







系列篇章💥
| No. | 文章 |
|---|---|
| 01 | 【DeepSeek应用实践】DeepSeek接入Word、WPS方法详解:无需代码,轻松实现智能办公助手功能 |
| 02 | 【DeepSeek应用实践】通义灵码 + DeepSeek:AI 编程助手的实战指南 |
| 03 | 【DeepSeek应用实践】Cline集成DeepSeek:开源AI编程助手,终端与Web开发的超强助力 |
| 04 | 【DeepSeek开发入门】DeepSeek API 开发初体验 |
| 05 | 【DeepSeek开发入门】DeepSeek API高级开发指南(推理与多轮对话机器人实践) |
| 06 | 【DeepSeek开发入门】Function Calling 函数功能应用实战指南 |
| 07 | 【DeepSeek部署实战】DeepSeek-R1-Distill-Qwen-7B:本地部署与API服务快速上手 |
| 08 | 【DeepSeek部署实战】DeepSeek-R1-Distill-Qwen-7B:Web聊天机器人部署指南 |
| 09 | 【DeepSeek部署实战】DeepSeek-R1-Distill-Qwen-7B:基于vLLM 搭建高性能推理服务器 |
| 10 | 【DeepSeek部署实战】基于Ollama快速部署DeepSeek-R1系列模型实战指南(Linux) |
| 11 | 【DeepSeek部署实战】基于Ollama+Chatbox零成本部署DeepSeek-R1系列模型攻略(Windows) |
| 12 | 【DeepSeek开发实战】DeepSeek-R1-Distill-Qwen与LangChain的本地大模型应用开发指南 |
目录
前言
大语言模型的落地应用离不开高效推理框架的支持,vLLM以其卓越的性能在众多框架中脱颖而出。本文将带你深入探索如何使用vLLM框架部署DeepSeek-R1-Distill-Qwen大语言模型,无论是深度学习新手还是有经验的开发者,都能从中获取实用的知识和技能。
一、vLLM框架特性解析
1、高效内存管理
在大模型推理中,内存管理至关重要。vLLM独创的PagedAttention算法,如同为显存空间安排了一位智能管家。它借鉴操作系统虚拟内存管理机制,实现了KV缓存的动态分页管理。这意味着,当模型处理大量数据时,不再需要一次性占用连续的显存空间,而是像拼积木一样,动态分配所需的显存块。在实际应用中,相较于传统方案,vLLM的内存利用率提升高达24倍,这使得在有限的显存条件下,也能高效运行大模型,大大降低了硬件门槛。
2、吞吐量王者
vLLM在推理速度上堪称王者。它支持连续批处理(Continuous Batching)和异步推理,就像一位高效的流水线工人,在A100 GPU上实测,吞吐量可达HuggingFace Transformers的24倍。在处理长文本生成任务时,这种优势更为显著。连续批处理技术让vLLM无需等待前一批次推理完成,就能马不停蹄地接收新任务,充分榨干GPU的计算资源;异步推理则进一步提升了系统的并发处理能力,让多个推理任务并行执行,大大提高了整体处理效率。
3、无缝生态集成
生态兼容性是vLLM的又一亮点。它与HuggingFace模型库完美兼容,支持超过50种主流大模型,这使得开发者可以轻松将vLLM融入现有的基于HuggingFace的开发流程中。同时,vLLM通过OpenAI API兼容设计,为现有基于ChatGPT的应用提供了便捷的迁移路径。开发者无需大规模修改代码,就能将应用迁移到使用vLLM框架的DeepSeek-R1-Distill-Qwen大语言模型上,极大地降低了技术迁移成本。
4、分布式推理支持
对于大规模推理任务,vLLM采用张量并行(Tensor Parallelism)技术,支持多GPU分布式推理。在4*A100的环境下实测,推理速度提升3.8倍。这就好比将多个小引擎组合成一个超级引擎,充分利用多块GPU的计算能力,实现大规模模型的快速推理,满足企业级应用对高并发、低延迟的需求。无论是在线服务还是离线分析场景,分布式推理都能显著提升系统性能和响应速度。
5、开源社区驱动
vLLM拥有活跃的开源社区,在GitHub上星标数已突破3.9万,官方Discord社区日活开发者超过500人。社区成员们积极交流经验、分享代码、提出建议,共同推动vLLM的发展。同时,vLLM持续保持每周3 - 5次的版本迭代更新,不断优化性能、修复漏洞、增加新功能,让开发者能够始终使用到最前沿的技术。
二、环境配置指南
1、基础环境要求
为了高效部署 DeepSeek-R1-Distill-Qwen,推荐使用 Ubuntu 22.04 LTS 操作系统、Python 3.12 环境、CUDA 12.1 与 PyTorch 2.3.0,并配备至少 24GB 显存的 NVIDIA GPU,以确保模型推理的高性能和稳定性。
2、安装相关依赖
# 配置清华镜像源加速下载
python -m pip install --upgrade pip
pip config set global.index-url https://pypi.tuna.tsinghua.edu.cn/simple
# 安装核心依赖包
pip install modelscope==1.22.3
pip install openai==1.61.0
pip install vllm==0.7.1
首先,将pip升级到最新版本,确保能使用最新的功能和特性。然后,将pip源配置为清华大学的镜像源,这样在下载依赖包时能显著提高下载速度,减少等待时间。接下来,依次安装核心依赖库。modelscope库提供灵活的模型下载和管理功能,方便获取DeepSeek-R1-Distill-Qwen模型;openai库用于与vLLM的OpenAI API兼容接口进行交互;vllm库则是本次部署的核心框架,实现高效的模型推理。
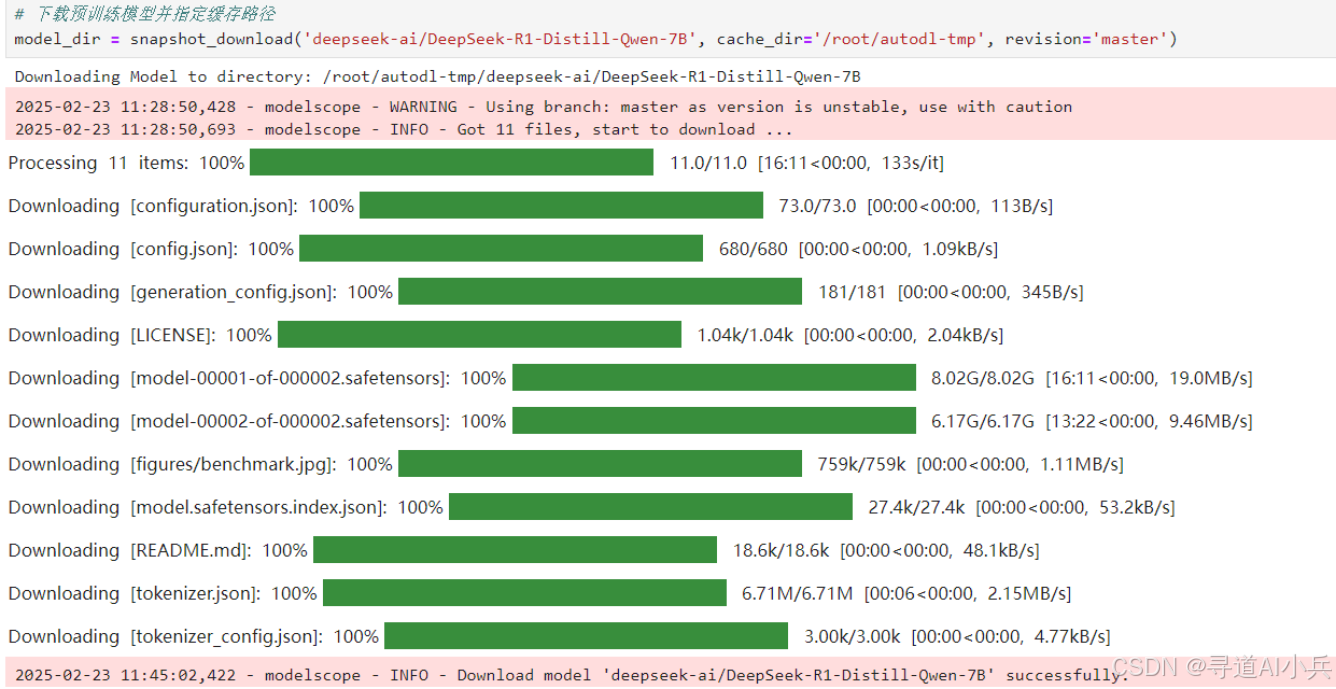
3、模型文件下载
from modelscope import snapshot_download
# 下载预训练模型并指定缓存路径
model_dir = snapshot_download('deepseek-ai/DeepSeek-R1-Distill-Qwen-7B', cache_dir='/root/autodl-tmp', revision='master')
这段代码用modelscope库的snapshot_download函数下载模型。deepseek-ai/DeepSeek-R1-Distill-Qwen-7B是模型在平台上的名字,cache_dir是你要把模型存到哪里,你可以自己改,revision='master’表示下最新版本。
三、模型推理实践
1、导入相关依赖包
from vllm import LLM, SamplingParams
from transformers import AutoTokenizer
import os
import json
# 自动下载模型时,指定使用modelscope; 否则,会从HuggingFace下载
os.environ['VLLM_USE_MODELSCOPE']='True'
2、定义LLM处理函数
def get_completion(prompts, model, tokenizer=None, max_tokens=8192, temperature=0.6, top_p=0.95, max_model_len=2048):
stop_token_ids = [151329, 151336, 151338]
# 创建采样参数。temperature 控制生成文本的多样性,top_p 控制核心采样的概率
sampling_params = SamplingParams(temperature=temperature, top_p=top_p, max_tokens=max_tokens, stop_token_ids=stop_token_ids)
# 初始化 vLLM 推理引擎
llm = LLM(model=model, tokenizer=tokenizer, max_model_len=max_model_len,trust_remote_code=True)
outputs = llm.generate(prompts, sampling_params)
return outputs
3、指定模型地址&定义消息
# 初始化 vLLM 推理引擎
model='/root/autodl-tmp/deepseek-ai/DeepSeek-R1-Distill-Qwen-7B' # 指定模型路径
# model="deepseek-ai/DeepSeek-R1-Distill-Qwen-7B" # 指定模型名称,自动下载模型
tokenizer = None
# 加载分词器后传入vLLM 模型,但不是必要的。
# tokenizer = AutoTokenizer.from_pretrained(model, use_fast=False)
text = ["请帮我推荐一种深圳到北京的出行方式<think>\n", ]
# 可用 List 同时传入多个 prompt,根据 DeepSeek 官方的建议,每个 prompt 都需要以 <think>\n 结尾,
#如果是数学推理内容,建议包含(中英文皆可):Please reason step by step, and put your final answer within \boxed{}.
# messages = [
# {"role": "user", "content": prompt+"<think>\n"}
# ]
# 作为聊天模板的消息,不是必要的。
# text = tokenizer.apply_chat_template(
# messages,
# tokenize=False,
# add_generation_prompt=True
# )
4、获取输出结果
# 思考需要输出更多的 Token 数,max_tokens 设为 8K,根据 DeepSeek 官方的建议,temperature应在 0.5-0.7,推荐 0.6
outputs = get_completion(text, model, tokenizer=tokenizer, max_tokens=8192, temperature=0.6, top_p=0.95, max_model_len=2048)
# 输出是一个包含 prompt、生成文本和其他信息的 RequestOutput 对象列表。
# 打印输出。
for output in outputs:
prompt = output.prompt
generated_text = output.outputs[0].text
if r"</think>" in generated_text:
think_content, answer_content = generated_text.split(r"</think>")
else:
think_content = ""
answer_content = generated_text
print(f"Prompt: {prompt!r}, Think: {think_content!r}, Answer: {answer_content!r}")
执行如下:

打印结果如下:
Prompt: '请帮我推荐一种深圳到北京的出行方式<think>\n', Think: '好的,我现在要帮用户推荐从深圳到北京的出行方式。用户之前已经问过这个问题,现在可能需要进一步的信息或不同的选项。首先,我得考虑用户的需求可能是什么。他们可能时间紧迫,或者喜欢不同的旅行风格。\n\n深圳到北京的路线有很多,比如高铁、飞机、大巴,还有可能的自驾或者中转其他城市。我应该先列出几种主要的交通方式,然后详细说明每种方式的优缺点,这样用户可以根据自己的情况选择。\n\n首先,高铁是最快的方式,时间大概4-5小时,而且舒适,还有直达的班次。但高铁需要提前预订,特别是节假日,可能要提前一到两周。高铁适合大多数用户,尤其是那些时间紧张或喜欢高铁舒适环境的人。\n\n然后是飞机,深圳有机场,北京有首都机场和大兴机场。飞机时间大约2-3小时,但价格比较高,而且航班可能比较紧张,尤其是热门季节。如果用户喜欢 direct flight,或者时间不够,飞机是个不错的选择。\n\n接下来是大巴,虽然时间较长,但价格便宜,而且在车上可以睡觉,体验更像旅行。但大巴的班次可能不如高铁频繁,而且在大站之间可能比较慢,适合预算有限的用户。\n\n另外,用户可能还考虑是否需要中转。比如从深圳飞到上海,再转到北京,或者深圳到天津再到北京。这样的路线可能在价格上更有优势,但时间会更长,可能不太适合时间紧张的用户。\n\n如果用户喜欢自驾,可以考虑从深圳到北京自驾,但需要考虑时间、路线、油费等因素,而且北京的限行政策可能需要提前了解。\n\n还有,是否有直达的高铁?比如深圳北站到北京西站的G字头列车,这可能是一个快速的选择。如果用户对高铁比较熟悉,这样的选择会很方便。\n\n我还需要提醒用户注意一些细节,比如高铁需要提前订票,尤其是节假日,可能会有 seat changes 的限制。飞机方面,提前预订机票,选择合适的航班,避免延误。\n\n另外,北京的天气可能在冬季较冷,用户可能需要带保暖衣物,或者考虑是否需要提前预订住宿。\n\n综合考虑,我应该推荐高铁作为首选,因为时间快、舒适,然后飞机作为替代,接着是大巴,最后是中转或自驾。这样用户可以根据自己的情况和预算做出选择。\n', Answer: '\n\n深圳到北京的出行方式多样,您可以根据自己的时间和预算选择最适合的方式。以下是几种主要的出行方式推荐:\n\n### 1. **高铁**\n - **优点**:时间最短,约4-5小时,舒适,直达。\n - **缺点**:需要提前预订,节假日可能需要提前一到两周。\n - **推荐理由**:如果时间紧张且喜欢高铁的舒适性,高铁是最佳选择。\n\n### 2. **飞机**\n - **优点**:时间较短,约2-3小时,直达。\n - **缺点**:价格较高,航班可能紧张,尤其是节假日。\n - **推荐理由**:如果您喜欢 direct flight,或者时间不够,飞机是一个不错的选择。\n\n### 3. **大巴**\n - **优点**:价格便宜,时间较长(约8-12小时),适合预算有限的用户。\n - **缺点**:班次可能不如高铁频繁,体验可能更像旅行。\n - **推荐理由**:如果预算有限且时间允许,大巴是一个经济的选择。\n\n### 4. **中转**\n - 深圳到北京的高铁和飞机主要班次都从北京西站或首都机场出发,您也可以选择中转,例如:\n - 深圳飞上海或天津,再转乘高铁或飞机到北京。\n - 深圳飞天津或上海,再转乘高铁到北京。\n - **优点**:价格可能更优惠,适合预算有限的用户。\n - **缺点**:时间会更长,建议提前规划。\n\n### 5. **自驾**\n - **优点**:时间灵活,可以体验沿途风光。\n - **缺点**:需要考虑时间和路线,油费等额外费用。\n - **推荐理由**:如果喜欢自驾,可以选择从深圳出发,沿京昆高速、京沪高速等行驶到北京。\n\n### 6. **其他方式**\n - **公共交通**:深圳有地铁、公交等,但直接到北京可能不太方便。\n - **共享出行**:如网约车服务(如滴滴出行、出租车等),方便灵活。\n\n### 建议:\n- **时间紧迫且喜欢高铁**:高铁是最佳选择。\n- **喜欢 direct flight**:飞机是不错的选择。\n- **预算有限**:大巴或中转是更好的选择。\n\n希望这些信息能帮助您选择合适的出行方式!如果需要更详细的行程规划或预订建议,可以告诉我您的偏好,我会尽力帮助您。'
四、OpenAI API服务部署测试
DeepSeek-R1-Distill-Qwen 是一款高性能的蒸馏语言模型,它兼容 OpenAI API 协议,能够通过 vLLM 框架快速创建一个本地的 OpenAI API 服务器。vLLM 是一个开源的高效推理框架,专为大语言模型设计,支持多种优化技术,如 PagedAttention 算法,能够显著提升推理效率。启动的服务器默认监听 http://localhost:8000,支持以下功能:
- Completions API:用于基本的文本生成任务,如生成文章、故事或邮件。
- Chat Completions API:用于对话任务,如构建聊天机器人。
1、发布OpenAI API服务
部署服务器时,可以指定以下参数:
–host 和 --port:指定服务器地址和端口。
–model:指定模型路径。
–chat-template:指定聊天模板。
–served-model-name:指定服务模型的名称。
–max-model-len:指定模型的最大上下文长度。
以下是启动命令:
python -m vllm.entrypoints.openai.api_server \
--model /root/autodl-tmp/deepseek-ai/DeepSeek-R1-Distill-Qwen-7B \
--served-model-name DeepSeek-R1-Distill-Qwen-7B \
--max-model-len=2048
服务启动如下:
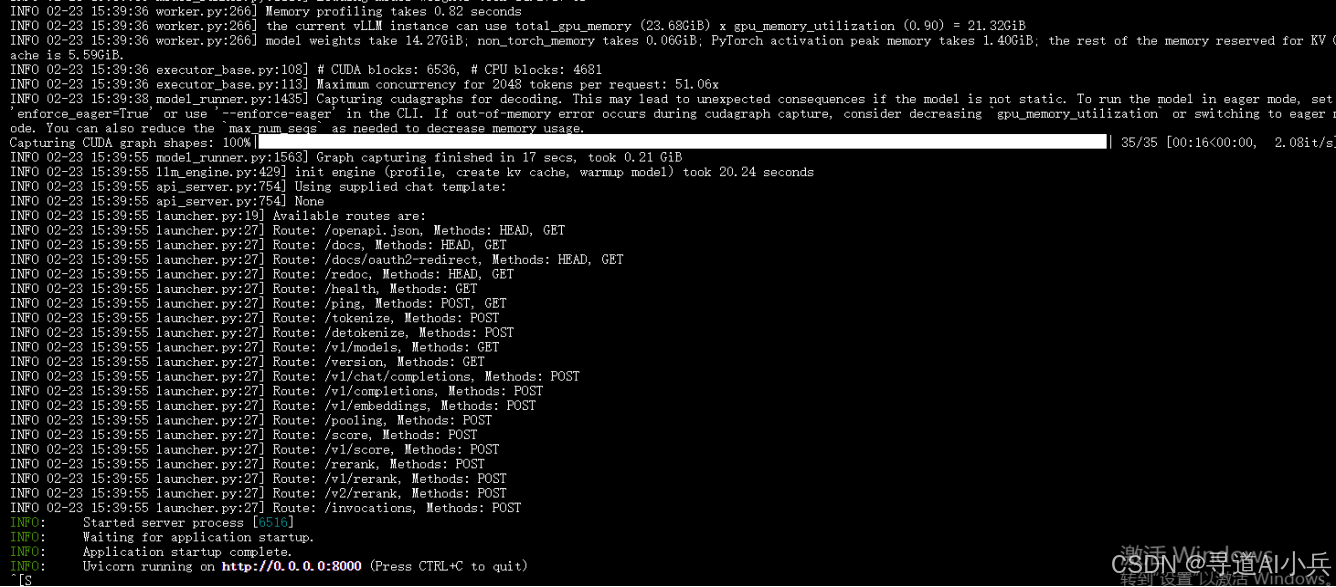
此命令将启动一个本地服务器,监听 http://localhost:8000。
2、Completions API调用
from openai import OpenAI
client = OpenAI(base_url="http://localhost:8000/v1", api_key="sk-xxx")
response = client.completions.create(
model="DeepSeek-R1-Distill-Qwen-7B",
prompt="简单介绍一下deepseek?<think>\n",
max_tokens=1024
)
print(response.choices[0].text)
在这段代码中,使用openai库创建OpenAI客户端对象,指定base_url为本地启动的vLLM服务地址http://localhost:8000/v1,api_key为任意值(因为在本地测试,这里主要用于满足接口格式要求)。然后,调用client.completions.create方法,传入模型名称、提示词和最大生成token数,获取模型的推理结果,并打印生成的文本。如果在调用过程中出现错误,可能是因为服务未启动、参数设置错误等原因,需要仔细排查。
模型响应输出如下:
好的,我现在要介绍一下DeepSeek。首先,我得快速浏览一下用户提供的内容,了解DeepSeek的基本信息。DeepSeek是一家专注实现AGI的中国的人工智能公司,由深度求索人工智能研究院成立,致力于AGI研究和落地。
我知道AGI指的是通用人工智能,即在智力上超越人类的人工智能系统,具有自主学习、推理、解决问题等能力。所以DeepSeek的项目目标就是实现这一点。接下来,他们的研究领域包括认知科学、计算机科学、量子计算、脑机接口和元学习,这些都是AGI研究的重要方向。
然后看了一下他们的方向,包括认知建模与理解、自由意志与决策、量子计算与算力提升、脑机交互与意识提升、元学习与自适应学习。这些听起来比较广泛,涵盖了多个技术领域。技术能力方面提到了自然语言处理、计算机视觉、数值计算等,这些都是机器学习中的核心领域,特别是深度学习在这些方面的应用。
医疗、教育、 withdrawal这些应用领域,尤其是医疗和教育,都是AI应用的重要方向。医疗AI可以帮助诊断疾病,提高治疗效果;教育AI可以提供个性化学习体验,提高教育效率。
最后,他们的愿景是让用户与AI成为完美的协作伙伴,这可能意味着DeepSeek希望通过其技术帮助用户更高效地解决各种问题,提升生活质量和工作效率。
整体来看,DeepSeek是一家致力于实现AGI的公司,涉及多个技术领域,并且有明确的应用目标,这使得他们的 work likely 在AI领域有不错的影响力。如果有时间,我想深入了解它们的研究方法、取得的成果以及面临的挑战。
现在,我要检查一下是否理解正确,以及信息是否有遗漏。比如,DeepSeek的成立背景是什么?我需要确保“深度求索人工智能研究院”是其成立的背景,而非其他。此外,AGI的定义是否正确,是否有其他公司也在 chasing AGI?
另外,DeepSeek的具体技术手段是什么?是基于特定模型或算法的创新?提到的自然语言处理、计算机视觉等,这些具体如何实现AGI的目标?
在应用方面, withdraw的应用可能是指用户退出或其他功能,可能需要更正。此外,技术能力部分可能需要更详细地解释每个技术如何支持AGI。
总结来说,我需要确保在介绍中准确传达DeepSeek的核心目标、研究领域、技术能力以及应用,同时注意使用准确的专业术语,并保持逻辑清晰。
</think>
DeepSeek 是一家专注实现通用人工智能(AGI)的中国公司,由深度求索人工智能研究院成立于2023年。其目标是通过研究和实现AGI,推动人工智能技术的变革性发展。以下是DeepSeek的详细介绍:
1. **背景与目标**
- **成立背景**:由深度求索人工智能研究院成立,致力于AGI研究和落地。
- **核心目标**:实现AGI,即超越人类智力水平的人工智能系统,具备自主学习、推理和解决问题的能力。
2. **研究领域**
- 涵盖认知科学、计算机科学、量子计算、脑机接口和元学习,涵盖多个关键领域,包括但不仅限于认知建模与理解、自由意志与决策、量子计算与算力提升、脑机交互与意识提升以及元学习与自适应学习。
3. **技术能力**
- 应用于自然语言处理、计算机视觉、数值计算、元学习和强化学习等技术领域,推动新兴技术的发展,特别是深度学习在各领域的创新应用。
4. **应用领域**
- **医疗**:通过AI提高诊断准确性和治疗效果,优化资源配置,提升医疗服务。
- **教育**:提供个性化学习方案,提升学习体验和教育效率。
- **其他**:DeepSeek 还探索在 withdrawals 行业的应用,如安全监控和应急响应等领域。
5. **愿景**
- 让用户与AI成为完美的协作伙伴,提升生活质量和工作效率,实现人机完美的协作。
**补充说明**:
- **成立背景**:作为一家新兴的高科技公司,DeepSeek可能尚未获得广泛的关注,但其专注于AGI的研究,可能在量子计算、脑机接口等领域具备先发优势。
- **AGI挑战**:AGI的实现仍面临巨大挑战,包括技术突破、伦理问题和应用安全等,DeepSeek的进展值得持续关注。
- **技术手段**:具体的创新可能包括新型算法、硬件加速技术或跨学科的国际合作,以突破现有技术限制。
DeepSeek的成立标志着中国AI生态中的又一重要参与者,其目标不仅是技术突破,更是推动社会的整体发展。
3、Chat Completions API调用
chat_response = client.chat.completions.create(
model="DeepSeek-R1-Distill-Qwen-7B",
messages=[{"role": "user", "content": "我买了10个苹果,给了你3个,自己吃了1个,还剩几个?"}]
)
print(chat_response.choices[0].message.content)
此代码用于调用Chat Completions API,通过client.chat.completions.create方法,传入模型名称和包含用户消息的列表,获取聊天模式下的推理结果,并打印模型生成的回答内容。在实际应用中,可以根据用户需求,优化提示词和消息列表,以获得更准确、更有用的回答。
模型响应输出如下:
你买了总共10个苹果。
给了对方3个, yourself剩下10减去3等于7个苹果。
接着,自己又吃了1个苹果,剩下7减去1等于6个苹果。
所以,最终剩下6个苹果。
</think>
**解答:**
1. **总苹果数**:你最初有10个苹果。
2. **给对方3个**:
\( 10 - 3 = 7 \)
你剩下7个苹果。
3. **自己吃了1个**:
\( 7 - 1 = 6 \)
最终剩下6个苹果。
**答案:\boxed{6}**
4、命令行调用OpenAI API接口
命令行调用示例如下:
curl http://localhost:8000/v1/completions \
-H "Content-Type: application/json" \
-d '{
"model": "DeepSeek-R1-Distill-Qwen-7B",
"prompt": "我买了10个苹果,给了你3个,自己吃了1个,还剩几个?<think>\n",
"max_tokens": 1024,
"temperature": 0
}'
执行结果如下:

五、最佳实践建议
1. 显存优化
对于配备24G显存的3090显卡,建议设置max_model_len=2048。因为模型长度与显存占用密切相关,合理设置max_model_len,可以避免因模型长度过大导致显存不足的问题,确保模型能够稳定运行。如果需要处理更长的文本,可以考虑增加显存或者优化模型结构。
2. 温度参数
在不同的任务场景下,合理调整温度参数(temperature)至关重要。对于创造性任务,如文本创作、故事生成等,建议将temperature设置为0.7 - 0.9,这样可以使生成的文本更加多样化和富有创意;对于逻辑推理任务,如数学计算、知识问答等,建议将temperature设置为0.3 - 0.5,以确保生成的文本更加准确和逻辑严谨。
总结
通过本文的详细介绍,你已经掌握了使用vLLM框架部署DeepSeek-R1-Distill-Qwen大语言模型的全流程。从vLLM框架的特性解析,到环境配置、模型部署、API接口测试,再到最佳实践建议,每一步都为你在大语言模型部署的道路上提供了坚实的指引。希望你在实际应用中,能够灵活运用这些知识,充分发挥vLLM和DeepSeek-R1-Distill-Qwen模型的优势,实现更多创新的应用。

🎯🔖更多专栏系列文章:AI大模型提示工程完全指南、AI大模型探索之路(零基础入门)、AI大模型预训练微调进阶、AI大模型开源精选实践、AI大模型RAG应用探索实践🔥🔥🔥 其他专栏可以查看博客主页📑
😎 作者介绍:我是寻道AI小兵,资深程序老猿,从业10年+、互联网系统架构师,目前专注于AIGC的探索。
📖 技术交流:欢迎关注【小兵的AI视界】公众号或扫描下方👇二维码,加入技术交流群,开启编程探索之旅。
💘精心准备📚500本编程经典书籍、💎AI专业教程,以及高效AI工具。等你加入,与我们一同成长,共铸辉煌未来。
如果文章内容对您有所触动,别忘了点赞、⭐关注,收藏!加入我,让我们携手同行AI的探索之旅,一起开启智能时代的大门!



















 5682
5682

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











