







 超级会员免费看
超级会员免费看
一.lora模型的调用
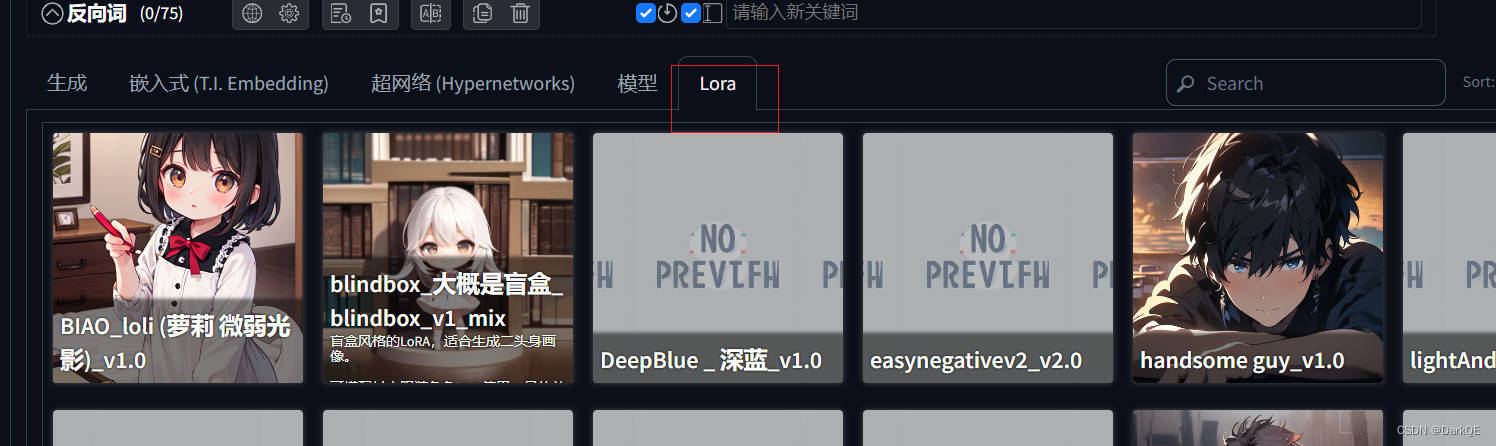
1.lora模型下载之后会放到根目录下的models文件下的lora文件下中,直接在lora选项标签中找到下载好的lora模型点击即可,你也可以通过冒号+数字的方式提高lora模型的权重。
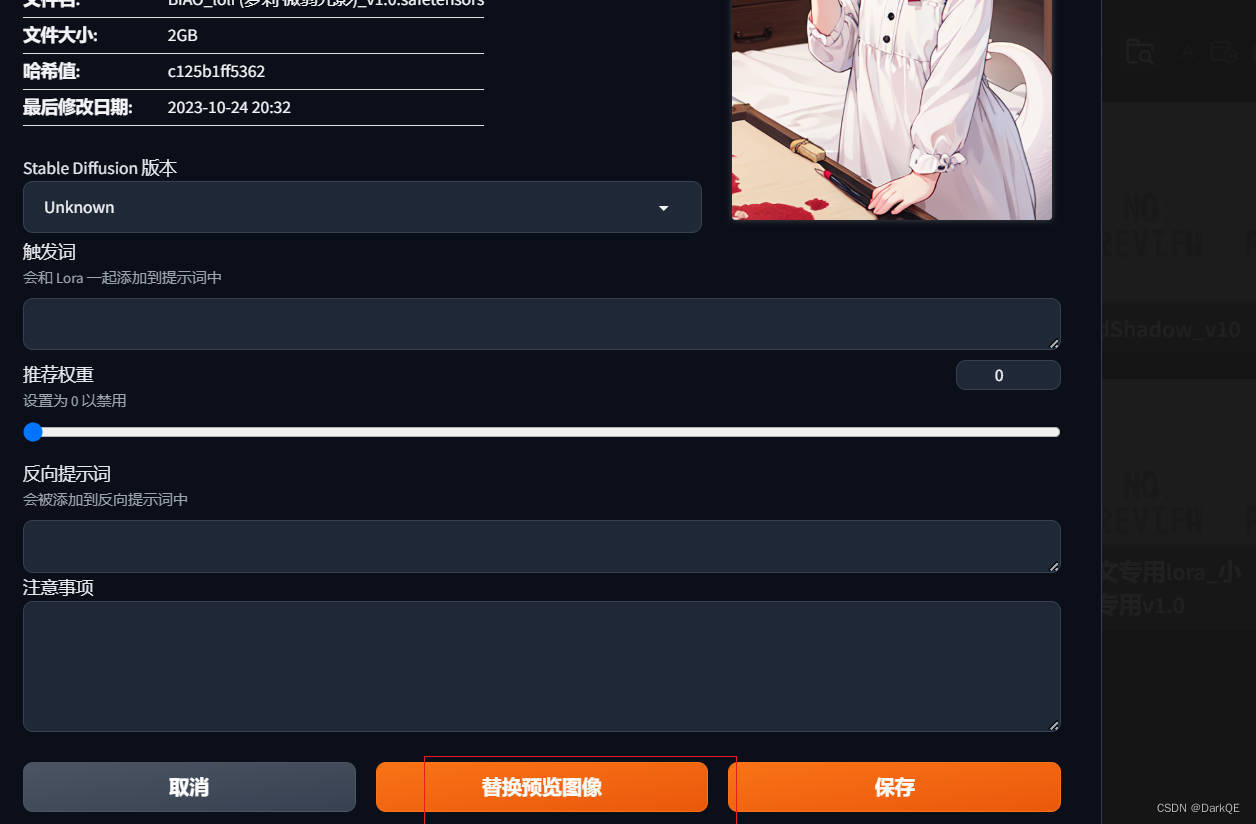
鼠标放在模型上面会出现工具的按钮,打开你可以设置一些选项,你可以用这个模型跑一张图出来,然后打开工具选择替换缩略图。
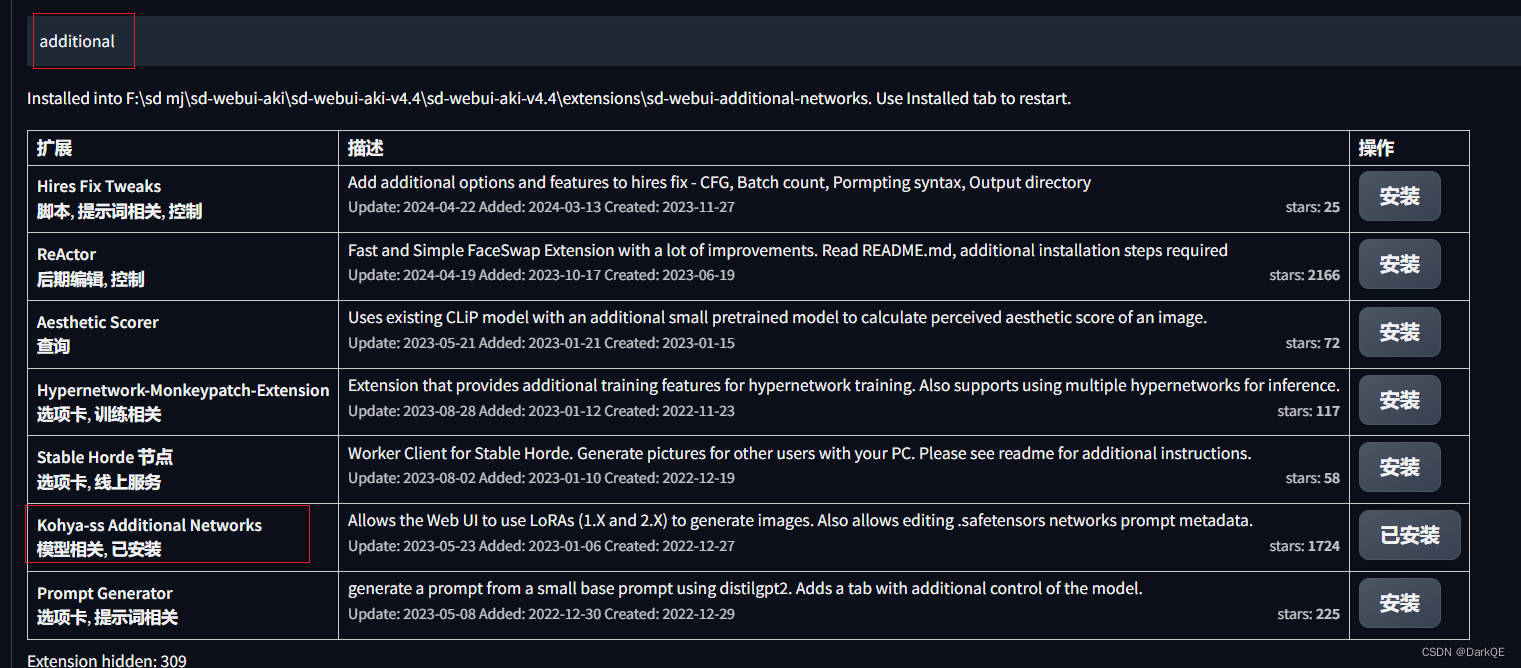
由于Lora的提示词太多就会变得像天书一样,因此有了一种新的方法,它需要借助一个扩展。
下载后在文生图和图生图的下方会出现一个选项
1.lora模型下载之后会放到根目录下的models文件下的lora文件下中,直接在lora选项标签中找到下载好的lora模型点击即可,你也可以通过冒号+数字的方式提高lora模型的权重。
鼠标放在模型上面会出现工具的按钮,打开你可以设置一些选项,你可以用这个模型跑一张图出来,然后打开工具选择替换缩略图。
由于Lora的提示词太多就会变得像天书一样,因此有了一种新的方法,它需要借助一个扩展。
下载后在文生图和图生图的下方会出现一个选项
 3958
2996
3958
2996

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言





 订阅专栏 解锁全文
订阅专栏 解锁全文


























