigned mask, int preducate);
- T __shfl_sync(unsigned mask, T v, int srcLane, int w = warpSize);
- T __shfl_up_sync(unsigned mask, T v, unsigned d, int w = warpSize);
- T __shfl_down_sync(unsigned mask, T v, unsigned d, int w = warpSize);
- T __shfl_xor_sync(unsigned mask, T v, int laneMask, int w = warpSize);
- __syncwarp();
- reduce_shfl();
2、协作组-线程块片函数
- unsigned __ballot_sync(int predicate);
- int __all_sync(int predicate);
- int __any_sync(int predicate);
- T __shfl_sync(T v, int srcLane);
- T __shfl_up_sync(T v, unsigned d);
- T __shfl_down_sync(T v, unsigned d);
- T __shfl_xor_sync(T v, int laneMask);
七、常用cuda库
- Thrust:类似于C++的标准模板库(standard template library)
- cuBLAS:基本线性代数子函数(basic liner algebra subroutines)
- cuFFT:快速傅里叶变换(fast Fourier transforms)
- cuSPARSE:稀疏(sparse)矩阵
- cuRAND:随机数生成器(rendom number generator)
- cuSolver:稠密(dense)矩阵和稀疏矩阵计算库
- cuDNN:深度神经网络(deep neural networks)
八、context、stream、event
流是一种基于context之上的任务管道抽象,未显式调用函数创建stream时使用默认stream:default stream,在一个stream里的执行步骤都是顺序的,可以是阻塞也可以是非阻塞,如下示例:
cudaMemcpy(d_x, h_x, M, cudaMemcpyHostToDevice);
cudaMemcpy(d_y, h_y, M, cudaMemcpyHostToDevice);
sum<<<grid_size, block_size>>>(d_x, d_y, d_z, N);
cudaMemcpy(h_z, d_z, cudaMemcpyDeviceToHost);stream并行实现计算与通信重叠,通过创建stream可以同时运行多个CUDA stream,多个stream可实现核函数和通信的并行执行,stream的用法如下:
1、创建stream
cudaError_t cudaStreamCreate(cudaStream_t *); // 创建stream
cudaError_t cudaStreamDestroy(cudaStream_t); // 销毁stream
2、使用stream
xxx_kernel<<<grid_size, block_size>>>(函数参数):
xxx_kernel<<<grid_size, block_size, SharedMemorySize>>>(函数参数):
xxx_kernel<<<grid_size, block_size, SharedMemorySize, stream_id>>>(函数参数):
3、等待完成
cudaError_t cudaStreamSynchronize(cudaStream_t stream); // 阻塞等待完成
cudaError_t cudaStreamQuery(cudaStream_t stream); // 非阻塞检查完成状态
一个完成的示例如下:
int main(){
int device_id = 0;
checkRuntime(cudaSetDevice(device_id));
cudaStream_t stream = nullptr;
checkRuntime(cudaStreamCreate(&stream)); //创建一个流
// 在GPU上开辟空间
float* memory_device = nullptr;
checkRuntime(cudaMalloc(&memory_device, 100 * sizeof(float)));
// 在CPU上开辟空间并且放数据进去,将数据复制到GPU
float* memory_host = new float[100];
memory_host[2] = 520.25;
// 异步复制操作,主线程不需要等待复制结束才继续
checkRuntime(cudaMemcpyAsync(memory_device, memory_host, sizeof(float) * 100, cudaMemcpyHostToDevice, stream));
// 在CPU上开辟pin memory,并将GPU上的数据复制回来
float* memory_page_locked = nullptr;
checkRuntime(cudaMallocHost(&memory_page_locked, 100 * sizeof(float)));
checkRuntime(cudaMemcpyAsync(memory_page_locked, memory_device, sizeof(float) * 100, cudaMemcpyDeviceToHost, stream)); // 异步复制操作,主线程不需要等待复制结束才继续
printf("%f\n", memory_page_locked[2]);//结果是0,因为还没等待结果返回
checkRuntime(cudaStreamSynchronize(stream)); //统一等待流队列中的结果
printf("%f\n", memory_page_locked[2]);
// 释放内存
checkRuntime(cudaFreeHost(memory_page_locked));
checkRuntime(cudaFree(memory_device));
checkRuntime(cudaStreamDestroy(stream));
delete [] memory_host;
return 0;
}event用以监控stream是否到达了某个检查点,可实现多个stream同步,举例说明如下:
- 在stream 1上面执行kernel 1 和 kernel 3
- 在stream 2上面执行kernel 2,但是必须等到stream 1上面的kernel 1执行结束之后才能开始
// Create streams and event
cudaStream_t stream1, stream2;
cudaEvent_t event1;
cudaEventCreate(&event1);
// Execute kernel1 in stream1
kernel1<<<gridDim, blockDim, 0, stream1>>>(d_data1, repeat);
cudaEventRecord(event1, stream1); // Record event1 after kernel1 execution in stream1
// Execute kernel2 in stream2, waiting for event1
cudaStreamWaitEvent(stream2, event1, 0);
kernel2<<<gridDim, blockDim, 0, stream2>>>(d_data1, repeat);
// Execute kernel3 in stream1 on a different array
kernel3<<<gridDim, blockDim, 0, stream1>>>(d_data2, repeat);
// Synchronize streams
cudaStreamSynchronize(stream1);
cudaStreamSynchronize(stream2);
// Free device memory and destroy streams and event
cudaStreamDestroy(stream1);
cudaStreamDestroy(stream2);
cudaEventDestroy(event1);九、统一内存
1、动态统一内存在HOST端使用cudaMallocManaged()函数进行申请,使用cudaFree()函数释放,HOST即Device端使用时,无需进行Memory Copy而直接使用,如下示例:
int main(void)
{
const int N = 100000000;
const int M = sizeof(double) * N;
double *x, *y, *z;
CHECK(cudaMallocManaged((void **)&x, M));
CHECK(cudaMallocManaged((void **)&y, M));
CHECK(cudaMallocManaged((void **)&z, M));
for (int n = 0; n < N; ++n)
{
x[n] = a;
y[n] = b;
}
const int block_size = 128;
const int grid_size = N / block_size;
add<<<grid_size, block_size>>>(x, y, z);
CHECK(cudaDeviceSynchronize());
check(z, N);
CHECK(cudaFree(x));
CHECK(cudaFree(x));
CHECK(cudaFree(x));
return 0
}2、静态统一内存使用__device__ __managed__进行修饰,如下示例:
#include <stdio.h>
__device__ __managed__ int ret[1000];
__globle__ void AplusB(int a, int b)
{
ret[threadIdx.x] = a + b + threadIdx.x;
}
int main(void)
{
AplusB<<<1, 1000>>>(10, 100);
CHECK(cudaDeviceSynchronize());
for (int i = 0; i < 1000; i++)
{
printf("%d: A+B = %d\n", i, ret[i]);
}
return 0
}3、统一内存可以申请超出实际内存的容量,因为实际使用时才会涉及到物理内存,类似缺页异常,申请的统一内存可以使用gpu_touch()核函数进行全部内存的初始化,如果申请了超量的统一内存,使用gpu_touch()核函数进行初始化时,在超量的部分Memory会初始化失败;
4、统一内存如果涉及到HOST Memory+Device Memory,如果Device不访问这段统一内存,那么HOST只能访问到HOST部分的内存,及时让Device使用cudaMemAdvise()/cudaMemPreftchAsync()函数同步一下统一内存,HOST才能访问到全部的统一内存,参考代码如下:
int main(void)
{
int device_id = 0;
CHECK(cudaGetDevice(&device_id));
const int N = 100000000;
const int M = sizeof(double) * N;
double *x, *y, *z;
CHECK(cudaMallocManaged((void **)&x, M));
CHECK(cudaMallocManaged((void **)&y, M));
CHECK(cudaMallocManaged((void **)&z, M));
for (int n = 0; n < N; ++n)
{
x[n] = a;
y[n] = b;
}
const int block_size = 128;
const int grid_size = N / block_size;
CHECK(cudaMemPrefetchAsync(x, M, device_id, NULL));
CHECK(cudaMemPrefetchAsync(y, M, device_id, NULL));
CHECK(cudaMemPrefetchAsync(z, M, device_id, NULL));
add<<<grid_size, block_size>>>(x, y, z);
CHECK(cudaFree(x));
CHECK(cudaMemPrefetchAsync(z, M, cudaCpuDeviceId, NULL));
CHECK(cudaDeviceSynchronize());
check(z, N);
CHECK(cudaFree(x));
CHECK(cudaFree(y));
CHECK(cudaFree(z));
return 0;
}十、疑问
1、核函数怎么被加载到gpu,gpu怎么运行核函数?
2、runtime/driver api怎么与KMD交互?
3、卷积、激活、池化、归一化、标量、向量、矩阵、张量?
GPU软件抽象与硬件映射的理解(Grid、Block、Warp、Thread与SM、SP)
GPU架构
GPU架构与通信互联技术介绍
CUDA运行API:RuntimeAPI
NVIDA CUDA-DirverAPI入门
具体化,讲解cuda runtime api是什么,runtime driver是什么
【YOLO系列】YOLOv5超详细解读(源码详解+入门实践+改进)
一文说清楚,DeePSeek用的PTX与CUDA的区别
自定义CUDA实现PyTorch算子的四种简单方法
PhD 第四学期 年中随笔
矩阵分解之: 特征值分解(EVD)、奇异值分解(SVD)、SVD++
cuda runtime/driver API解析
【CUDA】Driver API 和 Runtime API
https://www.zhihu.com/people/li-wei-27-70-68/posts

















 1784
1784

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









