




 本文探讨了网络剪枝方法,分为非结构化和结构化两类。非结构化剪枝如Learning both Weights and Connections及DEEP COMPRESSION,通过剪枝、量化和编码压缩模型。结构化剪枝主要在通道层面操作,如Network Slimming和Channel Pruning。通过调整网络结构,寻找高效网络配置。最后反思网络剪枝的价值,指出剪枝更多是为寻找网络结构,而非单纯保留大模型权重。
本文探讨了网络剪枝方法,分为非结构化和结构化两类。非结构化剪枝如Learning both Weights and Connections及DEEP COMPRESSION,通过剪枝、量化和编码压缩模型。结构化剪枝主要在通道层面操作,如Network Slimming和Channel Pruning。通过调整网络结构,寻找高效网络配置。最后反思网络剪枝的价值,指出剪枝更多是为寻找网络结构,而非单纯保留大模型权重。
本文记录一下对model pruning方法的学习,我只是挑了一些代表性的论文阅读一下,了解pruning的思路。
首先推荐一篇博客,闲话模型压缩之网络剪枝(Network Pruning)篇,其中的分类和思路讲得都非常清楚。本文中看的论文大多是该篇博客中讲的,本文相对于该博客,起一个细化和补充的作用,记录一下自己的理解。
先说一下Pruning的方法的分类,可以查阅其他博客,都将其分类成“结构化”和“非结构化”的两类。我认为“结构化”的意思就是不打破filter的表示,比如剪掉某一个channel,直观的来讲就是整个网络模型看起来就是超参数变化了。而“非结构化”则是打破了filter的表示,稀疏地不规则。
非结构化剪枝之后的结果打破了现有框架的表示,需要硬件的支持才能起到预期效果,所以当前研究大多是结构化的。
非结构化的
这里只介绍两篇非结构化的,属于比较早期的论文。
Learning both Weights and Connections for Efficient Neural Networks
代码:https://github.com/Guoning-Chen/SimplePruning-PyTorch
推荐结合代码和文章一起看,想法很容易理解。就是统计一下整个网络中权重的大小,然后把绝对值小权重的剪掉(具体就是置0,代码中用的是mask的方法)。
DEEP COMPRESSION: COMPRESSING DEEP NEURAL NETWORKS WITH PRUNING, TRAINED QUANTIZATION AND HUFFMAN CODING
是上一篇文章的改进,提出了剪枝+量化+哈夫曼编码的三步走策略。
先说剪枝,就是上文的剪枝方法,把绝对值小的去掉。既然要储存稀疏矩阵,那肯定要储存index。如果index数字很大的话,那储存一个index用的空间也不小。所以本文提出了储存relative index,如下图:
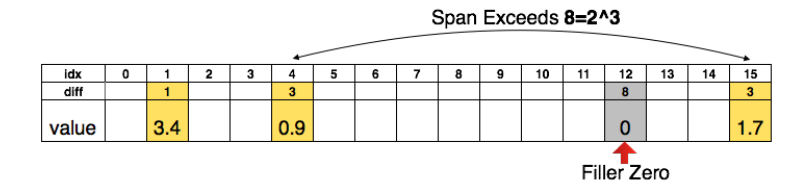
比如说储存原来的index,那么index最大是15,所以每个index需要4个bits,那么储存所有的index需要12bits。如果储存relative index,也就是上图的diff,限制diff最大为8,两个index之间超过8用0补充。那么储存每个index需要3bits,一共4个diff,所以也需要12个bits。那么如果最大index不是15,而是几万,这就凸显了用diff的好处。
再说量化,有了稀疏权重,那么权重是用32bits的浮点数表示,是不是也可以减少表示位数。如下图:
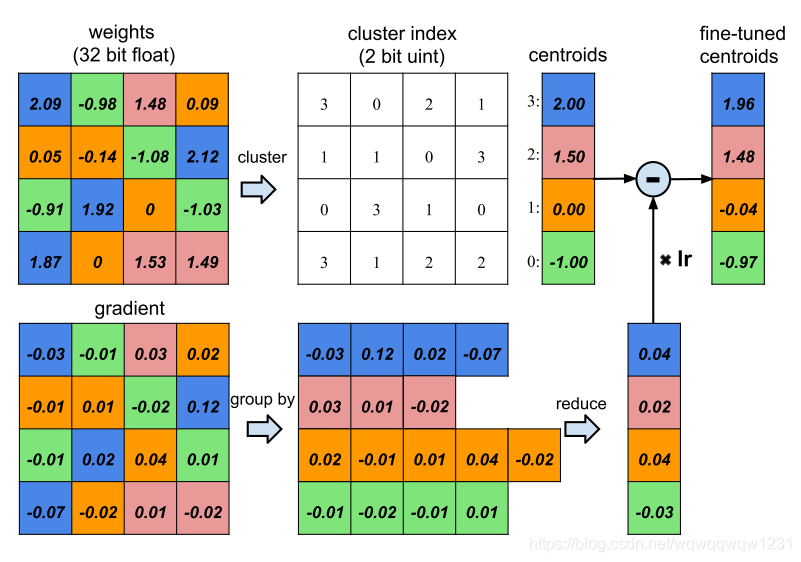
一共16个权重,原本占据16*32bits。现在用kmeans聚类,聚成4个类,表示类别的cluster index需要2bits,然后每个类用一个共享权重表示,所以占据空间是16*2+4*32bits。
最后再用Huffman编码进一步压缩权重。
结构化的
Learning Efficient Convolutional Networks through Network Slimming
对通道上做剪裁。本文一开始提出,在训练网络的同时,对每个feature map的channel加一个可训练的权重 γ \gamma γ,把权重乘到channel上面作为输出的feature map。在剪枝的时候,剪去 γ \gamma γ小的,也就是不重要的。
但这其实有个问题,对于没有BN的网络, γ \gamma γ变小和weight增大是相互抵消的,所以 γ \gamma
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 1072
1072

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









