







 本文介绍了决策树在分类中的应用,强调了其优势如可视化、对数据准备要求低等,同时也指出了过拟合和不稳定性等劣势。通过scikit-learn库的`DecisionTreeClassifier`进行实例演示,包括在Iris数据集上的应用,并提供了安装和使用Graphviz进行决策树可视化的指南。
本文介绍了决策树在分类中的应用,强调了其优势如可视化、对数据准备要求低等,同时也指出了过拟合和不稳定性等劣势。通过scikit-learn库的`DecisionTreeClassifier`进行实例演示,包括在Iris数据集上的应用,并提供了安装和使用Graphviz进行决策树可视化的指南。
机器学习训练营——机器学习爱好者的自由交流空间(入群联系qq:2279055353)
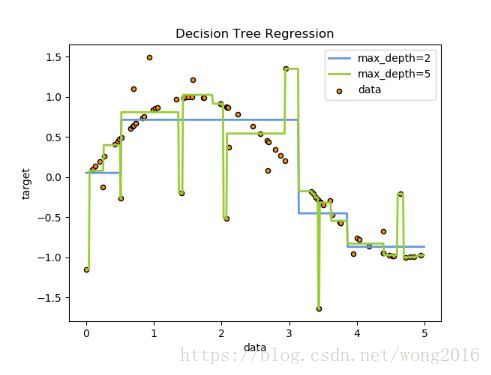
决策树(Decision Trees, DTs)是一种非参数的有监督学习方法,广泛使用于分类和回归中。它的目标是,通过数据特征学习简单的决策规则,产生一个决策模型预测一个目标变量的值。例如下面的例子,决策树从数据学习一个if-then-else规则集,近似一条正弦曲线。树越深,决策规则和拟合的模型就越复杂。
决策树具有以下优势:
-
树能可视化,容易理解和解释。
-
对数据准备要求低。其它的技术经常要求数据归一化、变量虚拟化、删除空白值。然而也要注意,决策树不支持缺失值。
-
使用树的代价,与训练树的数据点的数量是对数关系。
-
能够处理数值和类别数据。
-
能够处理多输出问题。
-
可以使用统计检验评价模型。
-
即使数据的真实模型与假设有点不一致,决策树的表现也很出色。
决策树的劣势包括:
-
决策树能产生过度复杂的树,不能很好地概括数据,这被称为过度拟合(overfitting).
-
决策树可能是不稳定的,数据的小的变异都可能导致生成完全不同的树。这个问题可以使用决策树集成方法解决。
-
学习一棵最优决策树是NP-complete的。因此,实际的决策树学习算法大多基于启发式学习,例如greedy算法。这些启发式算法并不能保证得到全局最优的决策树,可以通过在一个集成学习里训练多棵树的办法解决这个问题。
-
如果一些类占优势的话,决策树学习可能产生有偏的树。
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章

















 2万+
2万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









