



摘要
|
近年来,视频生成领域的进展主要依赖于扩散模型来生成短时内容。然而,这些方法在建模复杂叙事和保持角色长期一致性方面存在明显不足,这恰恰是电影等长视频制作的关键需求。 为此,我们提出 MovieDreamer——一种创新的层次化框架,通过整合自回归模型和基于扩散的渲染技术,首次实现了具有复杂情节推进和高视觉保真度的长视频生成。 该方法采用自回归模型确保全局叙事连贯性, 预测视觉标记序列,再通过扩散渲染转化为高质量视频帧。这种设计模拟了传统电影制作流程,将复杂故事分解为可管理的独立场景。特别地,我们引入多模态剧本概念,每个关键帧都包含图像风格、场景元素的丰富描述,以及角色文本描述和检索的人脸嵌入。 这种多模态脚本有效增强了跨场景的叙事连续性, 同时提供了灵活的角色控制能力。我们在多种电影类型上进行了广泛实验,结果表明:1)在视觉和叙事质量方面显著优于现有技术;2)将生成内容时长从当前主流的秒级扩展到数千关键帧规模;3)角色身份保持效果显著提升,自动化长视频制作开辟了新的可能性。 |

简介
随着生成建模技术的进步,视频生成领域取得了显著进展。大量研究致力于将预训练的文本到图像扩散模型适配为视频生成模型。近期, Sora 模型通过空间-时间网络的规模化实现了革命性突破,将生成视频时长从几秒大幅延长至前所未有的完整一分钟。这项技术深刻重塑了生成式 AI 的边界,激发了人们对小时级电影制作的期待。
当前主流视频生成方法采用扩散模型,但该范式更擅长视觉渲染,而在建模复杂抽象逻辑和推理方面表现不佳。此外,扩散模型缺乏支持任意长度的灵活性。相比之下,自回归模型在处理复杂推理和预测未来事件方面表现更优,这是世界模型的关键要素。自回归模型还能灵活处理不同长度的预测,并受益于成熟的训练和推理基础设施。因此,已有尝试使用自回归模型进行视频生成。然而,自回归模型在视觉渲染上的计算效率不如扩散模型,即使是图像渲染也需要更多计算资源。
本文另辟蹊径,结合自回归模型和扩散模型各自的优势实现了一种针对长视频生成的框架。我们突破了短视频生成的限制,实现具有丰富、引人入胜故事线的视频创作。

方法
MovieDreamer 包含三个核心组件:
-
标记化模块:扩散自动编码器将关键帧压缩为 2 个视觉标记,并能够将视觉标记解码回关键帧。
-
自回归模型:基于预训练的大预言模型,输入剧本预测视觉标记序列。
-
视频渲染器:将关键帧扩展为视频片段。
在实现上,为了保证预测的角色身份保持,我们增强了扩散自动编码器的解码器的交叉注意力模块。并提出了结构化的多模态剧本帮助自回归模型更好地预测当前压缩的视觉标记。我们证明了利用多元混合高斯模型建模连续的标记分布能够有效地保持住角色一致性。
为了充分利用我们已拥有的数据,我们使用了诸如随机翻转、时序反转、人脸嵌入随机化、激进的神经网络 DropOut 值和标记的随机遮盖策略去进行数据增强。这些策略有效提升了模型性能。
在视频生成时,我们的模型可以与任意的基于图像的视频生成模型结合。这也充分进一步说明了我们模型的灵活性。
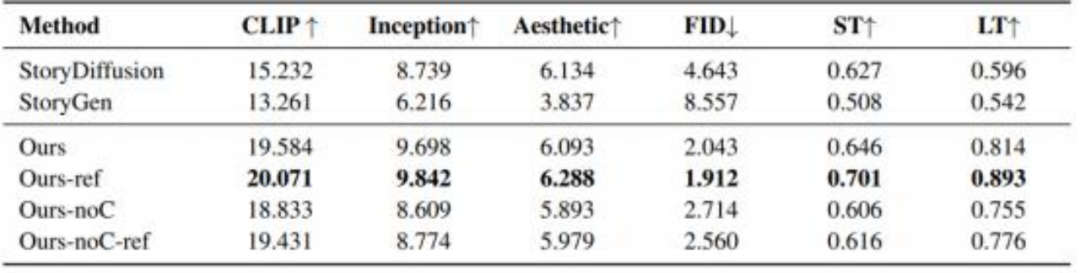
我们在多种电影类型上进行了广泛实验,验证了方法的有效性。实验结果表明,MovieDreamer 在视觉和叙事质量上优于现有方法,并能显著延长生成内容的时长。
具体而言:与现有故事生成方法相比,我们的方法在更长内容的生成中保持了更好的短时和长时一致性,角色身份和场景风格均得到有效保留。我们方法通过层次化框架生成的视频在质量和一致性上均表现优异,能够生成长达数十分钟以上的连贯视频。无论是长故事生成还是长视频生成,我们在图文对齐分数和美学打分等分数上均优于其他方法。


总结
本文提出的 MovieDreamer 通过结合自回归模型和扩散渲染技术,解决了生成长时视觉内容的挑战。该方法不仅实现了超长视频生成,还通过多模态剧本设计和身份保持渲染技术,显著提升了角色一致性和叙事连贯性。我们创新的长视频生成技术能够在"寻光"系列产品中为用户提供了专业级的长视频内容生成能力,远超当前主流短视频生成方案的时长限制。
未来,我们将进一步改进模型架构,探索更大规模的模型和数据集,以推动自动化长视频制作的边界。

















 827
827

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









