 实例分割:Labelme标注数据转COCO格式数据集
实例分割:Labelme标注数据转COCO格式数据集




 本文介绍了如何将使用Labelme标注的多边形框数据转换为COCO格式的数据集,适用于实例分割任务。通过运行特定的Python脚本如labelme2coco.py和labelme2cocoGuan.py,将标注的JSON文件和图像整合到COCO标准的结构中,包括annotations和images文件夹。此外,文章还提到了安装pycocotools的注意事项以及转换过程中可能出现的问题和解决方案。
本文介绍了如何将使用Labelme标注的多边形框数据转换为COCO格式的数据集,适用于实例分割任务。通过运行特定的Python脚本如labelme2coco.py和labelme2cocoGuan.py,将标注的JSON文件和图像整合到COCO标准的结构中,包括annotations和images文件夹。此外,文章还提到了安装pycocotools的注意事项以及转换过程中可能出现的问题和解决方案。
这里说明一下:
Labelme标注数据时候是用的多边形框,关于标注,可以看前面的博客文章
下面制作的COCO数据集是用于实例分割的数据集。
COCO格式数据集的制作
1、labelme标注的数据转coco数据集
Anaconda Prompt里 F:\rockdata 下的目录运行指令:
这里需要注意是在activate labelme后,
python labelme2coco.py NoObeject
NoObeject是放json文件和图像的文件夹名字。
下载:labelme2coco.py 代码,运行,无需修改。
运行代码会生成一个文件,trainval.json

代码参考:
github.com/Tony607/labelme2coco

视频参考:
labelme转coco与多个coco文件的合并_哔哩哔哩_bilibili https://www.bilibili.com/video/BV1g44y147C9
https://www.bilibili.com/video/BV1g44y147C9
2、labelme转coco数据集
源代码运行后,train和val文件夹下为空,原因是:写入图像的路径可能不对,修改源代码后正常:
代码如下:
import os
import json
import numpy as np
import glob
import shutil
import cv2
from sklearn.model_selection import train_test_split
np.random.seed(41)
#rock1
#rock2
#rock3
#rock4
#rock5
#rock6
#rock7
#rock8
#rock9
#rock10
#rock11
#sand_wave1
#sand_wave2
#sand_wave3
#sand_wave4
#sand_wave5
#sand_wave6
#sand_wave7
#sand_wave8
#sand_wave9
#sand_wave10
#sand_wave11
# 0为背景
classname_to_id = {
"1": 1,
"2": 2,
}
#注意这里:yxf
#需要从1开始把对应的Label名字写入:这里根据自己的Lable名字修改
class Lableme2CoCo:
def __init__(self):
self.images = []
self.annotations = []
self.categories = []
self.img_id = 0
self.ann_id = 0
def save_coco_json(self, instance, save_path):
json.dump(instance, open(save_path, 'w', encoding='utf-8'), ensure_ascii=False, indent=1) # indent=2 更加美观显示
# 由json文件构建COCO
def to_coco(self, json_path_list):
self._init_categories()
for json_path in json_path_list:
obj = self.read_jsonfile(json_path)
self.images.append(self._image(obj, json_path))
shapes = obj['shapes']
for shape in shapes:
annotation = self._annotation(shape)
self.annotations.append(annotation)
self.ann_id += 1
self.img_id += 1
instance = {}
instance['info'] = 'spytensor created'
instance['license'] = ['license']
instance['images'] = self.images
instance['annotations'] = self.annotations
instance['categories'] = self.categories
return instance
# 构建类别
def _init_categories(self):
for k, v in classname_to_id.items():
category = {}
category['id'] = v
category['name'] = k
self.categories.append(category)
# 构建COCO的image字段
def _image(self, obj, path):
image = {}
from labelme import utils
img_x = utils.img_b64_to_arr(obj['imageData'])
h, w = img_x.shape[:-1]
image['height'] = h
image['width'] = w
image['id'] = self.img_id
image['file_name'] = os.path.basename(path).replace(".json", ".jpg")
return image
# 构建COCO的annotation字段
def _annotation(self, shape):
# print('shape', shape)
label = shape['label']
points = shape['points']
annotation = {}
annotation['id'] = self.ann_id
annotation['image_id'] = self.img_id
annotation['category_id'] = int(classname_to_id[label])
annotation['segmentation'] = [np.asarray(points).flatten().tolist()]
annotation['bbox'] = self._get_box(points)
annotation['iscrowd'] = 0
annotation['area'] = 1.0
return annotation
# 读取json文件,返回一个json对象
def read_jsonfile(self, path):
with open(path, "r", encoding='utf-8') as f:
return json.load(f)
# COCO的格式: [x1,y1,w,h] 对应COCO的bbox格式
def _get_box(self, points):
min_x = min_y = np.inf
max_x = max_y = 0
for x, y in points:
min_x = min(min_x, x)
min_y = min(min_y, y)
max_x = max(max_x, x)
max_y = max(max_y, y)
return [min_x, min_y, max_x - min_x, max_y - min_y]
if __name__ == '__main__':
#这里是原来作者的路径
#labelme_path = "../../../xianjin_data-3/"
#这里注意:yxf
#需要把labelme_path修改为自己放images和json文件的路径
labelme_path = "F:\\rockdata\\NoObeject\\"
#saved_coco_path = "../../../xianjin_data-3/"
saved_coco_path = "F:\\rockdata\\COCO\\"
#saved_coco_path = "./"
#要把saved_coco_path修改为自己放生成COCO的路径,这里会在我当前COCO的文件夹下建立生成coco文件夹。
print('reading...')
# 创建文件
if not os.path.exists("%scoco/annotations/" % saved_coco_path):
os.makedirs("%scoco/annotations/" % saved_coco_path)
if not os.path.exists("%scoco/images/train2017/" % saved_coco_path):
os.makedirs("%scoco/images/train2017" % saved_coco_path)
if not os.path.exists("%scoco/images/val2017/" % saved_coco_path):
os.makedirs("%scoco/images/val2017" % saved_coco_path)
# 获取images目录下所有的joson文件列表
print(labelme_path + "/*.json")
json_list_path = glob.glob(labelme_path + "/*.json")
print('json_list_path: ', len(json_list_path))
# 数据划分,这里没有区分val2017和tran2017目录,所有图片都放在images目录下
train_path, val_path = train_test_split(json_list_path, test_size=0.1, train_size=0.9)
#这里yxf:将训练集和验证集的比例是9:1,可以根据自己想要的比例修改。
print("train_n:", len(train_path), 'val_n:', len(val_path))
# 把训练集转化为COCO的json格式
l2c_train = Lableme2CoCo()
train_instance = l2c_train.to_coco(train_path)
l2c_train.save_coco_json(train_instance, '%scoco/annotations/instances_train2017.json' % saved_coco_path)
for file in train_path:
#shutil.copy(file.replace("json", "jpg"), "%scoco/images/train2017/" % saved_coco_path)
#print("这里测试一下file:"+file)
img_name = file.replace('json', 'png')
#print("这里测试一下img_name:" + img_name)
temp_img = cv2.imread(img_name)
#print(temp_img) 测试图像读取是否正确
try:
#这个这句是原来作者的代码,运行之后train文件夹下生成的是空的
#cv2.imwrite("{}coco/images/train2017/{}".format(saved_coco_path, img_name.replace('png', 'jpg')),temp_img)
#我自己放train图像的路径:F:\rockdata\COCO\coco\images\train2017
img_name_jpg=img_name.replace('png', 'jpg')
print("jpg测试:"+img_name_jpg)
filenames = img_name_jpg.split("\\")[-1]
print(filenames) #这里是将一个路径中的文件名字提取出来
cv2.imwrite("./COCO/coco/images/train2017/{}".format(filenames),temp_img)
#这句写入语句,是将 X.jpg 写入到指定路径./COCO/coco/images/train2017/X.jpg
except Exception as e:
print(e)
print('Wrong Image:', img_name )
continue
print(img_name + '-->', img_name.replace('png', 'jpg'))
#print("yxf"+img_name)
for file in val_path:
#shutil.copy(file.replace("json", "jpg"), "%scoco/images/val2017/" % saved_coco_path)
img_name = file.replace('json', 'png')
temp_img = cv2.imread(img_name)
try:
#cv2.imwrite("{}coco/images/val2017/{}".format(saved_coco_path, img_name.replace('png', 'jpg')), temp_img)
img_name_jpg = img_name.replace('png', 'jpg') #将png文件替换成jpg文件。
print("jpg测试:" + img_name_jpg)
filenames = img_name_jpg.split("\\")[-1]
print(filenames)
cv2.imwrite("./COCO/coco/images/val2017/{}".format(filenames), temp_img)
except Exception as e:
print(e)
print('Wrong Image:', img_name)
continue
print(img_name + '-->', img_name.replace('png', 'jpg'))
# 把验证集转化为COCO的json格式
l2c_val = Lableme2CoCo()
val_instance = l2c_val.to_coco(val_path)
l2c_val.save_coco_json(val_instance, '%scoco/annotations/instances_val2017.json' % saved_coco_path)在Anaconda Prompt运行:
python labelme2CoCoCo.py
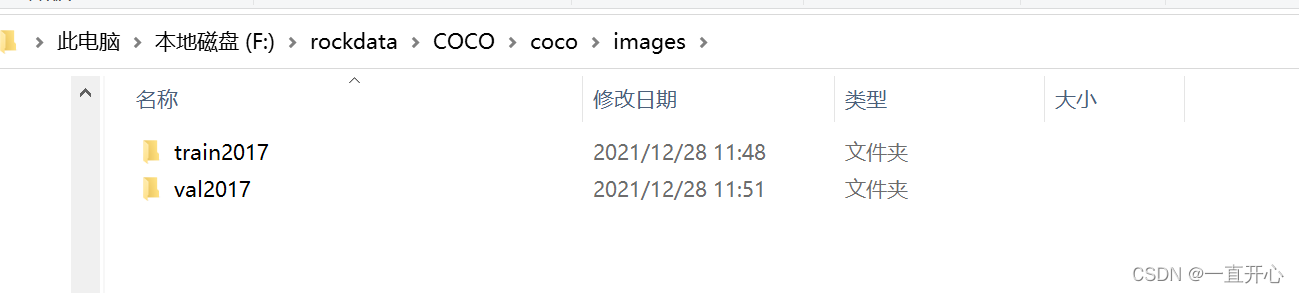
运行后,在我当前目录的COCO文件夹下,生成coco文件夹:
coco文件夹下有annotations文件夹和images文件夹,
annotations文件夹存放2个json文件。
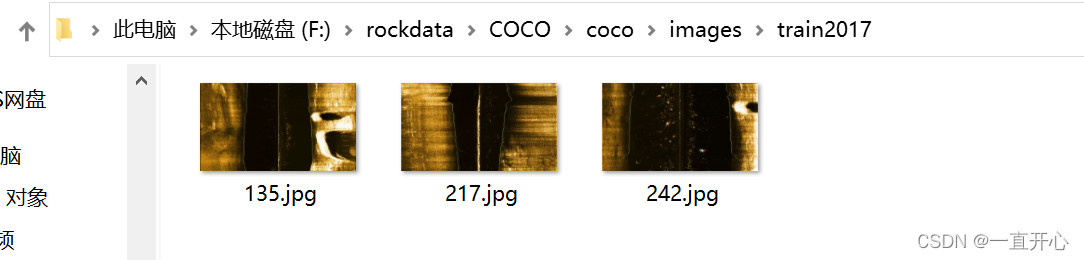
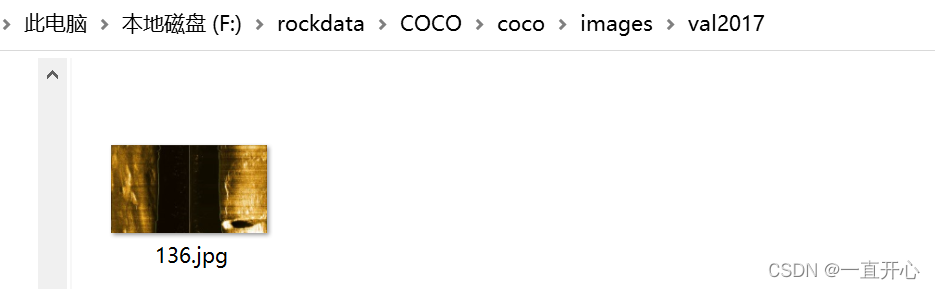
images文件夹存放train (存放:划分的用于训练的图像数据)和val (存放:划分的用于验证的图像数据) 两个文件夹。
这里是命令行运行结果截图:
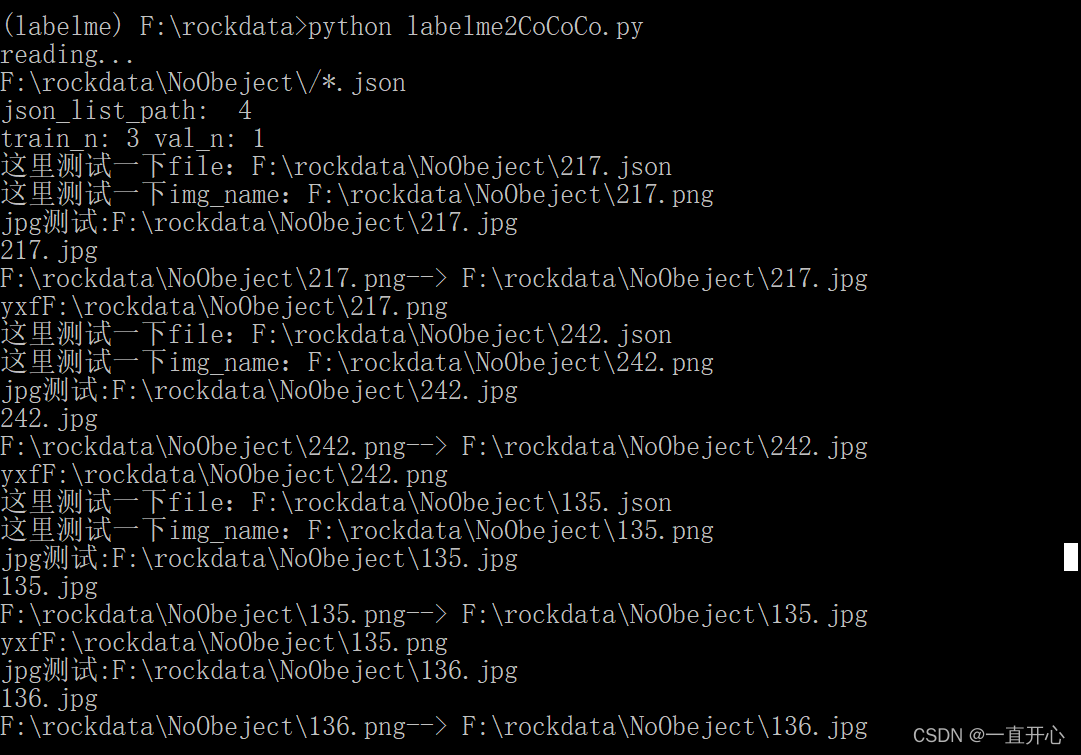


B站视频和代码:感谢UP主
代码:https://github.com/MrSupW/datasetapi
mmdetection系列教程合集_哔哩哔哩_bilibilihttps://www.bilibili.com/video/BV1jV411U7zb?p=6
3、来自Labelme的官网代码:
代码参考:labelme/examples/instance_segmentation at v3.11.2 · wkentaro/labelme (github.com)
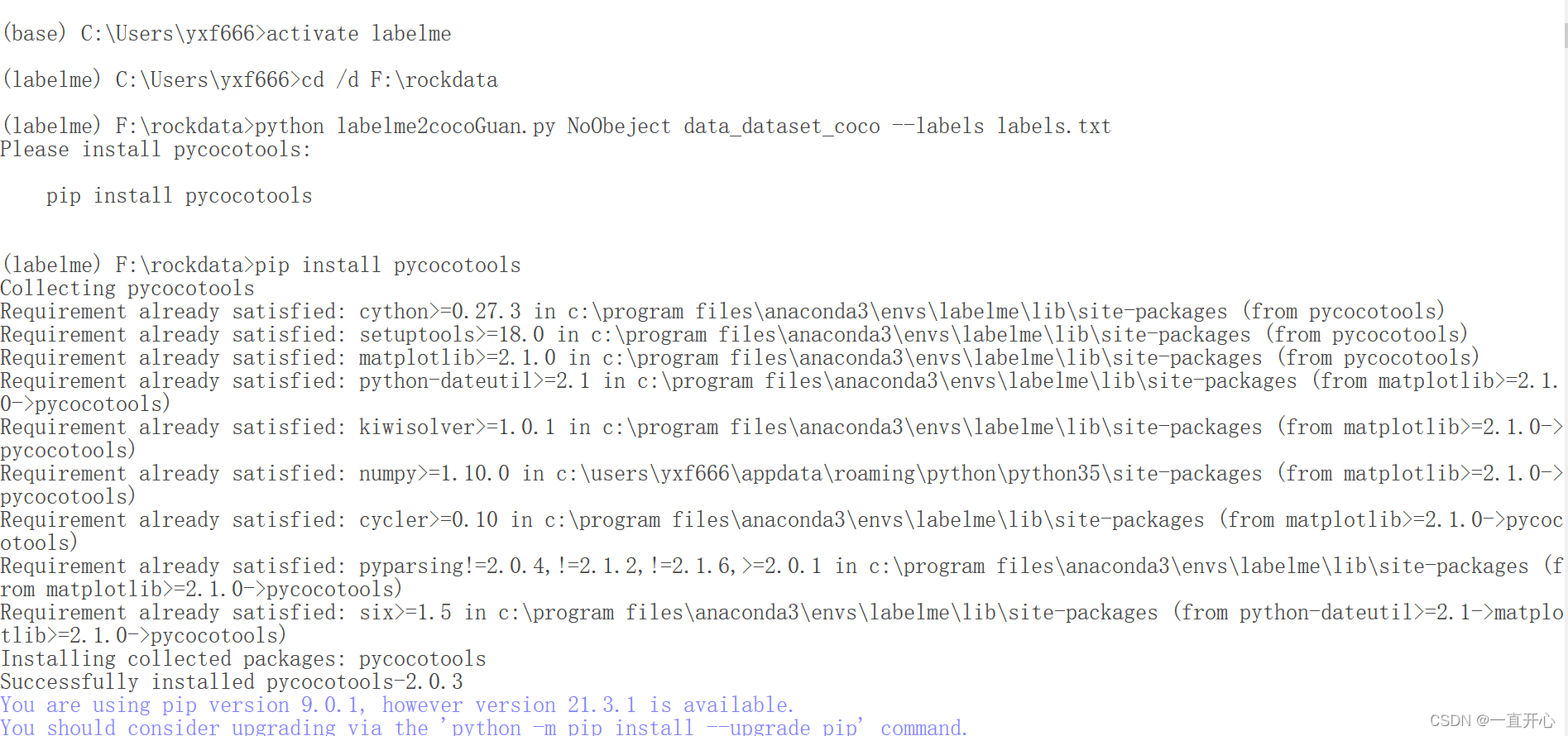
python labelme2cocoGuan.py NoObeject data_dataset_coco --labels labels.txt
这里:NoObeject 文件夹是存放原始图像文件和json文件。
生成的数据集coco放在data_dataset_coco文件夹。
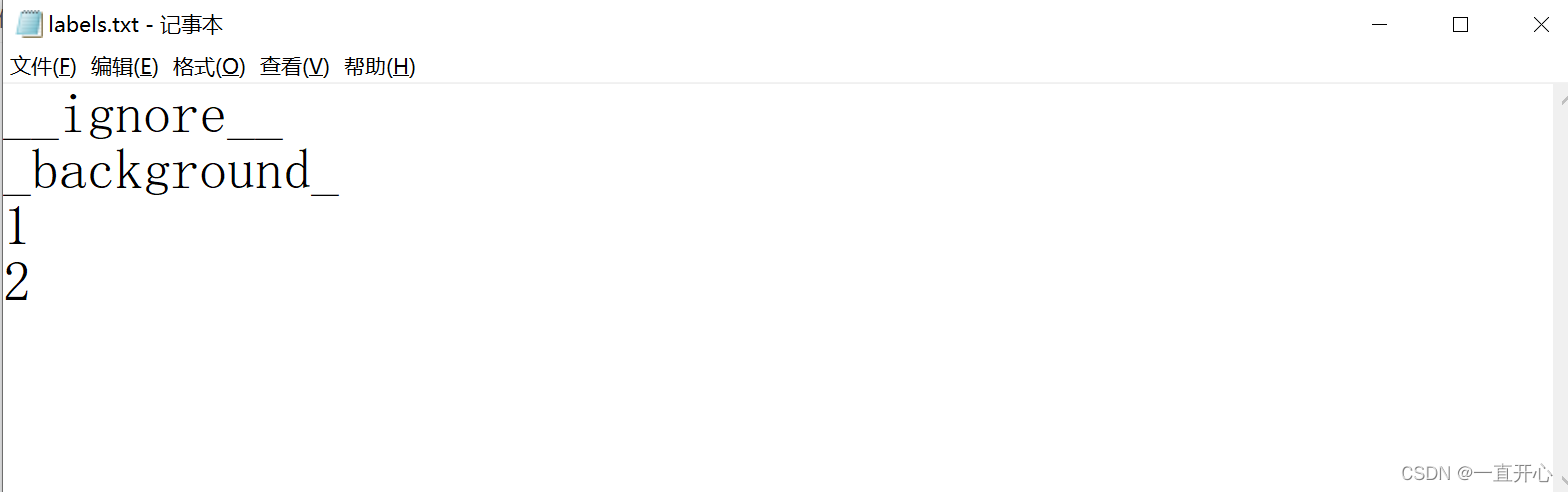
labels.txt 长这样:
命令行里运行结果如下:

运行后生成一个data_dataset_coco文件夹 ,
里面有一个JPEGImages文件夹(存放标注的那些原始图像)
和 annotations.json文件。

提示:这个代码运行前需要安装 pip install pycocotools
关于这个安装包的过程请看我之前的博客分享,专门讲解踩坑过程。
在Visual 2020里安装pip install pycocotools成功后, 在Anaconda Prompt这里仍需再安装一遍,才能成功运行上述代码。

















 3853
3853

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









