




DeepSeek R1虽然免费,但是基本到了无法使用的状态。一两轮对话后,就开始服务忙了。
好在这是一个开源模型,大量的第三方平台开始上线了。
上一篇我们就讲过硅基流动。
最近听闻腾讯云也上线了 DeepSeek-V3、DeepSeek-R1 满血版模型。
而且可以免费不限量使用。
具体规则如下:
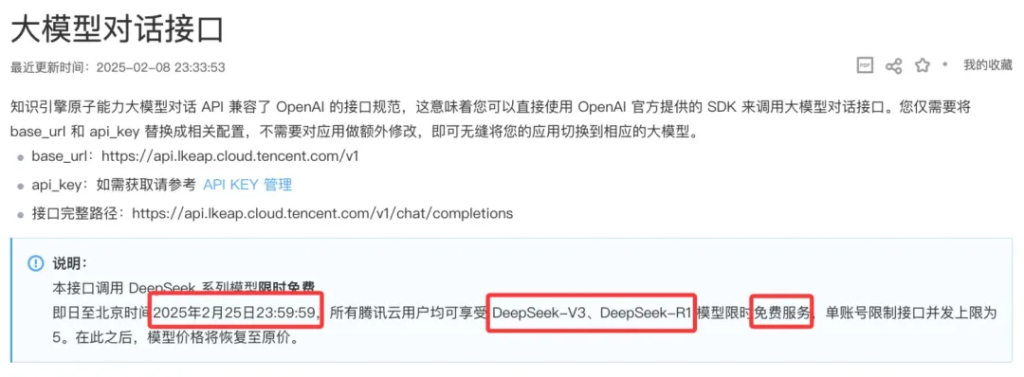
截至 2 月25 之前,可以完全免费使用 V3 和 R1 模型。只限制了并发,没有限制数量。对普通用户来说,这个并发完全够用。
那么大家一起来暴力测试一下鹅厂的实力(钞能力),一起撸它几亿token,把我腾讯 SSSSVIP 的钱撸回来😄。
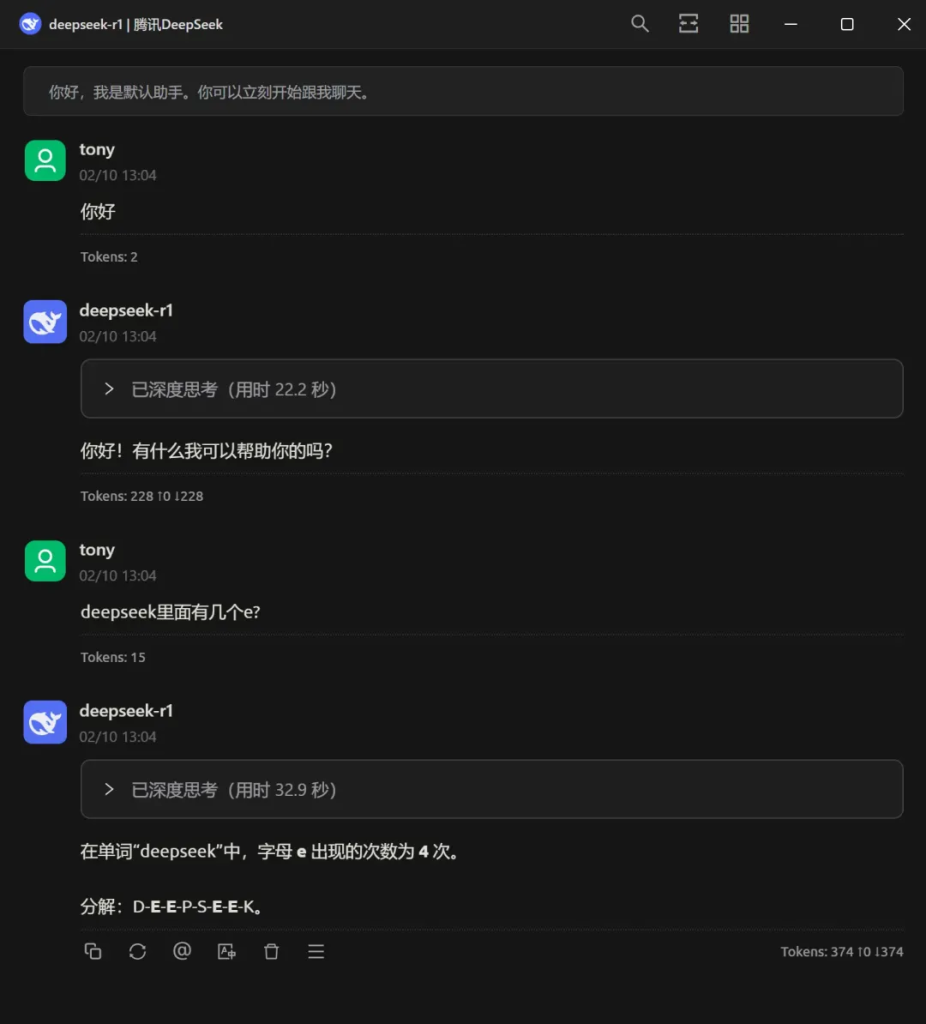
我测试过了,多轮对话,都没有出现卡死的情况,速度大概在 10t/s,不能说多快,但是完全能用。
下面我就完整的讲解一下如何使用腾讯云这个服务,进行本地可视化的对话,让你的DeepSeek R1空下来。
无需编程,无需复杂配置,几分钟搞定。
注册账号开通服务
腾讯云是腾讯云服务平台,如果要使用这个平台的服务第一步自然是注册。注册很简单,可以用微信 QQ 授权登录。
注册完成之后,需要开通以下服务。
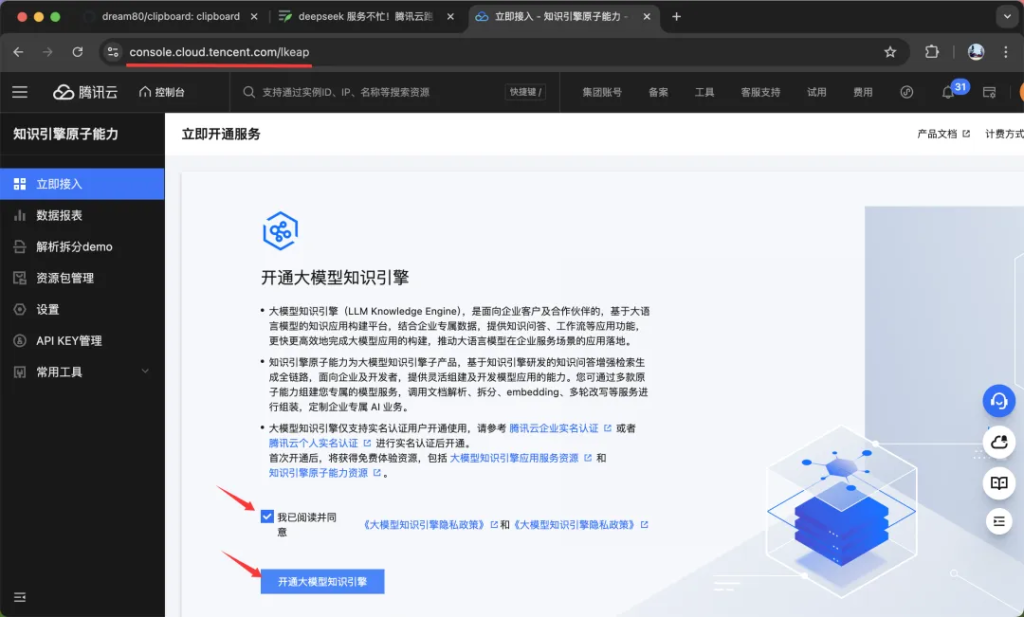
如上图,勾选已经阅读,点击开通大模型知识引擎。
开通之后会跳转到如下界面:
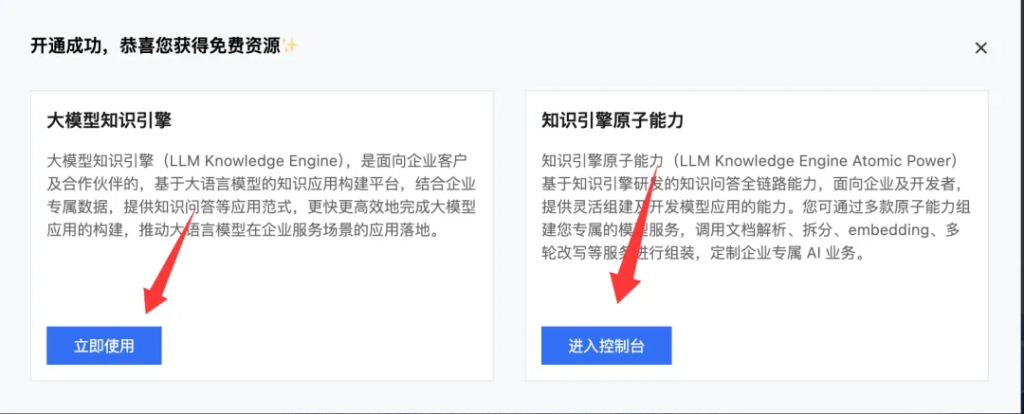
这里有两个选项,一个是立即使用,几个是进入控制台。我们只要直接点击立即使用即可。
当然也可以进入控制台看一眼。
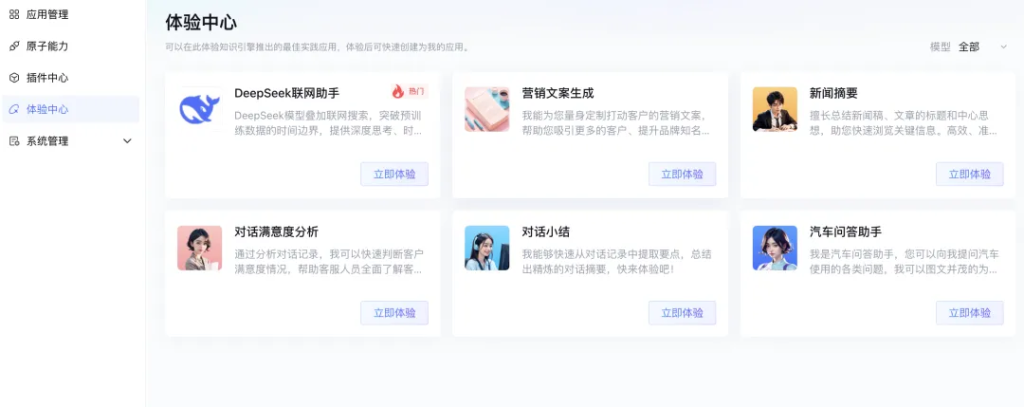
控制台里可以看到一些预设的应用。比如 deepseek 联网助手,营销文案生成,对话满意度分析…. 这个应该是类似 coze 的智能体。
获取密钥APIKEY
点击立即使用之后,就会跳转到接入界面。
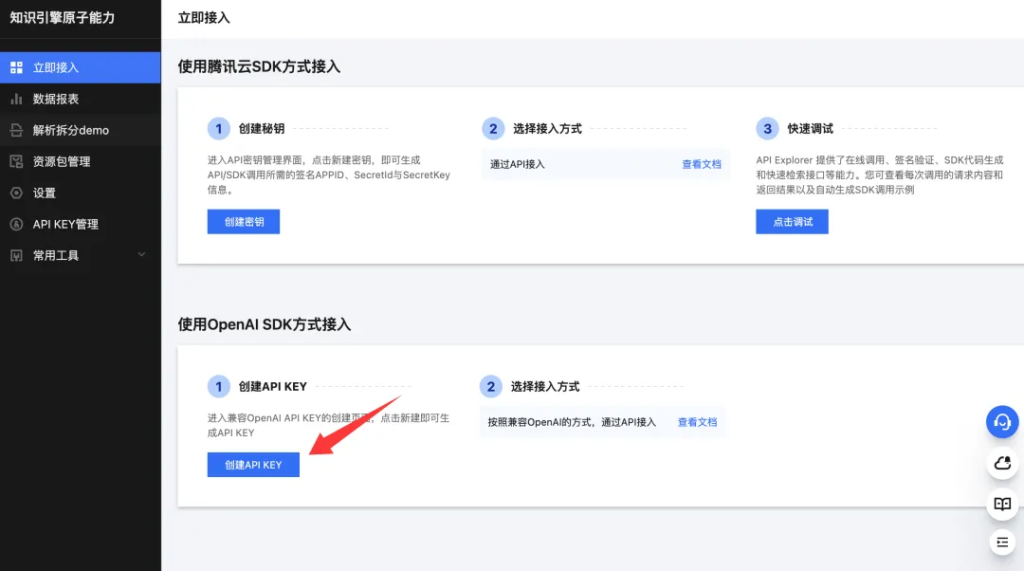
这里有两种接入方式,一种是腾讯云 SDK 方式,一种是 OpenAI SDK 方式。两种方式都可以使用,但是为了兼容性更强,方便后续使用客户端,我们选择 OpenAI 的方式。
现在的大模型接口基本都兼容 OpenAI,很多可视化的客户端工具也兼容 OpenAI 的方式。
点击创建APIKEY 进入密钥管理界面。
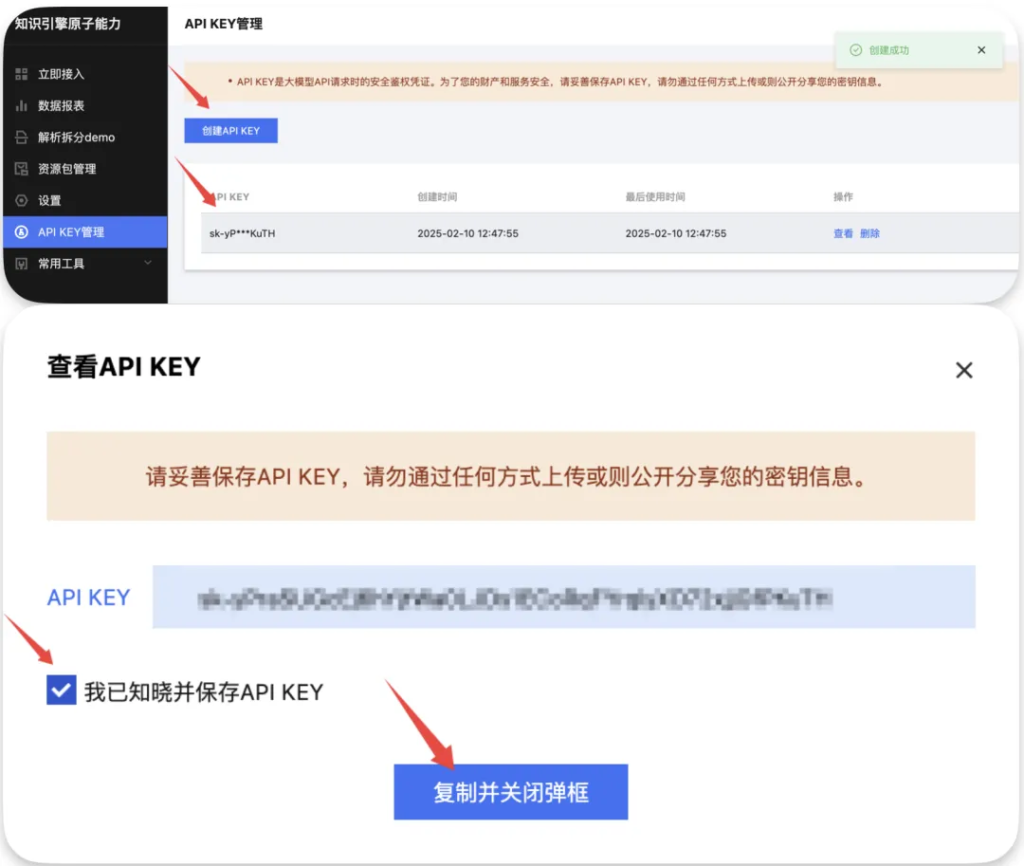
然后在这个界面再次点击创建APIKEY。点击之后下方就会出现一条记录。
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 6856
6856

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









