







一 导入 Pandas
import pandas as pd
以下的导入excel表只是演示作用。
为了能在 Python 中使用 Excel 表格,首先要导入 pandas,然后使用 read_excel 函数通过这个 Excel 文件构造一个 DataFrame。
如果你在 Python 3.9 或者更高版本中使用 pd.read_excel 函数,那么一定要 确保 pandas 版本在 1.2 以上,否则会在读取 xlsx 文件时发生错误。

二 创建 DataFrame
对于打开的文件来说,创建了 DataFrame 要用 to_excel 写入文件的表格中。
1.字典创建
键为列名,值为列表或 Series。

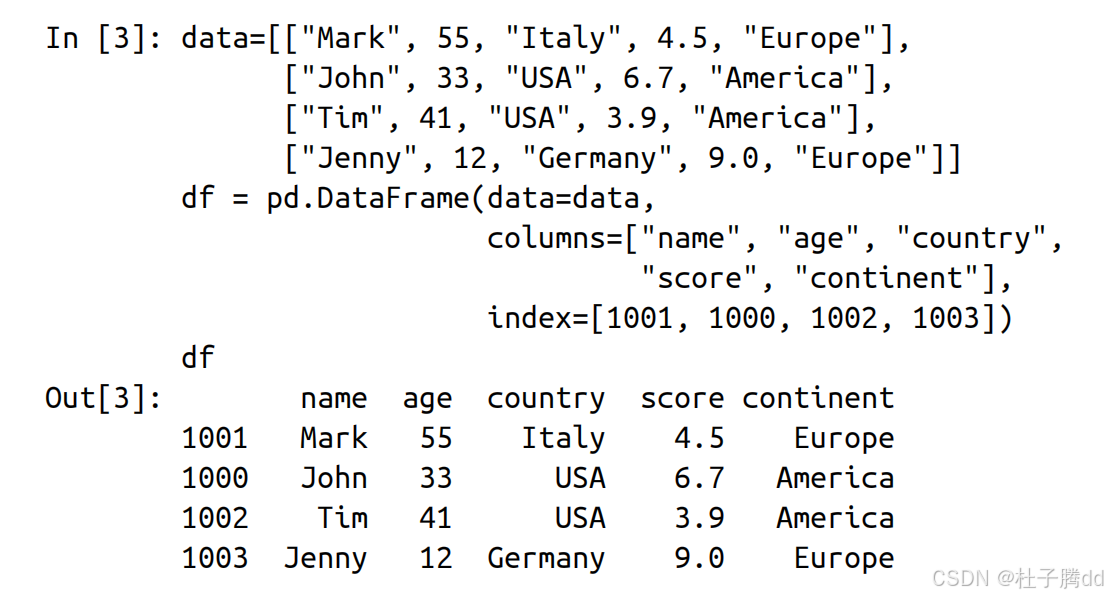
2.嵌套列表创建
提供数据, columns 参数和 index 参数。

三 数据操作
在使用数据之前,需要对其进行清理。
1.选取数据
1.使用标签选取数据
使用 loc 属性(代表 location 位置)指定你想获取的行和列。
df.loc [ 行的选择, 列的选择 ]

df.loc[1000, "country"]
1000:表示行标签(index),即数据中某行的唯一标识符 ,不是行的自然位置(如第 1000 行)
"country":表示列标签(column),即列的字段名。
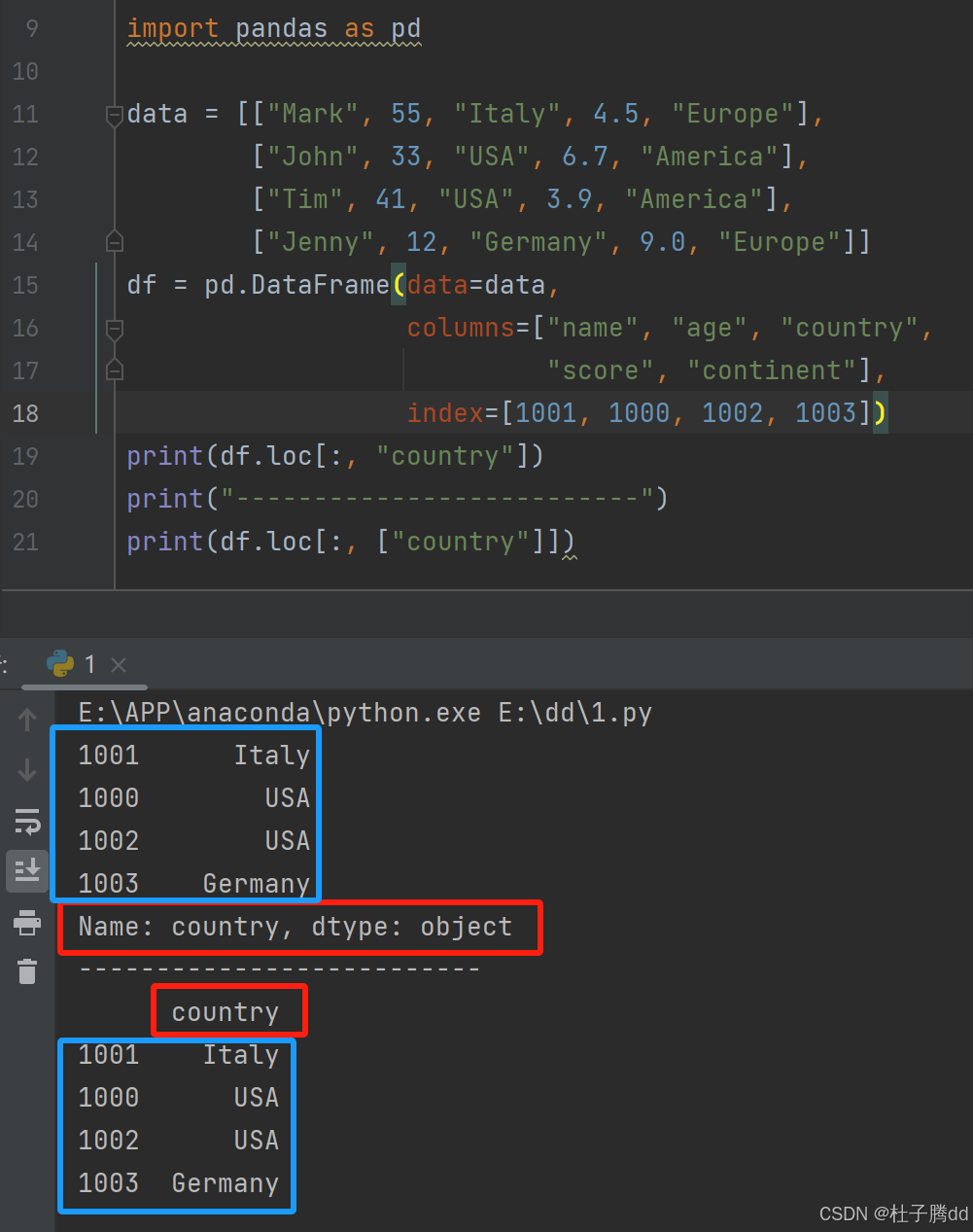
表格中的一列是不包括索引列的。一维就是没有标签名,二维就是有标签名。

1.参数类型决定维度
df.loc[:, "country"]:传入单个列名(字符串),Pandas 默认返回该列的所有数据,结果是一个 一维的 Series,包含列值和行索引。
df.loc[:, ["country"]]:传入包含列名的列表,Pandas 会将其视为多列选择(即使列表中只有一个元素),因此返回一个二维的 DataFrame,保留列值、行索引和列标签。
上述都是列的选取,便捷写法:df[column_selection]
2.在使用标签切片时,标签的区间包含区间首尾的两个标签。
3.举例

4.DataFrame(无论是一列还是多列)与 Series 之间是有区别的
2.使用条件判断选取数据

3.使用位置选取数据
使用 iloc 属性。
df.iloc [ 行的选择, 列的选择 ]
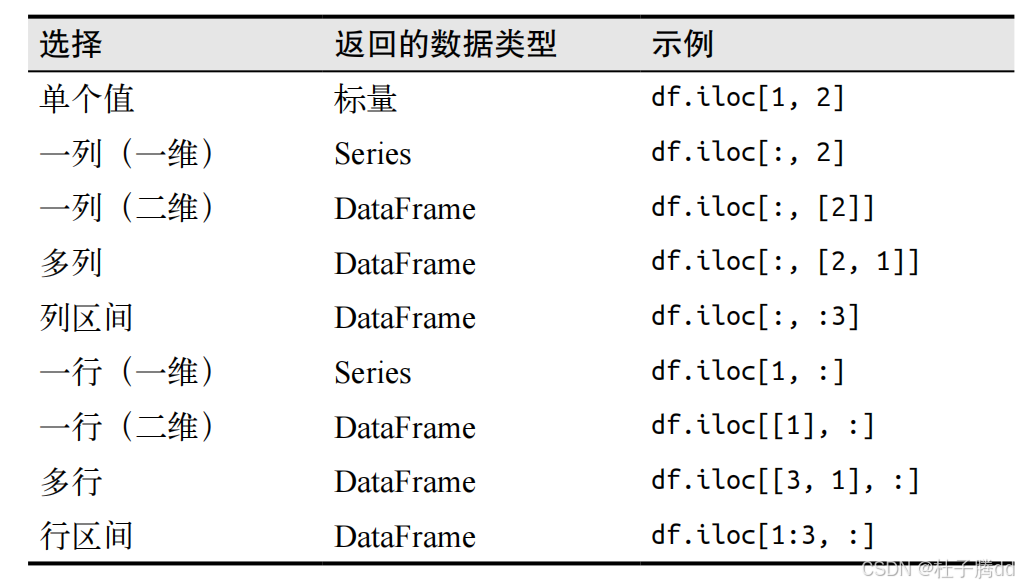
1.在使用切片时,iloc 使用的是标准的半开半闭区间,和 loc 属性不同。
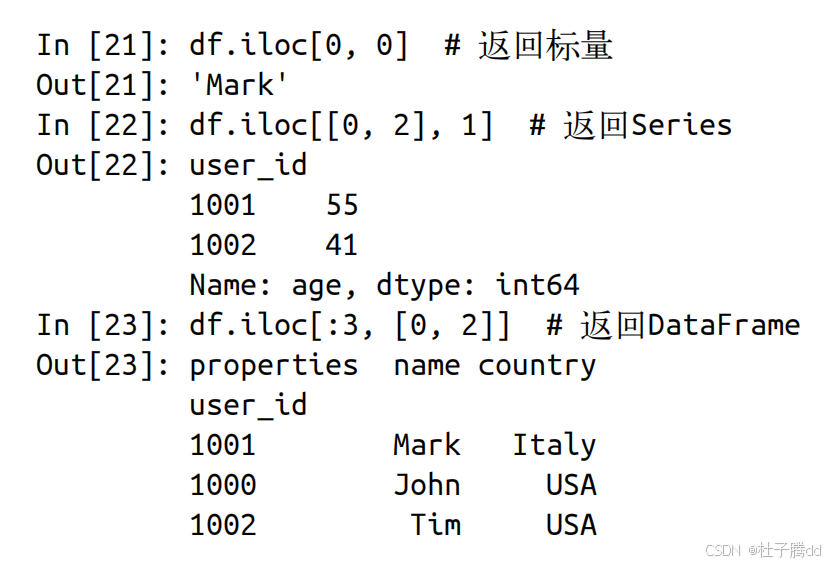
2.举例
4.使用布尔索引选取数据
方式1:
步骤1:生成布尔序列。
通过条件表达式(如 df['Age'] > 30)生成一个由 True/False 构成的 Series,长度与原 DataFrame 的行数一致。
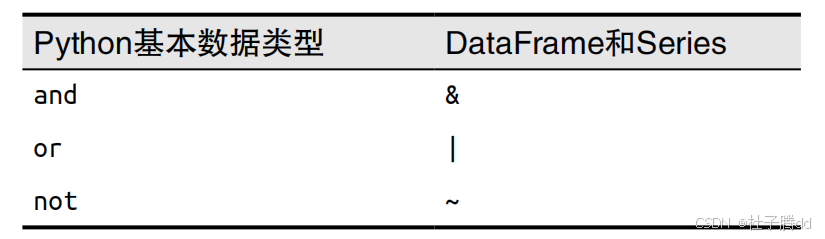
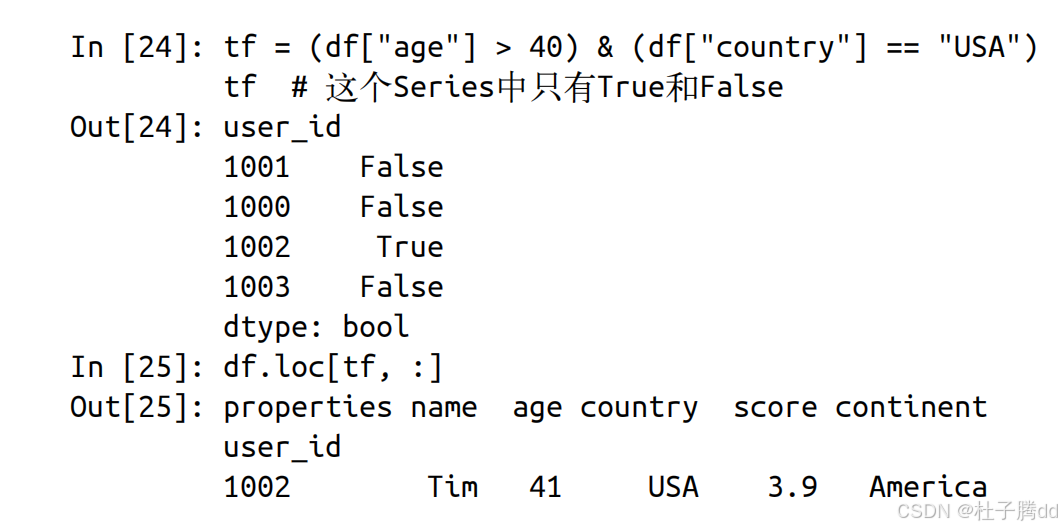
1.单条件筛选

condition = titanic["Age"] > 35 是基于布尔逻辑的条件表达式,作用是生成一个布尔序列。
2.多条件组合
通过逻辑运算符 &(与)、|(或)、~(非)组合多个条件。

3.处理缺失值
利用 isnull() 或 notnull() 生成布尔序列。

4.基于列表筛选(isin())
Python 的基本数据结构(如列表)可以使用 in 运算符判断是否包含某些对象。

5.对索引进行筛选
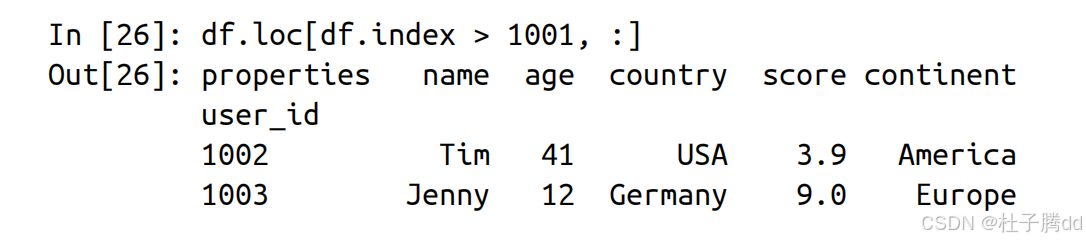
步骤2:筛选子集。
将布尔序列作为索引传递给 DataFrame(如 df[condition]),仅保留 True 对应的行。
举例:使其只展示居住在美国且年龄在 40 岁以上的学员。
方式2:
在不使用 loc 的情况下传递一整个布尔 DataFrame 作为参数:df[boolean_df] 。
在 DataFrame 只包含数字时这种语法特别有用。
举例:
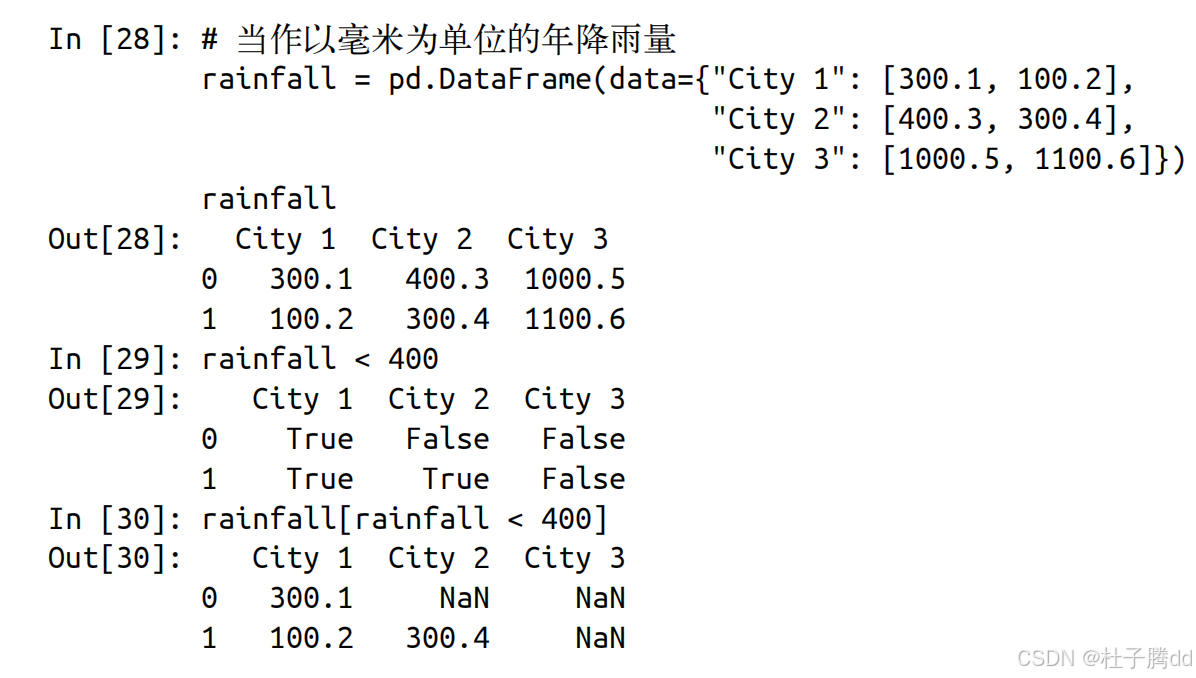
布尔值的这种用法经常被用来排除某些值,比如异常值。
5.使用 MultiIndex 选取数据
MultiIndex 是一种多级索引,可以将数据按层次分组。将 DataFrame 的索引设置为多级(层次化索引),便于按层次筛选数据。
原数据:
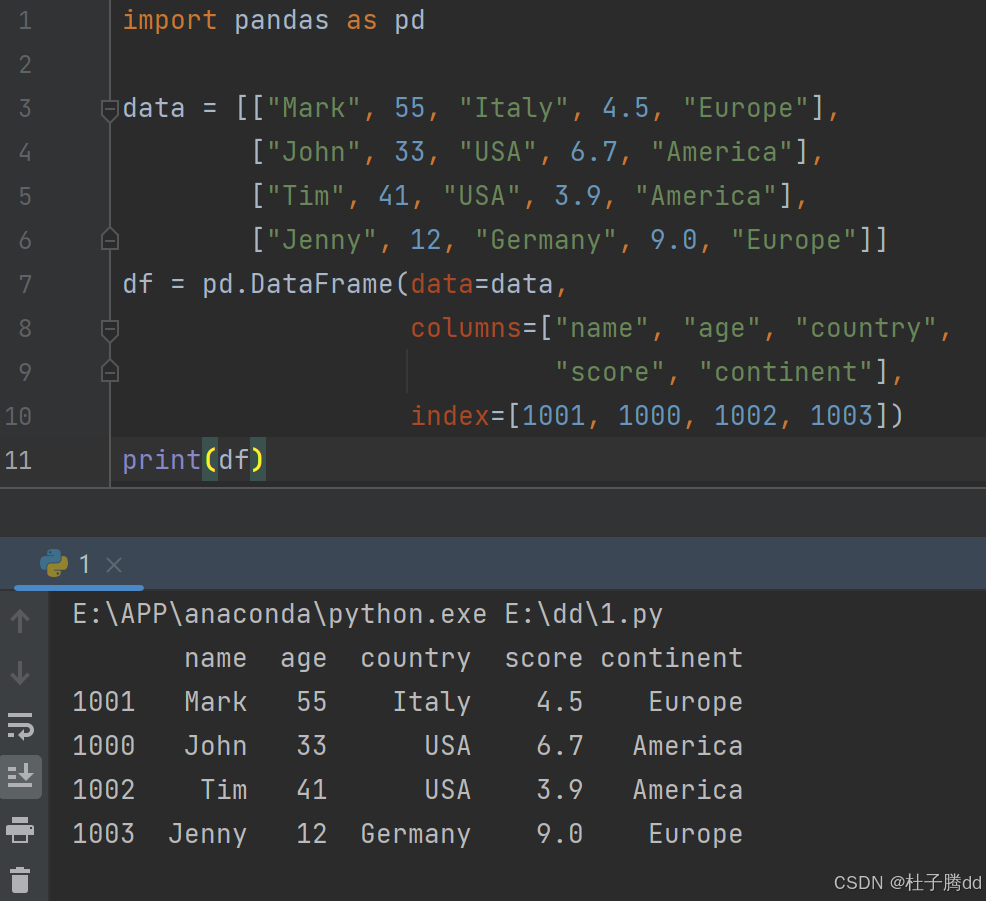
步骤1:创建 MultiIndex

reset_index:把索引还原成一个普通列。
set_index(["continent", "country"]):将 continent 和 country 列设为新的索引,形成两级(MultiIndex)。
sort_index():按索引层级(先 continent 后 country)排序。
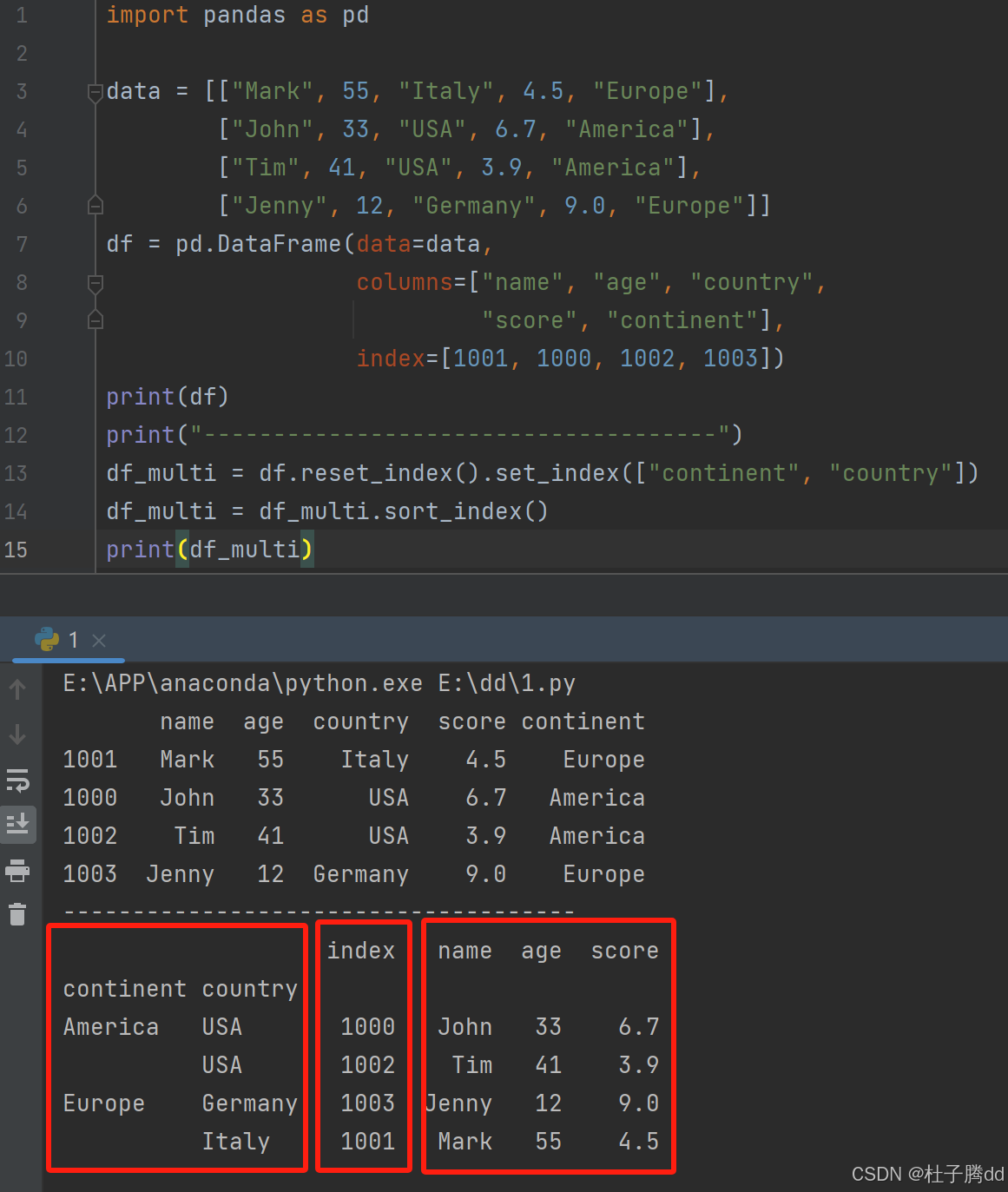
步骤2:通过第一级索引选取数据
直接通过大洲名称(第一级索引)选取所有对应国家的数据。
print(df_multi.loc["Europe", :])
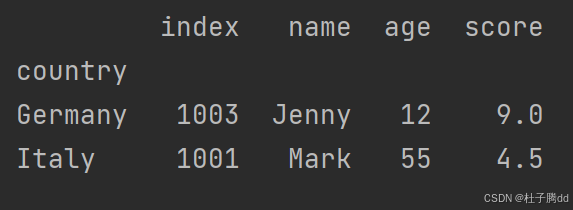
loc["Europe", :]:选取第一级索引为 Europe 的所有行,保留所有列。
步骤3: 通过多级索引精确选取
print(df_multi.loc[("Europe", "Italy"), :])
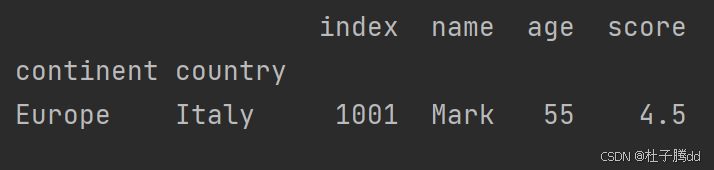
使用元组 ("Europe", "Italy") 指定两级索引的值,精确匹配欧洲的意大利数据。
步骤4:部分重置索引
将 MultiIndex 的某一层级恢复为普通列。
df_multi.reset_index(level=0)
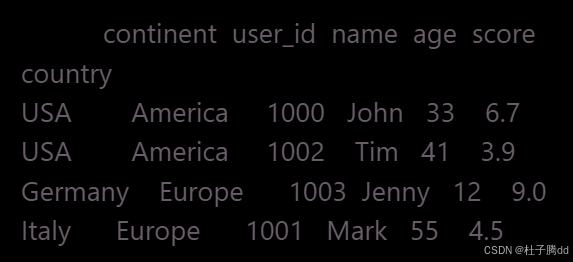
reset_index(level=0):将第一级索引(continent)转换为普通列,保留第二级索引(country)。
level=0 表示操作第一级索引(索引层级从左到右从 0 开始编号)。
2.统计与分组
1.统计
sum、mean、count 等方法。
1.在默认情况下,这些方法会按 axis=0 返回一个 Series

2.想计算行的统计量,那么需要提供 axis 参数

3. 默认情况下,缺失的值不会参与 sum 和 mean 的计算
2.分组
计算每个大洲的学员的平均分:
将各行按大洲分组,随后再应用 mean 方法,最终就算出了每组的平均值。

如果参数不止一列,那么结果 DataFrame 就会有分层索引,也就是前面见过的 MultiIndex:

3.使用自定义函数

3.处理缺失值
数据集中有空白是很常见的情况,并且你还不得不对其进行处理。在 Excel 中,你 通常必须用空白单元格或者 #N/A 错误进行处理。
1.用 NumPy 的 np.nan 代表缺失数据,显示为 NaN。
NaN 是浮点数标准中的 Not-a-Number(非数字)。对于时间戳,则是使用 pd.NaT,而文本使用的是 None。
2.要移除所有包含缺失数据的行

3.移除所有值都缺失了的行

4.反映对应位置上是否是 NaN 的布尔 DataFrame 或 Series
使用 isna 方法。

5.使用 fillna 来填补缺失的值

将数据点数量列中的 NaN 替换为平均分:

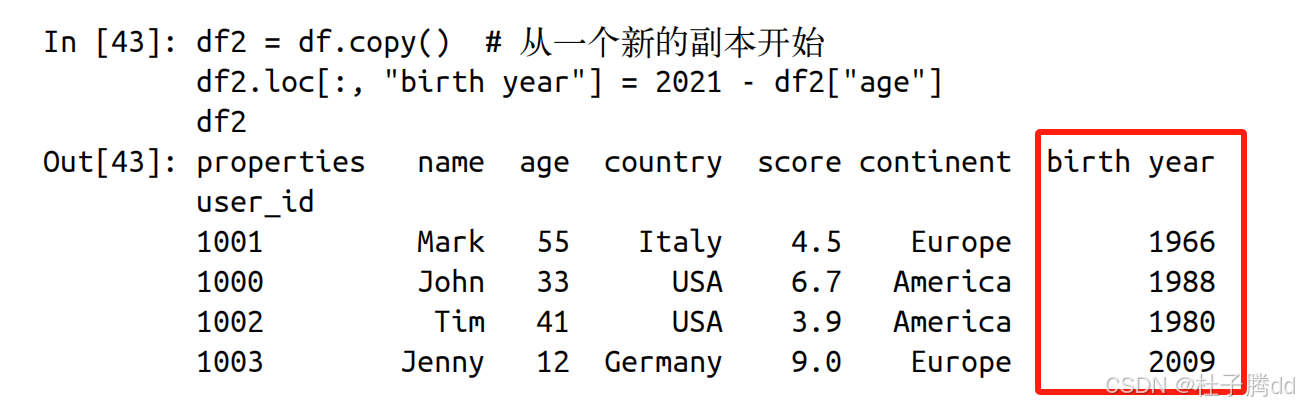
4.修改数据
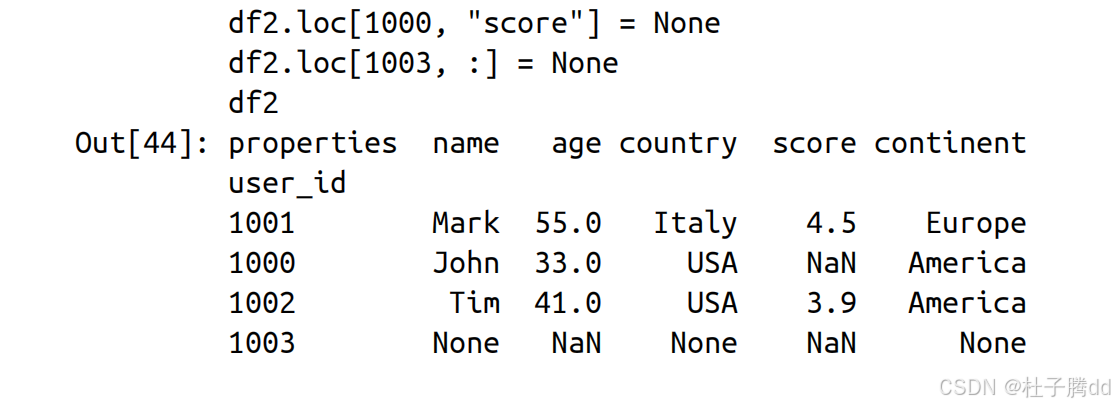
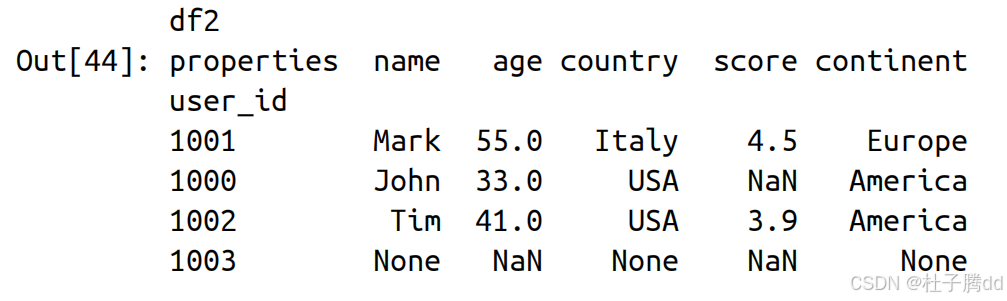
1.通过标签或位置设置值
以 df.reset_index() 的形式调用 DataFrame 的方法时,方法总 是会被应用到一个副本上,而原本的 DataFrame 是原封不动的。然而通过 loc 属性(按标签修改)和 iloc 属性(按位置修改)赋值时,原本的 DataFrame 是会被修改的。
1.修改某一个值
iloc同理。

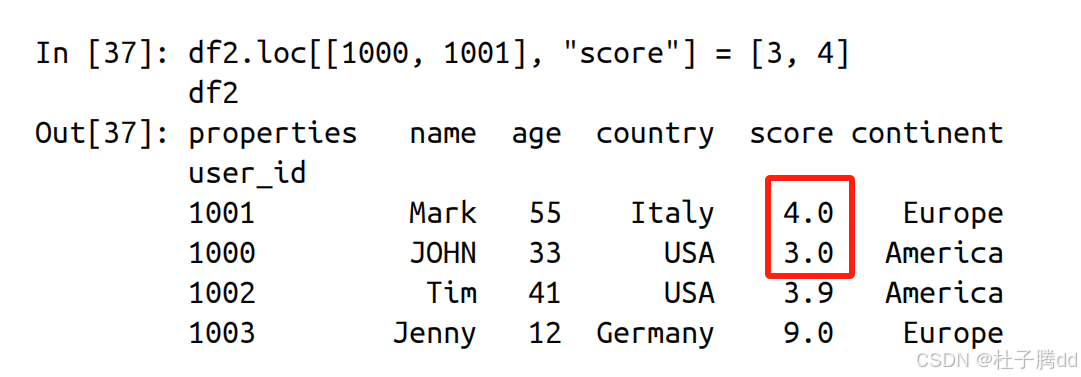
2.修改多个值
iloc同理。
2.通过布尔索引设置数据
1.用来筛选行的布尔索引用来为 DataFrame 赋值。

2.要将整个数据集中的某个值完全替换,而不是只涉及特定的列。
1.数据中全是数字数据
将一个布尔 DataFrame 作为参数。

2.replace 方法

如果只想在 country 列上进行操作:

3.通过添加新列设置数据
为一个新的列名赋值时会为 DataFrame 添加一个新列。
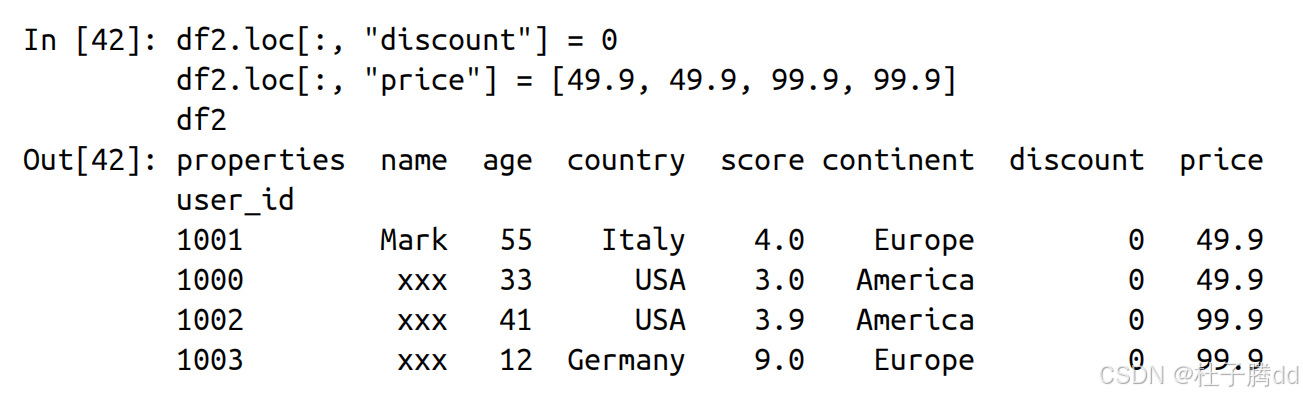
添加新列时经常涉及向量化运算。
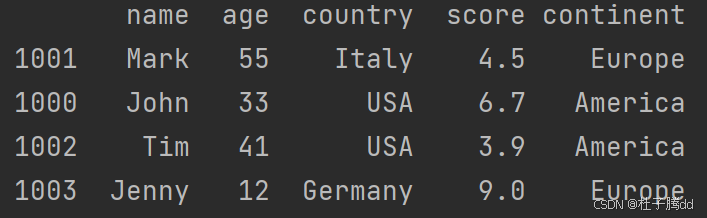
5.重复数据
1.清理重复的行
默认情况下,第一次出现的数据会得以保留。

2.确认某一列是否包含重复数据

3.获得去重后的值

4.知道哪些行是重复的
duplicated 方法,它的返回值是一个布尔 Series。
keep 参数的默认值是 "first",意思是会保留第一次出现的数据,只将重复数据标记为True。
将 keep 设置为 False 时,所有的重复数据(包括第一次出现时)都会被标记为 True,这样就可以方便地得到一个包含所有重复行的 DataFrame。
在实际工作中,通常都是找重复的索引或者整行的重复数据。这个时候就要使用 df.index.duplicated() 或者 df.duplicated()
举例:找 country 列的重复数据

6.算数运算
对多个 DataFrame 使用算术运算符时,pandas 会自动将它们按照列或行索引对齐。
1.DataFrame 中的每一个值加上一个数

2.两个相同行列标签的 DataFrame 求和


结果 DataFrame 的索引和列是两个 DataFrame 的并集:两个 DataFrame 中都有的字段会被相加,而其他的部分会显示为 NaN。 Excel 在执行算术运算时空单元格会被自动变成 0。
可以使用 add 方法,并将 fill_value 参数设置为 0 以代替默认的 NaN:

3.当算式的操作数是一个 DataFrame 和一个 Series 时,默认情况下 Series 会按索引进行广播。
1.按行索引加上一个 Series

2.按列索引加上一个 Series
需要在调用 add 方法时显式地提供 axis 参数。

4.算数运算符
其他算术运算符也有对应的方法,也是同样的工作方式。

7.处理文本列
含有文本数据的列和含有不同类型数据的列的数据类型是 object。要在含有文本字符串的列上执行相关操作,需要使用 str 属性。
str 属性可以访问 Python 的字符串方法。
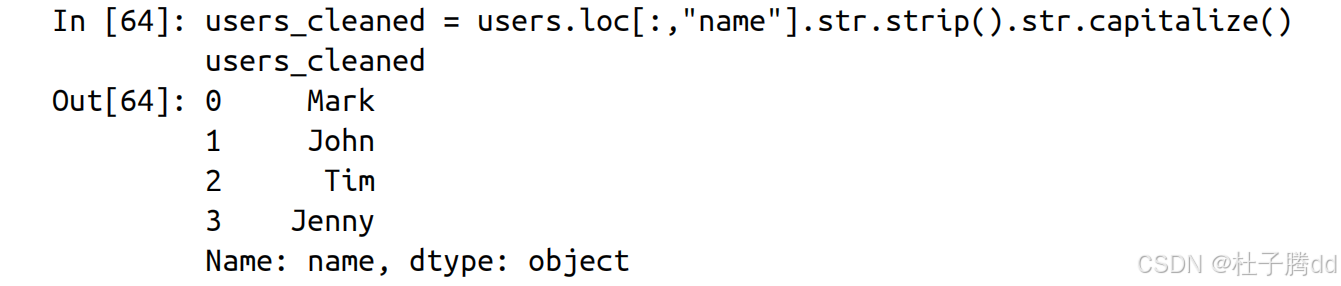
1.移除字符串首尾的空白
使用 strip 方法。
2.将首字母大写
使用 capitalize 方法。
3.举例
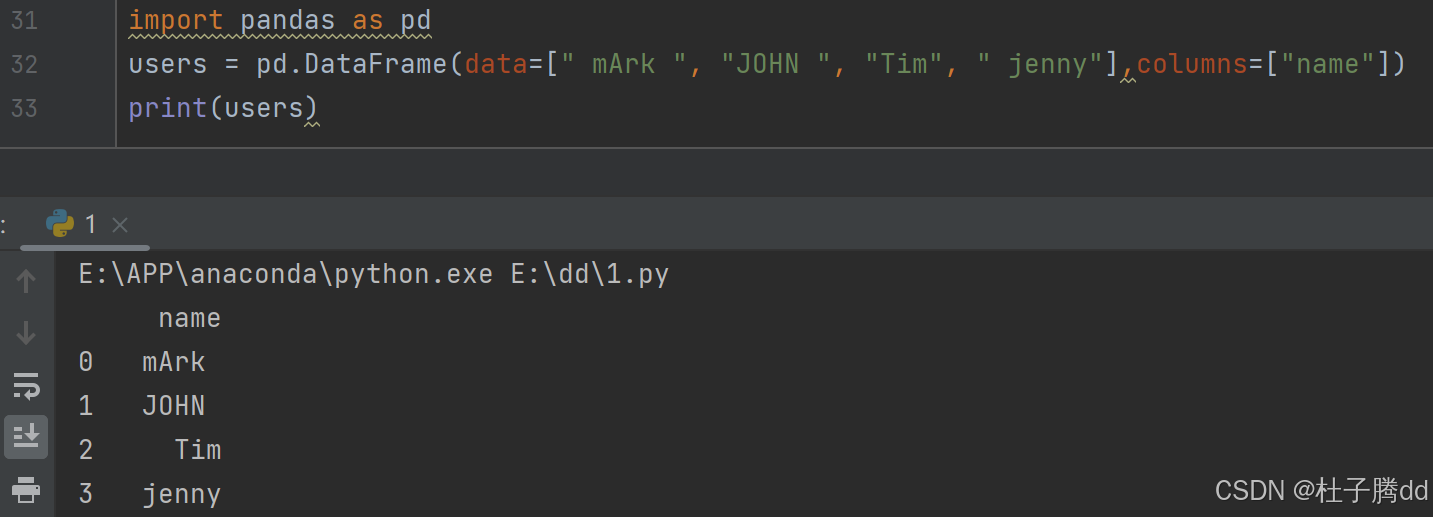
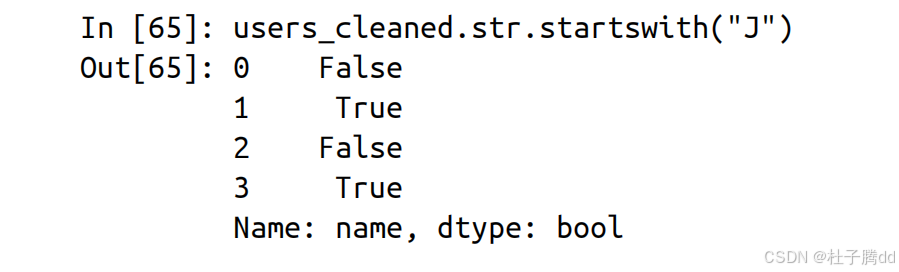
4.找到所有以“J”开头的名字
8.创建自己的函数,再将其应用DataFrame上
使用 applymap 方法,将一个函数应用到每一个元素上。
NumPy 并没有提供字符串格式化的 ufunc(通用函数),但可以像下面这样为 DataFrame 的每一个元素进行格式化:

通过 applymap 对 DataFrame 中的每个元素应用格式化函数。
传递函数时不要加括号。applymap 需要接受一个函数对象(format_string),而不是函数的调用结果(format_string())
如果写成 applymap(format_string()):会直接调用 format_string 函数,但此时函数缺少参数 x,导致报错。正确做法是传递函数本身,由 applymap 在内部自动调用它。
通常和 lambda 表达式结合使用。lambda 表达式是一 种匿名函数,也就是一种没有名称的函数。把 def 换成 lambda,省去 return 关键字,然后将函数的所有内容写到一行。作用是无须单独定义一个只会使用一次的函数。


9.将 DataFrame 写入 Excel
1.将 DataFrame 赋值给 Excel 区域的左上角单元格
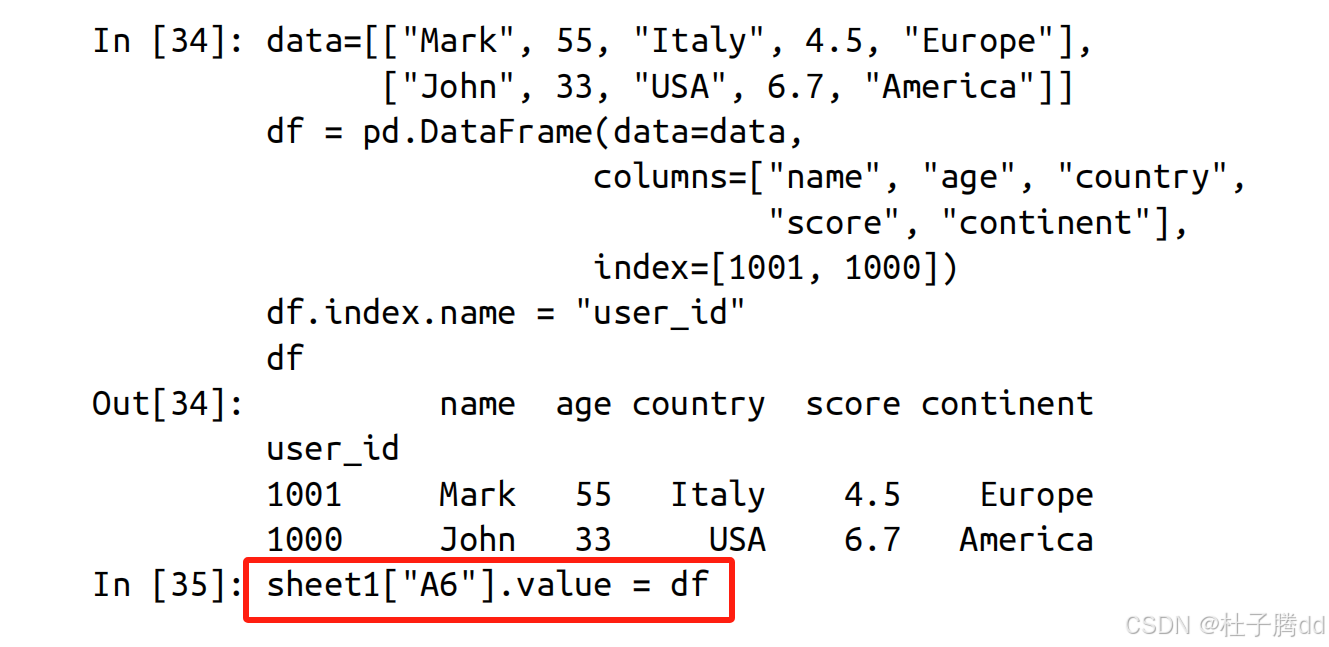
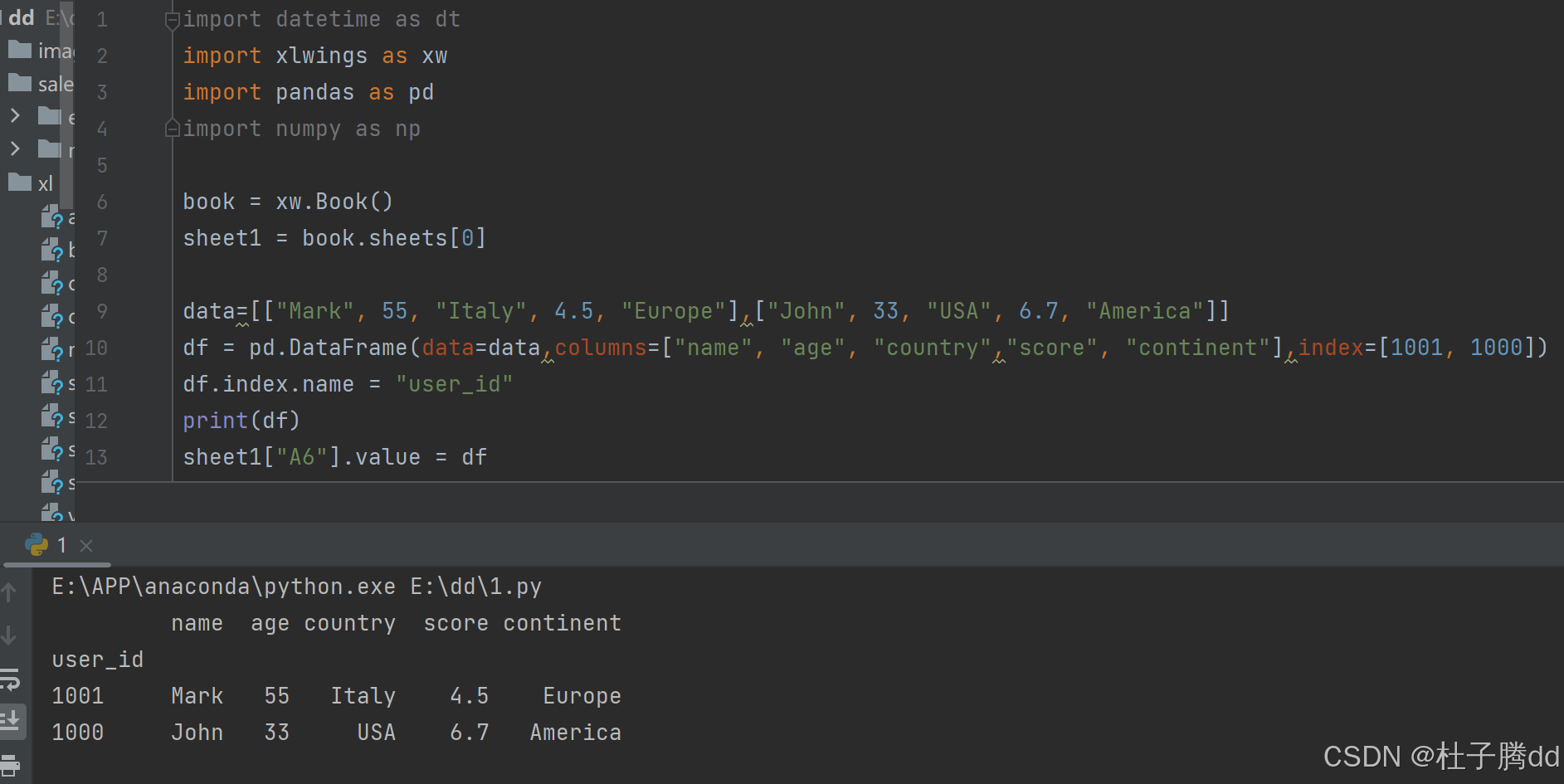
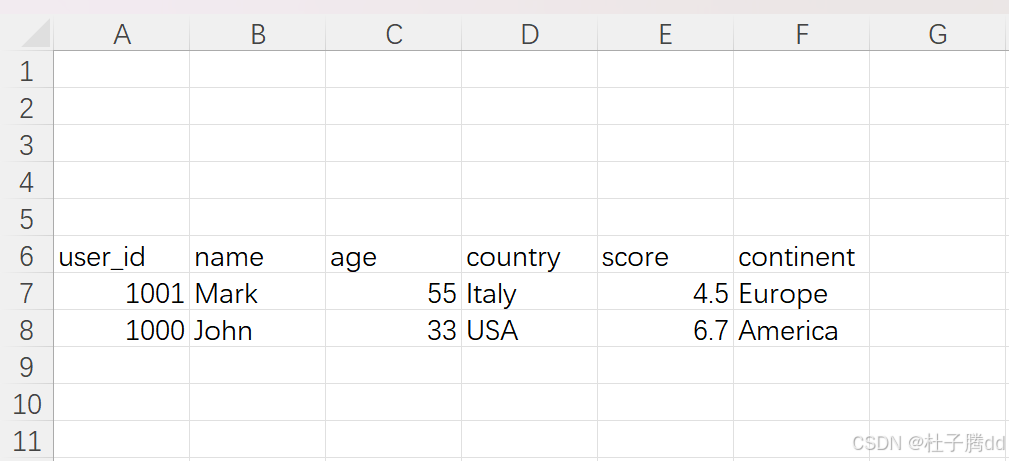
补充:去掉列标题或索引(也可以同时去掉两者),可以使用 options 方法。

2.convert 参数
要将 Excel 区域以 DataFrame 的形式读取,需要将 DataFrame 类传递给 options 方法的 convert 参数。
补充:convert 参数。
convert参数并非直接属于pandas.options方法,而是常见于read_csv、read_excel等数据读取函数中。为指定列定义转换函数,例如将字符串转换为日期。df = pd.read_excel('data.xlsx', converters={'Date': pd.to_datetime}) # 将'Status'列的'Active'映射为1,其他值映射为0 df = pd.read_excel('data.xlsx', converters={ 'Status': lambda x: 1 if x.strip().lower() == 'active' else 0})
在默认情况下,数据必须同时具备标题和索引,但是可以通过 index 参数和 header 参数来改变这种行为。
补充:
index,header, ndim ,empty、date 和 number 参数。
index_col参数:将指定列设置为DataFrame的索引列。# 将第一列(索引0)设置为索引 df = pd.read_excel('data.xlsx', index_col=0) # 将名为'ID'的列设置为索引 df = pd.read_excel('data.xlsx', index_col='ID')
header参数:指定哪一行作为列名(标题)。默认值header=0,即使用第一行作为列名。若数据没有标题行,需设置header=None,此时列名会默认为整数索引(0, 1, 2...)。# 无标题数据,手动指定列名 df = pd.read_excel('data.xlsx', header=None, names=['Column1', 'Column2'])
ndim 参数:
ndim是一个用于控制从 Excel 读取数据时的维度的参数。强制指定返回值的维度(一维或二维),仅在以列表或 NumPy 数组形式读取值时生效。
ndim可以设置为None、1或2,用于强制指定返回值的维度。
ndim=1 会强制让读到的单个单元格的值生成列表而非标量。在使用 pandas 时无须使用 ndim参数,因为 DataFrame 都是二维的,而 Series 都是一维的。
仅适用于列表或 NumPy 数组:当使用
.value属性或相关方法(如.options().value)读取数据时,ndim才生效。在默认情况下,从 Excel 中读取单个单元格时,会得到一个标量(比如浮点数或字符串);当读取一行或一列时,你得到的是一个简单列表;当读取一个二
维区域时,你得到的是一个嵌套(二维)列表。但一维的情况很特殊:有时候一列可能只是二维区域的特殊情况,在这种情况下,可以用 ndim=2 来强制区域的维度为 2:
假设有一个单行数据
A1:C1:
使用
ndim=2强制二维:
如果直接使用ndim=None(默认),单列/单行数据会被读取为一维数组: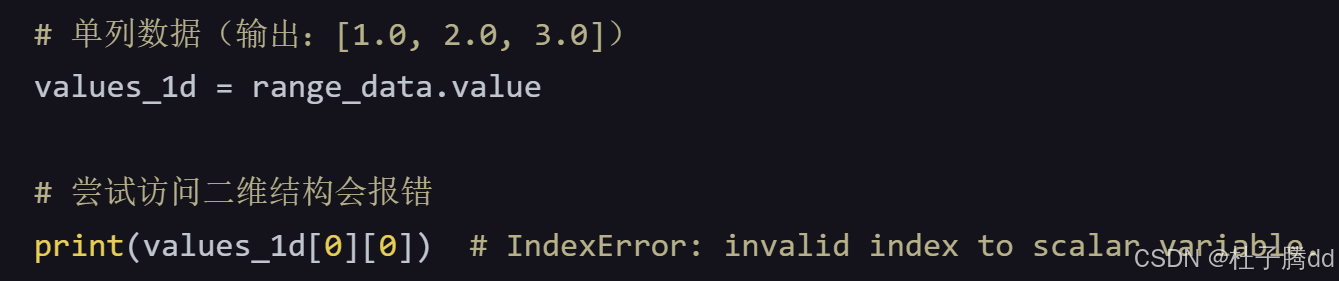 其他例子:假设 Excel 中有一个区域
其他例子:假设 Excel 中有一个区域A1:B2:
# ndim=None(默认) import xlwings as xw wb = xw.Book("example.xlsx") sheet = wb.sheets["Sheet1"] range_data = sheet.range("A1:B2") # 自动推断维度(二维) values = range_data.value print(values) # 输出:[[1.0, 4.0], [2.0, 5.0], [3.0, 6.0]] # ndim=1(强制一维) # 强制一维(数据被展平) values = range_data.options(ndim=1).value print(values) # 输出:[1.0, 4.0, 2.0, 5.0, 3.0, 6.0] # ndim=2(强制二维) # 强制二维(即使单行/单列也保持二维) values = range_data.options(ndim=2).value print(values) # 输出:[[1.0, 4.0], [2.0, 5.0], [3.0, 6.0]]
empty参数:指定空单元格的默认值。默认行为:空单元格会被读取为None。自定义行为:通过为empty提供一个值(如0、NaN或其他占位符),可以改变空单元格的默认返回值。
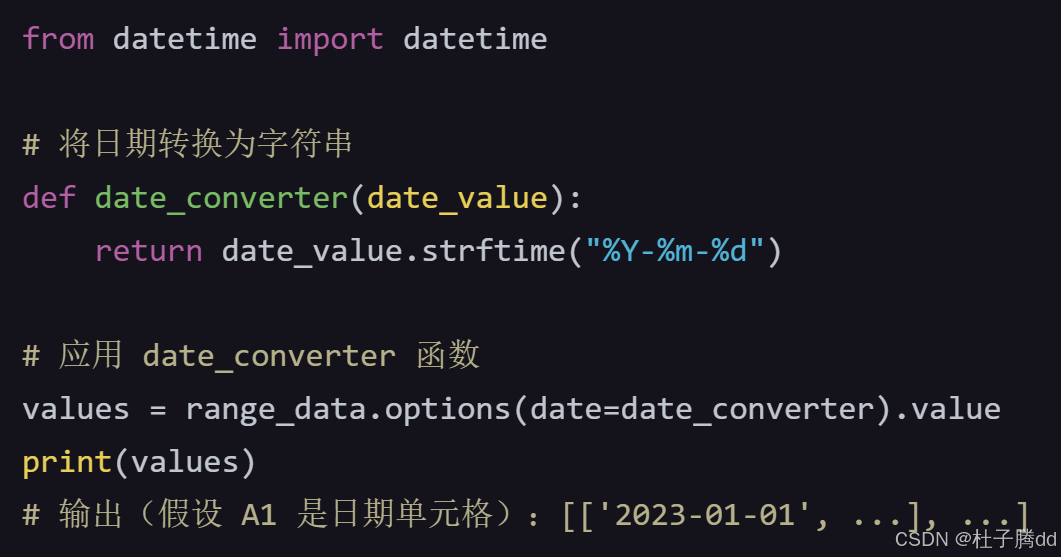
date参数:接受一个函数,该函数会被应用到从日期格式单元格读取的值上。默认行为:日期单元格会被读取为datetime对象。自定义行为:通过传入函数,可以转换日期格式(如字符串、时间戳等)。
numbers参数:接受一个函数,该函数会被应用到数值单元格的值上。默认行为:数值单元格会被读取为float或int。自定义行为:通过传入函数,可以修改数值(如四舍五入、格式化或类型转换)。





3.expand 方法
读取一块连续的单元格,这和在 Excel 中按下快捷键 Shift+Ctrl+ 下箭头 + 右箭头选中的区域是一样的,只不过 expand 会跳过左上角的空单元格。
补充:Shift+Ctrl+ 下箭头 + 右箭头的效果如图。
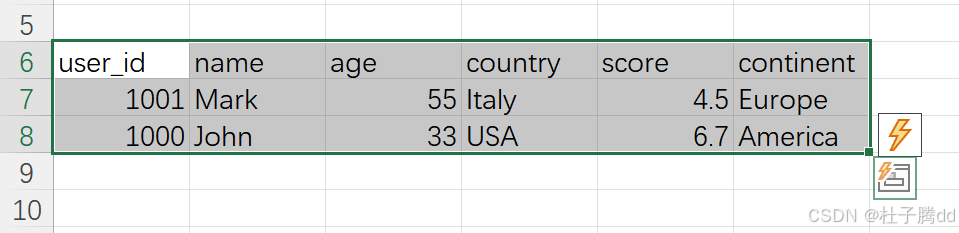

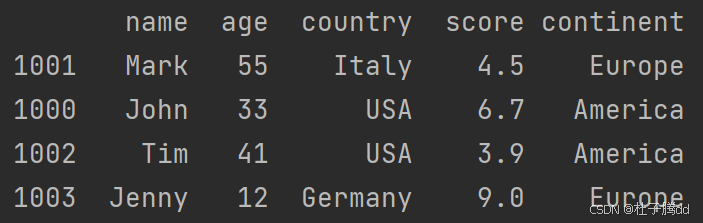
将 Excel 工作表 sheet1中A6单元格及其合并区域(如果有)的数据,转换为 Pandas DataFrame格式,并赋值给变量 df2 。
.expand():如果A6是合并单元格(如合并了A6:D8),此方法会扩展选中整个合并区域。如果A6是单个单元格,则仅选中A6本身。
.options(pd.DataFrame):设置读取选项,指定将Excel数据转换为Pandas的DataFrame格式(而非默认的嵌套列表)。
补充:修改索引的数据类型。
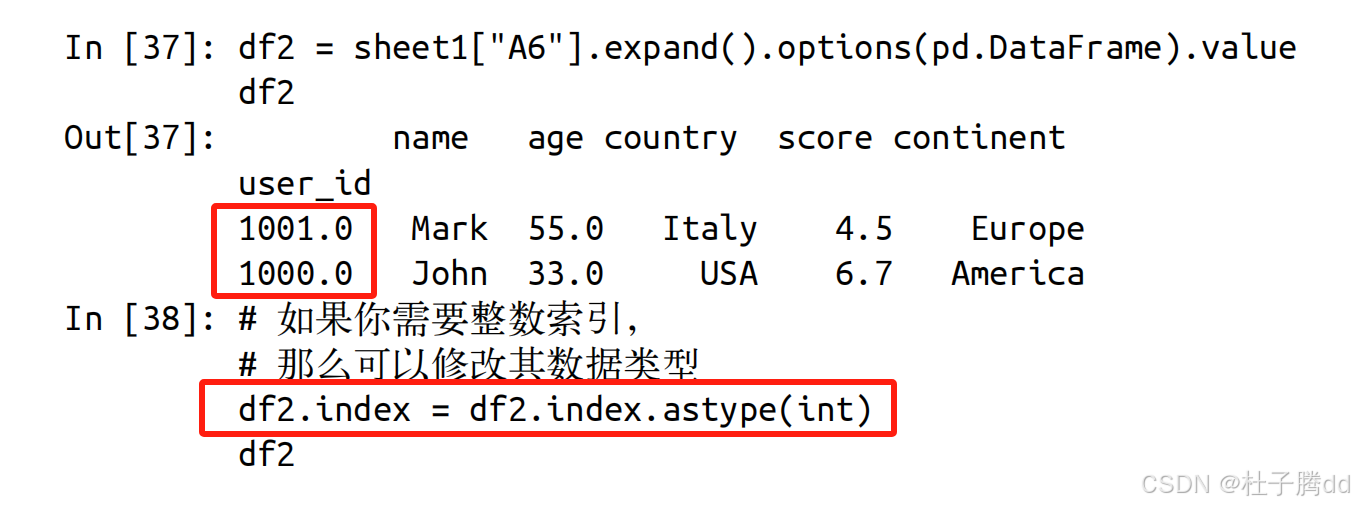

补充:生成的 DataFrame 不包含 Excel 行号作为索引。
将Excel工作表
sheet1中A6单元格及其合并区域的数据,转换为 Pandas DataFrame 格式,且生成的 DataFrame 不包含Excel行号作为索引。

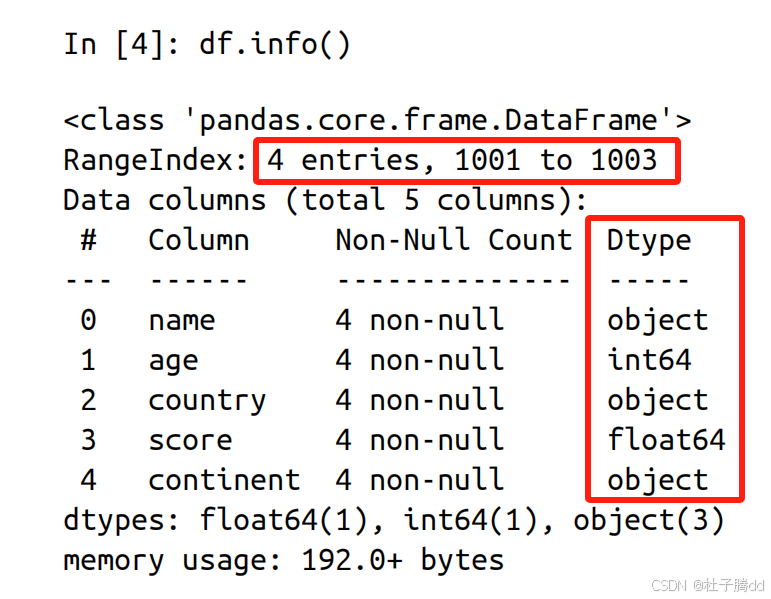
四 获得 DataFrame 的基本信息
使用 info 方法。
重要的是数据点数量和每一列的数据类型。
五 DataFrame 的方法返回的是副本
每当以 df.方法名() 的形式调用 DataFrame 的方法时,你都会得到一个应用了该方法的DataFrame 副本,而原来的 DataFrame 没有任何变化。
六 什么时候 pandas 会使用 DataFrame 的视图,以及什么时候使用的是副本
在原本的 DataFrame 中设置值,而不是在切片生成的 DataFrame 中操作。
如果你想在切片后获得一个单独的 DataFrame,则应该显式地调用 copy。
selection = df.loc[:, ["country", "continent"]].copy()
loc 和 iloc 的情况很复杂,但是诸如 df.dropna() 或 df.sort_value("column_ name") 这样的 DataFrame 方法总是返回副本。
七 可视化
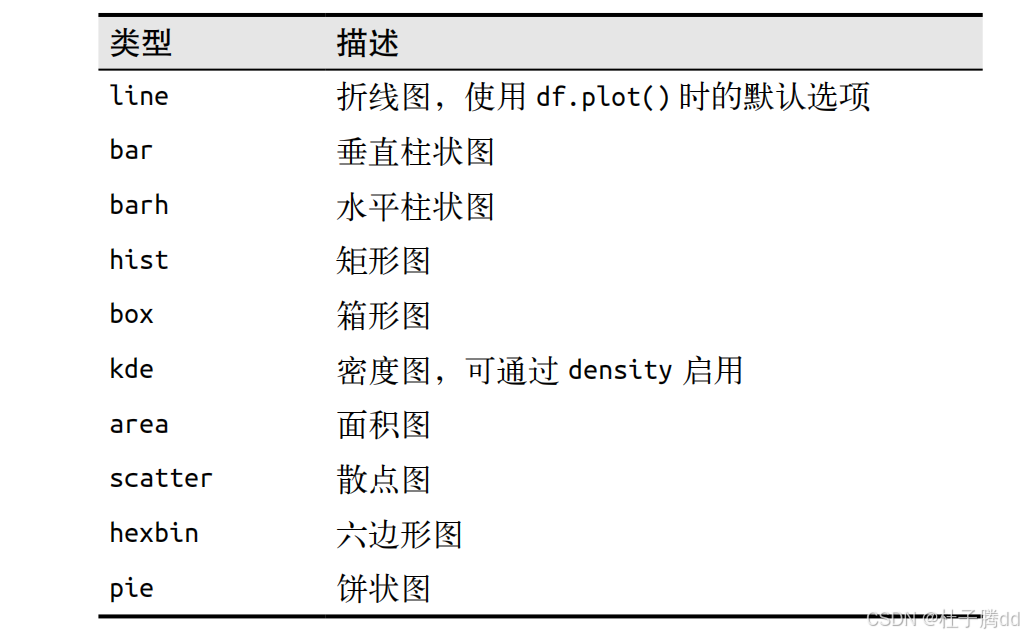
1.结合 Seaborn 生成热图,展示列间相关系数
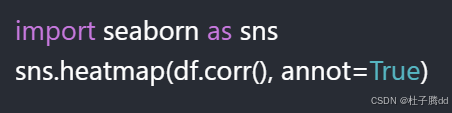
2.pandas 默认的绘图库 Matplotlib
第8节
3.现代化的绘图库 Plotly
第9节

















 2万+
2万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









