



上一篇中,大致聊了下国产小钢炮MiniCPM的特性,看起来很不错,可玩性很高。
今天,主要来说一下,如何在本地运行这个项目。
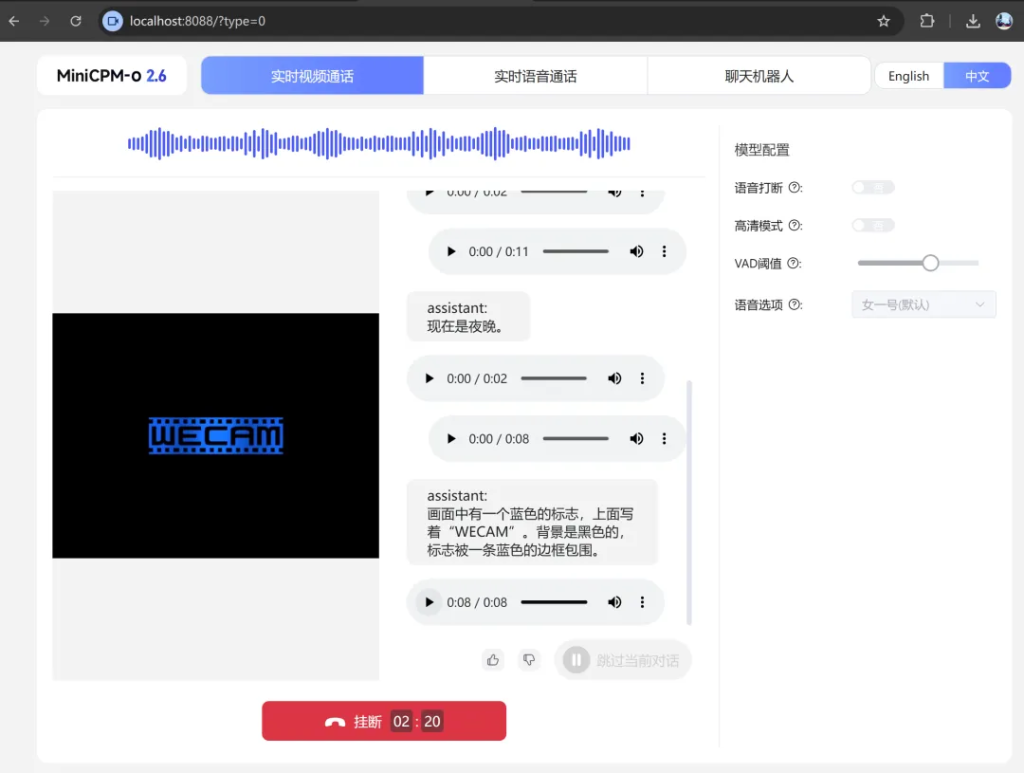
配置过程花了一些时间,最终还是成功了,可以正常进行视频通话,语音通话,和聊天机器人。安装和测试过程中遇到了几个棘手的问题。下面就完整记录下安装过程和遇到的问题的解决方案。
基础准备
巧妇难为无米之炊,有些比较基础的东西必须先准备好。
- Windows10/11
- 显卡RTX3060或者其他更强显卡
- 安装软件git,miniconda,Nodejs
这些应该不难,不懂的话,网上资料也很多。
为了运行这个项目中的webdemo,会涉及到Python和NodeJS相关内容,还有一个浏览器的设置问题。所以我们就这几个重点来分块说明。
模型服务的安装和配置
模型服务主要负责模型的载入和推理,然后Web端调用,这个是核心部分。这一部分完全由Python编写。
打开本地CMD或者WIndowws PowerShell 以此运行下面的命令。
克隆项目
git clone https://github.com/OpenBMB/MiniCPM-o.git
cd MiniCPM-o创建虚拟环境并激活
conda create -n MiniCPM-o python=3.10 -y
conda activate MiniCPM-o单独安装torch和onnxruntime
pip install torch==2.4.0 torchvision==0.19.0 torchaudio==2.4.0 --index-url https://download.pytorch.org/whl/cu121
pip install onnxruntime-gpu==1.20.1使用req文件安装其他依赖。
pip install -r requirements_o2.6.txt因为torch和onnx已经安装完成了,所以这一步运行之前可以打开requirements_o2.6.txt,把相应的项目注释掉或者删除掉。
正常来说,依赖安装到这里就结束了。
其实,最麻烦的才刚刚开始。接下来这个问题,浪费了我一下午的时间。
flash_attn的问题
当你试图启动模型服务的时候,你会遇到这样的错误提示。
ImportError: This modeling file requires the following packages that were not found in your environment: flash_attn. Run `pip install flash_attn`正常来说,就是根据提示运行如下命令:
pip install flash_attn然后就完美收工了。
实际上很可能会遇到CUDA需要大于11.7的提示。
为了解决这个问题,只能根据提示升级cuda和cudnn(浪费一波时间)
升级完成之后在执行安装命令,没有错误,但是会开始本地编译。
编译了四个多小时,放弃了…
之所以会这样,是因为没有匹配本地环境的依赖包。
Windows下无法自动安装一些包也很常见。
一个比较好的解决思路是,找别人编译好的WHL文件。
进过多番查找和尝试,最终解决了这个问题。
直接用编译好的文件,执行命令:
pip install whl\flash_attn-2.7.0.post2-cp310-cp310-win_amd64.whl之前命令前,获取到这个文件,放到whl文件夹下面。
这里需要注意要几个点:
Python版本为3.10
Torch为2.4.0 对应的cuda为 cu121
上面的版本,但凡搞错一个,就会痛不欲生。
所有依赖正确安装之后,就可以启动模型服务了。
运行服务器:
python web_demos/minicpm-o_2.6/model_server.py运行之后,会自动去HF下载模型,模型大概有10G+,所以需要一个较好的网络,并且保持网络通畅。
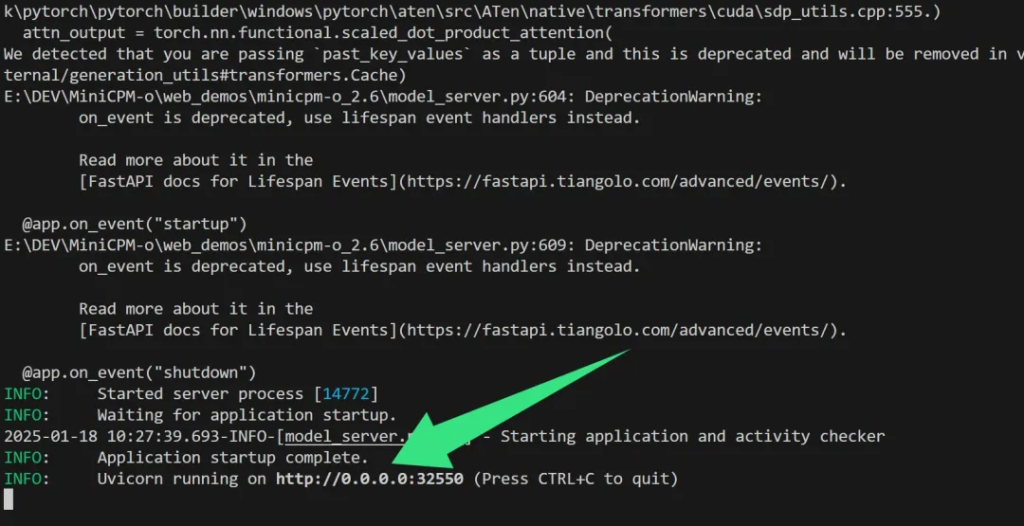
运行成功之后会会显示Application startup complete,同时显示服务运行在某个端口。
由于默认下载的是没有量化的版本,所以加载这个模型需要18G显存。
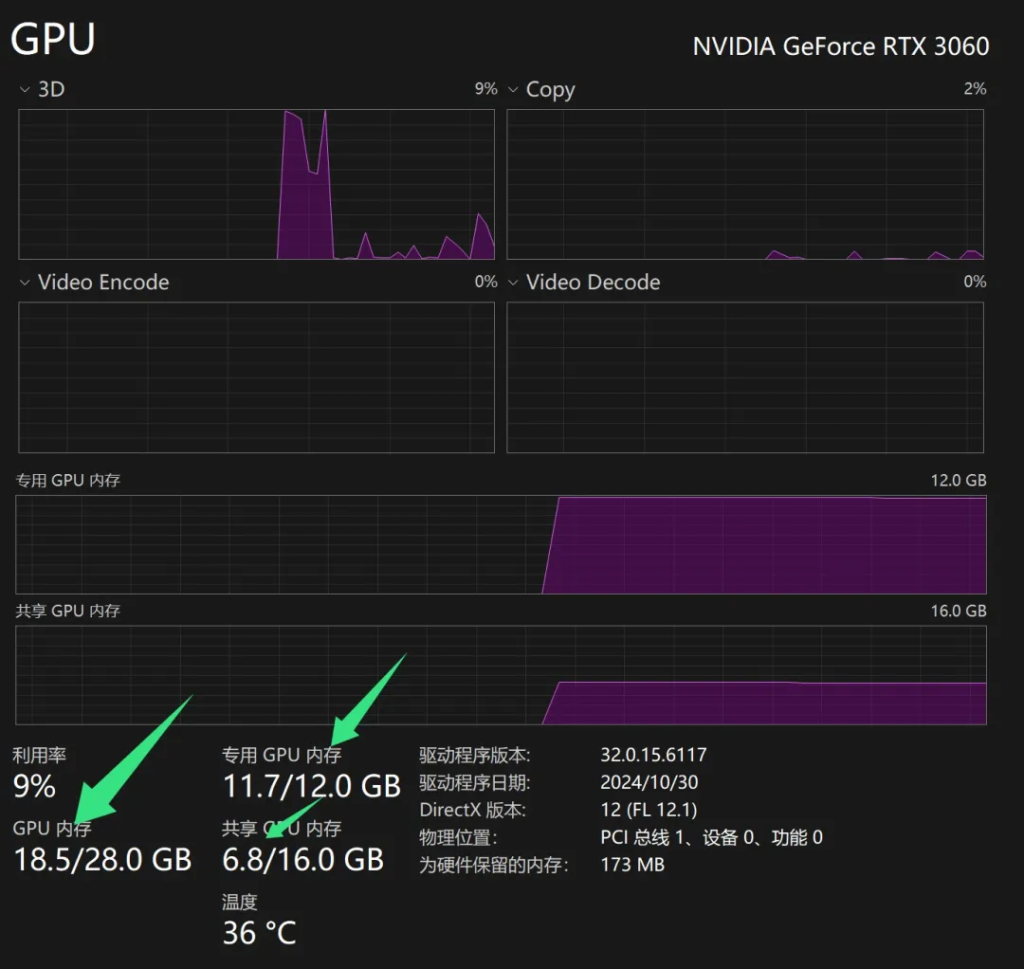
我一直以为12G的3060无法载入这个模型,但是实际情况是,它会使用虚拟内存。最终整个电脑用去了18.5的显存。除去其他软件的使用量,确实和官方要求的18G非常接近。
这里顺带提一嘴:
MiniCPM-o 2.6 int4 的显存需求为9GB
MiniCPM-V 2.6 gguf的显存需求为6GB
这就是之前说到的低配电脑也能运行的原因所在。
到这里Python部分就完成了。
网页服务的安装和配置
网页服务使用了vue相关技术,需要nodejs环境,如果没有用过,需要先安装nodejs。
安装nodejs
这个很简单,打开nodejs.org,下载Node.js ,然后双击运行安装即可。
安装过程一路Next默认设置安装。
如果之前就有Nodejs 使用 node -v 命令查看一下版本。版本太低需要升级一下。
运行web服务:
cd web_demos/minicpm-o_2.6/web_server
npm install -g pnpm
pnpm install # install requirements
pnpm run dev # start server这个过程非常快。
启动成功之后显示如下:
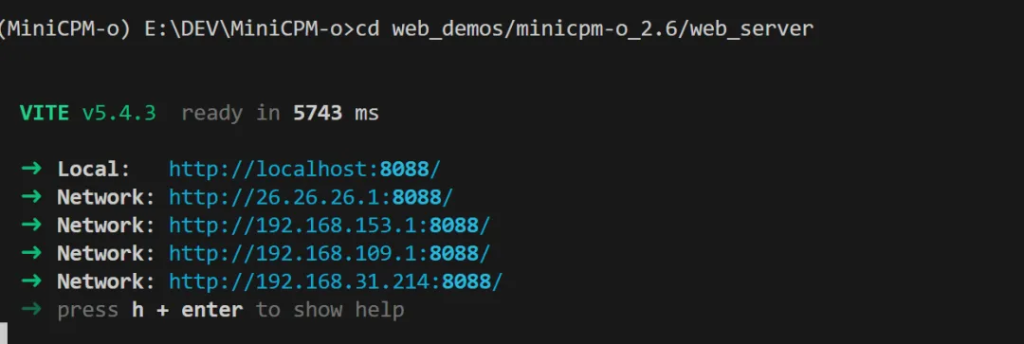
这里有好多地址,包括本地local还有不同网络的IP地址。本机测试直接打开local地址,如果局域网其他电脑测试,或者手机测试,可以打开局域网地址。比如我这里的192.168.31.214 就是局域网地址。
浏览器的设置
我首先是在本地电脑测试,但是遇到了一个问题,让我摸不着头脑。实时通话和实时语音点了之后全部没有反应,而聊天机器人可以正常使用。这一度让我以为是的安装配置有问题。
其实是和浏览器权限有关系。由于本地IP运行,没有https证书。所以chrome浏览器会直接限制你调用本地相机和麦克风。这种限制甚至不会有任何提示。左上角不会弹出授权提示!!!
为了解决这个问题,需要进行如下设置:
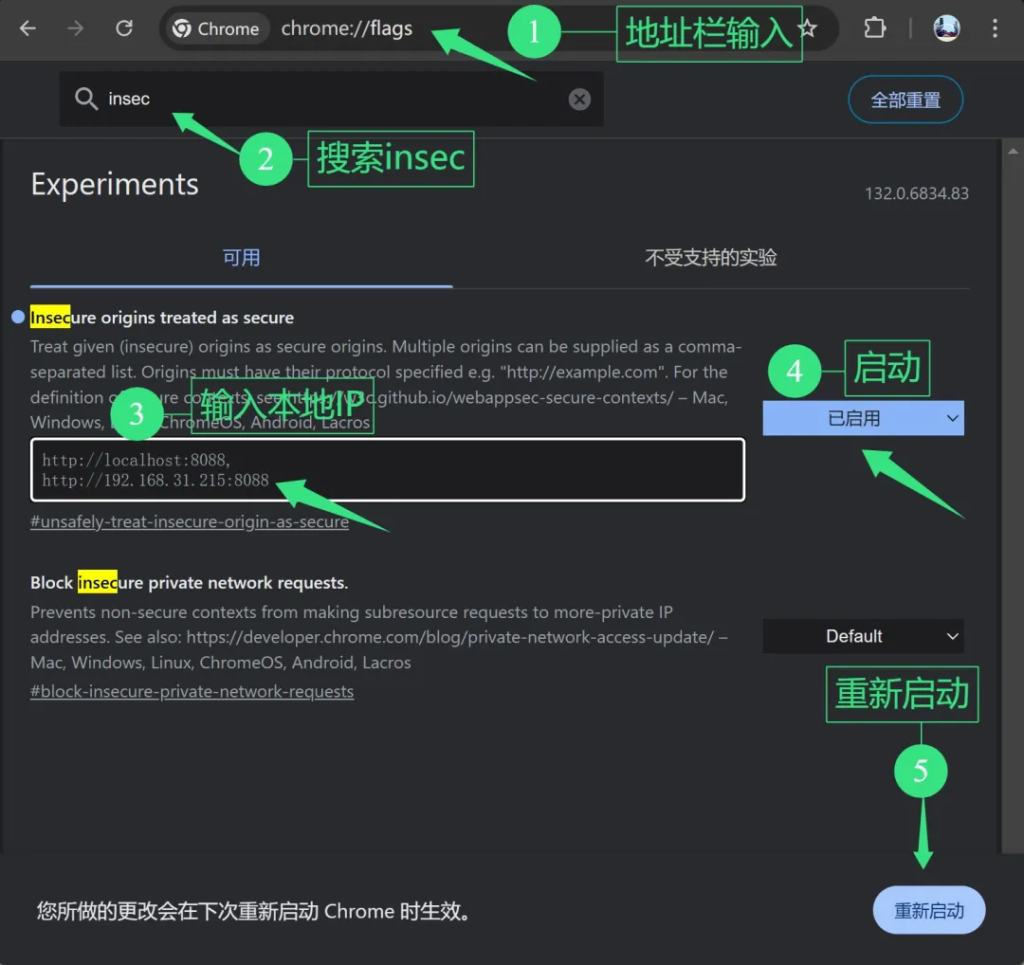
1️⃣地址栏输入chrome://flags/
2️⃣找到insecure 选项
3️⃣输入本地的Ip地址
4️⃣启动改选项
5️⃣重新启动浏览器
再次打开,你就可以通过下面的设置启动摄像头和麦克风了。
显示点击浏览器左上角的地址栏前面的不安全。
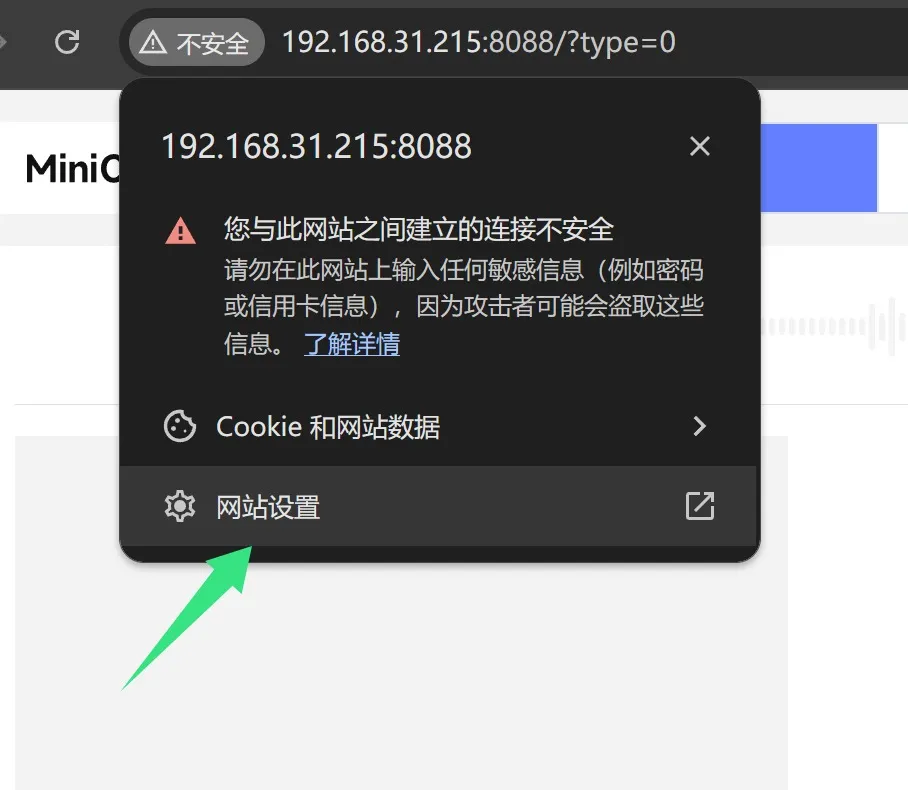
在弹出菜单中点击网站设置。
在网站设置中,对该网址启用摄像头和麦克风权限
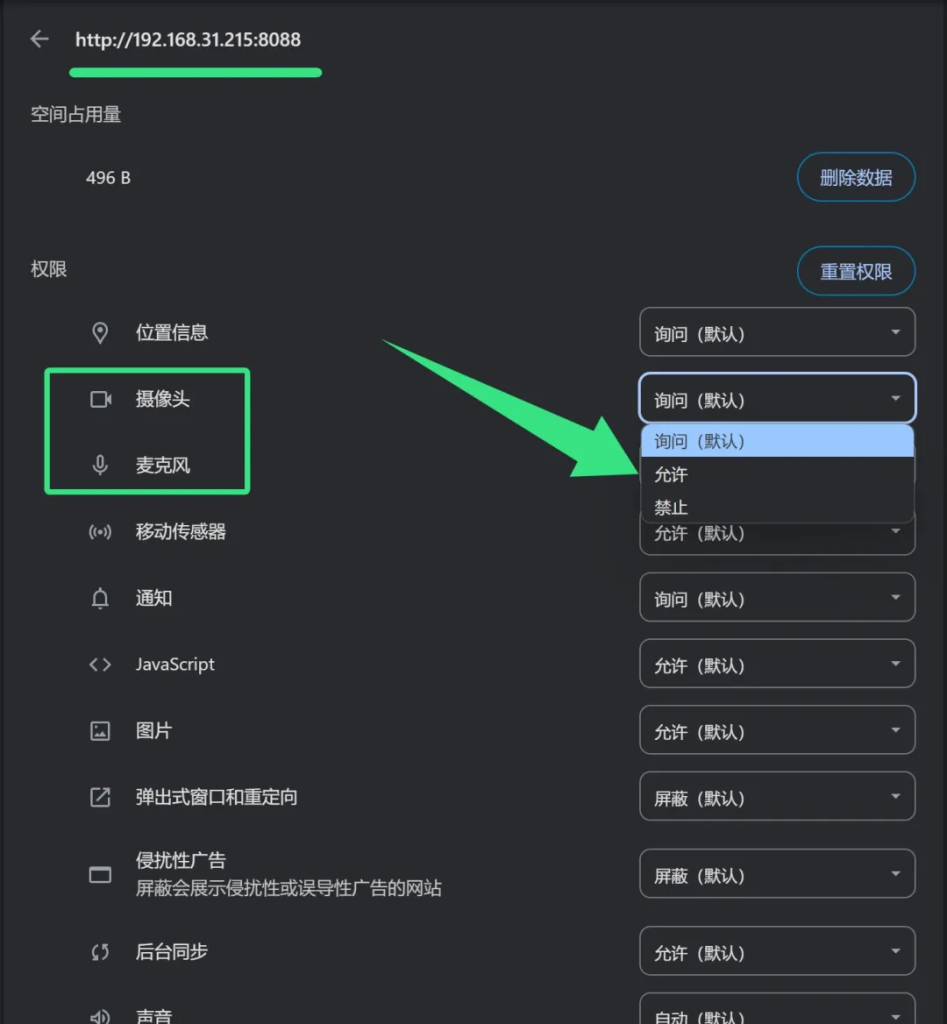
下拉中选择询问或者允许。
设置完成之后,刷新网页。应该就可以了。
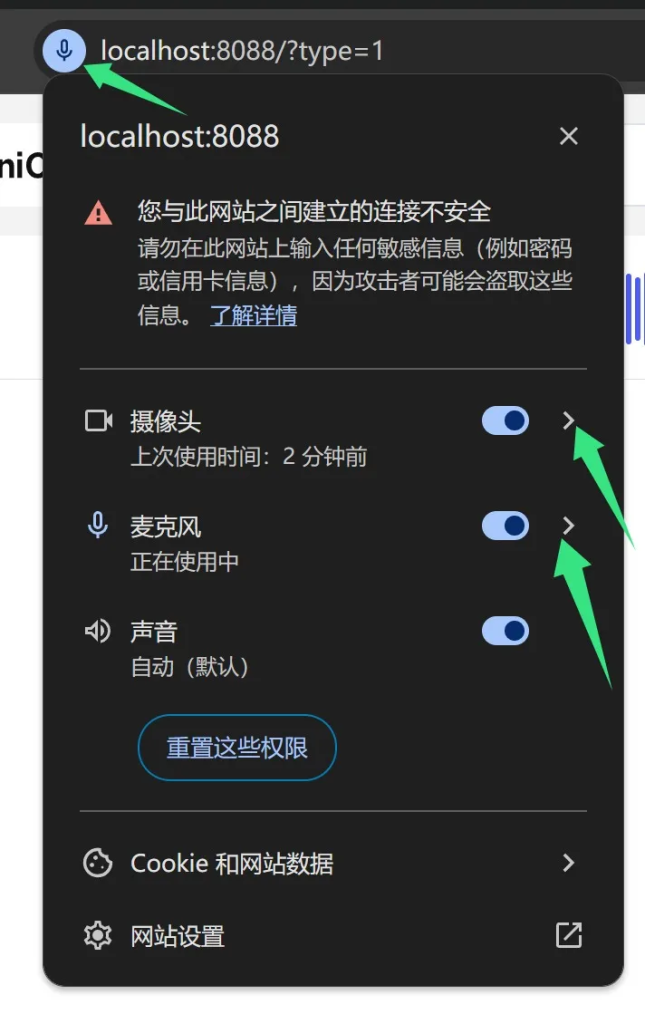
可以看到摄像头和麦克风都已经启用了。
到这里Chrome的设置就完成了。
运行测试
所有设置完成之后,就可以开始尝试各种功能了。
视频通话:
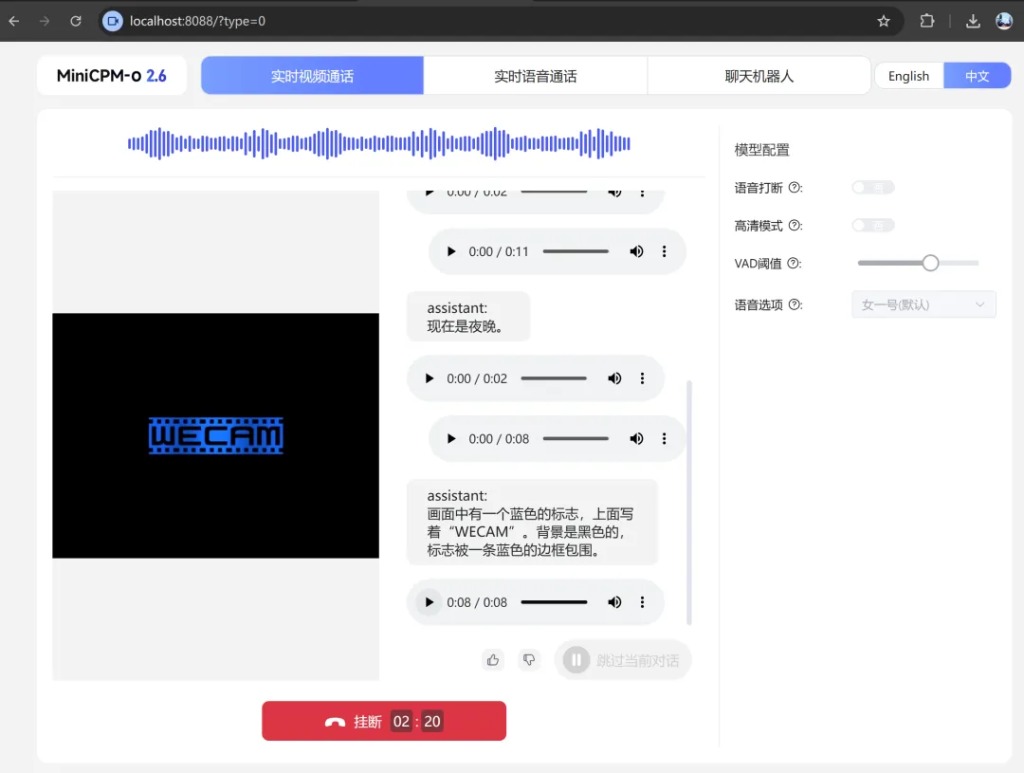
点击视频通话,就可以开始了。
由于我使用了原版模型,加载时使用了虚拟内存,所以导致速度非常…慢,但是确实能用。另外由于我本地摄像头比较多,不知道chrome是什么逻辑,调用了虚拟摄像头Wecam。
语音通话:
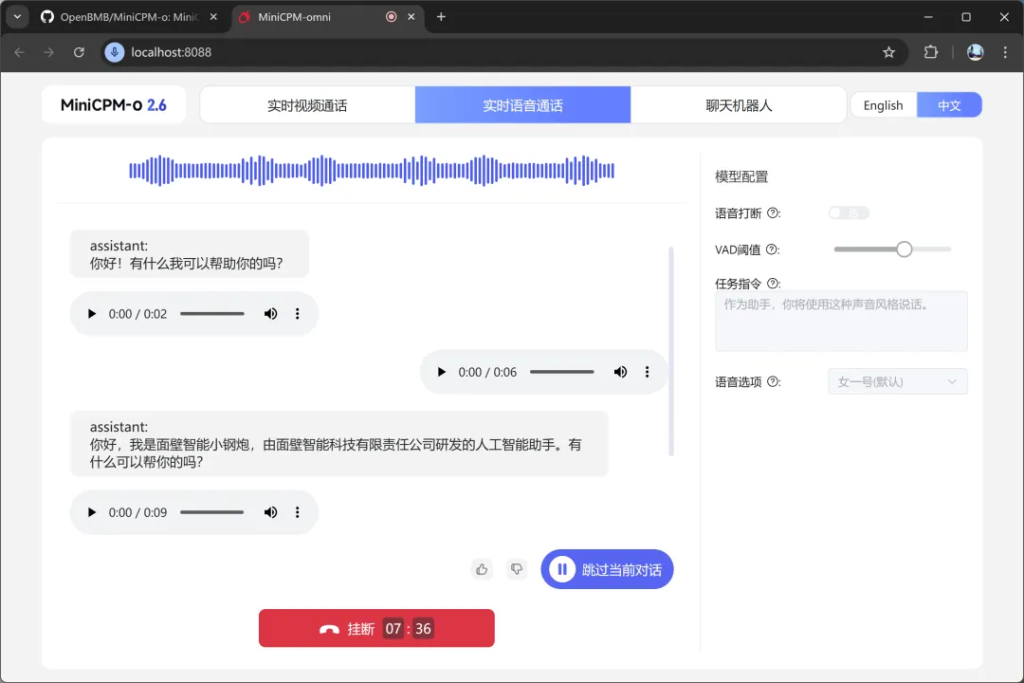
语音通话也完全没问题,接通后直接说就行了。
但是这个功能也面临一些问题,比如声音输入检测问题,检测不好,会有大量干扰声音,在吵杂的环境中很难测试。另外一个问题,可能是电脑配置关系,声音会断断续续。另外,语音对话的声音会发生变化。
毕竟是Demo,还有很多完善的空间。
聊天机器人:
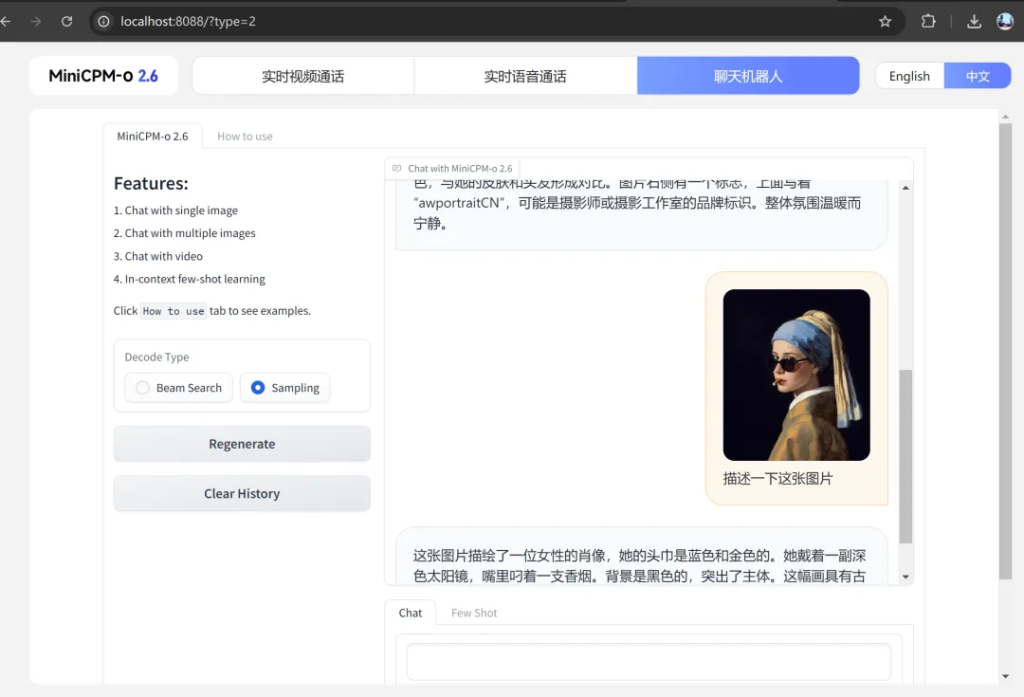
这个功能,没有语音和视频,用起来就稳定很多。只要上传一个张图片或视频,就可以分析上传的内容,并进行讨论了。通过功能就可以对它的图片,视频理解能力做一个直观的测试。
这个使用很流畅,没啥问题,就是必须上传图片或者视频之后,才能开启对话。
安装配置就是这样了,后面就是换台电脑搞个量化模型,把显存降下来,速度拉上去。
收工收工!


















 609
609

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









