






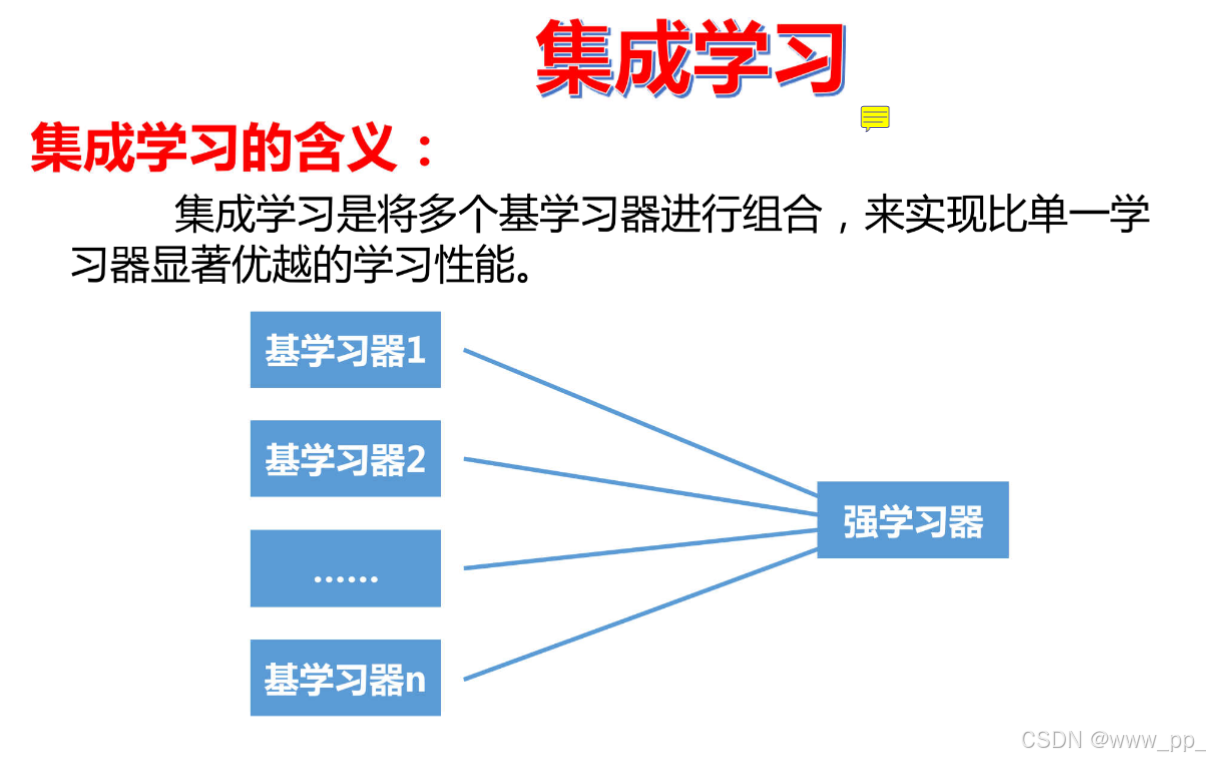
 集成学习(Ensemble Learning)是一种通过组合多个模型来提高预测性能的机器学习方法。它通过将多个弱学习器(Weak Learners)组合成一个强学习器(Strong Learner),从而提高模型的泛化能力和预测准确性。以下是集成学习的几种代表性方法
集成学习(Ensemble Learning)是一种通过组合多个模型来提高预测性能的机器学习方法。它通过将多个弱学习器(Weak Learners)组合成一个强学习器(Strong Learner),从而提高模型的泛化能力和预测准确性。以下是集成学习的几种代表性方法
1. Bagging(Bootstrap Aggregating)
Bagging 是一种通过自助采样(Bootstrap Sampling)来生成多个数据子集,然后在每个子集上训练一个模型,最后通过投票或平均的方式组合这些模型的集成方法。
代表性算法:
-
随机森林(Random Forest):
-
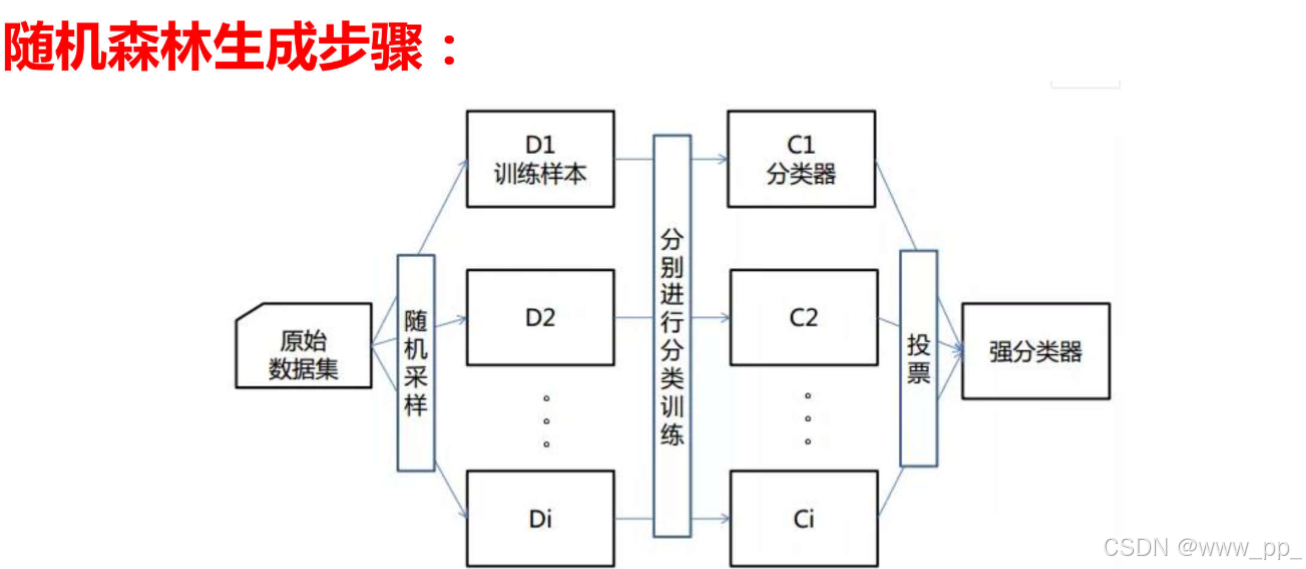
随机森林是 Bagging 方法的典型代表,它通过在每个子集上训练决策树,并在训练过程中引入特征的随机性(每次分裂只考虑部分特征),从而减少模型之间的相关性,进一步提高泛化能力。
-
-
特点:(1)数据采样随机 (2)特征选取随机 (3)森林 (4)基分类器为决策树
-
随机森林优点:
1.具有极高的准确率,
2.随机性的引入,使得随机森林的抗噪声能力很强。
3.随机性的引入,使得随机森林不容易过拟合。
4.能够处理很高维度的数据,不用做特征选择。
5.容易实现并行化计算。 -
随机森林缺点
1.当随机森林中的决策树个数很多时,训练时需要的空间和时间会较大。 -
2.随机森林模型还有许多不好解释的地方,有点算个黑盒模型
-
2. Boosting
Boosting 是一种逐步增强弱学习器的方法,通过迭代地训练模型,并在每次迭代中调整样本权重,使得模型更加关注之前模型预测错误的样本.
典型的是Xgboost
XGBoost(eXtreme Gradient Boosting)是一种基于梯度提升框架的高效机器学习算法,广泛应用于分类、回归和排序任务。它通过组合多个弱学习器(通常是决策树)来构建强学习器,利用梯度下降优化损失函数,逐步拟合残差以提高模型精度。XGBoost支持并行计算和分布式训练,能够快速处理大规模数据,并通过正则化项防止过拟合,同时具备处理稀疏数据的能力。此外,它还支持多种损失函数并可自定义目标函数,能够输出特征重要性评分,帮助理解模型决策过程。虽然参数较多、调参复杂,但其高精度、高效性和灵活性使其在数据科学竞赛和实际应用中备受青睐。
3. Stacking(堆叠)
Stacking 是一种通过训练多个不同类型的模型,并将这些模型的输出作为特征输入到一个新的模型中进行最终预测的方法。它通过组合不同模型的优势,进一步提高预测性能。
典型的是堆叠模型
代码实例
接下来实现了一个简单的垃圾邮件分类任务,使用了随机森林模型模型,并且包含了数据预处理、模型训练、预测和评估的步骤。
import pandas as pd
# 读取数据
data = pd.read_csv('spambase.csv') # 加载数据集,假设文件名为 'spambase.csv'
# 变量与标签分类
x = data.iloc[:, :-1] # 提取特征变量,即数据集的所有列除了最后一列
y = data.iloc[:, -1] # 提取目标变量,即数据集的最后一列
# 划分训练集和测试集
from sklearn.model_selection import train_test_split
xtrain, xtest, ytrain, ytest = train_test_split(x, y, test_size=0.2, random_state=0)
# 将数据集划分为训练集和测试集,其中 20% 的数据作为测试集,random_state=0 确保结果可复现
# 训练随机森林模型
from sklearn.ensemble import RandomForestClassifier
rf = RandomForestClassifier(
n_estimators=100, # 设置随机森林中树的数量为 100
max_features=0.8, # 每棵树在分裂时使用的特征比例为 80%
random_state=0 # 确保模型训练结果可复现
)
rf.fit(xtrain, ytrain) # 使用训练集数据训练随机森林模型
# 模型评估
from sklearn import metrics
# 在训练集上进行预测并评估模型性能
train_predicted = rf.predict(xtrain) # 使用训练集数据进行预测
score = rf.score(xtrain, ytrain) # 计算模型在训练集上的准确率
print(metrics.classification_report(ytrain, train_predicted)) # 打印分类报告
print(f"训练集准确率: {score:.4f}") # 打印训练集准确率
# 在测试集上进行预测并评估模型性能
test_predicted = rf.predict(xtest) # 使用测试集数据进行预测
score = rf.score(xtest, ytest) # 计算模型在测试集上的准确率
print(metrics.classification_report(ytest, test_predicted)) # 打印分类报告
print(f"测试集准确率: {score:.4f}") # 打印测试集准确率
# 特征重要性可视化
import matplotlib.pyplot as plt
from pylab import mpl
# 获取模型中特征的重要性
importances = rf.feature_importances_ # 随机森林模型提供的特征重要性属性
im = pd.DataFrame(importances, columns=["importances"]) # 将特征重要性保存到 DataFrame 中
# 获取特征名称
clos = data.columns # 获取数据集的列名
clos_1 = clos.values # 将列名转换为 NumPy 数组
clos_2 = clos_1.tolist() # 将数组转换为列表
clos = clos_2[0:-1] # 去掉最后一列(目标变量)的名称
im['clos'] = clos # 将特征名称添加到 DataFrame 中
# 按特征重要性降序排序,并取前 10 个特征
im = im.sort_values(by=['importances'], ascending=False)[:10]
# 设置中文字体
# mpl.rcParams['font.sans-serif'] = ['Microsoft YaHei'] # 设置中文字体为微软雅黑
# mpl.rcParams['axes.unicode_minus'] = False # 解决负号显示问题
# 绘制水平条形图
index = range(len(im)) # 创建索引范围
plt.yticks(index, im.clos) # 设置 y 轴的标签为特征名称
plt.barh(index, im['importances']) # 创建水平条形图,显示特征重要性
plt.xlabel('Feature Importances') # 设置 x 轴标签
plt.title('Top 10 Feature Importances') # 设置图表标题
plt.show() # 显示图表
运行结果
特征重要性分析
随机森林的一个重要优势是可以直接提供特征重要性评分。特征重要性可以帮助我们理解哪些特征对模型的决策过程贡献最大。我们通过代码提取特征重要性,并可视化前 10 个最重要的特征:
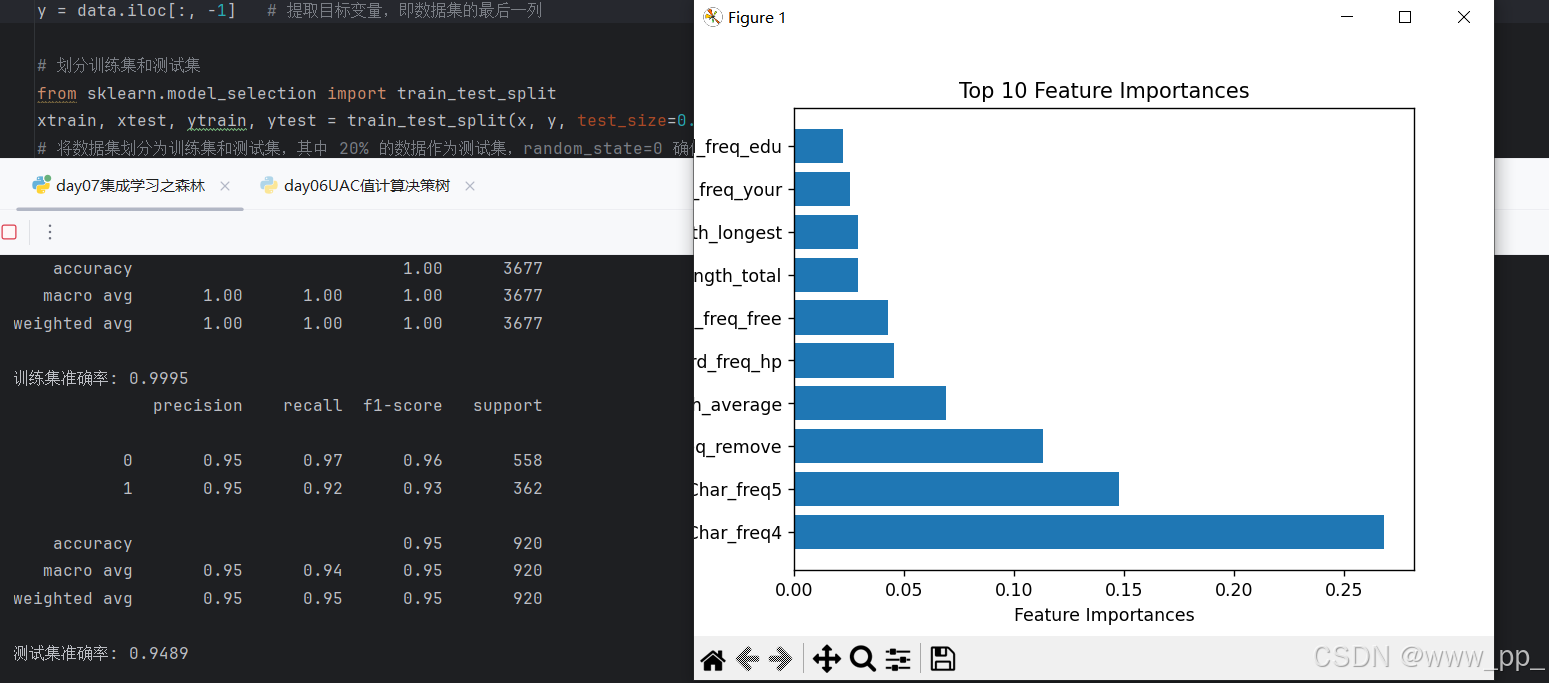
通过特征重要性分析,我们可以发现哪些特征对垃圾邮件的分类起到了关键作用。例如,某些单词或字符的频率可能对判断邮件是否为垃圾邮件具有重要影响。
总结
通过运行代码,我们得到了以下实验结果:
-
模型性能:
-
训练集准确率:模型在训练集上的表现较好,准确率较高。
-
测试集准确率:模型在测试集上的表现略低于训练集,但仍然具有较高的准确率。
-
分类报告:精确率、召回率和 F1 分数等指标进一步量化了模型的性能。
-
-
特征重要性:
-
通过特征重要性分析,我们发现了对垃圾邮件分类贡献最大的前 10 个特征。这些特征可能与邮件中的某些关键词或字符频率有关。
-
本文通过 Python 实现了基于随机森林的垃圾邮件分类,并对特征重要性进行了分析。实验结果表明,随机森林模型能够有效地对垃圾邮件进行分类,并且特征重要性分析为我们提供了模型决策的依据


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









