





 K最近邻(kNN)算法是一种简单的分类技术,适用于多种场景。它通过计算查询实例与训练集中所有示例之间的距离,选择距离最近的K个训练示例,并依据这些训练示例的类别来确定查询实例的类别。
K最近邻(kNN)算法是一种简单的分类技术,适用于多种场景。它通过计算查询实例与训练集中所有示例之间的距离,选择距离最近的K个训练示例,并依据这些训练示例的类别来确定查询实例的类别。
K最近邻(kNN,k-NearestNeighbor)分类算法
是数据挖掘分类技术中最简单的方法之一。所谓K最近邻,就是k个最近的邻居的意思,说的是每个样本都可以用它最接近的k个邻居来代表。
kNN算法的核心思想是如果一个样本在特征空间中的k个最相邻的样本中的大多数属于某一个类别,则该样本也属于这个类别,并具有这个类别上样本的特性。该方法在确定分类决策上只依据最邻近的一个或者几个样本的类别来决定待分样本所属的类别。 kNN方法在类别决策时,只与极少量的相邻样本有关。由于kNN方法主要靠周围有限的邻近的样本,而不是靠判别类域的方法来确定所属类别的,因此对于类域的交叉或重叠较多的待分样本集来说,kNN方法较其他方法更为适合。
KNN算法的机器学习基础
显示相似数据点通常如何彼此靠近存在的图像
大多数情况下,相似的数据点彼此接近。KNN算法就是基于这个假设以使算法有用。KNN利用与我们童年时可能学过的一些数学相似的想法(有时称为距离、接近度或接近度),即计算图上点之间的距离。例如,直线距离(也称为欧氏距离)是一个流行且熟悉的选择。
KNN通过查找查询和数据中所有示例之间的距离来工作,选择最接近查询的指定数字示例( K ),然后选择最常用的标签(在分类的情况下)或平均标签(在回归的情况下)。
在分类和回归的情况下,我们看到为我们的数据选择正确的K是通过尝试几个K并选择最有效的一个来完成的。
KNN算法的步骤
- 加载数据
- 将K初始化为你选择的邻居数量
- 对于数据中的每个示例
3.1 根据数据计算查询示例和当前示例之间的距离。
3.2 将示例的距离和索引添加到有序集合中 - 按距离将距离和索引的有序集合从最小到最大(按升序)排序
- 从已排序的集合中挑选前K个条目
- 获取所选K个条目的标签
- 如果回归,返回K个标签的平均值
- 如果分类,返回K个标签的模式"
为K选择正确的值
为了选择适合你的数据的K,我们用不同的K值运行了几次KNN算法,并选择K来减少我们遇到的错误数量,同时保持算法在给定之前从未见过的数据时准确预测的能力。
一些trick:
1)当我们将K值降低到1时,我们的预测会变得不稳定。相反,随着K值的增加,由于多数投票/平均,我们的预测变得更加稳定,因此更有可能做出更准确的预测(直到某一点)。最终,我们开始看到越来越多的错误。正是在这一点上,我们知道我们把K的价值推得太远了。
2)如果我们在标签中进行多数投票(例如,在分类问题中选择模式),我们通常会将K设为奇数,以便有一个决胜局。"
算法优劣
1)优势
该算法简单易行。
没有必要建立模型,调整多个参数,或者做额外的假设。
该算法是通用的。它可以用于分类、回归和搜索。"
2)缺点
随着示例和/或预测器/独立变量数量的增加,算法变得非常慢。KNN的主要缺点是随着数据量的增加变得非常慢,这使得在需要快速做出预测的环境中,变成了一个不切实际的选择。此外,有更快的算法可以产生更准确的分类和回归结果。
然而,如果你有足够的计算资源来快速处理你用来预测的数据,KNN仍然有助于解决那些有依赖于识别相似对象的解决方案的问题。
k-NN classification problem
取一个新的观测向量x,将它分到 K 个离散的类 Ck (k=1,2,…,K) 之一。一般来说,类之间是互不相容的,因此,每一个观测只能被分到一个类中。
大间隔最近邻居(Large margin nearest neighbor,LMNN)
大间隔最近邻居分类算法是统计学的一种机器学习算法。该算法是在k近邻分类其中学习一种欧式距离度量函数。基于欧式距离度量学习函数的大间隔最近邻居分类算法能够很好的改善k近邻算法分类效果。
为什么KNN分类中为什么有白色区域?
答:没有获得任何一个区域的投票
这白色区域应该是KNN无法决策的区域,比如KNN的类中有2个或2个以上的是最近的,要减少白色区域可以调整K值,或者修改最近邻的决策条件,再或者修正距离公式。
课件中的demo
地址:http://vision.stanford.edu/teaching/cs231n-demos/knn/
1)k=1,其他参数任选,基本上不会有白色区域,因为总能在training data中找到最邻近的sample和相应的class,如果有两个sample的距离相等,那就对应了classes之间的边界。
如下图所示。但是k=1时,很容易出现过拟合。

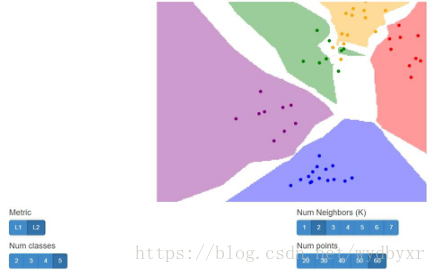
2)k>1,如下图所示,出现了该问题中的白色区域。回答这个问题先要弄清楚,k>1时,如何预测。
若k=2,那么先计算得到与test sample相距最邻近的两个training samples,如果这两个samples属于相同的class,比如A,那么该test sample将被划为class A所在的区域。 但是如果这两个samples分别属于不同的class,比如A和B,那么在课程的例子中,就会被划为白色区域。 但是可以通过一些策略打破,比如当k=7,结果中3个A class的samples,3个B class的samples和1个C class的samples,那么必须从A和B中选择一个,而非划为White region。
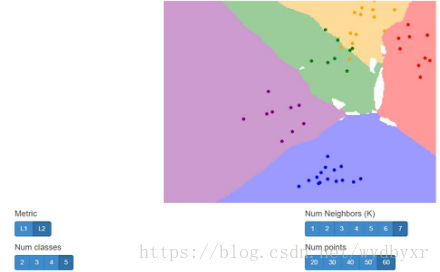
另外,k=2非常特殊,与k=7相比,更容易出现White region。比较k=2和k=7的结果,可以看出来,也很容易理解。
如下图,k=2,很容易出现大面积的白色区域
如下图,k=7,相比k=2,不容易出现白色区域

















 1371
1371

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









