



摘要
|
随着 LLM 产业的发展,实践应用中用户愈加看重模型的长文本上下文能力。但主流模型大都是为短上下文场景优化的,其长文本上下文能力往往无法与短文本能力相提并论,主要是长文本数据标注困难等原因造成的。 对此,达摩院团队提出了一种名为 LongPO的新方法。通过自进化学习过程使模型在无需长文本优质数据训练的前提下,将短文本能力迁移泛化到长文本上下文场景,同时不影响模型的短上下文能力。 论文标题:LongPO: Long Context Self-Evolution of Large Language Models through Short-to-Long Preference Optimization 论文链接:https://www.arxiv.org/abs/2502.13922 代码仓库:https://github.com/DAMO-NLP-SG/LongPO |

构建长上下文LLM:现存问题
LLM 的标准构建过程分为两步,分别是预训练和对齐(后训练),但对于长上下文场景而言,就需要加入一个 continual 长文本训练步骤,用大量 token 多做一个预训练过程。同时为了避免对齐步骤中损失长文本预训练的能力,还要在对齐时也加入长文本的后训练过程,如图所示:
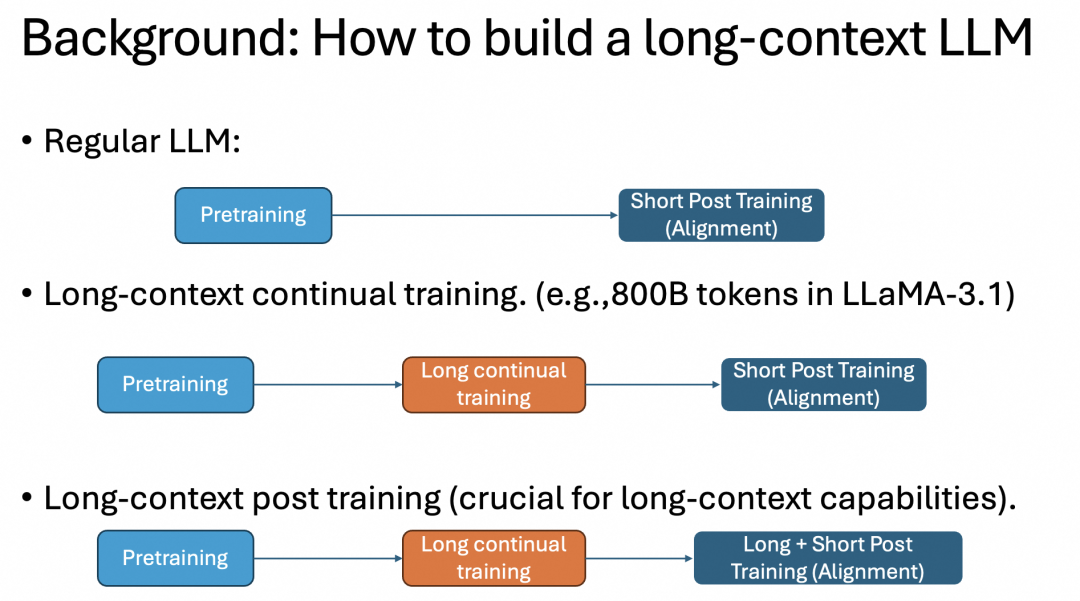
上述长文本训练方法存在的问题是,所需的长文本后训练数据集通常需要人来标注,而人天然不擅长阅读长文本并给出足够的标注信息。如果使用更大规模的 LLM 来辅助人标注长文本,成本又会显著提升。
小规模的 LLM 虽然也可用于辅助标注,但会显著降低标注质量,严重影响模型文本处理能力。另外,后训练过程混合长短文本数据后,模型又很难平衡长短文本的相关能力。
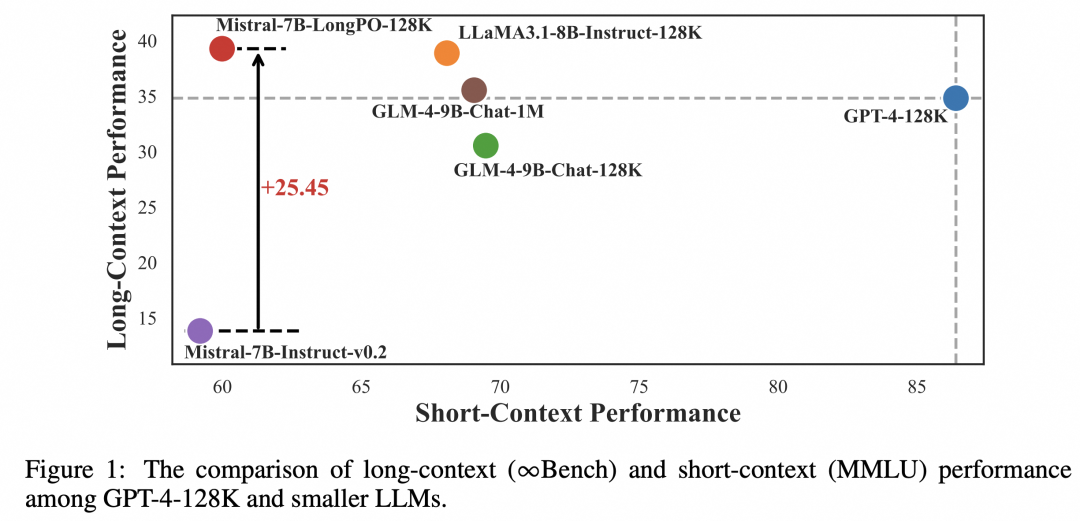
目前,主流模型一般倾向于只使用非常少量的长文本数据来对齐模型(例如,LLaMA 3.1 的长文本后训练数据只有 1% 的比例)以适应实践中短文本占主流的场景,导致模型能力无法被很好地迁移到长文本场景中。

自进化的 LLM:长上下文能力提升新方法
为了解决上述问题,达摩院团队提出了一种新的自进化方法来替换传统的长文本训练过程,提出了一种让专注于短文本的 LLM 可以自进化发展出长文本能力的方法,名为 LongPO:
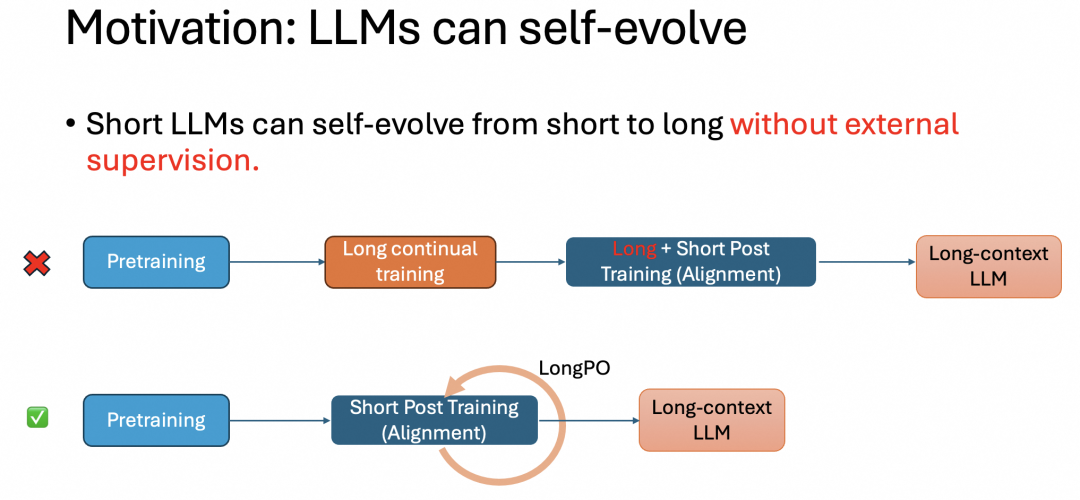
该方法应用在短文本 LLM 的对齐过程中,让模型自己指导自己向长文本能力进化,同时完全不影响原有的短文本能力,也不需要任何外界标注。
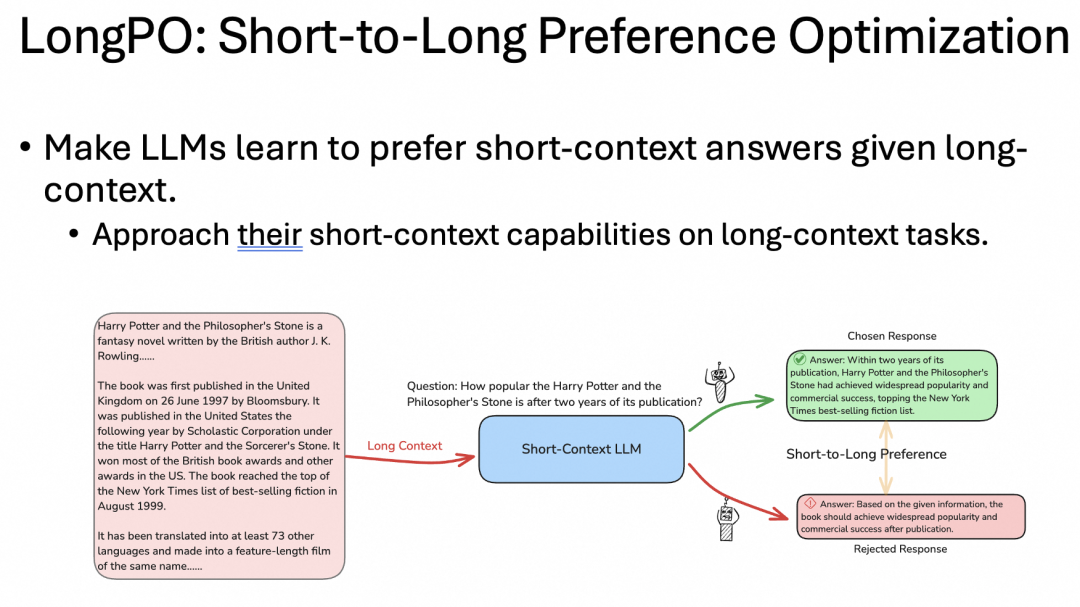
从原理来看,LongPO 的机制是让为短文本优化的 LLM 分别对一段长文本上下文,和从长文本中截取出的一小段包含重点信息的短文本上下文给出回答。因为 LLM 是为短文本优化的,所以第二类回答的质量较高。
接着使用这种方法生成的每一对回答作为训练数据,让模型在之后应对长文本上下文时更偏向于输出高质量的回答,从而增强模型的长文本上下文能力,如下图:
长文本训练过程一般不采用 DPO 方法,因为 DPO 需要一个参考模型来约束模型输出,而参考模型本身往往并没有针对长文本优化,所以用于长文本场景时是不可靠的,可能会让模型走向错误的方向。
而 LongPO 方法的原理是让参考模型在较短的重点上下文上,用输出来约束要训练的模型,而参考模型对于这些较短的上下文有着很好的效果,给出的约束就比较可靠:

上述方法的问题在于:如何在长文本中挑选出包含重点信息的短文本段落?由人或大模型标注的方法是不现实的,达摩院团队的方法则是先从长文本中随机挑选一些短文本片段,用这些片段倒推提示问题,再用这些提示问题,让模型对长文本再生成答案,与前面对短文本生成的答案形成数据对用于训练,这样就跳过了从长文本中筛选重点段落的步骤,并保证了重点段落的完整性,从而实现了完全由模型自我驱动的长文本进化过程:
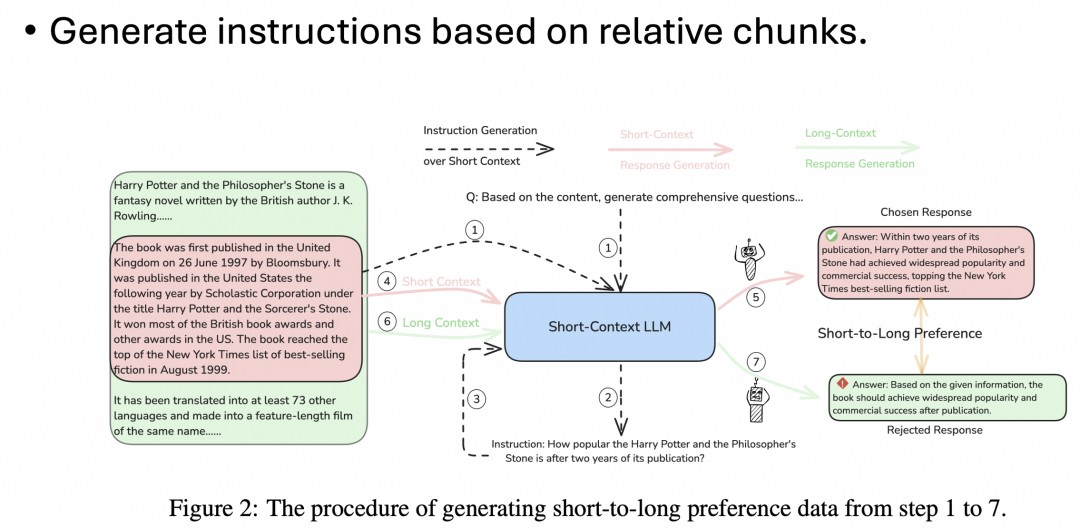
以下是达摩院团队使用的实验设置:

数据源[1]:https://huggingface.co/datasets/togethercomputer/Long-Data-Collections
数据源[2]:Together Computer Redpajama: An open source recine to reproduce llama training datasets 2023

测试成绩对比
与 SFT/DPO 方法相比,LongPO 表现出了非常显著的性能提升:
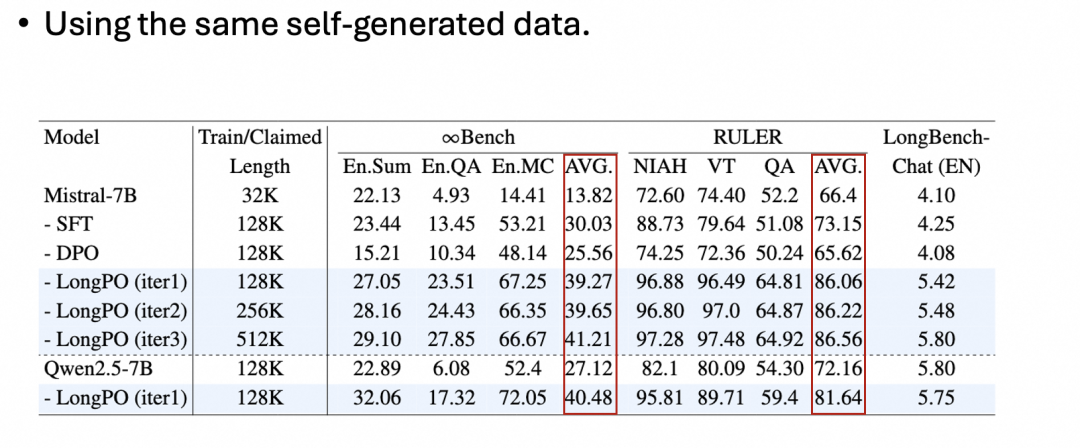
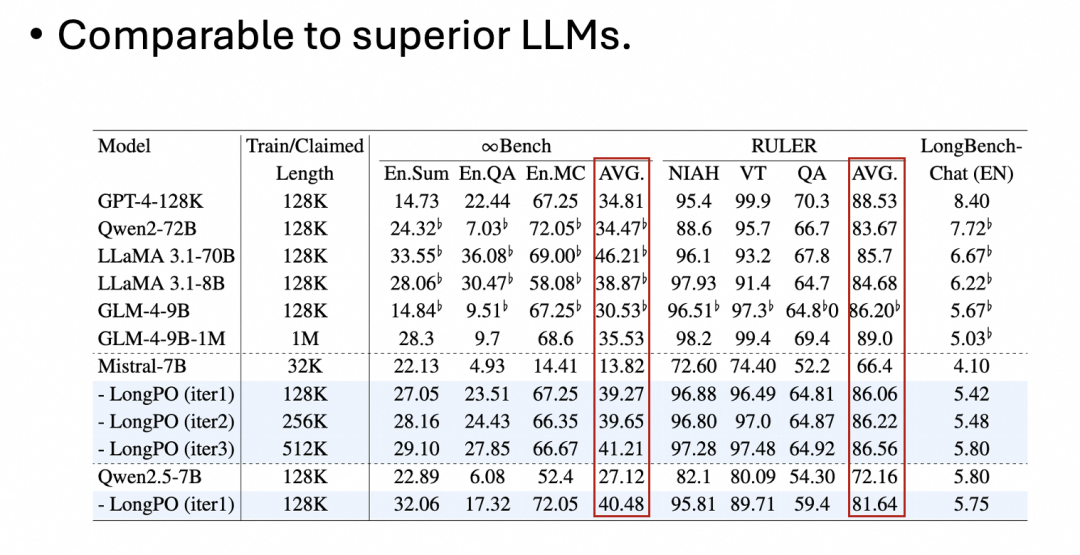
之所以有这样的提升,是因为 LongPO 将 LLM 本身具备的短上下文能力迁移泛化到了长文本上下文上,而不依赖数据集的长文本标注质量。与业内顶尖 LLM 相比,即便不依赖更高质量的数据集,LongPO 也表现出了相近或更好的长文本能力:
使用最新的长文本 Benchmark 测试也得到了类似的结论:
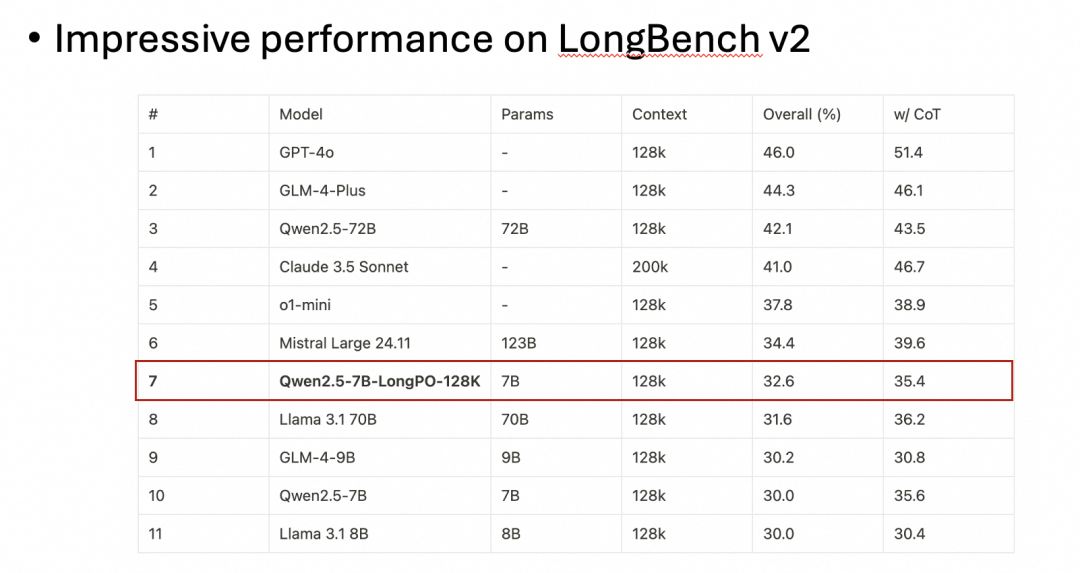
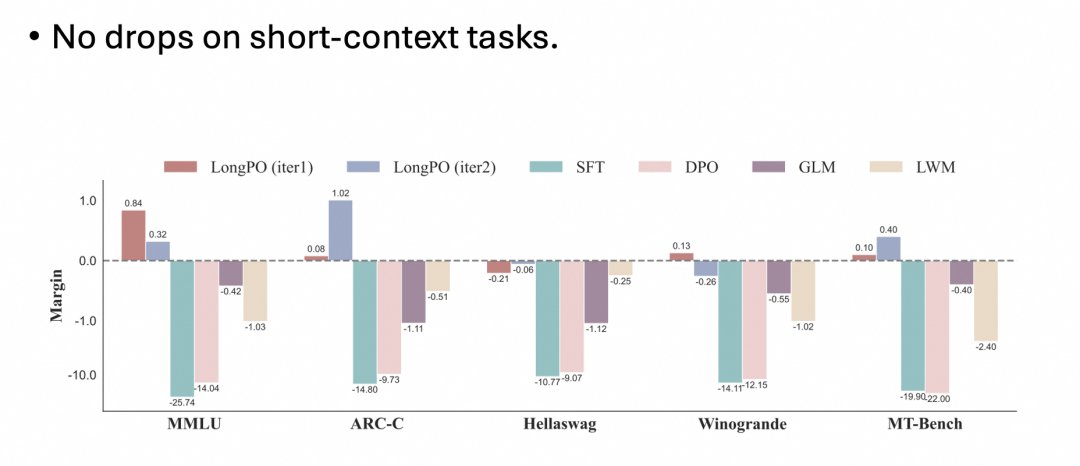
这也表明,目前的主流模型在长文本上下文场景中的能力并没有被充分挖掘,而 LongPO 可以弥补这一差距。此外,对模型短文本能力的测试对比也表明 LongPO 并不会让模型的短文本能力下降:

















 3062
3062

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









