




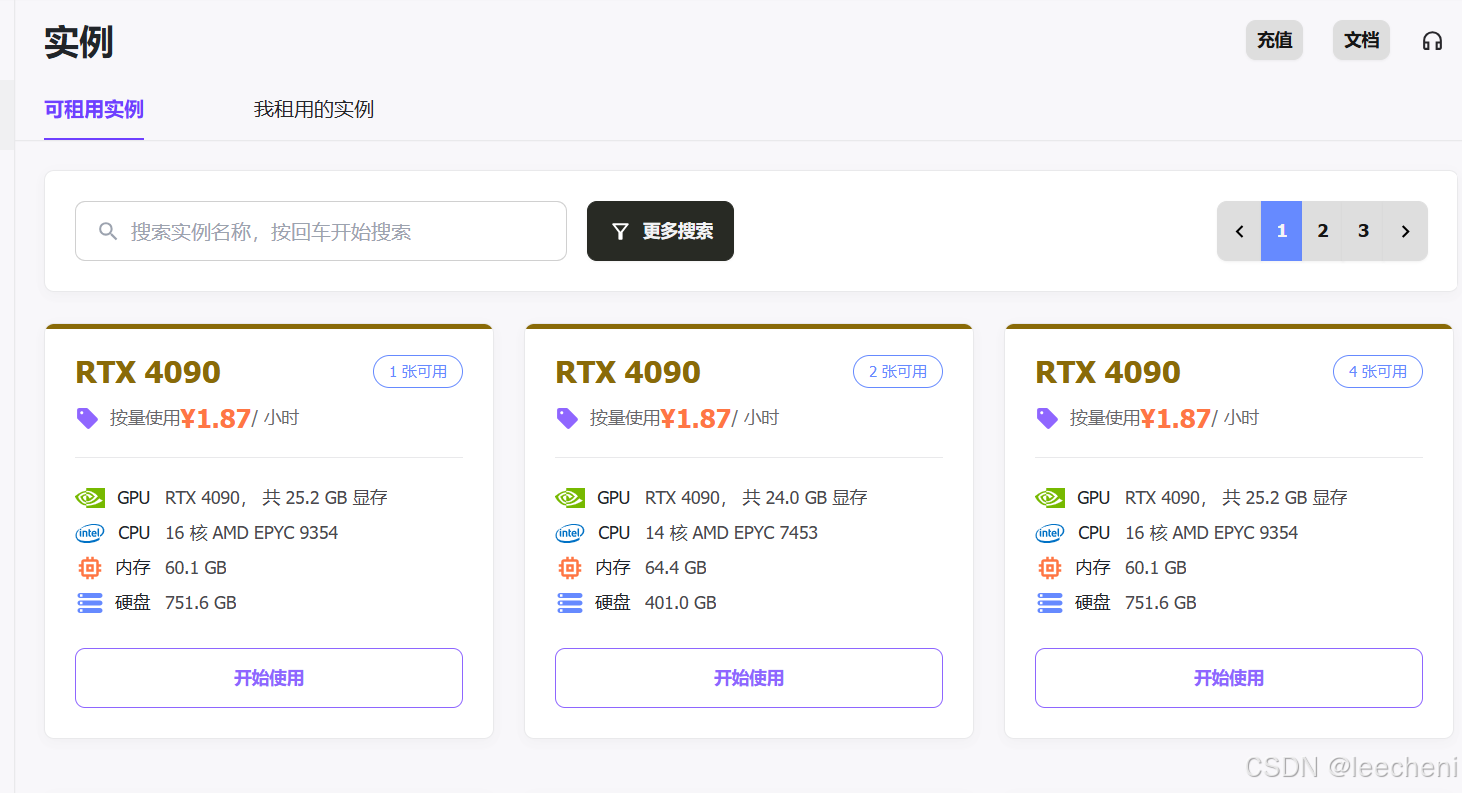
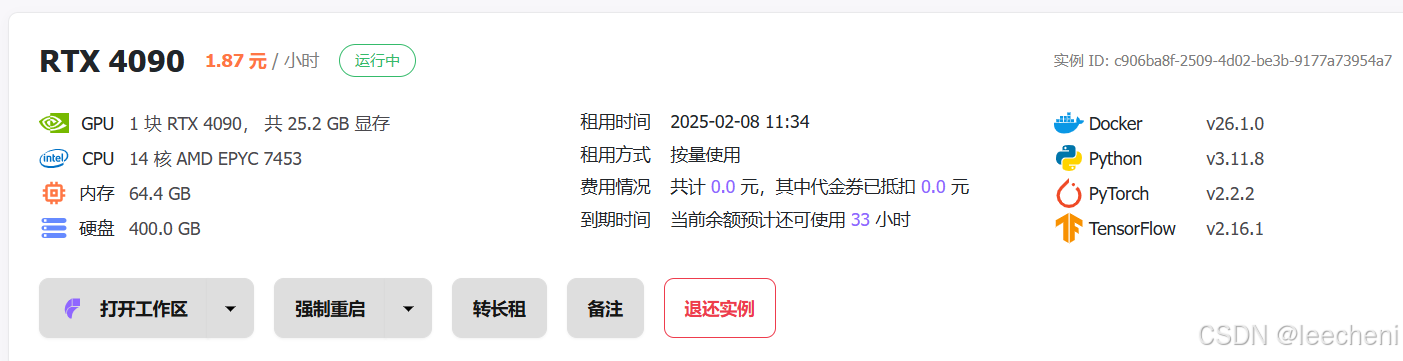
1.租用featurize上实例
2.安装ollama
curl -fsSL https://ollama.com/install.sh | sh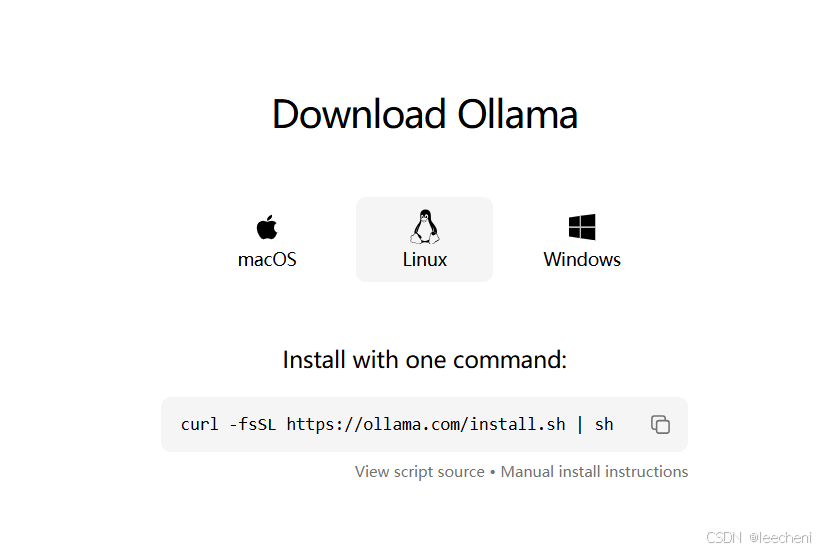
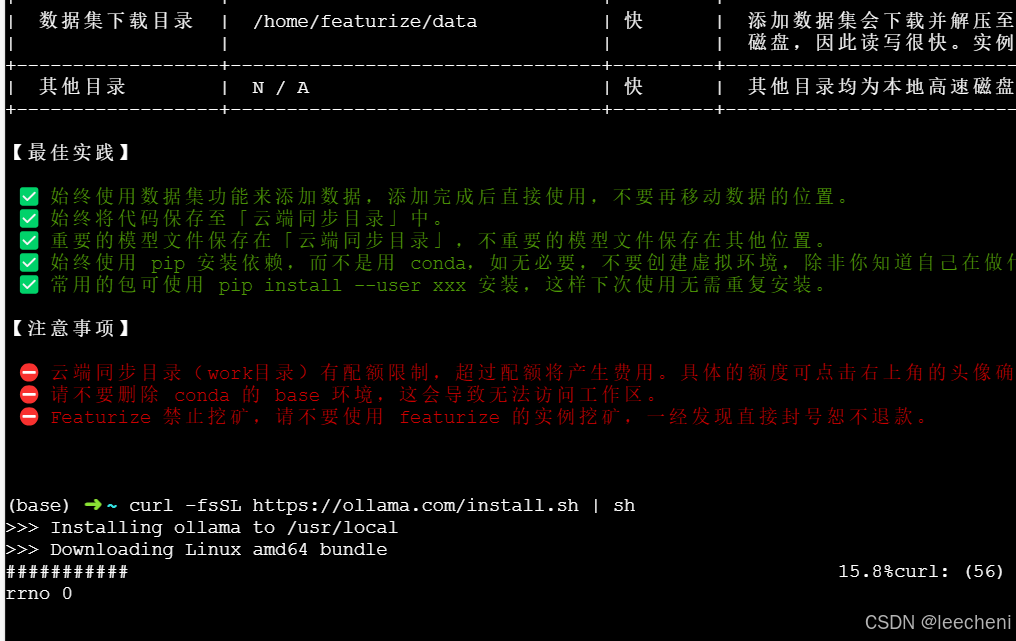
当输入ollama可以识别这个命令的时候就是安装完成了。
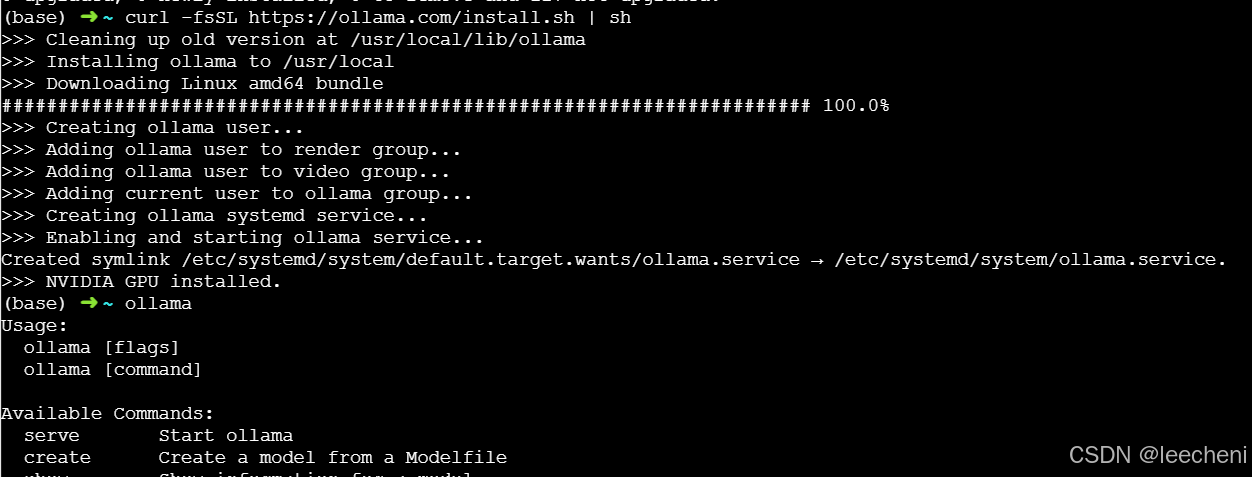
3.安装 deepseek-r1:32b
在这个虚拟机上的下载速度可以达到32M左右,速度还是可以的。
ollama run deepseek-r1:32b
ollama run deepseek-r1:32b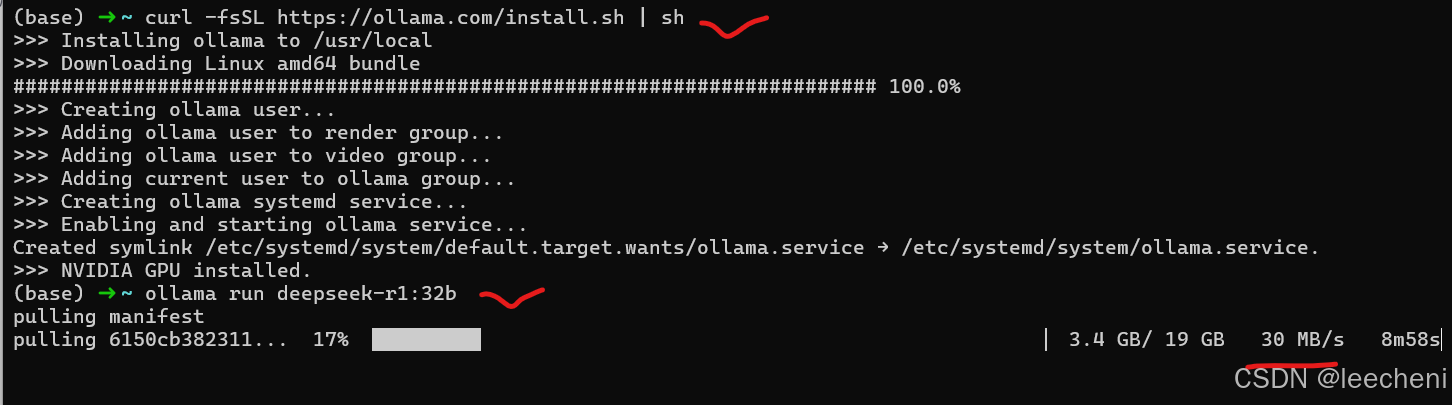
后面速度慢了可以ctrl+C终止掉再来一次,不影响已经下载的。

4.测试答复如何
直接问答就好,这个命令就是运行这个模型的。
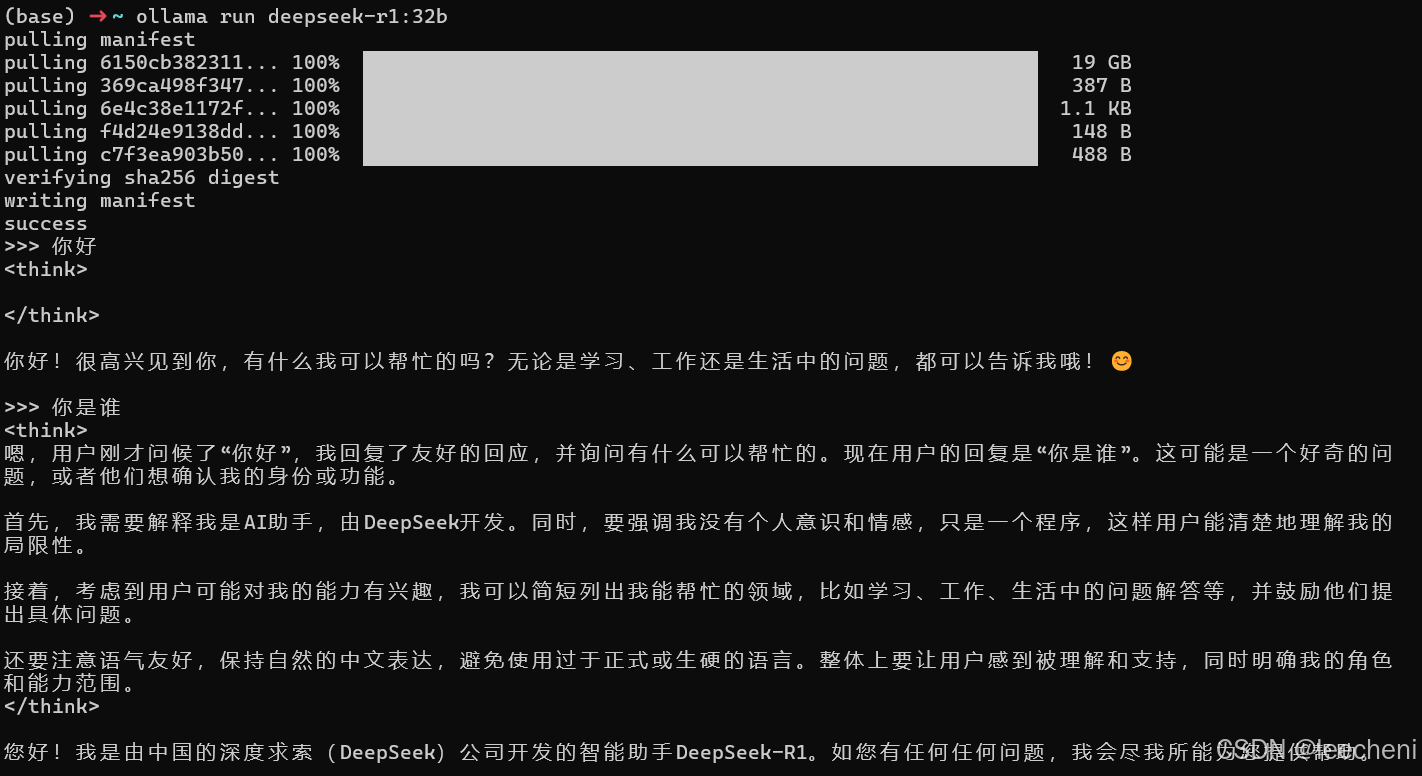
怎么退出按Ctrl+d或者输入/bye就可以退出,下次怎么进来,还是这个命令就可以了。
ollama run deepseek-r1:32b
5.如何查看相关模型命令
OllamaGet up and running with large language models.![]() https://ollama.com/search?q=deepseek
https://ollama.com/search?q=deepseek
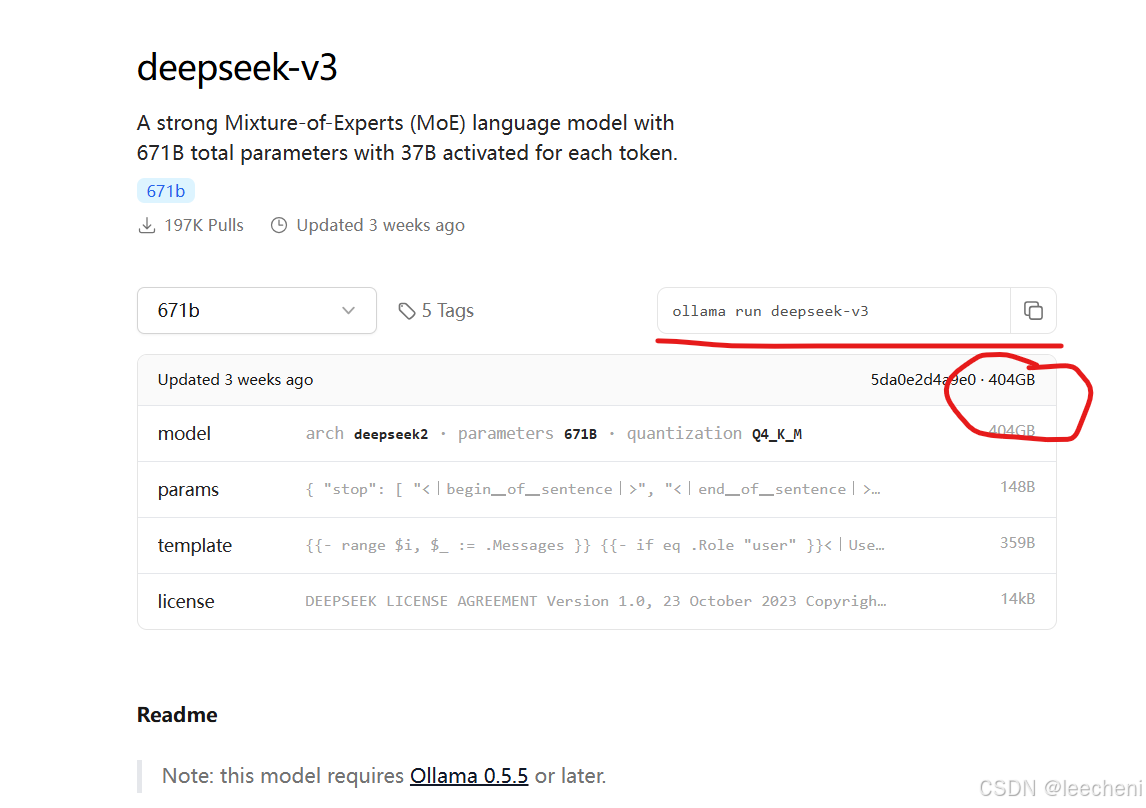
点击进去后可以看到模型有多大,如v3有404G,就要评估一下下载时间了。



















 2902
2902

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











