







sourenaKhanzadeh/snakeAi: Reinforcement Learning with the classic snake game
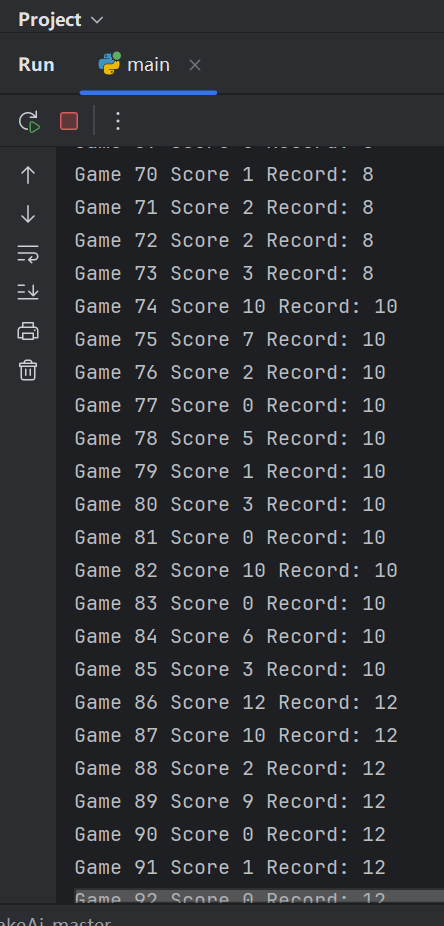
运行效果

代码分析
agent.py
class Agent:
def __init__(self, game, pars=dict()):
# 初始化参数与组件
def remember(self, *args):
# 存储经验到记忆库
def train_long_memory(self):
# 批量经验回放训练
def train_short_memory(self, *args):
# 单步即时训练
def get_action(self, state):
# ε-greedy策略选择动作 def __init__(self, game, pars=dict()):
"""
(Agent, Snake, dict()) -> None
Initialize everything
get everything that is passed from
json file to modify attributes and train model
"""
self.n_games = 0
self.epsilon = pars.get('eps', EPSILON)
self.eps = pars.get('eps', EPSILON)
self.gamma = pars.get('gamma', GAMMA) # discount rate
self.eps_range = pars.get('eps_range', EPS_RANGE)
print(self.epsilon ,self.eps)
self.memory = deque(maxlen=MAX_MEMORY) # popleft()
self.model = Linear_QNet(len(game.get_state()), pars.get('hidden_size', HIDDEN_SIZE), OUTPUT_SIZE)
self.trainer = QTrainer(self.model, lr=pars.get('lr',LR), gamma=self.gamma)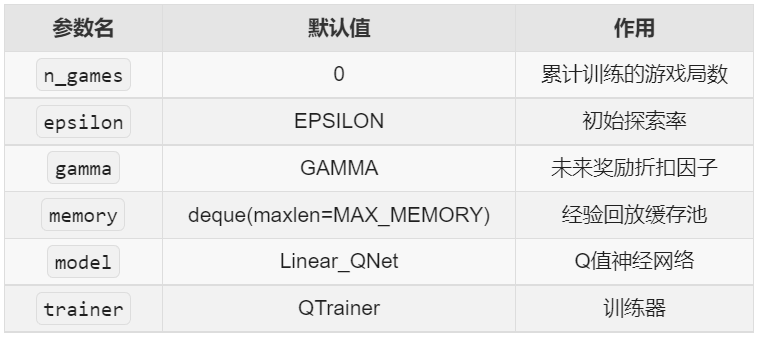
1. remember() - 经验存储
def remember(self, *args):
state, action, reward, next_state, done = args
self.memory.append((state, action, reward, next_state, done))- 功能:将单步经验
(s,a,r,s',done)存入记忆库 - 设计要点:
- 使用双端队列
deque实现先进先出 maxlen=MAX_MEMORY限制记忆容量,避免内存溢出
- 使用双端队列
2. train_long_memory() - 批量训练
def train_long_memory(self):
if len(self.memory) > BATCH_SIZE:
mini_sample = random.sample(self.memory, BATCH_SIZE)
else:
mini_sample = self.memory
states, actions, rewards, next_states, dones = zip(*mini_sample)
self.trainer.train_step(states, actions, rewards, next_states, dones)- 流程:
- 当记忆库>BATCH_SIZE时随机采样
- 解压为独立的数据列表
- 调用训练器进行批量梯度下降
- 目的:打破数据相关性,提高训练稳定性
3. train_short_memory() - 即时训练
def train_short_memory(self, *args):
state, action, reward, next_state, done = args
self.trainer.train_step(state, action, reward, next_state, done)- 适用场景:每个时间步立即更新
- 优缺点:
- 优点:快速响应最新经验
- 缺点:数据相关性高,容易震荡
4. get_action() - 动作选择
def get_action(self, state):
self.epsilon = self.eps - self.n_games
if is_random_move(self.epsilon, self.eps_range):
move = random.randint(0, 2)
else:
state0 = torch.tensor(state, dtype=torch.float)
prediction = self.model(state0)
move = torch.argmax(prediction).item()
final_move[move] = 1
return final_move
- ε-greedy策略:
epsilon = initial_eps - n_games线性衰减- 随机动作概率随训练局数增加而降低
- 动作编码:独热编码形式
[左转, 直行, 右转]
model.py
一、神经网络架构:Linear_QNet
1. 网络结构设计
class Linear_QNet(nn.Module):
def __init__(self, input_size, hidden_size, output_size):
super().__init__()
self.linear1 = nn.Linear(input_size, hidden_size) # 输入层->隐藏层
self.linear2 = nn.Linear(hidden_size, output_size) # 隐藏层->输出层
def forward(self, x):
x = F.relu(self.linear1(x)) # ReLU激活
x = self.linear2(x) # 线性输出
return x- 输入特征:游戏状态向量(如蛇头坐标、食物位置等)
- 隐藏层:单隐层全连接结构
- 输出层:对应3个动作的Q值估计
- 激活函数:ReLU引入非线性,仅用于隐藏层
2. 模型保存机制
def save(self, file_name='model.pth'):
model_folder_path = './model'
os.makedirs(model_folder_path, exist_ok=True) # 自动创建目录
torch.save(self.state_dict(), os.path.join(model_folder_path, file_name))
- 保存内容:仅存储模型参数(state_dict)
- 路径管理:统一保存到
./model目录下
二、训练器类:QTrainer
1. 初始化配置
def __init__(self, model, lr, gamma):
self.model = model
self.optimizer = optim.Adam(model.parameters(), lr=lr)
self.criterion = nn.MSELoss() # 均方误差损失
self.gamma = gamma # 折扣因子
- 优化器选择:Adam优化器平衡收敛速度与稳定性
- 损失函数:MSE衡量Q值预测误差
- 超参数:γ控制未来奖励的重要性
2. 训练步骤分解
def train_step(self, state, action, reward, next_state, done):
# 张量转换与维度处理
state = torch.tensor(state, dtype=torch.float)
...
if len(state.shape) == 1: # 单样本转批量形式
state = torch.unsqueeze(state, 0)
...
# Q值预测与目标计算
pred = self.model(state)
target = pred.clone()
for idx in range(len(done)):
Q_new = reward[idx]
if not done[idx]:
Q_new += self.gamma * torch.max(self.model(next_state[idx]))
target[idx][torch.argmax(action[idx]).item()] = Q_new
# 反向传播
self.optimizer.zero_grad()
loss = self.criterion(target, pred)
loss.backward()
self.optimizer.step()
关键步骤说明:
-
输入处理:
- 将numpy数组转为PyTorch张量
- 单个样本添加batch维度([x] -> [1, x])
-
目标Q值计算:
- 对于终止状态:
Q_new = reward - 对于非终止状态:
Q_new = reward + γ * max(next_state_Q) - 只更新执行动作对应的Q值:
target[idx][action_idx] = Q_new
- 对于终止状态:
-
梯度更新:
- 计算预测Q值与目标Q值的MSE损失
- 反向传播更新网络参数

















 3万+
3万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









