




注:使用不同的推理模型,需要的模型文件是不一样的,比如我前面用的ollama下载的模型,则只能在ollma里面使用,不能拿到vLLM来使用。
1.vLLM介绍
vLLM相比ollama复杂,ollama启动以后,读取模型文件就可以提供服务,但是vllm则只是一个框架,本身不具有启动服务的能力,它需要依赖python来启动服务。虽然vLLM比较复杂,但是他具有组成集群跑更大模型的能力,所以我这里先用单机版来让搭建对这个vLLM有一个的理解,后期再深入。
2.miniconda环境准备
miniconda可以方便的管理多个Python环境,也可以不用安装直接使用物理机或者虚拟机的Python环境。由于我是复用的上次的Linux+GPU的环境,所以这里我也使用miniconda来提供Python环境。
安装过程需要先回车,在阅读同意协议,最后更新环境变量。
#下载
wget https://repo.anaconda.com/miniconda/Miniconda3-latest-Linux-x86_64.sh -O ~/miniconda.sh
#安装,该操作会下载800m 的文件
bash miniconda.sh
#安装完成提示
==> For changes to take effect, close and re-open your current shell. <==
Thank you for installing Miniconda3!3.创建vLLM虚拟环境
需要先退出当前bash重新进入,进入以后,左边就会多出一个base。这里的Python版本是conda自带的,中途还需要输入一个y。
conda create --name vllm python=3.12.9![]()
4.切换进入vLLM虚拟Python环境
(base) [root@MiWiFi-RD03-srv ~]# conda activate vllm
(vllm) [root@MiWiFi-RD03-srv ~]# 5.下载vLLM
强烈建议采用原生自带高版本的内核,由于我这个机器是复用上次Linux+GPU的机器,所以我又重新编译了gcc,然后中途还遇到了很多问题。
#安装vLLM,大概会产生8G的内容。
#我这里加速用华为会报错,用阿里则没问题。
(vllm) [root@MiWiFi-RD03-srv ~]# pip install vllm -i https://mirrors.huaweicloud.com/repository/pypi/simple
Looking in indexes: https://mirrors.huaweicloud.com/repository/pypi/simple
Collecting vllm6.下载模型
模型下载可以手工去国内镜像网站下载,也可以用下面的脚本进行下载。
#国内镜像站
https://hf-mirror.com/deepseek-ai/DeepSeek-R1脚本下载
#下载一个python包,用于下载模型
(vllm) [root@MiWiFi-RD03-srv ~]# pip install modelscope -i https://mirrors.huaweicloud.com/repository/pypi/simple
Looking in indexes: https://mirrors.huaweicloud.com/repository/pypi/simple
Collecting modelscope#创建下载文件
vi down_model.py
#下载代码
from modelscope import snapshot_download
model_dir = snapshot_download('deepseek-ai/DeepSeek-R1-Distill-Qwen-1.5B',
cache_dir='/root/deepseekr1_1.5b',
revision='master')
#执行下载
python down_model.py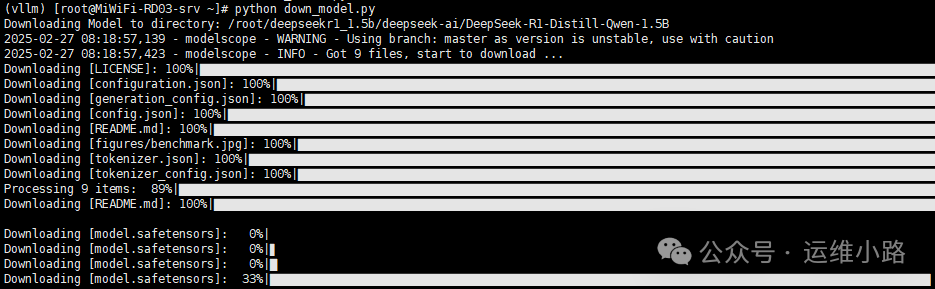
7.启动模型
最后的参数是我这个显卡性能不行,才需要加的,默认只要本地路径即可。
vllm serve \
/root/deepseekr1_1.5b/deepseek-ai/DeepSeek-R1-Distill-Qwen-1.5B \
--dtype=half
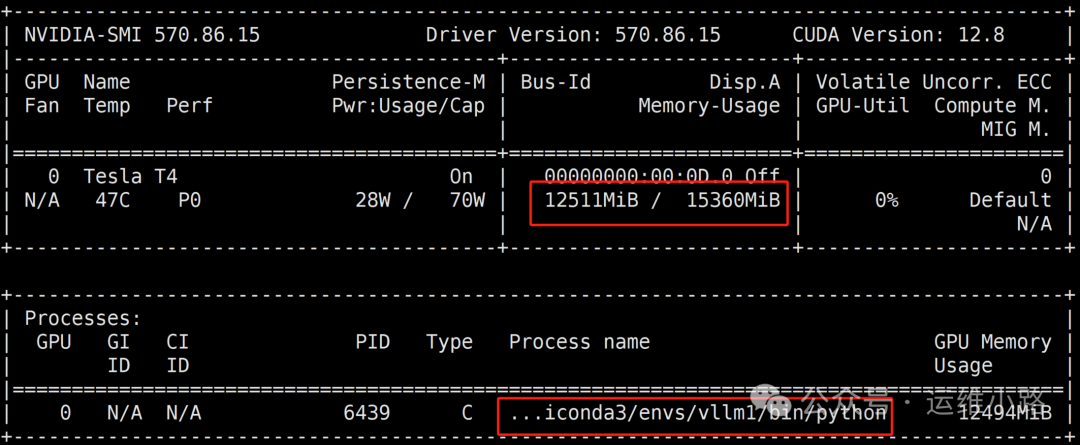
8.访问模型
这个vLLM相比ollma也会更麻烦,就算在控制台操作也需要额外配置,这个配置还只能做到定向问题,人工还需要形成对话模式则还需要改写代码才能实现。
import requests
import json
def stream_chat_response():
response = requests.post(
"http://localhost:8000/v1/chat/completions",
json={
"model": "/root/deepseekr1_1.5b/deepseek-ai/DeepSeek-R1-Distill-Qwen-1.5B",
"messages": [{"role": "user", "content": "写一篇关于AI安全的短论文"}],
"stream": True,
"temperature": 0.7
},
stream=True
)
print("AI: ", end="", flush=True) # 初始化输出前缀
full_response = []
try:
for chunk in response.iter_lines():
if chunk:
# 处理数据帧
decoded_chunk = chunk.decode('utf-8').strip()
if decoded_chunk.startswith('data: '):
json_data = decoded_chunk[6:] # 去除"data: "前缀
try:
data = json.loads(json_data)
if 'choices' in data and len(data['choices']) > 0:
delta = data['choices'][0].get('delta', {})
# 提取内容片段
content = delta.get('content', '')
if content:
print(content, end='', flush=True) # 实时流式输出
full_response.append(content)
# 检测生成结束
if data['choices'][0].get('finish_reason'):
print("\n") # 生成结束时换行
except json.JSONDecodeError:
pass # 忽略不完整JSON数据
except KeyboardInterrupt:
print("\n\n[用户中断了生成]")
return ''.join(full_response)
# 执行对话
if __name__ == "__main__":
result = stream_chat_response()
print("\n--- 完整响应 ---")
print(result)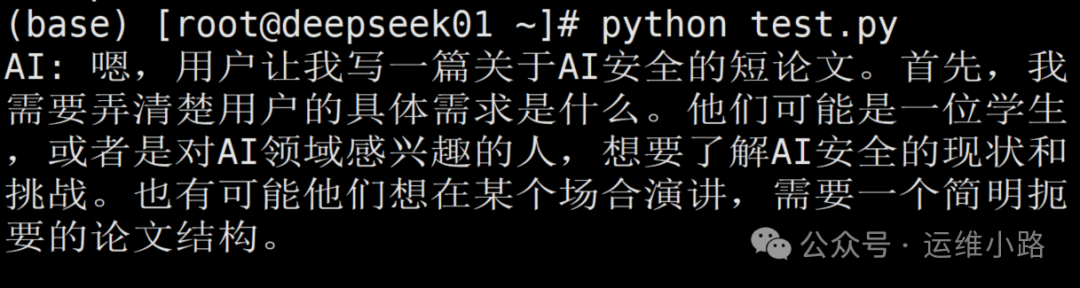
我后面用Ubuntu 20.4 重新部署了一次,大概的步骤和上面的步骤基本一致。但是没有手工编译gcc的步骤,这里的gcc也是满足要求的,并且安装驱动的是也只安装了显卡的驱动,CUDA都自带,安装步骤如下:
#类似安装源,下载地址和方法参考上小节
dpkg -i nvidia-driver-local-repo-ubuntu2004-570.86.15_1.0-1_amd64.deb
apt-get update
#安装驱动,甚至都不用安装cuda驱动就可以,安装完成系统需要重启系统
apt-get install nvidia-driver-570运维小路
一个不会开发的运维!一个要学开发的运维!一个学不会开发的运维!欢迎大家骚扰的运维!
关注微信公众号《运维小路》获取更多内容。


















 4949
4949

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









