







 超级会员免费看
超级会员免费看
在stable diffusion中所有和扩展有关的功能都被放到了扩展标签中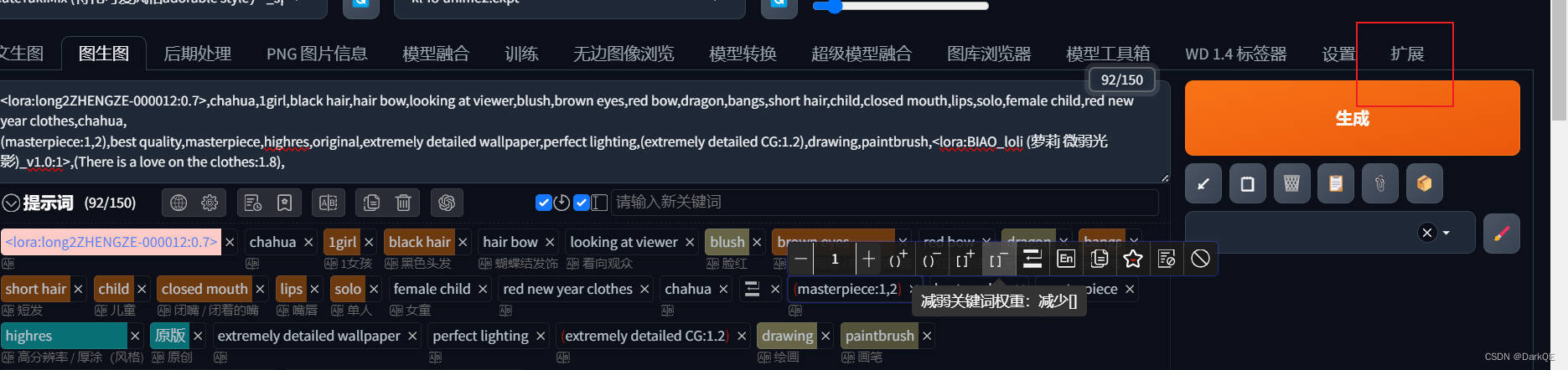
它的下方有一些选项
第一.插件安装
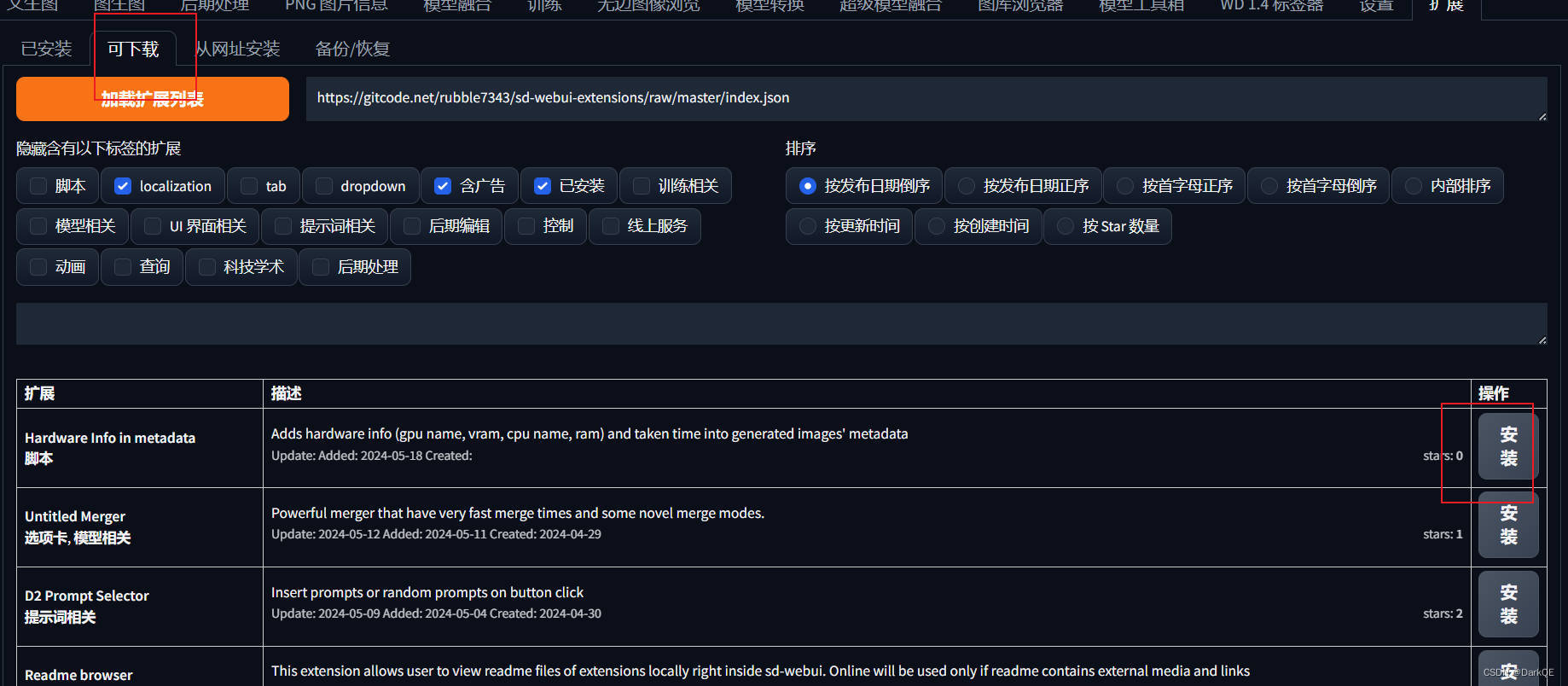
1.安装1:选择第二个标签,你可以看到可下载的插件,搜索框可以帮助你快速找到想要下载的插件
安装2:链接安装,插件制作出来,作者一般都会发送到gitee、github网站上,复制这些链接到第三个标签中即可
在stable diffusion中所有和扩展有关的功能都被放到了扩展标签中
它的下方有一些选项
1.安装1:选择第二个标签,你可以看到可下载的插件,搜索框可以帮助你快速找到想要下载的插件
安装2:链接安装,插件制作出来,作者一般都会发送到gitee、github网站上,复制这些链接到第三个标签中即可
 4172
1639
4172
1639


 订阅专栏 解锁全文
订阅专栏 解锁全文























 到【灌水乐园】发言
到【灌水乐园】发言








