



一、前言
YOLOv4(You Only Look Once version 4)是一种先进的目标检测系统,于2020年推出。它是对之前版本YOLO的改进,后者是一种广泛使用的基于深度学习的目标检测算法。YOLOv4基于深度卷积神经网络,可以高精度实时检测图像中的目标。它使用单个神经网络,输入图像并输出所有目标的边界框和类别概率。YOLOv4相对于其前身YOLOv3的一些主要改进包括:
- 增加网络的深度和宽度,以获得更好的特征表示
- 使用先进的数据增强技术,以提高模型的泛化能力
- 整合多种先进的目标检测技术,如空间金字塔池化、Mish激活函数和交叉阶段部分网络。
YOLOv4是一个开源项目,在GitHub上免费提供。它已成为许多计算机视觉应用程序的流行选择,包括自动驾驶汽车、安全系统和监控系统。论文 ,代码。
本实验基于代码Github开源代码:
二、运行环境准备
运行文件前,需要的主要的库(依赖)我们都可以在requirements.txt中找到。
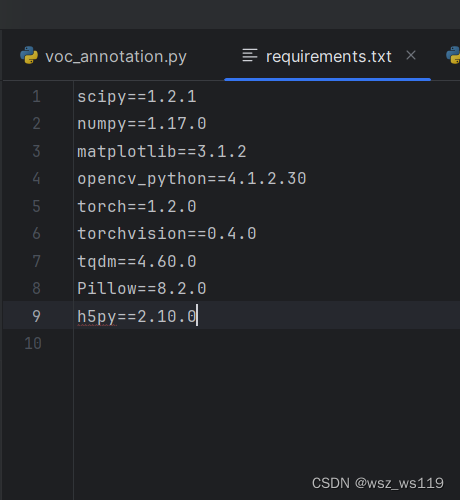
我们直接运行下面这个代码就可以安装所需要的库(如果下载太慢可以在后面加一个源,只要是国内的,什么源都可以)。如果下面代码运行不成功,那只能辛苦一下自己,一个一个下载。总之,没有什么库就下什么库。
pip install -r requirements.txtpip install -r requirements.txt -i https://pypi.tuna.tsinghua.edu.cn/simple/在这里如果条件允许的话,下载torch的时候选择cuda版本,这样训练模型的时候会快一点。因为我的是集显的笔记本,而且安装cuda版本的话很麻烦,所以我的是cpu版本的torch,训练的时候真的是很久。
三、数据准备
1、准备数据集
因为我自己的数据集不好,质量也不咋地,所以我就拿了一个数据集来用(当然你们也可以自己准备一个数据集),我的数据集是猫、狗、狐狸的数据。数据集链接:下载
动物照片_数据集-飞桨AI Studio星河社区 (baidu.com) https://aistudio.baidu.com/datasetdetail/154928
https://aistudio.baidu.com/datasetdetail/154928
有了数据集后,我们需要借助labellmg_exe来对我们的数据图像标记来得到标签数据。
下面链接是labellmg_exe工具的安装和使用:
图片格式为jpg,标签为xml。
在labellmg使用中可以选择PascalVOC和YOLO两种,我们标注时选择PascalVOC,这样得到的标签文件就是xml格式。
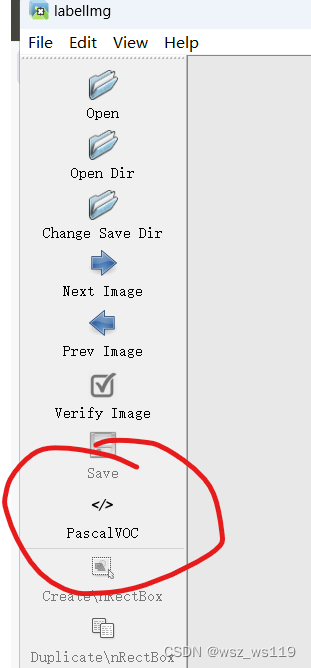
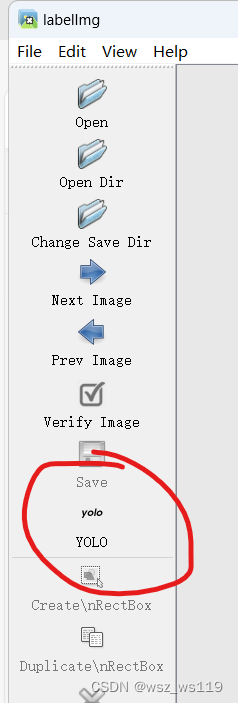
在图像和标签处理好之后,我们需要把yolov4里的yolov4-pytorch-master\VOCdevkit\VOC2007文件夹下的Annotations和JPEGImages替换成我们自己的标签和图像(标签和图像时一一对应的)。
Annotations文件夹放的是标签数据
JPEGImages文件夹放的是图像数据
2、划分数据集
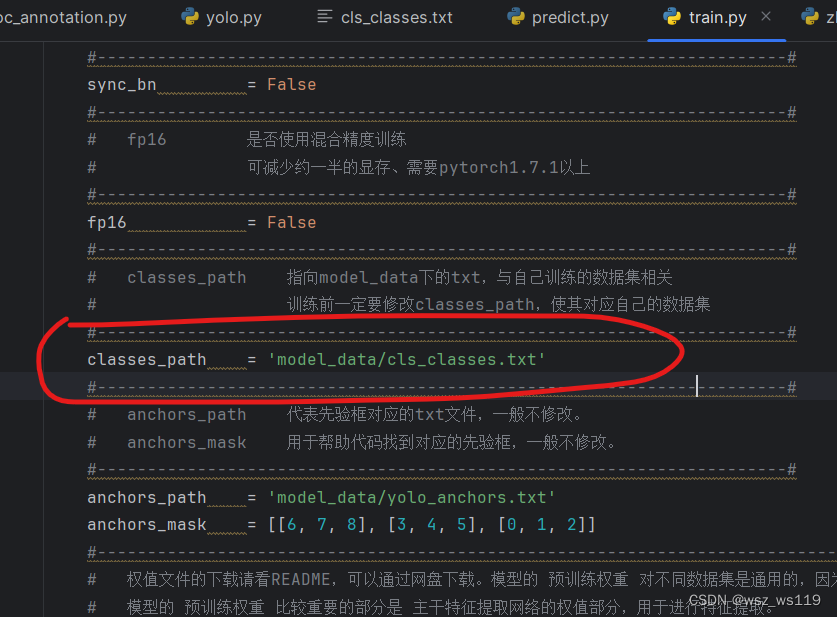
找到我们的voc_annotation.py文件,这个文件是对数据集划分训练集和测试集。在运行voc_annotation.py前我们只要改一个参数classes_path。
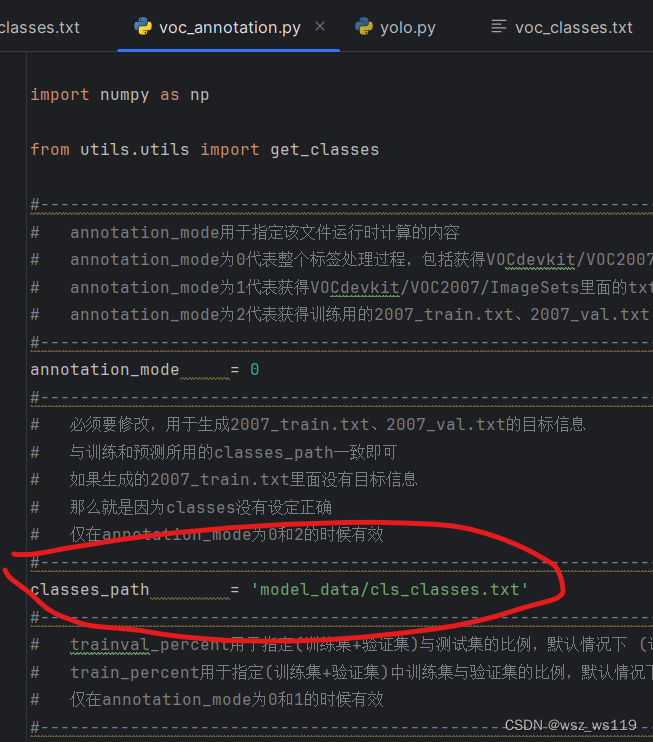
我这里的cls_classes.txt是自己新建立的txt文件,放到model_data文件夹下,内容就是图片对应的名字,或者也可以在coco_classes.txt文件中改(这样上面一步就不用改)。
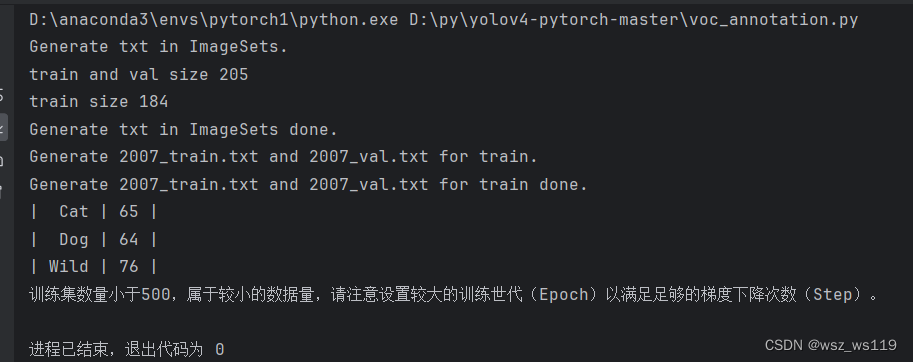
运行voc_annotation.py,我们可以得到以下结果,对我们的数据集进行了划分。
四、训练数据
第一次训练
(1)、train.py文件
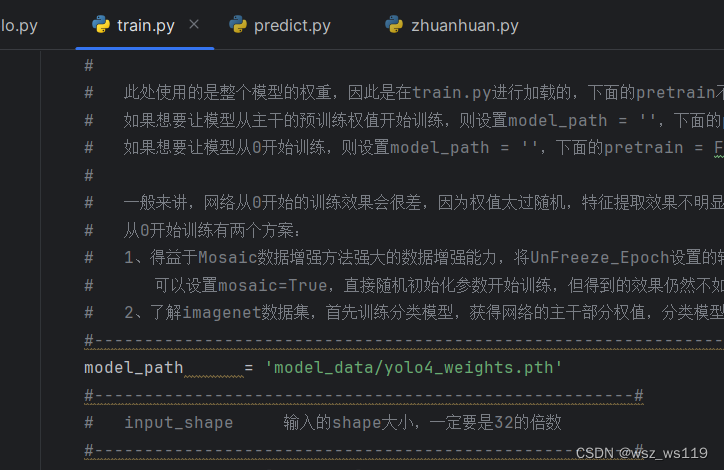
train.py文件可以根据我们提供的数据进行训练,运行得出模型的权值。第一次训练的时候,在这个文件中我们有要修改的参数,classes_path
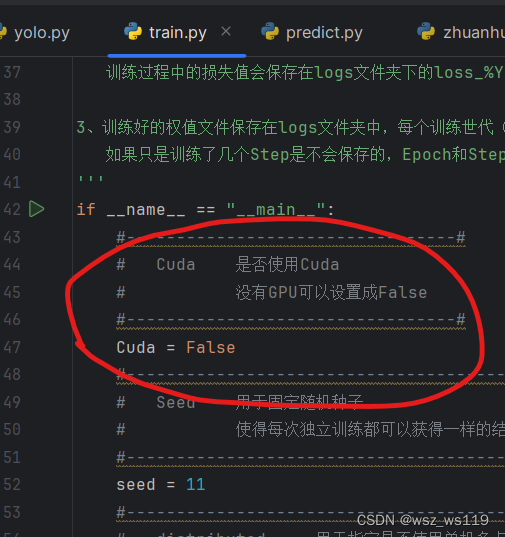
使用cuda版本torch的这里要把False改成True,cpu版本的可以不管。我的是cpu版本的所以就没改
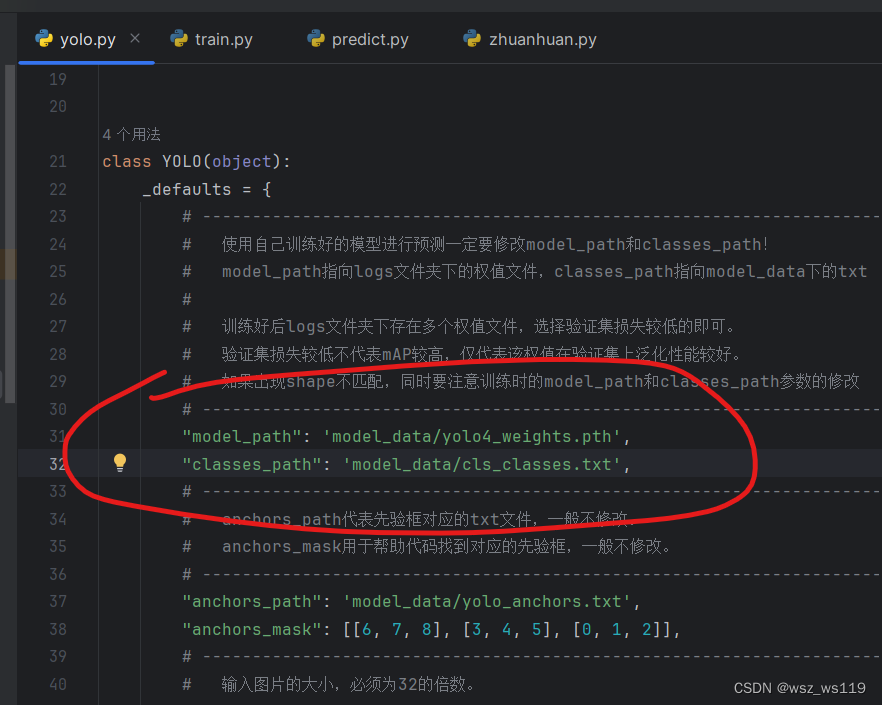
2、yolo.py文件
yolo.py也和train,py文件一样把参数classes_path和cuda都要改。不过yolo.py有两个类,都要改。
然后就是运行train.py文件。
训练期间会输出模型性能的统计数据,包括不同类别(dragon fruit 和 snake fruit)的平均精度(AP)和平均精度均值(mAP),以及它们对应的分数阈值、F1-分数、召回率和精确率。

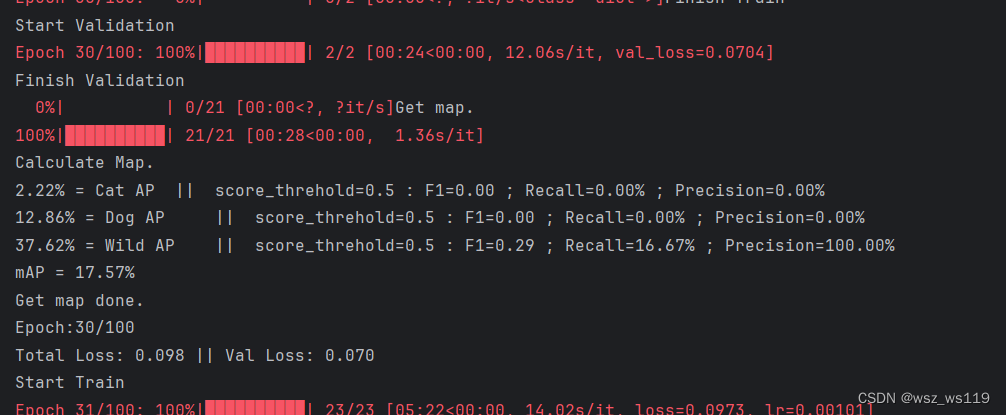
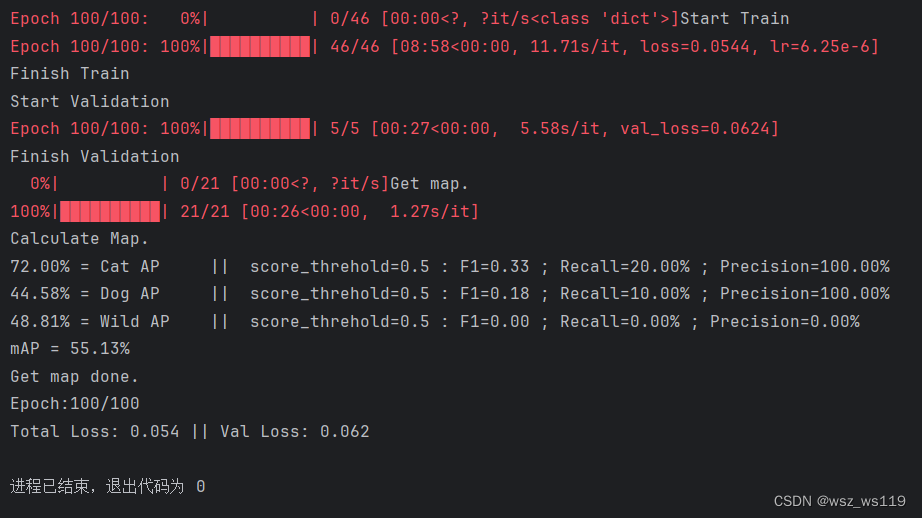
第一次训练可以修改参数UnFreeze_Epoch,也就是训练的总批次,我这里是100个批次这样可以减少我们训练的时间。
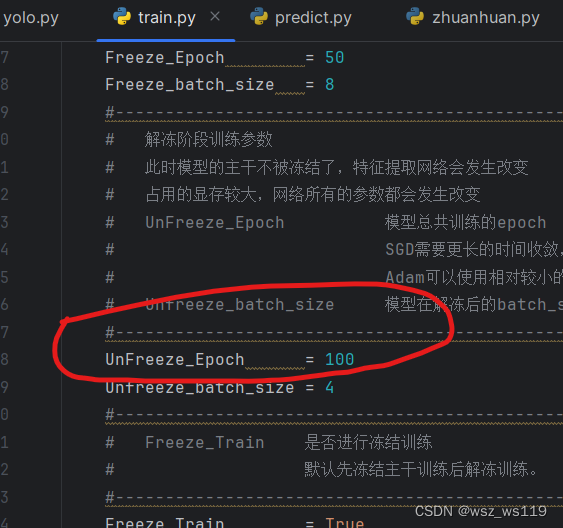
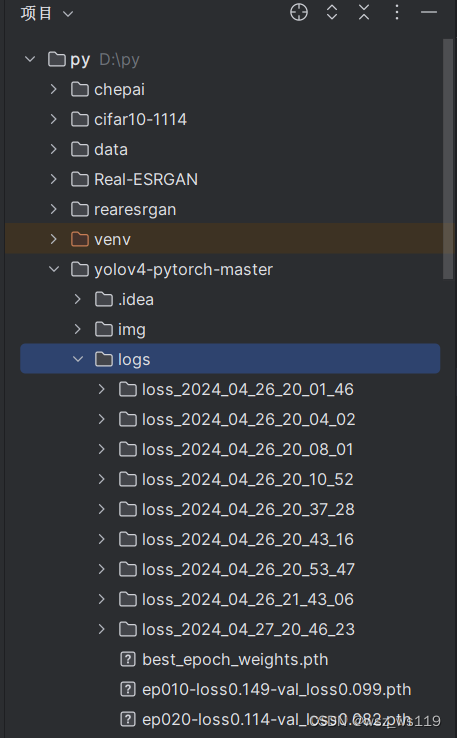
然后就是我们训练结束后得到的权值文件,都会保存在logs文件下,best_epoch_weights.pth文件就是我们训练得到的权值文件。
第二或三次训练
对于我们想要得到的权值文件,一次训练是不够的,所以我们需要第二、第三次训练。
第二次训练前我们需要把把logs文件best_epoch_weights.pth文件移到model_data文件下,可以换个名字方便我们区别。当然,我们可以调整参数UnFreeze_Epoch=300或者200,使得我们得到较好的权值.
在train.py文件,把参数model_path改成我们上一次得到的权值文件best_epoch_weights.pth
yolo.py文件也一样要改参数model_path,两个类的参数model_path都要改。
以此类推,第三次训练是权值文件改成第二次训练得到的权值文件。
训练多少次呢?
当平均精度均值(mAP)的值满足图片标注时就可以了(可能是80%左右)。当训练次数少了,mAP小(就像我第一次map55%,就没有标注图像),我们运行predict.py想要标注图像会发现没有标注。
3、predict.py文件
在运行predict.py文件前,把logs文件的best_epoch_weights.pth文件移到model_data文件下,需要把yolo.py文件的参数model_path的yolo4_weights.pth改成best_epoch_weights.pth。
predict.py文件不需要修改什么,实在是想改的话可以改参数fps_image_path,测试的图片路径
运行之后,输入我们想要进行目标检测的图片的路径,就可以得到一张标注好的图片
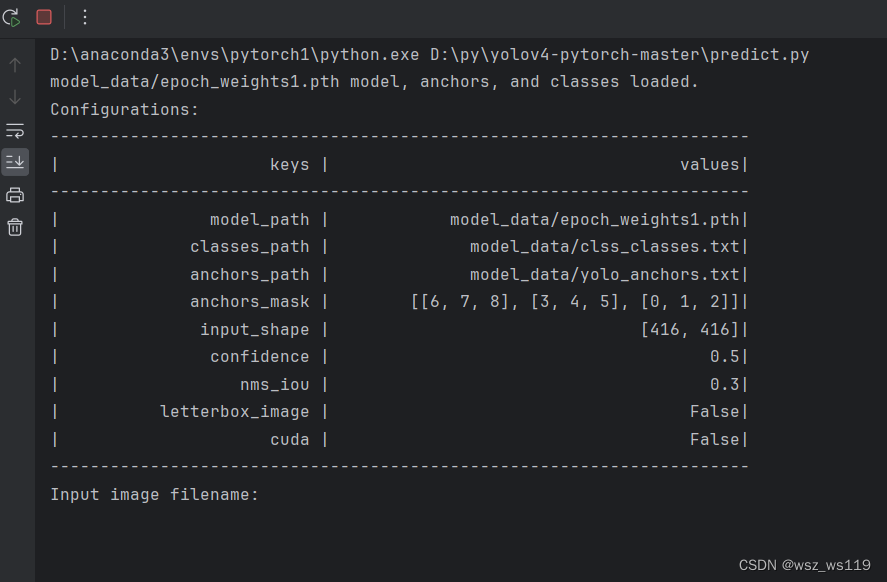
结果展示


可以看到结果的第二张图把猫识别成狗了,这是可能是数据集或者训练的模型权值不够好,我的数据集都是怼脸的照片,这个模型把猫识别成狗了。解决的办法是多训练一两遍、增加数据集量等
在运行这个文件的时候可能会得到错误:
AttributeError: 'ImageDraw' object has no attribute 'textsize'
我的解决办法是修改Pillow的版本
到最后,对于yolov4算法还有很多的用法,我这里只是简单的实现图片标注。


















 3252
3252



 到【灌水乐园】发言
到【灌水乐园】发言








