







初始版本
class TicTacToe:
def __init__(self):
self.board = [" " for _ in range(9)] # 使用列表存储棋盘状态
self.current_player = "X" # 当前玩家
self.winner = None # 胜利者
self.moves = 0 # 总步数计数器
def print_board(self):
"""打印当前棋盘状态"""
print("\n")
for i in range(3):
row = self.board[i * 3: (i + 1) * 3]
print("| " + " | ".join(row) + " |")
if i < 2:
print("-------------")
@staticmethod
def print_board_nums():
"""显示位置编号示意图"""
print("\n位置编号:")
number_board = [[str(i + 1) for i in range(j * 3, (j + 1) * 3)] for j in range(3)]
for row in number_board:
print("| " + " | ".join(row) + " |")
def make_move(self, position):
"""处理玩家移动"""
if self.board[position - 1] == " ":
self.board[position - 1] = self.current_player
self.moves += 1
return True
return False
def check_winner(self):
"""检查游戏是否结束"""
# 检查所有可能的获胜组合
win_combinations = [
[0, 1, 2], [3, 4, 5], [6, 7, 8], # 横向
[0, 3, 6], [1, 4, 7], [2, 5, 8], # 纵向
[0, 4, 8], [2, 4, 6] # 对角线
]
for combo in win_combinations:
a, b, c = combo
if self.board[a] == self.board[b] == self.board[c] != " ":
self.winner = self.board[a]
return True
# 检查平局
if self.moves >= 9:
self.winner = "Draw"
return True
return False
def switch_player(self):
"""切换当前玩家"""
self.current_player = "O" if self.current_player == "X" else "X"
def play(self):
"""游戏主循环"""
print("欢迎来到井字棋游戏!")
self.print_board_nums()
while not self.check_winner():
try:
position = int(input(f"玩家 {self.current_player} 的回合,请输入位置 (1-9): "))
if position < 1 or position > 9:
print("请输入1-9之间的数字!")
continue
if self.make_move(position):
self.print_board()
if not self.check_winner():
self.switch_player()
else:
print("该位置已被占用,请选择其他位置!")
except ValueError:
print("请输入有效的数字!")
# 显示最终结果
if self.winner == "Draw":
print("\n游戏结束,平局!")
else:
print(f"\n恭喜玩家 {self.winner} 获胜!")
if __name__ == "__main__":
game = TicTacToe()
game.play()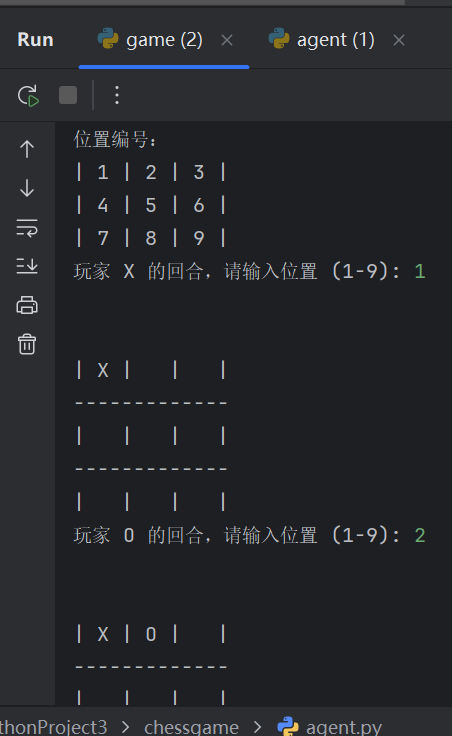
两个AI_player对战训练模型
两个AI对弈
game.py
class TicTacToe:
def __init__(self):
self.board = [" " for _ in range(9)] # 使用列表存储棋盘状态
self.current_player = "X" # 当前玩家
self.winner = None # 胜利者
self.moves = 0 # 总步数计数器
def print_board(self):
"""打印当前棋盘状态"""
print("\n")
for i in range(3):
row = self.board[i * 3: (i + 1) * 3]
print("| " + " | ".join(row) + " |")
if i < 2:
print("-------------")
@staticmethod
def print_board_nums():
"""显示位置编号示意图"""
print("\n位置编号:")
number_board = [[str(i + 1) for i in range(j * 3, (j + 1) * 3)] for j in range(3)]
for row in number_board:
print("| " + " | ".join(row) + " |")
def make_move(self, position):
"""处理玩家移动"""
if self.board[position] == " ":
self.board[position] = self.current_player
self.moves += 1
return True
return False
def check_winner(self):
"""检查游戏是否结束"""
# 检查所有可能的获胜组合
win_combinations = [
[0, 1, 2], [3, 4, 5], [6, 7, 8], # 横向
[0, 3, 6], [1, 4, 7], [2, 5, 8], # 纵向
[0, 4, 8], [2, 4, 6] # 对角线
]
for combo in win_combinations:
a, b, c = combo
if self.board[a] == self.board[b] == self.board[c] != " ":
self.winner = self.board[a]
return True
# 检查平局
if self.moves >= 9:
self.winner = "Draw"
return True
return False
def switch_player(self):
"""切换当前玩家"""
self.current_player = "O" if self.current_player == "X" else "X"
def play(self,position):
self.print_board_nums()
if position < 1 or position > 9:
print("请输入1-9之间的数字!")
if self.make_move(position-1):
self.print_board()
if not self.check_winner():
self.switch_player()
else:
print("该位置已被占用,请选择其他位置!")
model_player1.py
import torch.optim as optim
import torch.nn as nn
import os
import random
import numpy as np
from collections import deque
import torch
class Net1(nn.Module):
def __init__(self, input_size, hidden_size, output_size):
super().__init__()
self.net = nn.Sequential(
nn.Linear(input_size, hidden_size),
nn.ReLU(),
nn.Linear(hidden_size, output_size)
)
def forward(self, x):
return self.net(x)
def save_model(self, file_name='player1.pth'):
model_folder_path = './model'
if not os.path.exists(model_folder_path):
os.mkdir(model_folder_path)
file_name = os.path.join(model_folder_path, file_name)
torch.save(self.state_dict(), file_name)
class Agent1:
def __init__(self, input_size=9, hidden_size=128, output_size=9):
# 神经网络组件
self.model = Net1(input_size, hidden_size, output_size)
self.target_model = Net1(input_size, hidden_size, output_size)
self.optimizer = optim.Adam(self.model.parameters(), lr=0.001)
self.loss_fn = nn.MSELoss()
# 强化学习参数
self.gamma = 0.95 # 折扣因子
self.epsilon = 1.0 # 初始探索率
self.epsilon_min = 0.01 # 最小探索率
self.epsilon_decay = 0.995 # 探索率衰减
self.batch_size = 64 # 训练批次大小
self.memory = deque(maxlen=10000) # 经验回放池
# 同步目标网络
self.update_target_model()
def update_target_model(self):
"""同步目标网络参数"""
self.target_model.load_state_dict(self.model.state_dict())
def get_state(self, game):
"""将游戏状态转换为神经网络输入"""
# 将棋盘状态转换为数值:X=1, O=-1, 空=0
print(game.board)
return torch.FloatTensor([1 if c == 'X' else -1 if c == 'O' else 0 for c in game.board])
def choose_action(self, state, available_actions):
"""使用ε-greedy策略选择动作"""
if np.random.rand() <= self.epsilon:
# 随机探索可用动作
return random.choice(available_actions)
else:
# 使用模型预测最佳动作
with torch.no_grad():
state_tensor = state.unsqueeze(0)
q_values = self.model(state_tensor)
# 过滤无效动作
q_values = q_values.squeeze().numpy()
available_actions = [i - 1 for i in available_actions]
valid_q = {i + 1: q_values[i] for i in available_actions}
print(valid_q)
return max(valid_q, key=valid_q.get)
def remember(self, state, action, reward, next_state, done):
"""存储经验到回放池"""
self.memory.append((state, action, reward, next_state, done))
def replay_experience(self):
"""经验回放训练"""
if len(self.memory) < self.batch_size:
return
# 随机采样批次
minibatch = random.sample(self.memory, self.batch_size)
states, targets = [], []
for state, action, reward, next_state, done in minibatch:
target = reward
if not done:
# 计算目标Q值
with torch.no_grad():
next_q = self.target_model(next_state.unsqueeze(0)).max().item()
target += self.gamma * next_q
# 更新当前动作的Q值
current_q = self.model(state.unsqueeze(0)).squeeze()
current_q[action] = target
states.append(state)
targets.append(current_q)
# 批量训练
self.optimizer.zero_grad()
states = torch.stack(states)
targets = torch.stack(targets)
predictions = self.model(states)
loss = self.loss_fn(predictions, targets)
loss.backward()
self.optimizer.step()
# 衰减探索率
if self.epsilon > self.epsilon_min:
self.epsilon *= self.epsilon_decaymodel_player2.py
import torch.optim as optim
import torch.nn as nn
import os
import random
import numpy as np
from collections import deque
import torch
class Net2(nn.Module):
def __init__(self, input_size, hidden_size, output_size):
super().__init__()
self.net = nn.Sequential(
nn.Linear(input_size, hidden_size),
nn.ReLU(),
nn.Linear(hidden_size, output_size)
)
def forward(self, x):
return self.net(x)
def save_model(self, file_name='player2.pth'):
model_folder_path = './model'
if not os.path.exists(model_folder_path):
os.mkdir(model_folder_path)
file_name = os.path.join(model_folder_path, file_name)
torch.save(self.state_dict(), file_name)
class Agent2:
def __init__(self, input_size=9, hidden_size=16, output_size=9):
# 神经网络组件
self.model = Net2(input_size, hidden_size, output_size)
self.target_model = Net2(input_size, hidden_size, output_size)
self.optimizer = optim.Adam(self.model.parameters(), lr=0.001)
self.loss_fn = nn.MSELoss()
# 强化学习参数
self.gamma = 0.95 # 折扣因子
self.epsilon = 1.0 # 初始探索率
self.epsilon_min = 0.01 # 最小探索率
self.epsilon_decay = 0.995 # 探索率衰减
self.batch_size = 64 # 训练批次大小
self.memory = deque(maxlen=10000) # 经验回放池
# 同步目标网络
self.update_target_model()
def update_target_model(self):
"""同步目标网络参数"""
self.target_model.load_state_dict(self.model.state_dict())
def get_state(self, game):
"""将游戏状态转换为神经网络输入"""
# 将棋盘状态转换为数值:X=1, O=-1, 空=0
return torch.FloatTensor([1 if c == 'X' else -1 if c == 'O' else 0 for c in game.board])
def choose_action(self, state, available_actions):
"""使用ε-greedy策略选择动作"""
if np.random.rand() <= self.epsilon:
# 随机探索可用动作
return random.choice(available_actions)
else:
# 使用模型预测最佳动作
with torch.no_grad():
state_tensor = state.unsqueeze(0)
q_values = self.model(state_tensor)
# 过滤无效动作
q_values = q_values.squeeze().numpy()
available_actions = [i - 1 for i in available_actions]
valid_q = {i + 1: q_values[i] for i in available_actions}
print(valid_q)
return max(valid_q, key=valid_q.get)
def remember(self, state, action, reward, next_state, done):
"""存储经验到回放池"""
self.memory.append((state, action, reward, next_state, done))
def replay_experience(self):
"""经验回放训练"""
if len(self.memory) < self.batch_size:
return
# 随机采样批次
minibatch = random.sample(self.memory, self.batch_size)
states, targets = [], []
for state, action, reward, next_state, done in minibatch:
target = reward
if not done:
# 计算目标Q值
with torch.no_grad():
next_q = self.target_model(next_state.unsqueeze(0)).max().item()
target += self.gamma * next_q
# 更新当前动作的Q值
current_q = self.model(state.unsqueeze(0)).squeeze()
current_q[action] = target
states.append(state)
targets.append(current_q)
# 批量训练
self.optimizer.zero_grad()
states = torch.stack(states)
targets = torch.stack(targets)
predictions = self.model(states)
loss = self.loss_fn(predictions, targets)
loss.backward()
self.optimizer.step()
# 衰减探索率
if self.epsilon > self.epsilon_min:
self.epsilon *= self.epsilon_decayagent.py
from chessgame.game import TicTacToe
from chessgame.model_player1 import Agent1
from chessgame.model_player2 import Agent2
class Training:
def __init__(self):
self.agent1 = Agent1()
self.agent2 = Agent2()
self.env = TicTacToe() # 使用之前定义的井字棋环境
self.ai1Win=0
self.ai2Win=0
def train(self, episodes=1000):
for episode in range(episodes):
print("欢迎来到井字棋游戏!"+str(episode))
cur=1
self.env = TicTacToe() # 重置环境
done = False
total_reward1 = 0
total_reward2 = 0
while not done:
print("第"+str(cur)+"回合")
cur+=1
if not done:
# Ai1
# 获取可用动作
state1 = self.agent1.get_state(self.env)
# print("state1:", state1)
available_actions1 = [i+1 for i, val in enumerate(self.env.board) if val == " "]
print("Ai1可选择" + str(available_actions1))
if available_actions1 != []:
# AI选择动作
action1 = self.agent1.choose_action(state1, available_actions1)
print("Ai1位置:" + str(action1))
# 执行动作
prev_state1 = state1
next_state1 = self.agent1.get_state(self.env)
self.env.play(action1)
# 计算奖励
reward1 = 0
if self.env.check_winner():
if self.env.winner == "X": # 假设AI始终是X玩家
print("Ai1获胜")
done = True
reward1 = 1
self.ai1Win+=1
elif self.env.winner == "O":
print("Ai2获胜")
done = True
reward1 = -1
self.ai2Win+=1
else:
reward1 = 0.1 if self.env.moves % 2 == 0 else -0.1 # 鼓励主动进攻
else:
reward1=0
reward2=0
done=True
if not done:
# Ai2
# 获取可用动作
state2 = self.agent1.get_state(self.env)
# print("state2:", state2)
available_actions2 = [i+1 for i, val in enumerate(self.env.board) if val == " "]
print("Ai2可选择" + str(available_actions2))
if available_actions2 != []:
# AI选择动作
action2 = self.agent2.choose_action(state2, available_actions2)
print("Ai2位置:"+str(action2))
# 执行动作
prev_state2 = state2
next_state2 = self.agent2.get_state(self.env)
self.env.play(action2)
# 计算奖励
reward2 = 0
if self.env.check_winner():
if self.env.winner == "O": # 假设AI始终是X玩家
print("Ai2获胜")
done = True
reward2 = 1
self.ai2Win+=1
elif self.env.winner == "X":
print("Ai1获胜")
done = True
reward2 = -1
self.ai1Win += 1
else:
reward2 = 0.1 if self.env.moves % 2 == 0 else -0.1 # 鼓励主动进攻
else:
reward1 = 0
reward2 = 0
done = True
# Ai1
# 存储经验
done = self.env.winner is not None
self.agent1.remember(prev_state1, action1 - 1, reward1, next_state1, done)
# 训练模型
self.agent1.replay_experience()
total_reward1 += reward1
state1 = next_state1
# Ai2
# 存储经验
done = self.env.winner is not None
self.agent2.remember(prev_state2, action2 - 1, reward2, next_state2, done)
# 训练模型
self.agent2.replay_experience()
total_reward2 += reward2
state2 = next_state2
# 定期更新目标网络
if episode % 10 == 0:
self.agent1.update_target_model()
self.agent2.update_target_model()
print(episode)
print("Ai1获胜次数:"+str(self.ai1Win))
print("Ai2获胜次数:" + str(self.ai2Win))
# 定期保存模型
if episode % 100 == 0:
self.agent1.model.save_model()
print(f"Agent1:Episode: {episode}, Reward: {total_reward1:.2f}, Epsilon: {self.agent1.epsilon:.2f}")
self.agent2.model.save_model()
print(f"Agent2:Episode: {episode}, Reward: {total_reward2:.2f}, Epsilon: {self.agent1.epsilon:.2f}")
if __name__ == "__main__":
trainer = Training()
trainer.train(episodes=1000)
解析
训练90次
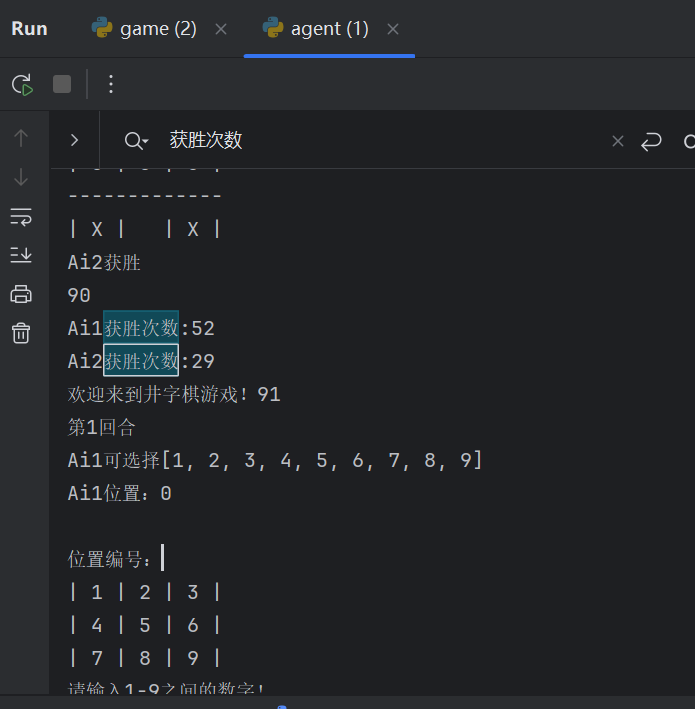
ai1获胜次数大于ai2获胜次数原因:
Ai1
def __init__(self, input_size=9, hidden_size=128, output_size=9):
Ai2
def __init__(self, input_size=9, hidden_size=16, output_size=9):
Ai1神经元更多,能更好地学习
读取模型Ai与人对战
peopleVsAi.py
import torch
from chessgame.game import TicTacToe
from chessgame.model_player1 import Agent1, Net1
from chessgame.model_player2 import Agent2
class Playing:
def __init__(self):
self.agent1 = Agent1()
self.agent2 = Agent2()
self.env = TicTacToe() # 使用之前定义的井字棋环境
self.aiWin=0
self.peopleWin=0
def play(self):
# Ai先走!
print("欢迎来到井字棋游戏!")
model = Net1(9,128,9)
model.load_state_dict(torch.load('./model/player1.pth'))
model.eval() # 将模型设置为评估模式
cur=1
self.env = TicTacToe() # 重置环境
done = False
while not done:
print("第"+str(cur)+"回合")
cur+=1
if not done:
# Ai1
# 获取可用动作
state1 = self.agent1.get_state(self.env)
# print("state1:", state1)
available_actions1 = [i+1 for i, val in enumerate(self.env.board) if val == " "]
print("Ai1可选择" + str(available_actions1))
if available_actions1 != []:
# 使用模型预测最佳动作
with torch.no_grad():
state_tensor = state1.unsqueeze(0)
q_values = model(state_tensor)
# 过滤无效动作
q_values = q_values.squeeze().numpy()
available_actions1 = [i - 1 for i in available_actions1]
valid_q = {i + 1: q_values[i] for i in available_actions1}
action1 = max(valid_q, key=valid_q.get)
print("Ai1位置:" + str(action1))
# 执行动作
self.env.play(action1)
if self.env.check_winner():
if self.env.winner == "X": # 假设AI始终是X玩家
print("Ai获胜")
done = True
self.aiWin+=1
elif self.env.winner == "O":
print("People获胜")
done = True
self.peopleWin+=1
else:
done=True
if not done:
# People
available_actions2 = [i+1 for i, val in enumerate(self.env.board) if val == " "]
print("People可选择" + str(available_actions2))
if available_actions2 != []:
# AI选择动作
action2 = int(input("选择位置"))
print("Ai2位置:"+str(action2))
# 执行动作
self.env.play(action2)
# 计算奖励
if self.env.check_winner():
if self.env.winner == "O":
print("People获胜")
done = True
self.peopleWin+=1
elif self.env.winner == "X":
print("Ai获胜")
done = True
self.aiWin += 1
else:
done = True
if __name__ == "__main__":
player = Playing()
player.play()
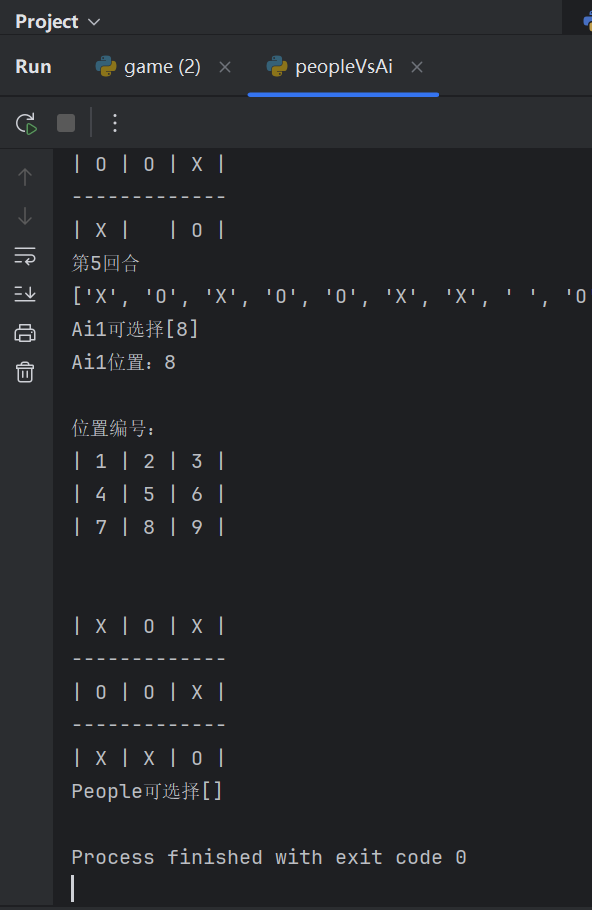
运行结果

















 1443
1443

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









