



一、引言
在机器学习领域,KNN(K-Nearest Neighbors)算法是一种简单而强大的分类和回归算法。它基于“近朱者赤,近墨者黑”的原理,通过查找训练数据中与目标点最近的K个点(邻居)来预测目标点的类别或值。KNN算法因其简单易懂、无需复杂模型训练而被广泛应用,尤其适合处理小规模数据集。本文将从KNN算法的原理、优缺点、参数选择以及实际应用四个方面进行详细解析,并通过Python代码示例展示其使用方法。
二、KNN算法原理
1. 算法概述
KNN算法的核心思想是:对于一个待分类的样本点,通过计算其与训练集中所有样本点的距离,找到距离最近的K个样本点(即“邻居”)。然后,根据这K个邻居的类别信息,通过多数投票(分类任务)或平均值(回归任务)来预测目标点的类别或值。
2. 距离度量
在KNN算法中,距离度量是关键步骤之一。常见的距离度量方式包括:
-
欧氏距离:适用于连续型数据,计算两点之间的直线距离。
d(x,y)=i=1∑n(xi−yi)2 -
曼哈顿距离:适用于网格状数据,计算两点在各维度上的绝对差之和。
d(x,y)=i=1∑n∣xi−yi∣ -
明可夫斯基距离:欧氏距离和曼哈顿距离的泛化形式,通过参数p控制距离的计算方式。
d(x,y)=(i=1∑n∣xi−yi∣p)1/p 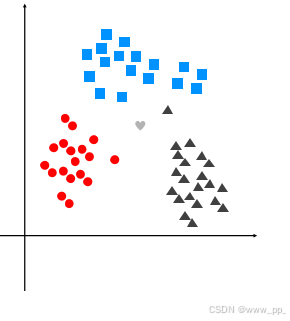
3. K值的选择
K值的选择对KNN算法的性能有重要影响。K值过小会导致模型对噪声数据过于敏感,容易过拟合;K值过大则会使模型过于平滑,容易欠拟合。通常,K值的选择需要通过交叉验证等方法进行优化。
4. 多数投票与加权投票
缺点
1. K值的选择
K值的选择是KNN算法的关键。通常,K值的选择需要通过交叉验证等方法进行优化。常见的选择方法包括:
2. 距离度量的选择
距离度量的选择取决于数据的类型和分布。对于连续型数据,欧氏距离是常用的选择;对于网格状数据,曼哈顿距离可能更合适。在实际应用中,可以通过实验比较不同距离度量的效果,选择最优的距离度量方式。
四、KNN算法的参数选择
-
多数投票:在分类任务中,根据K个最近邻的类别标签,通过多数投票决定目标点的类别。
-
加权投票:考虑每个邻居对目标点的影响程度,根据距离赋予不同的权重,距离越近权重越大。
-
三、KNN算法的优缺点
优点
-
简单易懂:KNN算法原理简单,实现容易,无需复杂的数学推导。
-
无需训练:KNN算法在训练阶段只需存储训练数据,无需构建模型,适合处理小规模数据集。
-
适应性强:KNN算法对数据的分布没有假设,能够适应各种类型的分类和回归任务。
-
计算复杂度高:每次预测都需要计算目标点与所有训练样本的距离,计算量大,效率低。
-
存储需求大:需要存储全部训练数据,占用大量内存。
-
对数据敏感:对噪声数据和不相关特征敏感,容易受到异常值的影响。
-
难以处理不平衡数据:在类别不平衡的数据集中,KNN算法的性能可能会受到影响。
-
交叉验证:通过将数据集划分为训练集和验证集,尝试不同的K值,选择使验证集性能最优的K值。
-
启发式方法:根据数据集的规模和特征数量,选择一个合理的K值范围(如 K=n,其中 n 为数据集大小)。
1. K值的选择
K值的选择是KNN算法的关键。通常,K值的选择需要通过交叉验证等方法进行优化。常见的选择方法包括:
交叉验证:通过将数据集划分为训练集和验证集,尝试不同的K值,选择使验证集性能最优的K值。
启发式方法:根据数据集的规模和特征数量,选择一个合理的K值范围(如 K=n,其中 n 为数据集大小)。
距离度量的选择取决于数据的类型和分布。对于连续型数据,欧氏距离是常用的选择;对于网格状数据,曼哈顿距离可能更合适。在实际应用中,可以通过实验比较不同距离度量的效果,选择最优的距离度量方式。
2. 距离度量的选择
距离度量的选择取决于数据的类型和分布。对于连续型数据,欧氏距离是常用的选择;对于网格状数据,曼哈顿距离可能更合适。在实际应用中,可以通过实验比较不同距离度量的效果,选择最优的距离度量方式。
五、KNN算法的实际应用
案例实现
现在有很多大学里出现室友矛盾,假如室友可以选择: 大学里面 ,对于校方,把类型相同的学生放在一个寝室,在基于大二大三大四的
现已存在一个数据文件datingTestSet2.txt ,为历年大学生的调查问卷表 第1列:每年旅行的路程 第2列:玩游戏所有时间百分比 第3列:每个礼拜消耗零食的重量 第4列:学生所属的类别,1表示爱学习,2表示一般般,3表示爱玩。 目的为学生在大学中挑选室友的信息
代码例子
以下代码展示了如何使用NumPy数组和Python列表进行基本的数据操作,包括数组的创建、加法运算、切片、修改元素以及转置等。通过对比,我们可以清晰地看到NumPy数组和Python列表在操作上的差异。
import numpy as np
# 定义数组a
a = np.array([[8,8,8,7,8],
[9,8,8,8,9],
[10,9,7,7,8],
[10,9,7,7,8],
[10,8,8,8,8]])
print('a的值为:\n',a,type(a))
# 定义列表b
b = [[8,8,8,7,8],
[9,8,8,8,9],
[10,9,7,7,8],
[10,9,7,7,8],
[10,8,8,8,8]]
print('b的值为:\n',b,type(b))
# 定义随机数组c
c = np.random.rand(5,5)
print('c的值为:\n',c)
print('a+c的结果:\n',a+c)
# 尝试a+b,由于b是列表,所以会报错
try:
print('a+b的结果:\n',a+b)
except Exception as e:
print(e)
# 定义列表d
d = [[8,8,9,7,8],
[9,8,8,80,9],
[10,9,7,70,8],
[10,9,8,9,9],
[10,8,8,8,8]]
print('d的值为:\n',d)
print('b+d的值为:\n',b+d)
# 计算a的平方
print(a**2)
# 修改a的元素
a[0,3]= 11
print(a[0,3])
# 切片操作
print(a[0:2,1:3])
# 转置操作
print(a.T)
运行调试
使用Python和Matplotlib绘制3D散点图:一个完整的KNN数据可视化案例
在机器学习中,数据可视化是理解数据分布和特征关系的重要手段。本文将通过一个具体的案例,展示如何使用Python的matplotlib库和NumPy库读取数据文件,并绘制3D散点图。我们将使用datingTestSet2.txt文件中的数据,该文件包含了一些用于KNN算法的样本数据,每行代表一个样本,最后一列是样本的类别标签
数据集说明
datingTestSet2.txt是一个包含多个样本的数据文件,每行代表一个样本,其中前几列是特征,最后一列是类别标签。该数据集通常用于KNN算法的分类任务,通过特征来预测样本的类别。
代码解析与实现
'''1、读取datingTestSet2.txt文件数据'''
import matplotlib.pyplot as plt
import numpy as np
# 读取数据文件
data = np.loadtxt('datingTestSet2.txt')
# 根据类别标签筛选数据
data_1 = data[data[:, -1] == 1] # 类别1的数据
data_2 = data[data[:, -1] == 2] # 类别2的数据
data_3 = data[data[:, -1] == 3] # 类别3的数据
# 创建3D图形
fig = plt.figure()
ax = plt.axes(projection="3d")
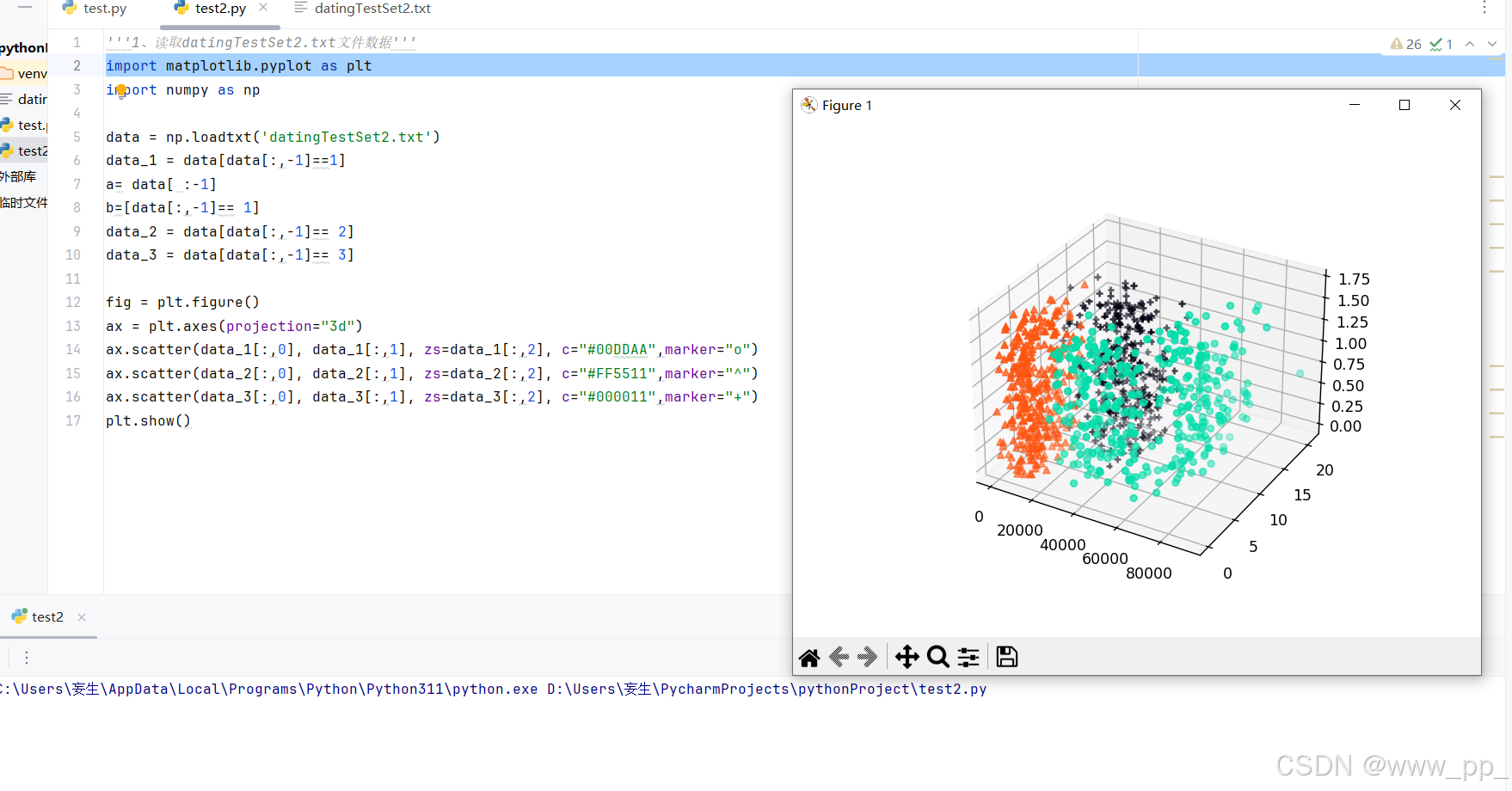
# 绘制不同类别的数据点
ax.scatter(data_1[:, 0], data_1[:, 1], zs=data_1[:, 2], c="#00DDAA", marker="o", label="Class 1")
ax.scatter(data_2[:, 0], data_2[:, 1], zs=data_2[:, 2], c="#FF5511", marker="^", label="Class 2")
ax.scatter(data_3[:, 0], data_3[:, 1], zs=data_3[:, 2], c="#000011", marker="+", label="Class 3")
# 添加图例
ax.legend()
# 显示图形
plt.show()
输出结果
运行上述代码后,您将看到一个3D散点图,其中不同类别的数据点用不同的颜色和标记表示。这有助于直观地观察数据的分布情况和类别之间的差异。
注意事项
-
数据文件路径:
-
确保
datingTestSet2.txt文件与脚本位于同一目录下,或者提供正确的文件路径。
-
-
数据格式:
-
确保数据文件的格式正确,每行包含相同数量的数值,并且最后一列是类别标签。
-
-
Matplotlib版本:
-
确保安装了支持3D绘图的
matplotlib版本。如果版本过低,可能需要更新matplotlib库。
-
以下代码展示了如何使用scikit-learn库中的KNeighborsClassifier类来实现KNN算法,并对给定的数据进行分类预测。
import numpy as np
from sklearn.neighbors import KNeighborsClassifier
# 读取数据文件
data = np.loadtxt('datingTestSet2.txt')
# 分离特征和标签
X = data[:, :-1] # 特征数据
y = data[:, -1] # 标签数据
# 创建KNN分类器
neigh = KNeighborsClassifier(n_neighbors=10)
# 训练模型
neigh.fit(X, y)
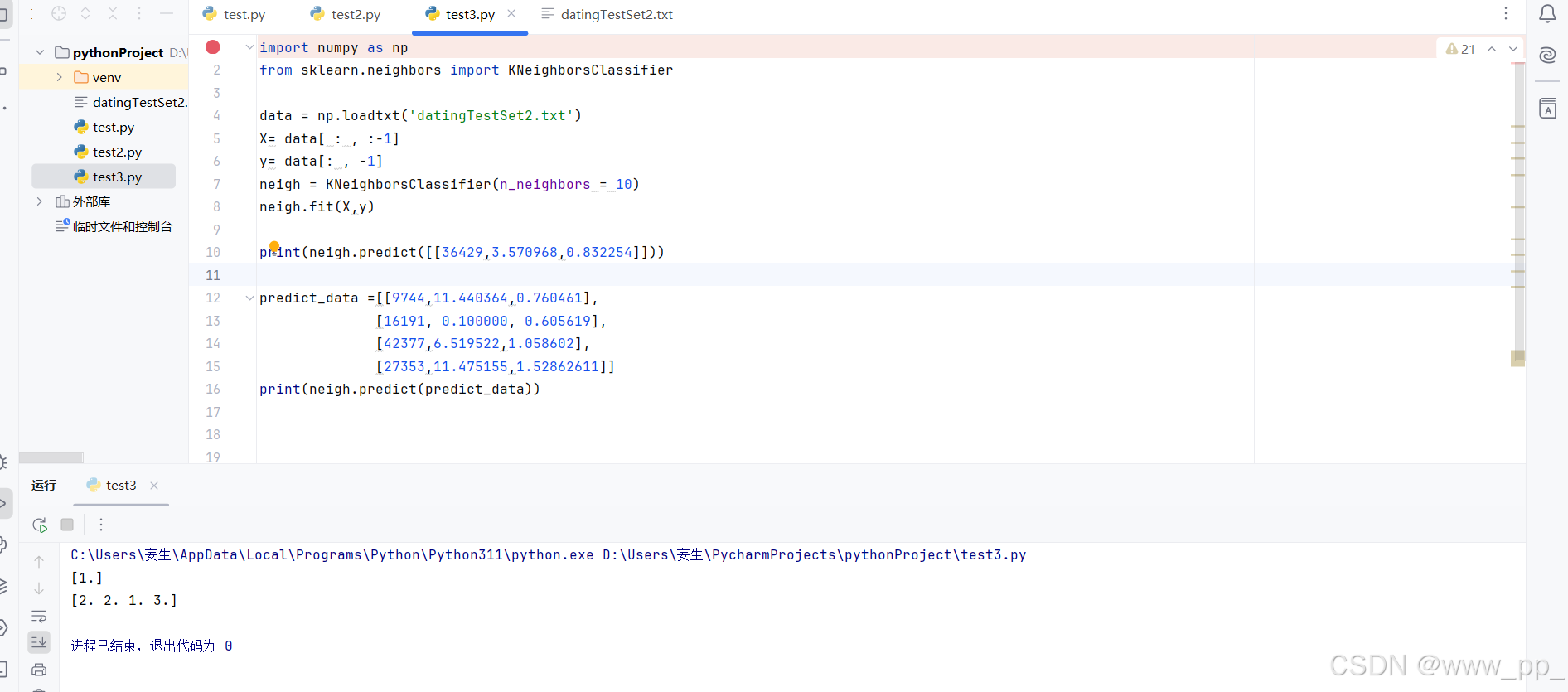
# 单个数据点预测
print("单个数据点的预测结果:", neigh.predict([[36429, 3.570968, 0.832254]]))
# 多个数据点预测
predict_data = [
[9744, 11.440364, 0.760461],
[16191, 0.100000, 0.605619],
[42377, 6.519522, 1.058602],
[27353, 11.475155, 1.52862611]
]
print("多个数据点的预测结果:", neigh.predict(predict_data))
输出结果
运行上述代码后,您将看到以下输出结果:
注意事项
-
数据文件路径:
-
确保
datingTestSet2.txt文件与脚本位于同一目录下,或者提供正确的文件路径。
-
-
数据格式:
-
确保数据文件的格式正确,每行包含相同数量的数值,并且最后一列是类别标签。
-
-
K值选择:
-
n_neighbors参数的值对模型性能有重要影响。通常需要通过交叉验证等方法进行优化。
-
-
数据预处理:
-
在实际应用中,数据预处理(如归一化、标准化)对KNN算法的性能有显著影响。可以使用
scikit-learn的StandardScaler或MinMaxScaler进行数据预处理
-
六、总结
KNN算法是一种简单而强大的机器学习算法,适用于处理小规模数据集。它基于“近朱者赤,近墨者黑”的原理,通过查找最近的K个邻居来预测目标点的类别或值。KNN算法的优点是简单易懂、无需复杂模型训练,但其缺点是计算复杂度高、存储需求大。在实际应用中,K值的选择和距离度量的选择对算法性能有重要影响,需要通过交叉验证等方法进行优化。通过本文的介绍和示例代码,相信读者对KNN算法有了全面的了解,能够将其应用到实际问题中。


















 1万+
1万+



 到【灌水乐园】发言
到【灌水乐园】发言








