



一、 什么是FastGPT?
FastGPT,是一个基于 LLM 大语言模型的知识库问答系统,提供开箱即用的数据处理、模型调用等能力。
同时可以通过 Flow 可视化进行工作流编排,从而实现复杂的问答场景!
二、 FastGPT知识库的部署架构和工作流程
首先当我们录入知识库时,FastGPT会用集成的向量模型对知识库中的文本进行分割,得到文本块。
利用embedding模型给出文本块的embedding,并利用向量数据库进行保存。
然后当用户给大模型输入问题后,问题输入与知识库通过大预言模型根据用户输入信息的embedding, 通过向量数据库检索得到最相关的文本片段,将提示词模板与用户提交问题及历史消息合并输入大语言模型。大语言模型进行结果组装返回给用户回答。

部署FastGPT需要部署的环境。
- Docker DeskTop
- OneAPI
- Ollama + LLM大模型以及 向量模型
关于Docker DeskTop怎么部署参看Windows系统安装Docker容器博客
什么是OneApi?
One API 是一个 OpenAI 接口管理 & 分发系统,可以通过标准的 OpenAI API 格式访问所有的大模型,开箱即用。
默认情况下,FastGPT 只配置了 GPT 的模型,如果你需要接入其他模型,需要进行一些额外配置。FastGPT 可以通过接入 One API 来实现对不同大模型的支持。
OneApi中渠道和令牌的关系及OneApi及FastGPT的工作流程
**渠道:**
OneApi 中一个渠道对应一个 Api Key,这个 Api Key 可以是GPT、微软、ChatGLM、文心一言的。一个Api Key通常可以调用同一个厂商的多个模型。
One API 会根据请求传入的模型来决定使用哪一个Key,如果一个模型对应了多个Key,则会随机调用。
**令牌:** Api Key
访问 One API 所需的凭证,只需要这1个凭证即可访问One API上配置的模型。因此FastGPT中,只需要配置One API的baseurl和令牌即可。
**大致工作流程** Api Key
客户端请求 One API
根据请求中的 model 参数,匹配对应的渠道(根据渠道里的模型进行匹配,必须完全一致)。如果匹配到多个渠道,则随机选择一个(同优先级)。
One API 向真正的地址发出请求。
One API 将结果返回给客户端。
常用的中文向量模型
mofanke/acge_text_embedding
shaw/dmeta-embedding-zh
m3e
bge-m3
三、安装FastGPT和OneAPI
通过GitHub下载FastGPT的Docker-compose 文件https://github.com/labring/FastGPT/blob/main/files/docker/docker-compose/docker-compose
和OneAPI的Config.json文件
https://github.com/labring/FastGPT/blob/main/projects/app/data/config.json
将两个文件放置到相同目录下,然后在文件浏览器窗口该目录下输入cmd命令,执行
docker-compose up -d
可以看到docker自动拉取镜像并安装执行,等到全部安装结束即可。

全部安装结束,我们即可打开本地http://ip:3001端口即是OneAPI的登录入口,默认用户名 root 密码123456。本地http://ip:3000即是FastGPT的登录入口,默认用户名root 密码1234。

四、下载并运行大模型和向量模型。
第一种方式:通过Ollama进行快速下载和运行:
登录ollama官网搜索下载大模型和向量模型,这步非常简单,直接命令行运行Ollama run+模型名称即可。ollama支撑常见的多种模型下载和运行。
譬如,大语言模型:llama3、qwen2、gema;
向量模型:mofanke/acge_text_embedding
shaw/dmeta-embedding-zh
bge-m3
以下是我已经下载并运行的模型。

第二种方式:通过其它方式进行下载和运行:
docker方式:
m3e
#GPU模式启动
docker run -d -p 6008:6008 --gpus all --name m3e --network fastgpt_fastgpt registry.cn-hangzhou.aliyuncs.com/fastgpt_docker/m3e-large-api
#CPU模式启动,并把m3e加载到fastgpt同一个网络
docker run -d -p 6008:6008 --name m3e --network fastgpt_fastgpt stawky/m3e-large-api
五、重新配置OneApi渠道以及修改Config.json文件并重启docker-compose。
config.json文件里面配置了示例的大模型名称和向量模型名称。我们根据本地的实际情况修改成自己的大模型名称和向量模型名称即可。
然后再相同的目录下Docker-compose down 将容器停止,再Docker-compose up -d 重启。
最后登录OneAPI平台配置渠道,若是ollama下载的大模型,则类型选择Ollama。
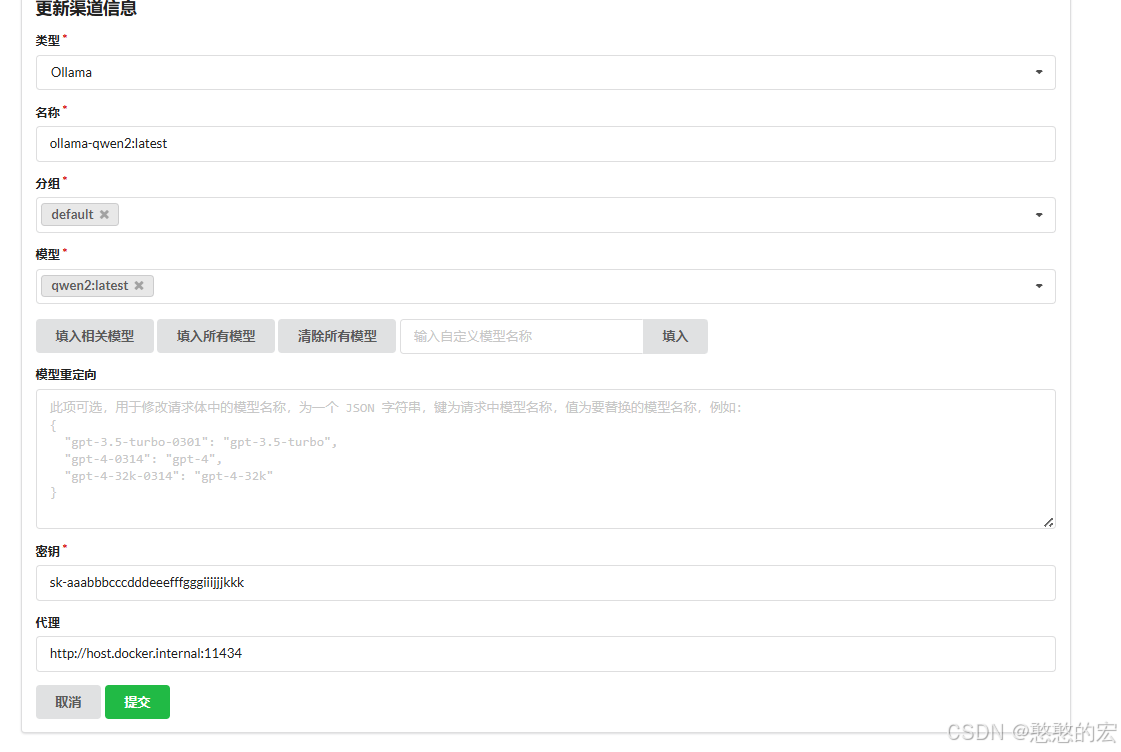
代理部分填入:http://host.docker.internal:11434
配置时的注意点:
1.注意最后代理填入Docker容器与本机Ollama通讯的地址。
2.向量模型在OneAPI渠道测试时会报400错误,直接略过即可。
3.config.json文件中配置的"model": 名称需要与OneAPI里面“模型”标签,以及ollama list里面的模型名称完全一致,并且不能有空格。
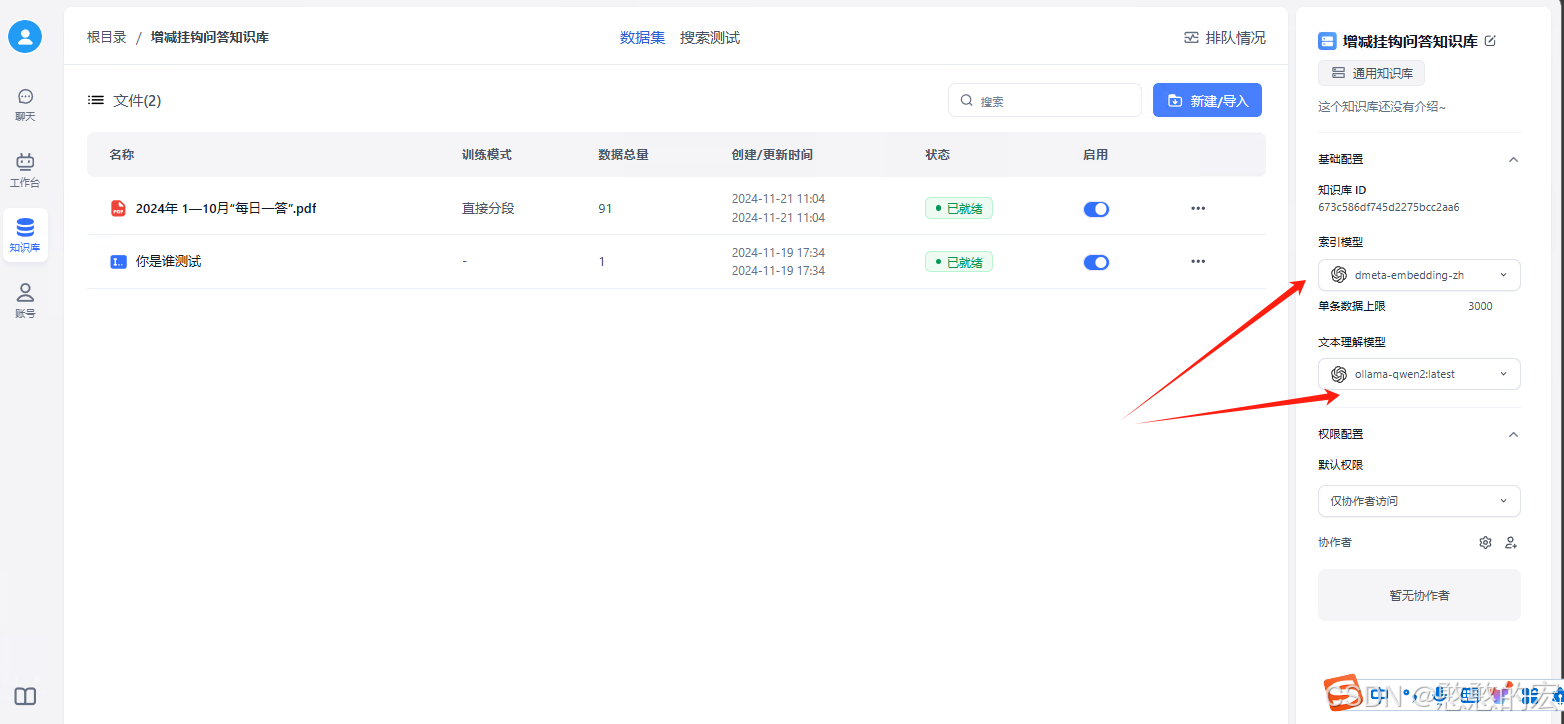
六、进行FastGPT应用建立和问答测试。
新建知识库,然后选中向量模型和LLM模型。点击测试对话即可开始对话。
七、最后附上config.json和fastgpt的docker-compose文件
// 已使用 json5 进行解析,会自动去掉注释,无需手动去除
{
"feConfigs": {
"lafEnv": "https://laf.dev" // laf环境。 https://laf.run (杭州阿里云) ,或者私有化的laf环境。如果使用 Laf openapi 功能,需要最新版的 laf 。
},
"systemEnv": {
"vectorMaxProcess": 15, // 向量处理线程数量
"qaMaxProcess": 15, // 问答拆分线程数量
"tokenWorkers": 50, // Token 计算线程保持数,会持续占用内存,不能设置太大。
"pgHNSWEfSearch": 100 // 向量搜索参数。越大,搜索越精确,但是速度越慢。设置为100,有99%+精度。
},
"llmModels": [
{
"model": "llama3.1:8b",
"name": "ollama-llama3.1:8b",
"avatar": "/imgs/model/openai.svg",
"maxContext": 125000,
"maxResponse": 16000,
"quoteMaxToken": 120000,
"maxTemperature": 1.2,
"charsPointsPrice": 0,
"censor": false,
"vision": false,
"datasetProcess": true,
"usedInClassify": true,
"usedInExtractFields": true,
"usedInToolCall": true,
"usedInQueryExtension": true,
"toolChoice": true,
"functionCall": true,
"customCQPrompt": "",
"customExtractPrompt": "",
"defaultSystemChatPrompt": "",
"defaultConfig": {}
},
{
"model": "qwen2:latest",
"name": "ollama-qwen2:latest",
"maxContext": 32000,
"avatar": "/imgs/model/openai.svg",
"maxResponse": 8000,
"quoteMaxToken": 20000,
"maxTemperature": 1.0,
"charsPointsPrice": 0,
"censor": false,
"vision": false,
"datasetProcess": true,
"usedInClassify": true,
"usedInExtractFields": true,
"usedInToolCall": true,
"usedInQueryExtension": true,
"toolChoice": true,
"functionCall": true,
"customCQPrompt": "",
"customExtractPrompt": "",
"defaultSystemChatPrompt": "",
"defaultConfig": {}
}
],
"vectorModels": [
{
"model": "shaw/dmeta-embedding-zh",
"name": "dmeta-embedding-zh",
"avatar": "/imgs/model/openai.svg",
"charsPointsPrice": 0,
"defaultToken": 512,
"maxToken": 3000,
"weight": 100,
"dbConfig": {},
"queryConfig": {}
},
{
"model": "mofanke/acge_text_embedding:latest",
"name": "mofanke/acge_text_embedding:latest",
"avatar": "/imgs/model/openai.svg",
"charsPointsPrice": 0,
"defaultToken": 512,
"maxToken": 3000,
"weight": 100,
"dbConfig": {},
"queryConfig": {}
},
{
"model": "bge-m3:latest",
"name": "bge-m3:latest",
"avatar": "/imgs/model/openai.svg",
"charsPointsPrice": 0,
"defaultToken": 512,
"maxToken": 3000,
"weight": 100,
"dbConfig": {},
"queryConfig": {}
},
{
"model": "m3e",
"name": "m3e",
"avatar": "/imgs/model/openai.svg",
"charsPointsPrice": 0,
"defaultToken": 512,
"maxToken": 3000,
"weight": 100,
"dbConfig": {},
"queryConfig": {}
}
],
"reRankModels": [],
"audioSpeechModels": [
{
"model": "tts-1",
"name": "OpenAI TTS1",
"charsPointsPrice": 0,
"voices": [
{ "label": "Alloy", "value": "alloy", "bufferId": "openai-Alloy" },
{ "label": "Echo", "value": "echo", "bufferId": "openai-Echo" },
{ "label": "Fable", "value": "fable", "bufferId": "openai-Fable" },
{ "label": "Onyx", "value": "onyx", "bufferId": "openai-Onyx" },
{ "label": "Nova", "value": "nova", "bufferId": "openai-Nova" },
{ "label": "Shimmer", "value": "shimmer", "bufferId": "openai-Shimmer" }
]
}
],
"whisperModel": {
"model": "whisper-1",
"name": "Whisper1",
"charsPointsPrice": 0
}
}
docker-compose文件修改的地方:


















 3171
3171

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









