






在当今数字化时代,客户流失是电信行业面临的重要问题之一。准确预测客户流失不仅能帮助企业提前采取措施挽留客户,还能优化资源配置,提升客户满意度和忠诚度。本文将通过 Python 代码实现,展示如何使用决策树算法对电信客户流失数据进行分析和预测,并通过可视化工具展示模型的性能和结果。
数据准备与预处理
本次实验使用的是“电信客户流失数据.xlsx”数据集,其中包含了客户的多种特征(如消费行为、服务使用情况、客户满意度等)以及是否流失的目标变量。数据集的结构如下:
-
特征变量(
data):数据集中的前几列,包含客户的各种属性和行为特征。 -
目标变量(
target):数据集的最后一列,表示客户是否流失(通常是二分类问题,如0表示未流失,1表示流失)
数据加载与划分
我们使用 pandas 加载数据,并将其划分为特征变量和目标变量。随后,通过 train_test_split 方法将数据集划分为训练集和测试集,测试集占比为 20%。代码如下
import pandas as pd
from sklearn.model_selection import train_test_split
# 导入数据
datas = pd.read_excel("电信客户流失数据.xlsx")
data = datas.iloc[:, :-1] # 特征变量
target = datas.iloc[:, -1] # 目标变量
# 划分数据集
data_train, data_test, target_train, target_test = train_test_split(
data, target, test_size=0.2, random_state=42
)
决策树模型构建
决策树是一种经典的机器学习算法,具有易于理解和解释的特点。它通过递归地划分数据,构建一棵树形结构,每个节点代表一个特征的判断条件,每个分支代表判断条件的结果。在本次实验中,我们使用 sklearn.tree.DecisionTreeClassifier 构建决策树模型,并设置以下参数:
-
criterion='gini':使用基尼不纯度作为分裂标准。 -
max_depth=4:限制树的最大深度,避免过拟合。 -
random_state=42:设置随机种子以确保结果的可重复性。
模型训练代码如下:
from sklearn import tree
# 定义决策树模型
dtr = tree.DecisionTreeClassifier(criterion='gini', max_depth=4, random_state=42)
dtr.fit(data_train, target_train)
模型评估与混淆矩阵可视化
为了评估模型的性能,我们使用了混淆矩阵(Confusion Matrix)和分类报告(Classification Report)。混淆矩阵直观地展示了模型预测结果与真实标签之间的关系,而分类报告则提供了精确率(Precision)、召回率(Recall)和 F1 分数等关键指标。
我们定义了一个函数 cm_plot,用于绘制混淆矩阵的热力图。通过 plt.matshow 和 plt.annotate,我们能够清晰地展示每个类别的预测结果和真实值的对比。代码如下
from sklearn.metrics import confusion_matrix, classification_report
import matplotlib.pyplot as plt
def cm_plot(y, yp):
cm = confusion_matrix(y, yp)
plt.matshow(cm, cmap=plt.cm.Blues)
plt.colorbar()
for x in range(len(cm)):
for y in range(len(cm)):
plt.annotate(cm[x, y], xy=(y, x), horizontalalignment='center', verticalalignment='center')
plt.ylabel('True label')
plt.xlabel('Predicted label')
return plt
训练集评估
我们首先对训练集进行预测,并绘制混淆矩阵和分类报告:
train_predicted = dtr.predict(data_train)
print("训练集分类报告:")
print(classification_report(target_train, train_predicted))
cm_plot(target_train, train_predicted).show()
测试集评估
随后,我们对测试集进行预测,并绘制混淆矩阵和分类报告
test_predicted = dtr.predict(data_test)
print("测试集分类报告:")
print(classification_report(target_test, test_predicted))
cm_plot(target_test, test_predicted).show()
决策树可视化
为了更好地理解决策树模型的工作原理,我们使用 plot_tree 方法绘制了决策树的结构。通过设置 filled=True,我们可以清晰地看到每个节点的分类结果和特征重要性。代码如下:
from sklearn.tree import plot_tree
fig, ax = plt.subplots(figsize=(32, 32)) # 设置图片大小
plot_tree(dtr, filled=True, ax=ax)
plt.show()
决策树的可视化不仅有助于解释模型的决策过程,还能帮助我们发现数据中的关键特征和规律
实验结果
通过运行代码,我们得到了以下实验结果:

AUC-ROC曲线与评分
除了混淆矩阵和分类报告,我们还计算了模型的AUC(Area Under Curve)值,并绘制了ROC曲线。AUC值是衡量模型性能的重要指标之一,它反映了模型在不同阈值下区分正负样本的能力。ROC曲线则通过展示假正率(False Positive Rate)和真正率(True Positive Rate)的关系,直观地展示了模型的性能。
在代码中,我们使用roc_curve计算了ROC曲线的点,并通过plt.plot绘制了曲线。代码如下:
from sklearn.metrics import roc_curve, roc_auc_score
# 计算AUC值
y_pred_data = dtr.predict_proba(data_test)[:, 1]
auc_result = roc_auc_score(target_test, y_pred_data)
# 绘制ROC曲线
fpr, tpr, thresholds = roc_curve(target_test, y_pred_data)
plt.figure()
plt.plot(fpr, tpr, color='darkorange', lw=2, label='ROC curve (area = %0.2f)' % auc_result)
plt.plot([0, 1], [0, 1], color='navy', lw=2, linestyle='--')
plt.xlim([0.0, 1.0])
plt.ylim([0.0, 1.05])
plt.xlabel('False Positive Rate')
plt.ylabel('True Positive Rate')
plt.title('Receiver Operating Characteristic (ROC)')
plt.legend(loc="lower right")
plt.show()
实验结果
通过运行代码,我们得到了以下实验结果:
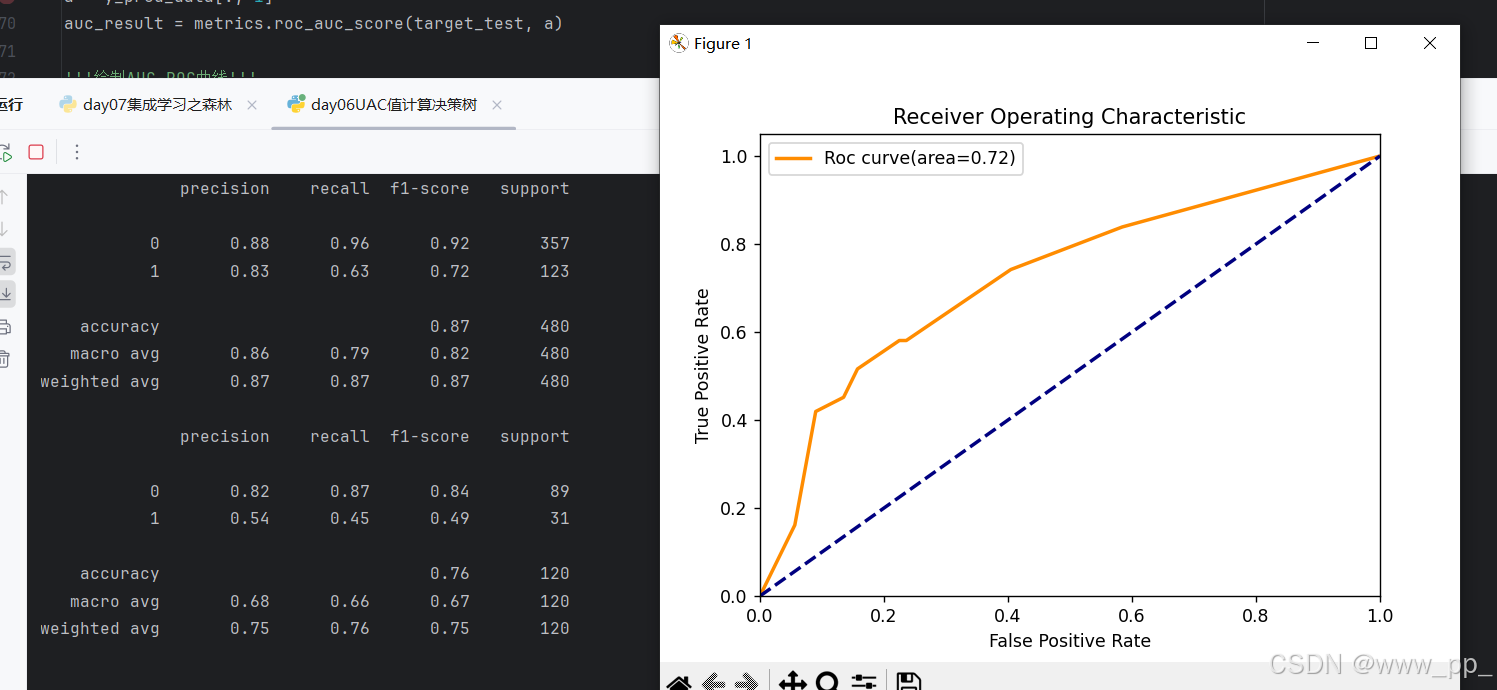
总结
-
混淆矩阵可视化:训练集和测试集的混淆矩阵展示了模型在不同数据集上的表现。通过对比混淆矩阵,我们可以发现模型在训练集上表现较好,但在测试集上可能存在一定的过拟合现象。
-
分类报告:精确率、召回率和F1分数等指标进一步量化了模型的性能。通过对比不同数据集的分类报告,我们可以选择更适合当前数据集的模型。
-
AUC-ROC曲线:AUC值和ROC曲线直观地展示了模型的性能。较高的AUC值表明模型具有较好的区分能力。

















 2002
2002

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









