







一、项目背景
随着电子商务的快速发展,快递行业成为了现代物流的重要组成部分。快递网点的分布和服务质量直接影响到用户的物流体验。为了更好地了解快递网点的分布情况、服务范围以及联系方式等信息,本项目通过爬虫技术从公开的快递信息网站上采集相关数据。‘
> 本文章中所有内容仅供学习交流使用,不用于其他任何目的,严禁用于商业用途和非法用途,否则由此产生的一切后果均与作者无关!
二、项目目的和意义
本项目的主要目的是通过爬虫技术,采集全国各大城市的快递网点信息,包括网点的名称、地址、联系电话、配送范围等。这些数据可以用于:
-
物流行业分析:通过分析快递网点的分布情况,了解各地区的物流覆盖情况。
-
用户服务优化:通过分析网点的服务范围和联系方式,帮助用户更好地选择快递服务。
-
数据支持:为物流公司、电商平台等提供数据支持,帮助他们优化物流网络布局。
三、环境准备
在开始项目之前,需要准备以下环境和工具:
-
Python 3.x:本项目使用Python编写,确保已安装Python 3.x版本。
-
第三方库:需要安装以下Python库:
-
requests:用于发送HTTP请求。 -
parsel:用于解析HTML文档。 -
csv:用于将数据保存为CSV文件。 -
re:用于正则表达式匹配。 -
random:用于随机选择User-Agent。 -
time:用于控制爬虫的请求频率。
-
可以通过以下命令安装所需的库:
pip install requests parsel四、采集字段介绍
| 字段名 | 描述 | 示例 |
|---|---|---|
| 物流名称 | 快递网点的名称 | 顺丰速运 |
| 标题 | 快递网点的标题信息 | 顺丰速运广州天河区网点 |
| 省份 | 快递网点所在的省份 | 广东省 |
| 城市 | 快递网点所在的城市 | 广州市 |
| 区 | 快递网点所在的区 | 天河区 |
| 公司地址 | 快递网点的详细地址 | 广州市天河区天河路123号 |
| 联系电话 | 快递网点的联系电话, 通常为固定电话或手机号码 | xxx-xxxxxx |
| 配送范围 | 快递网点的配送范围 | 天河区、越秀区、海珠区 |
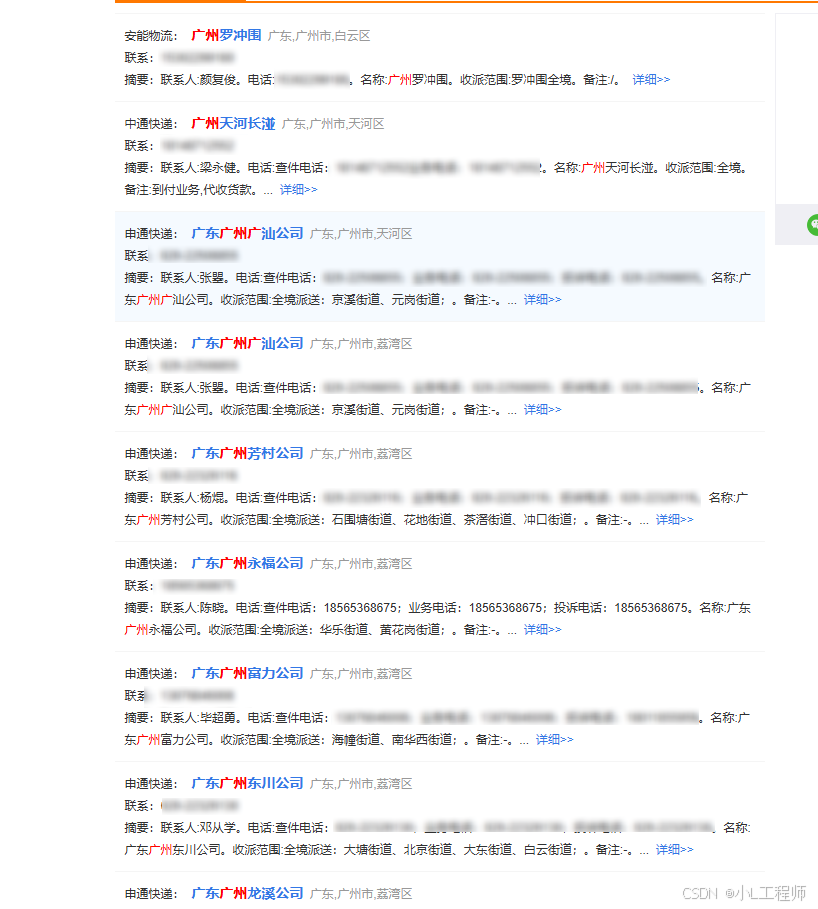
五、爬虫步骤分析
--------------------------要想提高采集效率,建议用scrapy框架进行采集----------------------------------------
-----------------------这个项目对采集速率过快的会进行封ip,proxy也得用上---------------------------------
1. 获取User-Agent列表
为了避免被网站反爬虫机制识别,项目使用随机的User-Agent来发送请求。ua_list()函数返回一个包含多个User-Agent的列表,每次请求时随机选择一个User-Agent。
def ua_list():
ua = [
'Mozilla/4.0 (compatible; MSIE 7.0; Windows NT 5.1; Trident/4.0; Hot Lingo 2.0)',
'Mozilla/5.0 (Windows NT 6.2; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/60.0.3112.90 Safari/537.36',
# 更多User-Agent...
]
return ua2. 获取省份与地区代码的映射
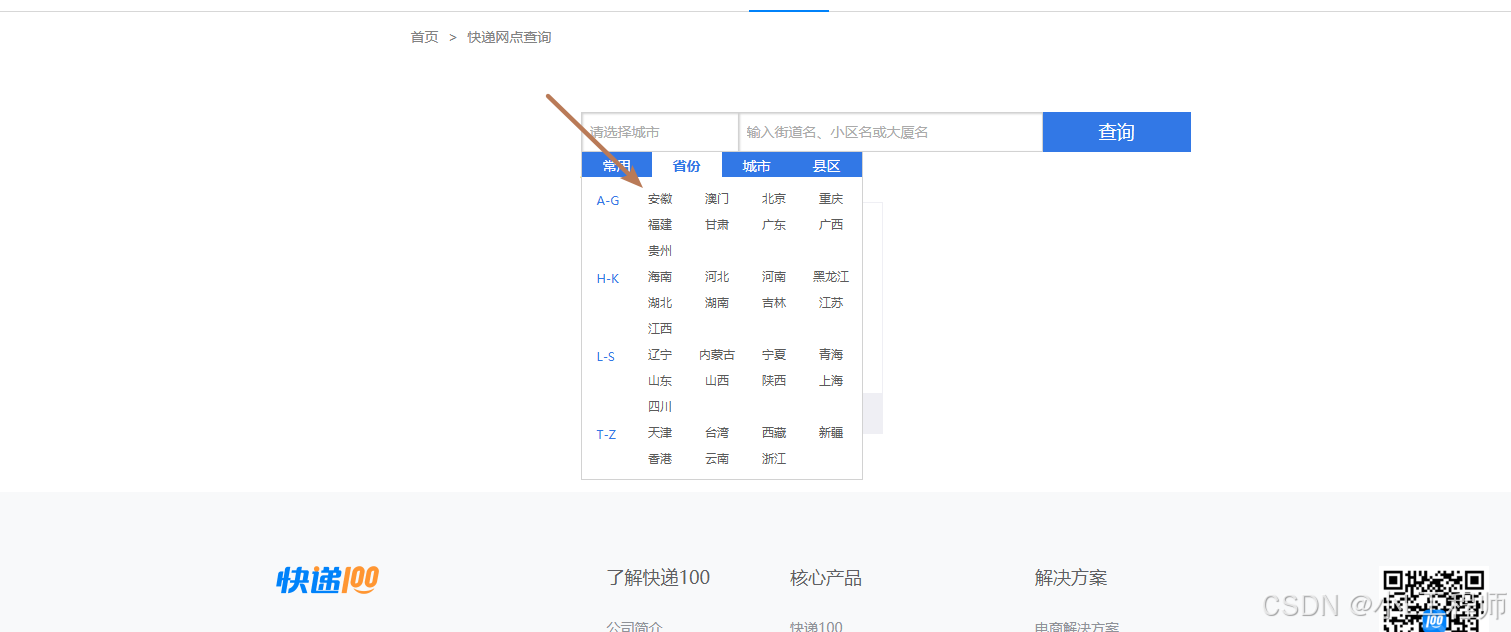
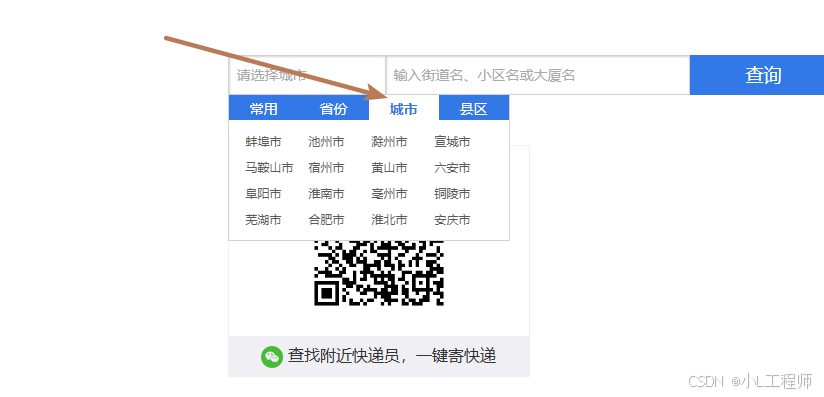
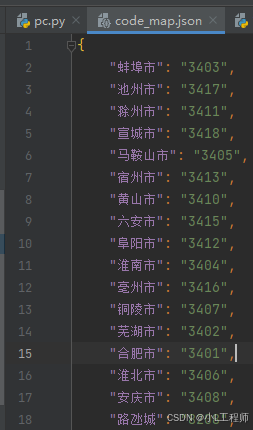
通过解析网页中的HTML代码,项目可以获取到每个省份对应的地区代码。get_region_mapping()函数通过解析HTML代码,生成一个省份与地区代码的映射字典。这部分可以通过selenium自动化点击操作采集所有城市的region_code映射。类似点一下--安徽,就会跳到城市显示安徽所有的城市,然后进行采集
3. 获取总页数
通过发送请求并解析返回的HTML文档,项目可以获取到每个地区的快递网点总页数。get_total_page()函数通过解析页面中的分页信息,计算出总页数。
def get_total_page(region_code):
headers = {
"Accept-Language": "zh-CN,zh;q=0.9",
"Connection": "keep-alive",
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/134.0.0.0 Safari/537.36",
}
url = f"https://www.kuaidi100.com/network/net_{region_code}_all_all_1.htm"
response = requests.get(url, headers=headers)
parsel_text = parsel.Selector(response.text)
as_label = parsel_text.xpath('//div[@class="select-box"]/dl/dd[1]/a')
counts = 0
for a in as_label[1:]:
num_ = a.xpath('./text()').get()
num = re.findall(r'\d+', num_, re.S)[0]
counts += int(num)
page_total = counts // 10 + (counts % 10 != 0)
return page_total4. 详情页解析
通过解析详情页的HTML文档,可以获取到每个快递网点的详细信息。info_url_parsel()函数负责解析详情页,并返回一个包含网点信息的字典。
def info_url_parsel(url):
headers = {
"Accept-Language": "zh-CN,zh;q=0.9",
"Connection": "keep-alive",
"User-Agent": random.choice(ua_list()),
}
response = requests.get(url, headers=headers)
parsel_text = parsel.Selector(response.text)
dic = {
'标题': title,
'省份': province,
'城市': city,
'区': district,
'公司地址': add,
'联系电话': phone,
'配送范围': range_,
}
return dic
5. 单页数据解析和保存
parsel_data()函数负责解析单页的快递网点列表,并调用info_url_parsel()函数获取每个网点的详细信息,最后将数据保存到CSV文件中。(有个别城市的数据在翻页的时候有问题,可以使用异try-except捕获,避免程序报错)
def parsel_data(region_code, page):
headers = {
"Accept-Language": "zh-CN,zh;q=0.9",
"Connection": "keep-alive",
"User-Agent": random.choice(ua_list()),
}
url = f"https://www.kuaidi100.com/network/net_{region_code}_all_all_{page}.htm"
response = requests.get(url, headers=headers)
parsel_text = parsel.Selector(response.text)
divs = parsel_text.xpath('//div[@class="col_1 mt10px"]/div')
for div in divs[:-1]:
name = div.xpath('./div/p[1]/span/text()').get()
name = name.strip().replace(':', '') # 物流名称
url = div.xpath('./div/p[1]/a/@href').get()
dic = info_url_parsel(url)
dic['物流名称'] = name
print(dic)
csv_write.writerow(dic)
time.sleep(random.uniform(0.8,1.5))6. 数据保存
本项目使用csv.DictWriter将采集到的数据保存到CSV文件中。需要保存到数据库的,则编写插入数据库语法即可。
if __name__ == '__main__':
f = open('快递网点.csv', mode='w', encoding='utf-8', newline='')
csv_write = csv.DictWriter(f, [
'物流名称',
'标题',
'省份',
'城市',
'区',
'公司地址',
'联系电话',
'配送范围',
])
csv_write.writeheader()
main()
print('采集结束')
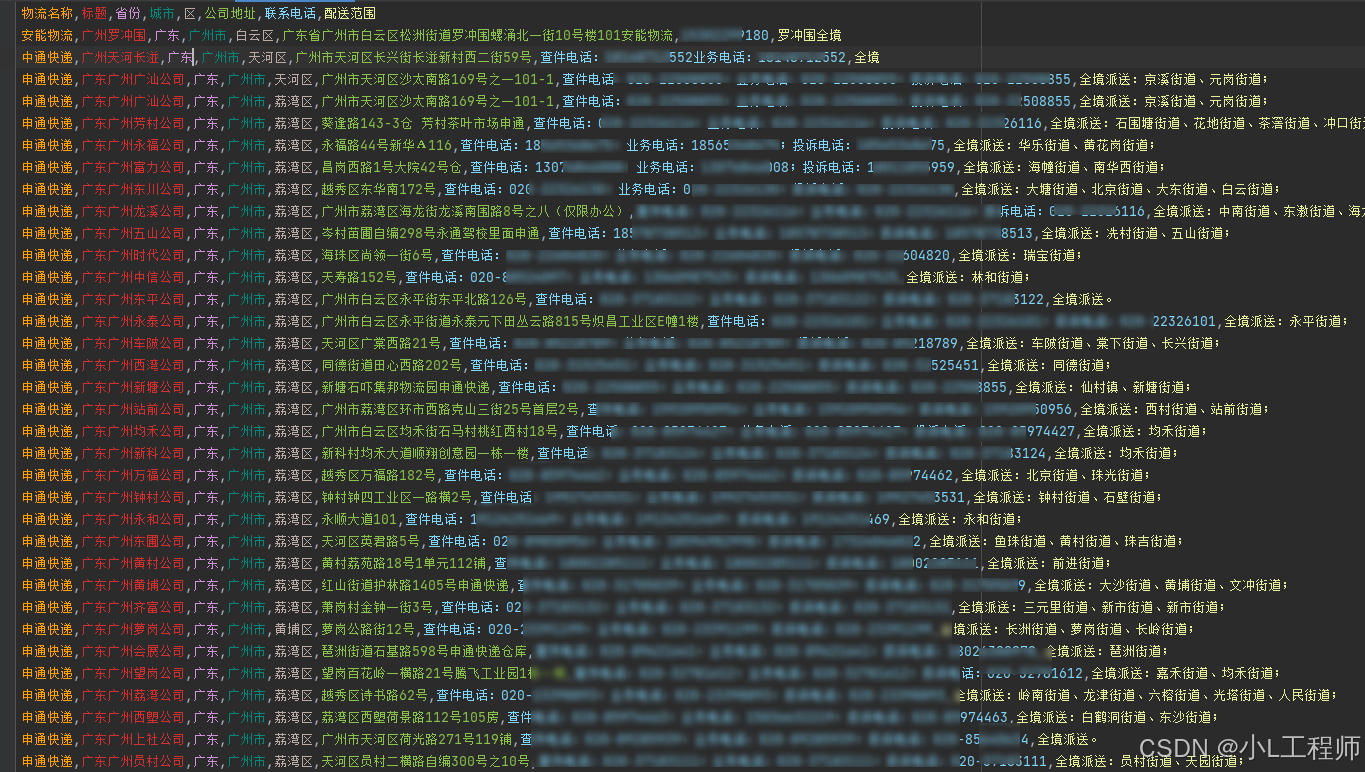
f.close()六、结果展示



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









