







一、项目背景
随着移动游戏的普及,王者荣耀作为一款现象级手游,拥有庞大的用户群体。许多玩家在游戏中投入了大量时间和金钱,因此账号交易市场也逐渐兴起。为了更好地了解王者账号交易市场的动态,本项目通过爬虫技术采集相关数据,并进行后续的可视化分析。
> 本文章中所有内容仅供学习交流使用,不用于其他任何目的,严禁用于商业用途和非法用途,否则由此产生的一切后果均与作者无关!
二、项目背景
-
市场分析:通过采集和分析王者账号交易数据,可以了解当前市场的价格趋势、热门商品类型、服务特性等信息,为玩家和商家提供参考。
-
数据驱动决策:商家可以根据数据分析结果调整销售策略,玩家也可以通过数据了解市场行情,做出更明智的购买决策。
-
技术实践:通过该项目,可以学习和实践爬虫技术、数据清洗、数据可视化等技能,提升技术能力。
三、环境准备
| 库名称 | 功能描述 |
|---|---|
| requests | 用于发送请求,获取网页数据 |
| csv | 用于将采集到的数据保存为CSV格式,便于后续处理 |
| execjs | 用于执行JavaScript代码,实现对网页请求的逆向分析 |
| json | 用于处理JSON格式的数据 |
| random和time | 用于控制爬虫的请求间隔 |
可以通过以下命令安装所需的Python库:
pip install requests execjs四、采集字段
| 字段名 | 描述 |
|---|---|
| 标题 | 商品标题,通常包含账号的描述信息。 |
| 游戏区服 | 账号所在的游戏区服。 |
| 游戏名 | 游戏名称,这里是“王者荣耀”。 |
| 商品类型 | 账号的类型,如“账号” |
| 价格 | 商品的当前价格。 |
| 原始价格 | 商品的原始价格。 |
| 亮点 | 商品的卖点或特色。 |
| 服务特性 | 如“放心购-可买包赔-花呗分期”等服务。 |
| 浏览数 | 商品的浏览次数。 |
| 热力值 | 商品的热度值。 |
| 发布时间 | 商品的上架时间。 |
| 详情页 | 商品的详情页链接。 |
四、爬虫步骤分析
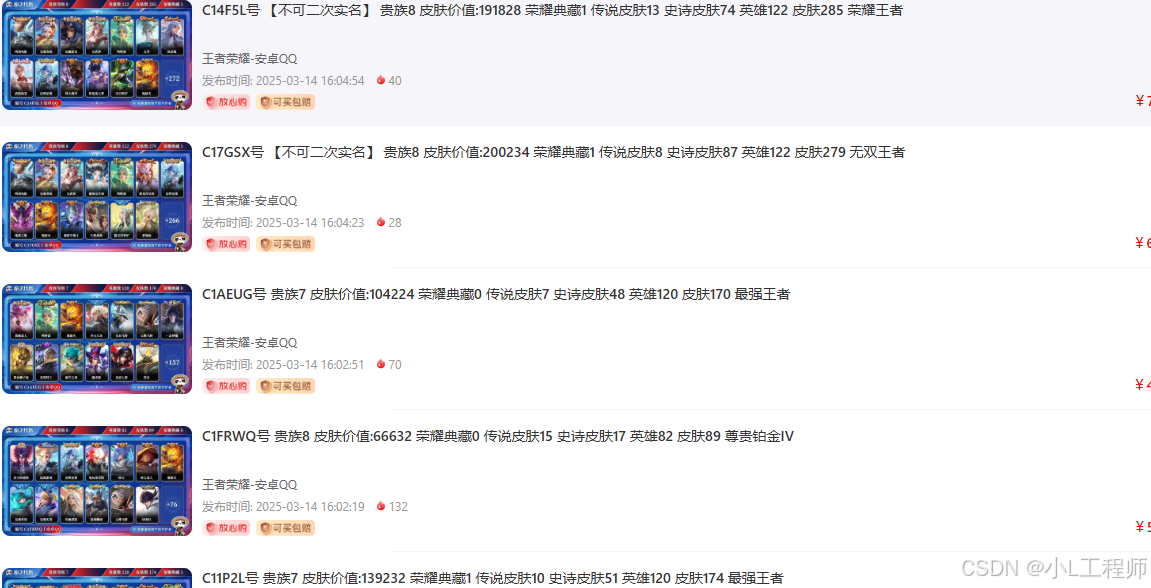
1. 分析目标网站
首先,需要分析数据的请求方式。通过浏览器的开发者工具,可以观察到数据是通过POST请求获取的,且请求头中包含了一些加密参数。

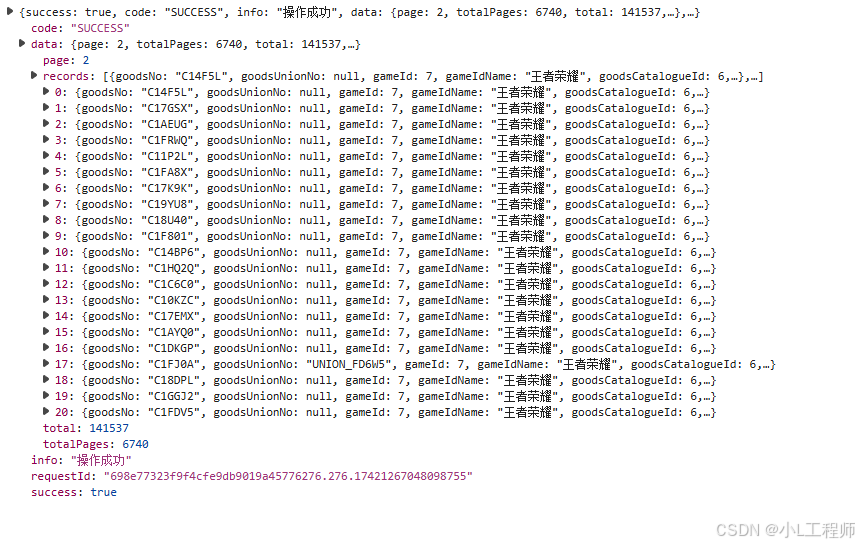
2. 逆向加密参数
-
使用
execjs库加载目标网站的JavaScript代码,通过调用特定的函数生成合法的请求头。这一步是爬虫能够成功获取数据的关键,需要对JavaScript代码进行深入分析和调试。 -
请求头中包含多个重要参数,如
Timestamp、Random、Sign等,这些参数用于验证请求。
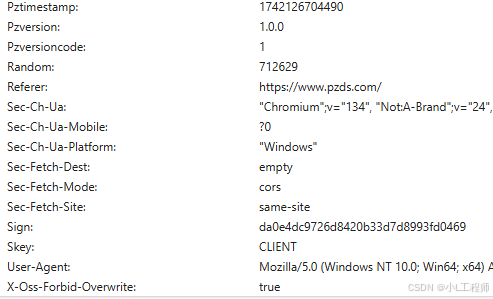
3. 发送请求并解析响应数据
-
使用
requests库发送POST请求,将构造好的请求头和参数传递给目标API接口。 -
获取响应数据后,使用
json库解析JSON格式的数据,提取出我们需要的字段,并将其保存为字典格式。
4. 数据保存
-
使用
csv库将采集到的数据保存为CSV文件,便于后续的数据处理和可视化。 -
在保存数据时,需要注意字段的对应关系和数据的完整性,确保保存的文件能够正确反映采集到的数据。
dic = {
'标题':title,
'游戏区服': simpleMessage,
'游戏名':gameIdName,
'商品类型':goodsCatalogueIdName,
'价格':price,
'原始价格':originalPrice,
'亮点':sellingPointLabels,
'服务特性':Service_,
'浏览数':viewsNum,
'热力值':hots,
'发布时间': onStandTime,
'详情页':url,
}
print(dic)
csv_write.writerow(dic)5. 控制请求频率
为了避免被网站封禁,需要合理控制爬虫的请求频率。在本项目中,我们使用time.sleep函数在每次请求之间随机暂停1到2秒,模拟正常用户的访问行为。
time.sleep(random.uniform(1,2))6. 异常尝试
网络请求可能会因为各种原因失败,例如网络波动、服务器繁忙或请求超时等。为了提高爬虫的稳定性和可靠性,通常会引入异常处理和重试机制。
在本项目中,我们为每个请求设置了异常处理和重试机制,重试次数为3次。具体实现思路如下:
def get_data(page):
"""
数据采集和保存函数
:param page: 采集的页数
:return: 返回值总页数
"""
retry_count = 0
while retry_count < 3:
try:
response = requests.post(url, headers, data)
return totalPages
except Exception as e:
print(f"采集第 {page} 页时发生错误--- 重试第-{retry_count}-次")
retry_count += 1
time.sleep(2)
print(f"采集第 {page} 页失败,跳过该页,继续采集下一页")
return None五、结果展示
本项目通过数据采集之后,获取10多万条数据
六、完整代码
(一)数据采集(爬虫)部分代码
<如果您对源码(爬虫+可视化)感兴趣(不白嫖)迪迦,可以在评论区留言(主页 \/)伪 善,我会根据需求提供指导和帮助>
(二)可视化代码
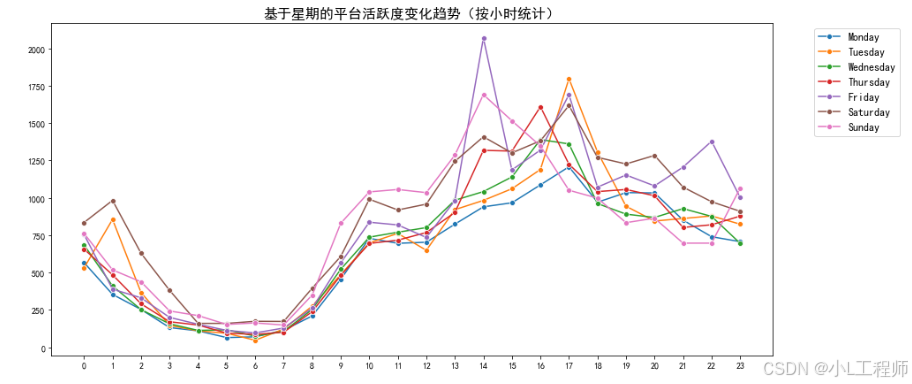
1.基于星期的平台活跃度变化趋势(按小时统计)
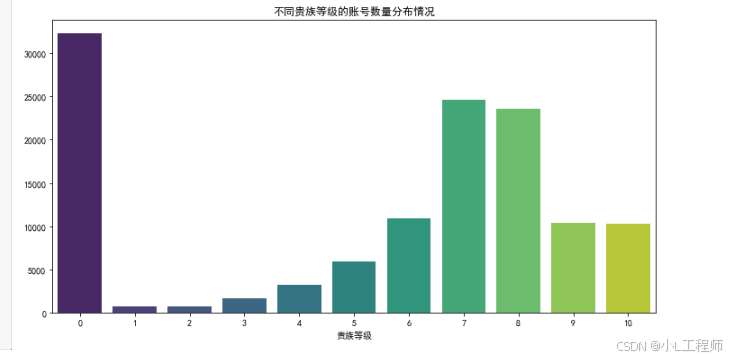
2.不同贵族等级的账号数量分布情况
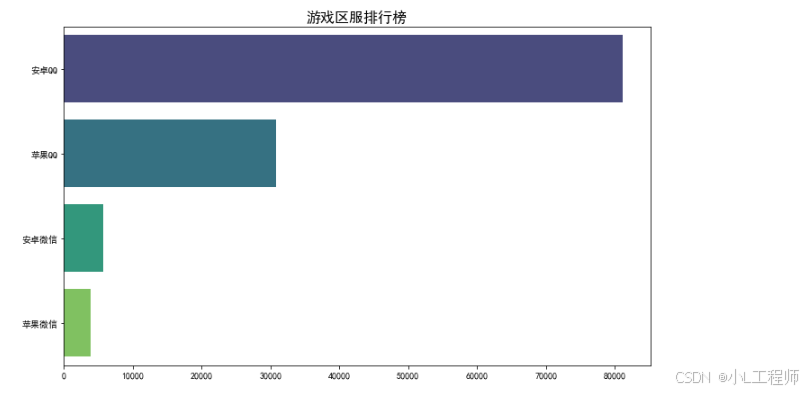
3.游戏区服排行榜
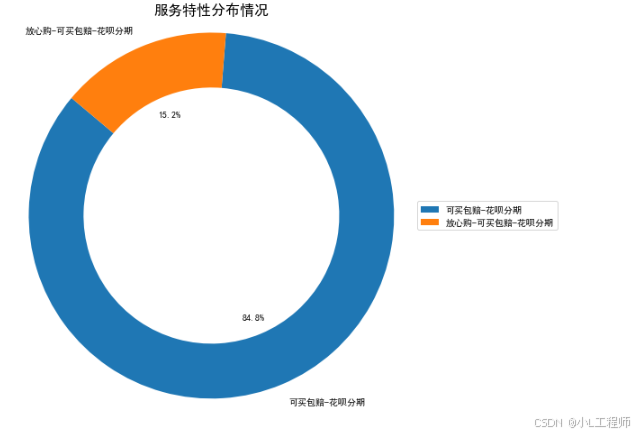
4.服务特性分布情况
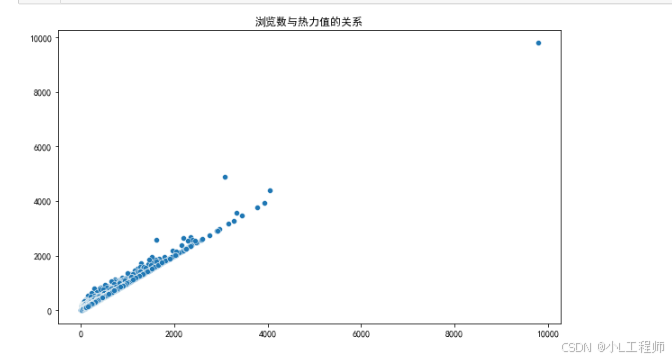
5. 浏览数与热力值的关系
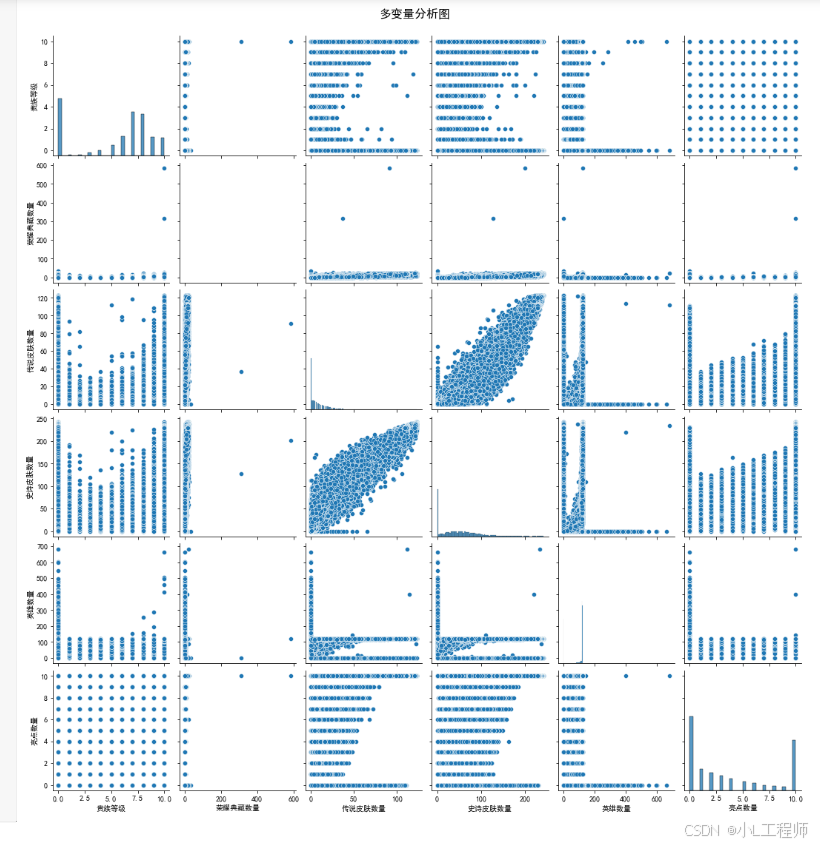
6.多变量分析图
7. 主要可视化代码
#1 基于星期的平台活跃度变化趋势(按小时统计)
hourly_counts = df.groupby(['小时', '周几']).size().reset_index(name='数量')
weekday_order = ['Monday', 'Tuesday', 'Wednesday', 'Thursday', 'Friday', 'Saturday', 'Sunday']
hourly_counts['周几'] = pd.Categorical(hourly_counts['周几'], categories=weekday_order, ordered=True)
hourly_counts = hourly_counts.sort_values(['小时', '周几'])
plt.figure(figsize=(14, 6))
sns.lineplot(data=hourly_counts, x='小时', y='数量', hue='周几', marker='o')
plt.title('基于星期的平台活跃度变化趋势(按小时统计)', fontsize=16)
plt.xlabel('')
plt.ylabel('')
plt.xticks(range(24))
plt.legend(title='', bbox_to_anchor=(1.05, 1), loc='upper left',fontsize=12) # 将图例放在右侧
plt.tight_layout()
plt.show()
#2 不同贵族等级的账号数量分布情况
plt.figure(figsize=(12, 6))
sns.countplot(x='贵族等级', data=df,palette='viridis')
plt.title('不同贵族等级的账号数量分布情况')
plt.xlabel('贵族等级')
plt.ylabel('')
plt.show()
#3 不同贵族等级的账号数量分布情况
game_server_counts = df['游戏区服'].value_counts()[:4]
plt.figure(figsize=(10, 6))
sns.barplot(x=game_server_counts.values, y=game_server_counts.index, palette='viridis')
# 添加标题和标签
plt.title('游戏区服排行榜', fontsize=16)
plt.xlabel('')
plt.ylabel(''
plt.tight_layout()
plt.show()
#4 服务特性分布情况
service_feature_counts = df['服务特性'].value_counts()
plt.figure(figsize=(8, 8)) # 设置图形大小
plt.pie(service_feature_counts, labels=service_feature_counts.index, autopct='%1.1f%%', startangle=140, wedgeprops=dict(width=0.3))
plt.title('服务特性分布情况', fontsize=16)
plt.legend(service_feature_counts.index, title='', loc='center left', bbox_to_anchor=(1, 0, 0.5, 1))
plt.axis('equal')
plt.show()
#5 浏览数与热力值的关系
plt.figure(figsize=(10, 6))
sns.scatterplot(x=df['浏览数'], y=df['热力值'], palette='viridis')
plt.title('浏览数与热力值的关系')
plt.xlabel('')
plt.ylabel('')
plt.show()
#6 多变量分析图
numerical_columns = ['贵族等级', '荣耀典藏数量', '传说皮肤数量', '史诗皮肤数量', '英雄数量', '亮点数量']
df_numerical = df[numerical_columns]
sns.pairplot(df_numerical)
plt.suptitle('多变量分析图', y=1.02, fontsize=16)
plt.show()

















 1563
1563

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









