




 本文介绍了非监督学习中的K-均值算法,详细阐述了算法过程、优化目标和集群中心点的选择。同时,探讨了降维技术,特别是主成分分析PCA,包括其算法过程、重建维度和选择K值的策略,并提供了PCA在数据压缩和可视化中的应用建议。
本文介绍了非监督学习中的K-均值算法,详细阐述了算法过程、优化目标和集群中心点的选择。同时,探讨了降维技术,特别是主成分分析PCA,包括其算法过程、重建维度和选择K值的策略,并提供了PCA在数据压缩和可视化中的应用建议。
非监督学习
如下图所示,,非监督学习是把相距较近的点划分为K个簇
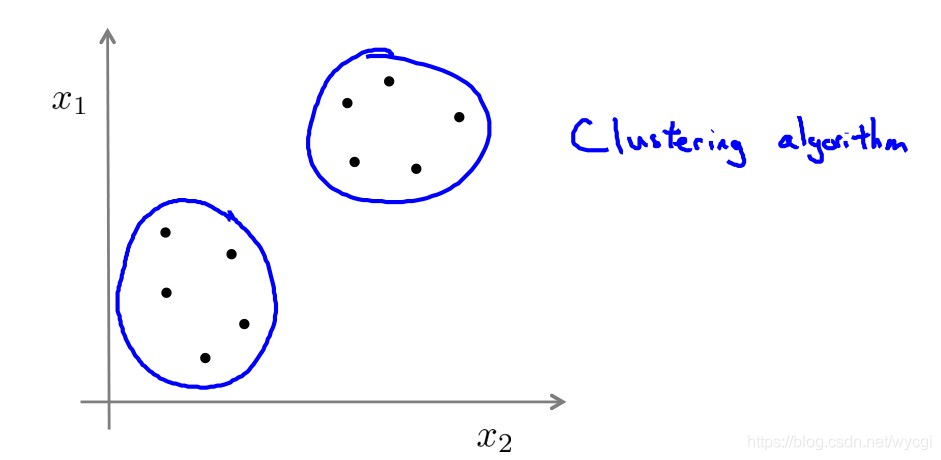
具体可以应用于市场分割、社交网络分析、组织计算集群和天文数据分析
K-均值算法
输入:需要划分的集群数量K,以及训练集 { x ( 1 ) , x ( 2 ) , … , x ( m ) } \{x^{(1)},x^{(2)},\dots,x^{(m)}\} {
x(1),x(2),…,x(m)}。
其中, x ( i ) ∈ R n x^{(i)}\in R^n x(i)∈Rn(不需要 x 0 = 1 x_0=1 x0=1)
算法过程:
随机初始化K个集群中心点 μ 1 , μ 2 , . . . , μ k ∈ R n \mu_1,\mu_2,...,\mu_k\in R^n μ1,μ2,...,μk∈Rn(一般从样本中随机取K个)
Repeat
f o r i = 1 t o m c ( i ) = 距 离 x ( i ) 最 近 的 集 群 中 心 的 编 号 ( 相 当 于 将 样 本 分 配 到 各 集 群 中 心 点 ) f o r k = 1 t o m μ k : = 所 有 归 属 于 该 集 群 中 心 的 样 本 的 均 值 点 ( 移 动 集 群 中 心 到 均 值 上 ) for\quad i = 1\quad to\quad m \\ c^(i) = 距离x^{(i)}最近的集群中心的编号 (相当于将样本分配到各集群中心点) \\ for\quad k = 1\quad to\quad m \\ \mu_k := 所有归属于该集群中心的样本的均值点 (移动集群中心到均值上) fori=1tomc(i)=距离x(i)最近的集群中心的编号(相当于将样本分配到各集群中心点)fork=1tomμ
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 2574
2574

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









