







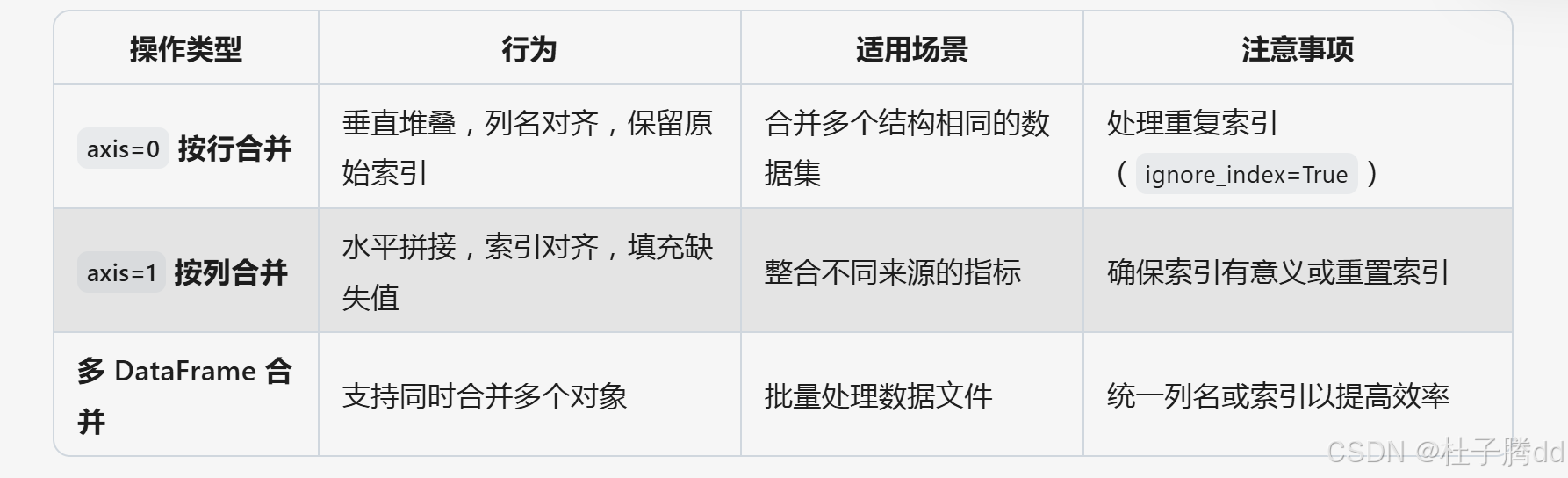
一 连接
1.pd.concat():多向拼接
沿指定轴(行或列)拼接多个 DataFrame,适用于简单堆叠数据。
concat 的一个既特别又有用的特性是,它可以接受两个以上的 DataFrame。可以将多个 CSV 文件中的数据合并成一个 DataFrame。
axis=0(默认):垂直拼接(行堆叠)。
axis=1:水平拼接(列合并)。
join='outer'(默认保留所有列)或 join='inner'(仅保留共有列)。
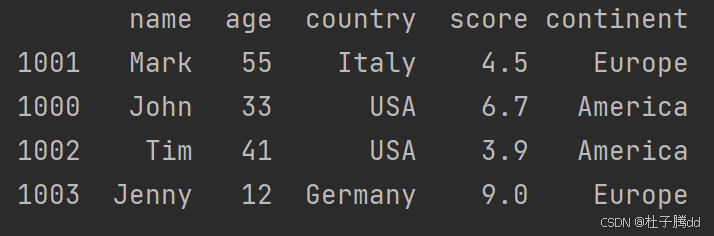
新增用户数据 more_users:
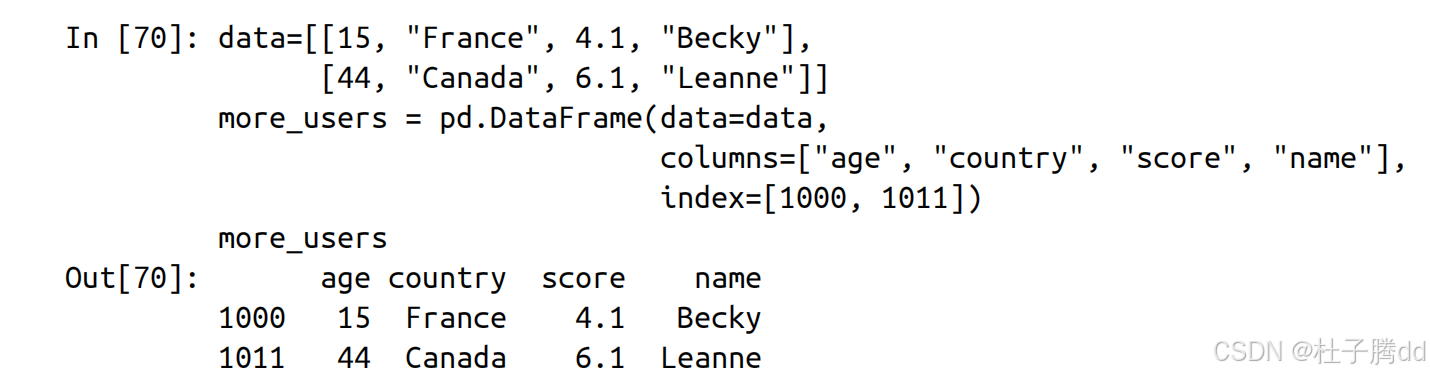

1.按行合并(axis=0)
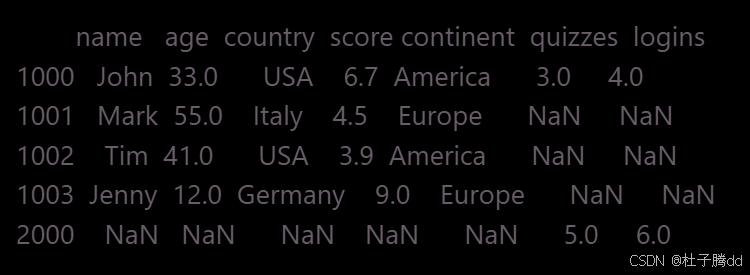
将 df 和 more_users 按行上下拼接。
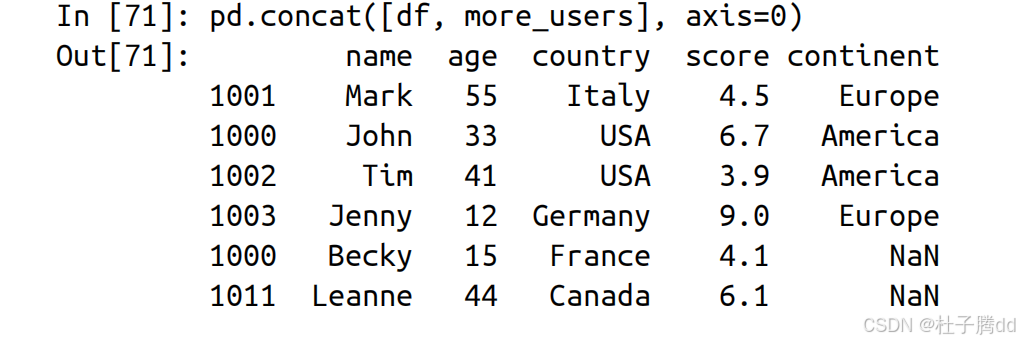
df 的列顺序为 name, age, country, score, continent,more_users 的列顺序为 age, country, score, name。concat 会自动按列名匹配,缺失的列(如 continent)用 NaN 填充。
保留原始索引,导致索引重复(例如 1000 在两个 DataFrame 中均存在)。


索引重复时可用 ignore_index=True 重置索引。
2.按列合并(axis=1)
将 df 和 more_categories 按列左右拼接。
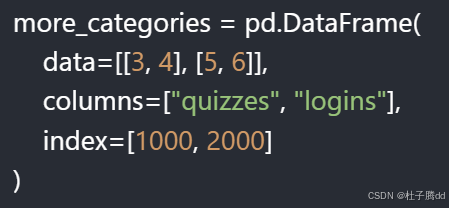
新增分类数据 more_categories:

操作:
![]()
基于索引对齐数据,不匹配的索引(如 1001, 1002, 1003 和 2000)用 NaN 填充。
默认行为是保留所有索引(join='outer')。
结果:仅索引交集部分有完整数据,其他位置填充 NaN。
3.多 DataFrame 合并

1.使用场景
按行合并:合并多个结构相同的 CSV 文件(如不同月份的数据)。
按列合并:整合来自不同来源的指标(如用户属性 + 行为数据 + 交易记录)。
2.常用参数
axis:合并方向(0 为行,1 为列)。
join:对齐方式('inner' 仅保留共有索引/列名,'outer' 保留全部,默认 'outer')。
ignore_index:忽略原始索引,生成新索引(避免重复)。
keys:为合并后的数据添加层级索引(标识来源)。

4.总结
2.df.join():索引关联合并
只能用于两个 DataFrame。
适用场景:索引代表唯一标识(如时间序列、地理位置)。
基于行索引横向合并 DataFrame(默认左连接),适合索引对齐的场景。
how:连接方式(left、right、inner、outer)。lsuffix/rsuffix:处理列名冲突。
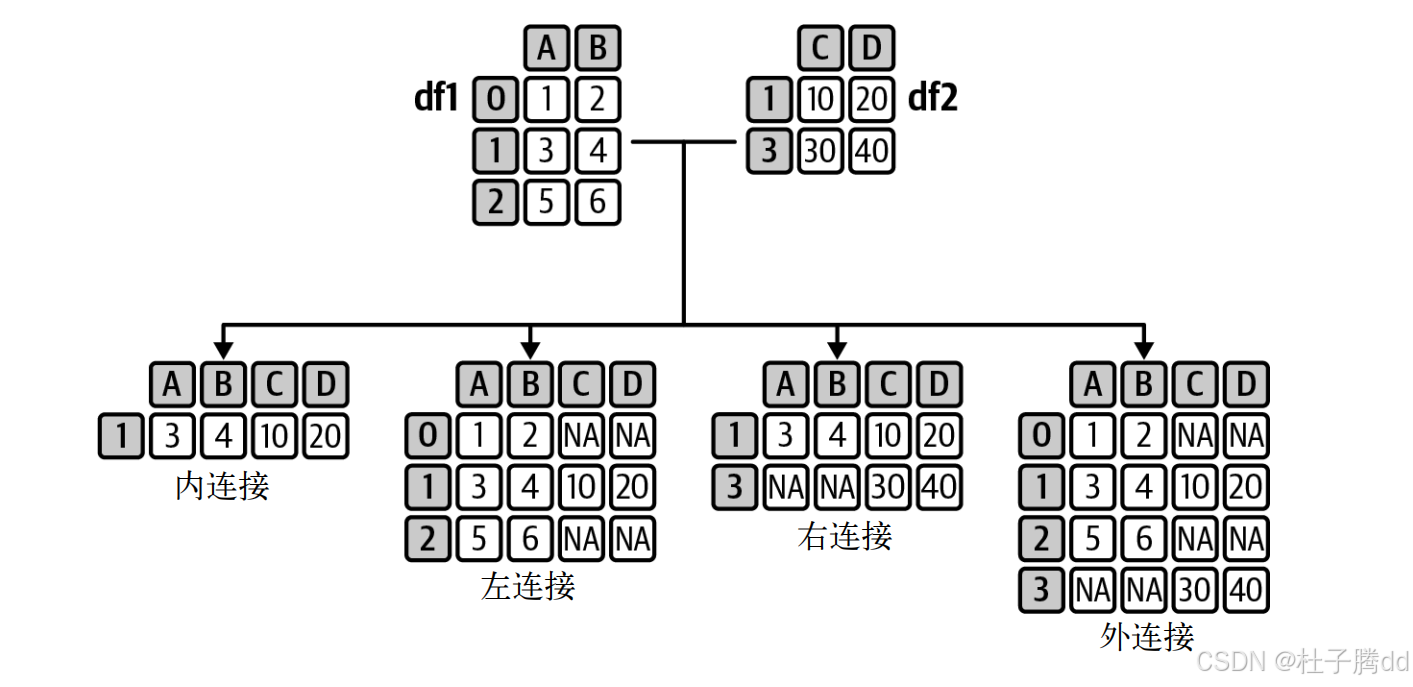
这两个 DataFrame 的列会连接在一起,而行的行为会借助集合论的原理来确定。

3.df.merge():列关联合并
想在不依赖于索引的情况下连接 DataFrame 中的一列或多列应该使用 merge 。
基于列值(类似 SQL JOIN)合并两个 DataFrame,支持多种连接方式(四种连接)。
on:指定关联列名(需存在于两表中)。这些列必须是两个 DataFrame 所共有的,它们会被用来和行进行匹配。
how:inner(默认,交集)、left(左表全保留)、right、outer(并集)。
suffixes=('_x', '_y'):处理重复列名。

4.总结

二 数据透视表
1.是什么
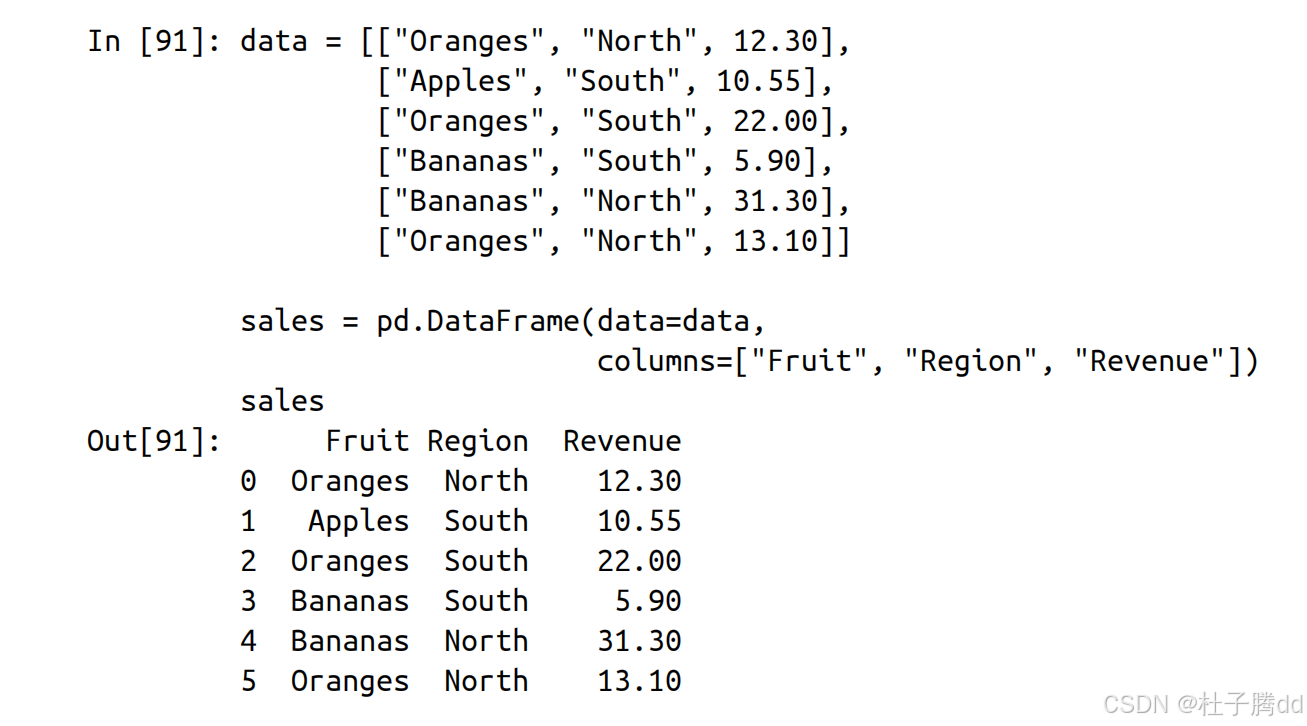
通过行、列分组键对目标值进行聚合统计(如求和、均值、计数),将原始数据转化为结构化的汇总表。
超市销售表中,原始数据包含日期、产品、销售额等字段。通过透视表,可快速得出“每月各产品类别的销售额总和”。
2.为什么有
原始数据多为逐条记录,难以直观总结规律。
支持行、列、值的自由组合,快速生成交叉统计结果。
若用groupby分组统计,需多次调整代码;而透视表通过参数配置即可实现矩阵化展示,例如同时统计“不同城市+月份的销售额均值与总和”。
3.如何使用
1.创建数据透视表
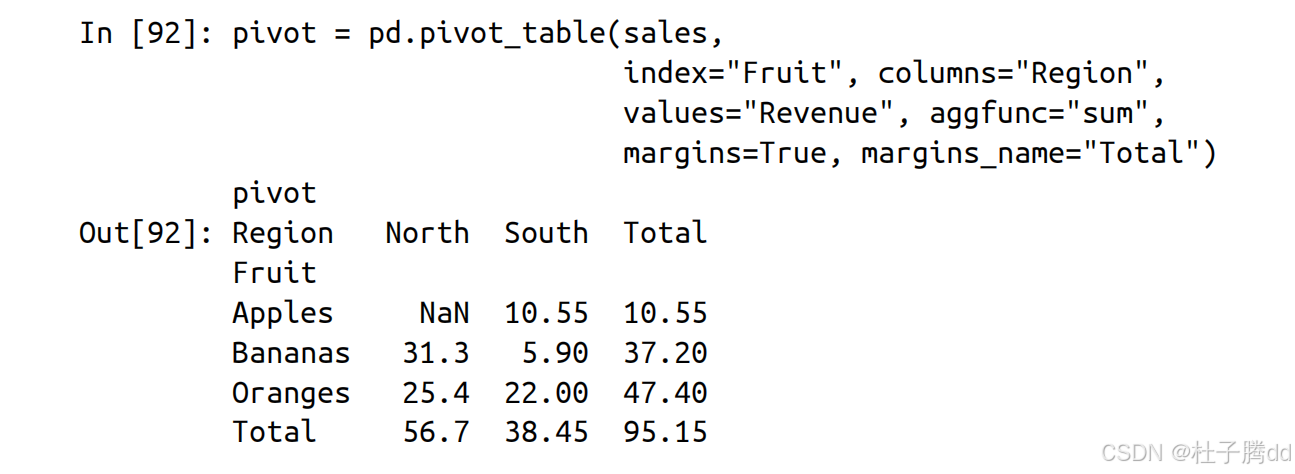
将 DataFrame 作为第一个参数传递给 pivot_table 函数。
index:行分组键(如“月份”“地区”)。
columns:列分组键(如“产品类别”)。
index 和 columns 分别指定了哪一列会成为数据透视表的行标签和列标签。
aggfunc:聚合函数(如 sum 求和、mean 求均值)。
values:要统计的数值列(如“销售额”“利润”)。values 会通过 aggfunc(以字符串或者 NumPy ufunc 的形式提供)被聚合到结果 DataFrame 中的数据部分。
fill_value:填充缺失值(如将空值替换为0)。

2.高级技巧
多级索引:index=["大区", "城市"] 实现嵌套分组。
差异化聚合:aggfunc={"销售额": np.sum, "订单量": np.mean} 针对不同列设置统计方式。
动态时间分析:结合pd.Grouper(key="日期", freq="M") 按月份自动分组。
4.透视数据
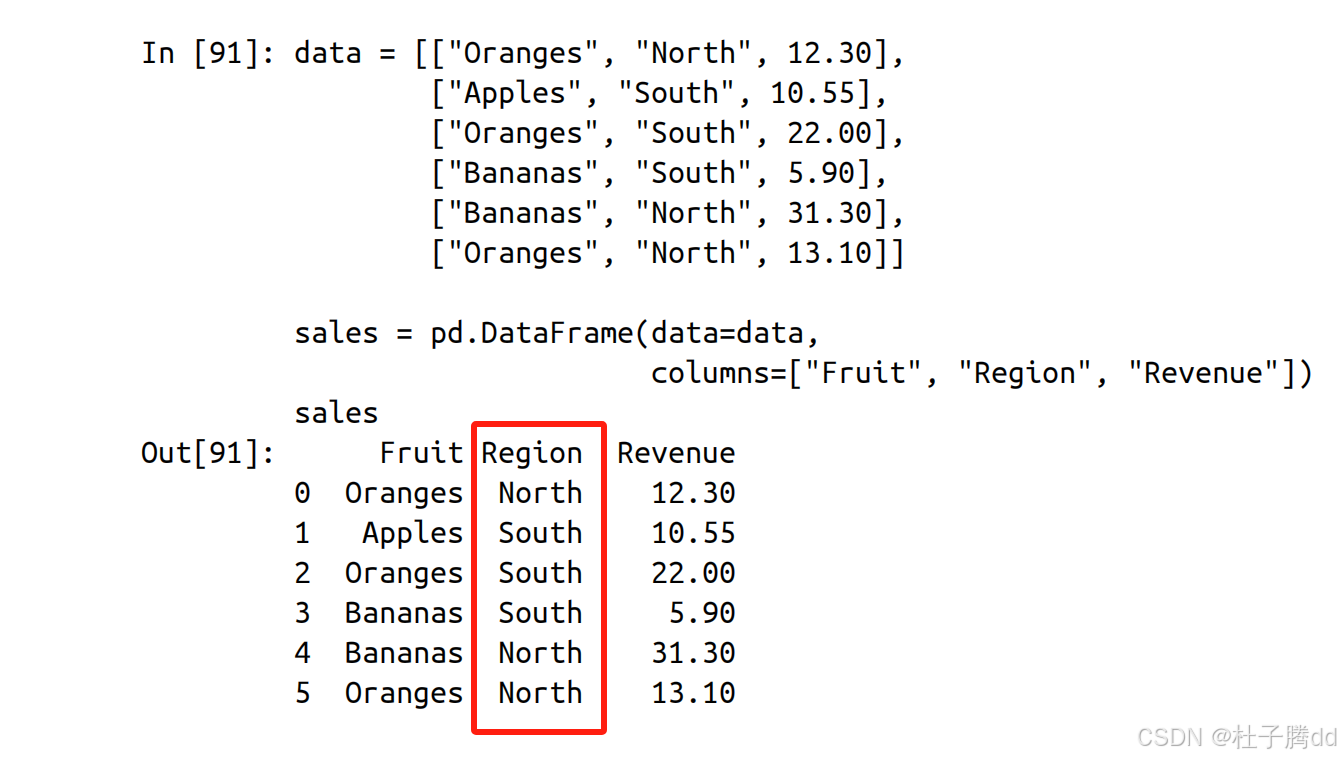
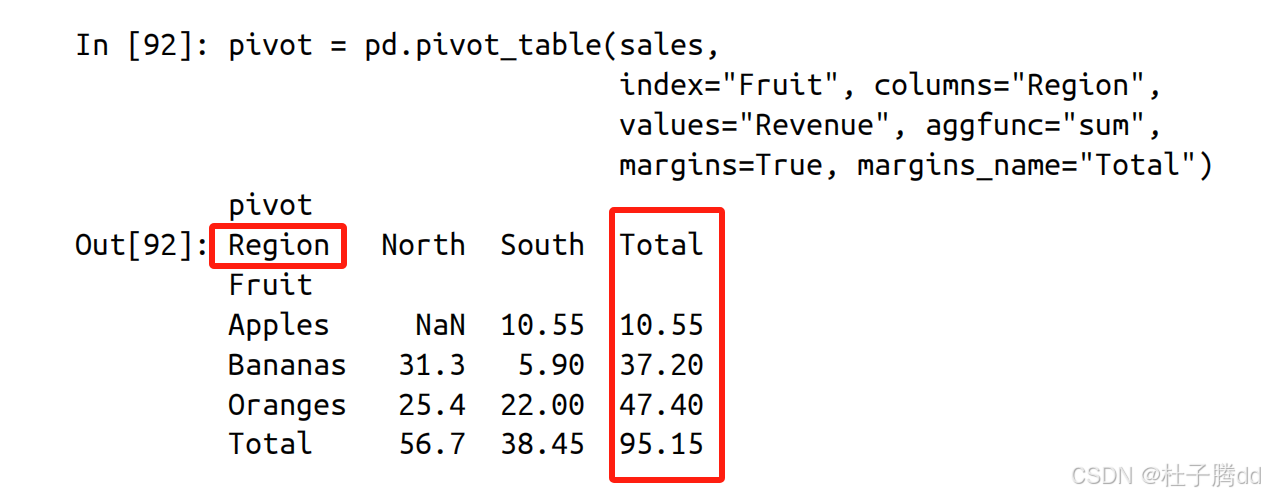
想将列标题转换成列的值:使用 melt 。
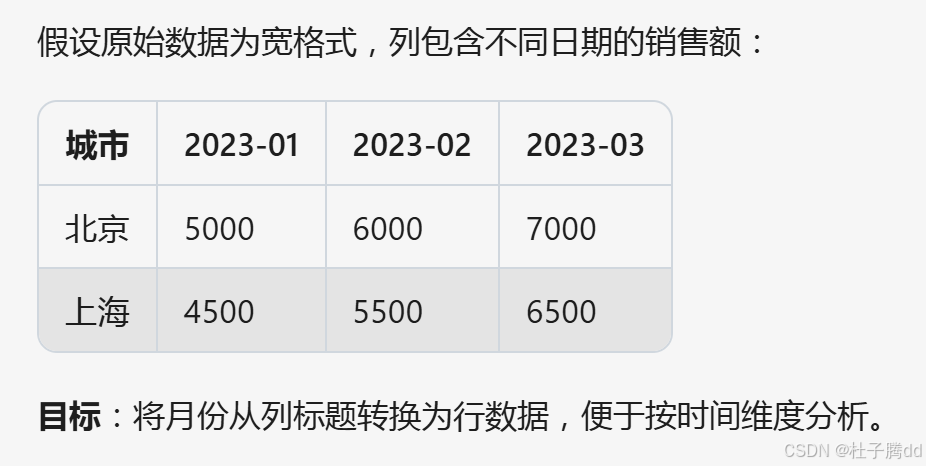

id_vars:保留不转换的列(作为标识列)。
value_vars:需要转换的列(默认转换除 id_vars 外的所有列) 。
var_name:新列名(存储原列标题的列,默认 variable) 。
value_name:新列名(存储原列值的列,默认 value) 。
5.和其他的联系
1.和Excel透视表

2.和groupby分组
groupby:生成一维聚合结果,适合简单统计。
透视表:生成二维矩阵,支持多层级行列交叉分析。

















 3402
3402

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









