




一、项目背景
随着互联网的快速发展,电影评论成为了观众表达观影感受的重要途径。豆瓣作为中国最大的电影评分和评论平台之一,积累了大量的用户评论数据。这些数据不仅反映了观众对电影的评价,还可以通过数据分析挖掘出用户的观影习惯、地域分布、评分偏好等信息。本项目以电影《哪吒2》为例,通过爬虫技术采集豆瓣电影评论数据,并结合可视化工具对数据进行深入分析,旨在为电影制作方、市场营销人员以及普通观众提供有价值的参考。
> 本文章中所有内容仅供学习交流使用,不用于其他任何目的,严禁用于商业用途和非法用途,否则由此产生的一切后果均与作者无关!
更新时间:2025-6-29
可用版本:selenium版本、普通爬虫版本
二、目的和意义
-
数据采集:通过爬虫技术获取豆瓣电影《哪吒2》的用户评论数据,包括用户名、观看状态、评分、发布时间、地区、有用数、评论内容等字段。
-
数据分析:对采集到的数据进行清洗、整理和分析,挖掘用户的观影行为、地域分布、评分偏好等信息。
-
可视化展示:通过图表、地图、词云等形式直观展示分析结果,帮助用户更好地理解数据背后的信息
三、前期准备
1. 环境配置
-
Python版本:3.7及以上
-
依赖库:
-
selenium:用于网页自动化操作。 -
pandas:用于数据处理和分析。 -
matplotlib、seaborn:用于数据可视化。 -
wordcloud:用于生成词云。 -
pyecharts:用于生成交互式地图。 -
jieba:用于中文分词。
-
可以通过以下命令安装所需的Python库:
pip install selenium pandas matplotlib seaborn wordcloud jieba2. 采集方式
| 采集方式 | Selenium控制浏览器 | 逆向登录(会话维持) | 手动添加Cookie字段(Requests抓包) |
|---|---|---|---|
| 实现难度 | 中等 | 高 | 低 |
| 技术门槛 | 需要掌握Selenium和浏览器驱动配置 | 需要掌握逆向工程、验证码破解、会话维持等技术 | 需要掌握HTTP请求、Cookie管理和Requests库 |
| 采集效率 | 较低(受浏览器渲染和页面加载速度限制) | 高(直接通过API或接口获取数据) | 高(直接通过API或接口获取数据) |
| 稳定性 | 较高(模拟真实用户行为,不易被封禁) | 中等(依赖会话维持,可能因验证码或IP封禁失效) | 低(Cookie可能失效,需频繁更新) |
| 反爬虫对抗能力 | 较强(模拟真实用户行为,绕过简单反爬虫机制) | 中等(需破解验证码和动态加密参数) | 弱(容易被封禁,依赖Cookie时效性) |
| 维护成本 | 较高(需维护浏览器驱动和页面结构变化) | 高(需持续破解验证码和更新加密逻辑) | 中等(需定期更新Cookie) |
| 适用场景 | 适合动态加载、JavaScript渲染的页面 | 适合需要登录且验证码复杂的网站 | 适合简单接口或无验证码的网站 |
| 痛点 | - 浏览器资源占用高 - 采集速度慢 - 页面结构变化需频繁调整代码 | - 验证码破解难度大 - 会话维持复杂 - 动态加密参数需频繁更新 | - Cookie时效性短 - 容易被封禁 - 需手动更新Cookie |
| 优点 | - 模拟真实用户行为 - 绕过简单反爬虫机制 - 适合复杂页面 | - 采集效率高 - 直接获取数据 - 适合大规模数据采集 | - 实现简单 - 采集效率高 - 适合小规模数据采集 |
| 缺点 | - 采集速度慢 - 资源消耗大 - 依赖浏览器驱动 | - 技术门槛高 - 维护成本高 - 容易被封禁 | - 稳定性差 - 依赖Cookie时效性 - 容易被封禁 |
综上所述,在本次《哪吒2》评论数据采集项目中,我选择使用 Selenium 接管浏览器 的方式,因为这种方式可以快速复用已登录的浏览器状态,无需重新登录,调试效率高且代码实现简单。
3. 目标网页结构分析
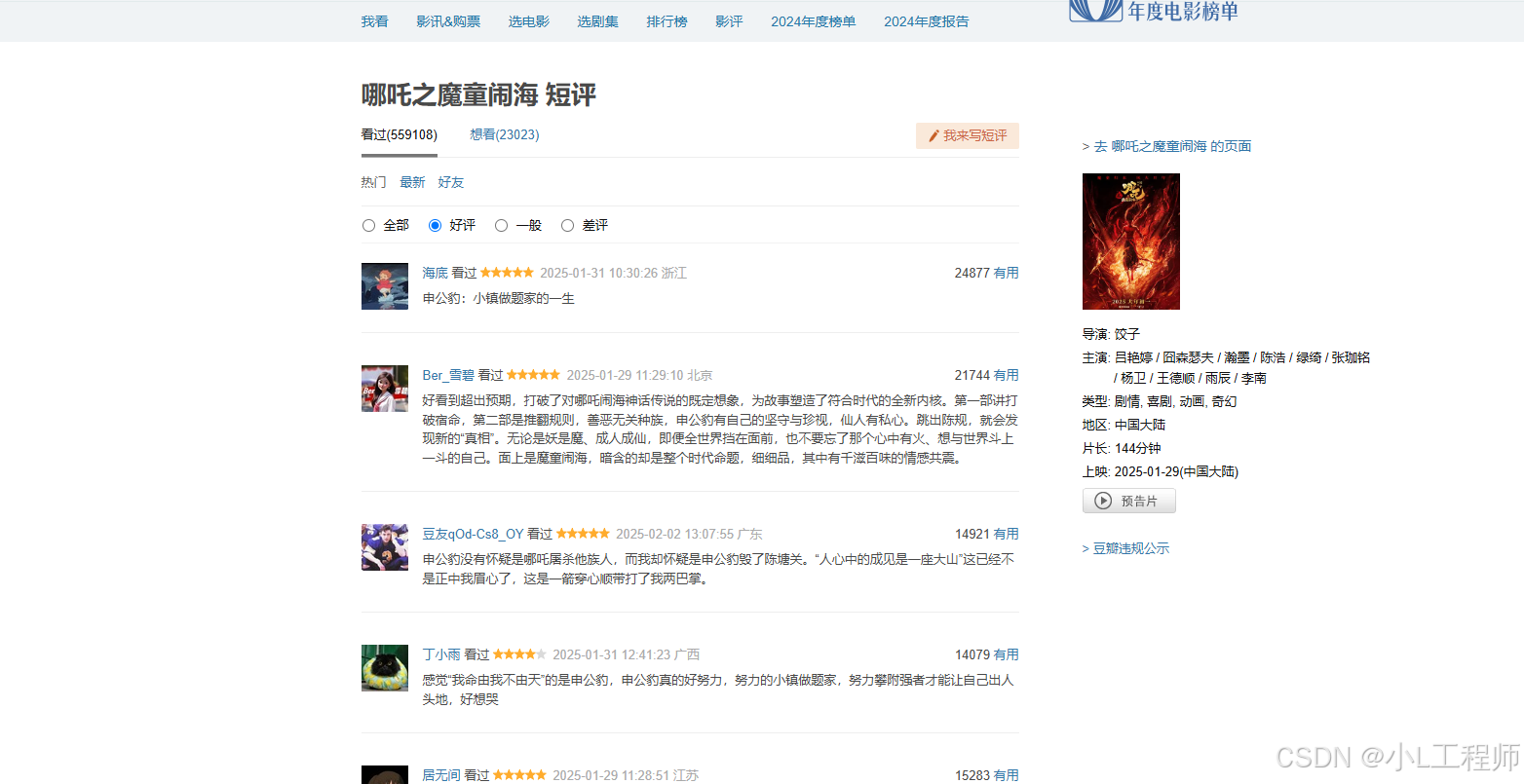
目标网页:哪吒2评论
页面的结构相对简单,评论信息主要包含在div.comment-item标签中。每个评论项包含用户名、评分、评论内容等信息。通过分析网页结构,我们可以使用直接定位这些元素并提取所需数据。
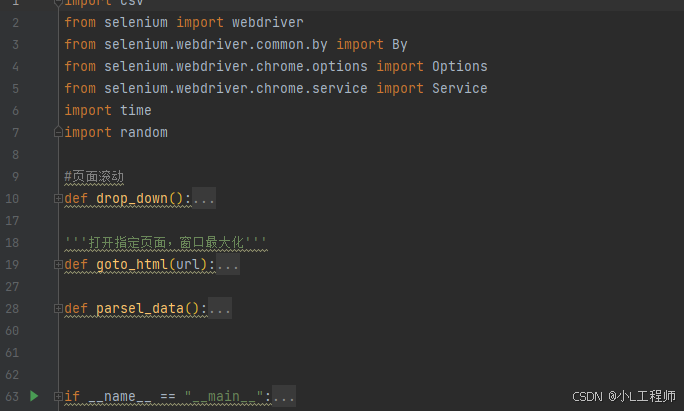
四、爬虫步骤
1. 初始化Selenium
使用Selenium模拟浏览器操作,首先需要初始化浏览器驱动:
from selenium import webdriver
from selenium.webdriver.chrome.options import Options
from selenium.webdriver.chrome.service import Service
options = Options()
options.add_experimental_option("debuggerAddress", "127.0.0.1:9527") # 连接已打开的浏览器
service = Service(executable_path="path/to/chromedriver") # 替换为chromedriver的实际路径
driver = webdriver.Chrome(options=options, service=service)2. 页面滚动与数据加载
为了加载完整的评论数据,需要模拟页面滚动操作:
def drop_down():
for x in range(1, 10, 3):
time.sleep(random.uniform(0.6, 0.9))
j = x / 9
js = 'document.documentElement.scrollTop = document.documentElement.scrollHeight * %f' % j
driver.execute_script(js)3. 数据采集
通过Selenium提取页面中的评论数据,并存储到CSV文件中:
def parse_data():
divs = driver.find_elements(By.CSS_SELECTOR, 'div.comment-item')
for div in divs:
user_name = div.find_element(By.CSS_SELECTOR, '.comment-info>a').text
watched_status = div.find_element(By.CSS_SELECTOR, '.comment-info>span').text
comment_time = div.find_element(By.CSS_SELECTOR, '.comment-time').text.strip()
score_characters = div.find_element(By.CSS_SELECTOR, '.comment-info>span:nth-child(3)').get_attribute('title')
score = score_map.get(score_characters)
region = div.find_element(By.CSS_SELECTOR, '.comment-location').text
vote_count = div.find_element(By.CSS_SELECTOR, '.votes.vote-count').text
comment_content = div.find_element(By.CSS_SELECTOR, '.short').text
data = {
'用户名': user_name,
'观看状态': watched_status,
'评分': score,
'发布时间': comment_time,
'地区': region,
'有用数': vote_count,
'评论内容': comment_content,
}
csv_writer.writerow(data)4. 翻页
通过点击后页实现翻页,不能点击则是最后一页
5. 结果展示
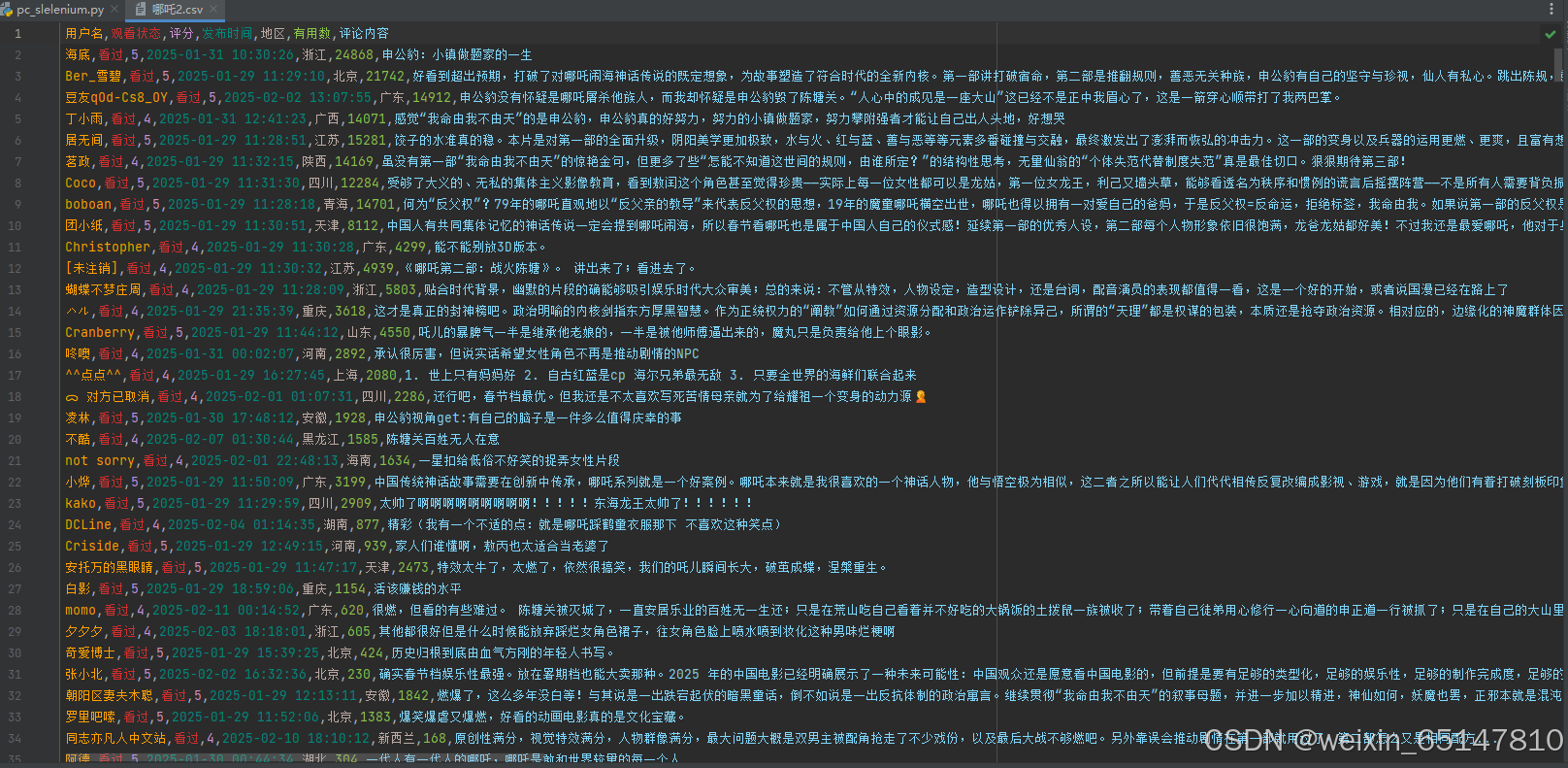
五、完整代码
(一)数据采集(爬虫)部分代码
<如果您对源码(爬虫+可视化)感兴趣(不白嫖)迪迦,可以在评论区留言(主页 \/)伪善,我会根据需求提供指导和帮助>
(二)可视化代码
1.评论数量中国各省份分布情况

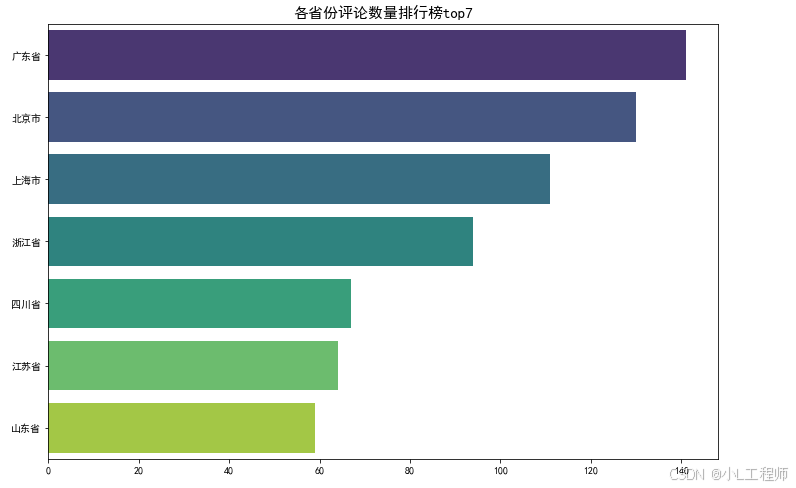
2.评论数量排行榜top7
3. 基于星期的用户活跃度变化趋势(按小时统计)

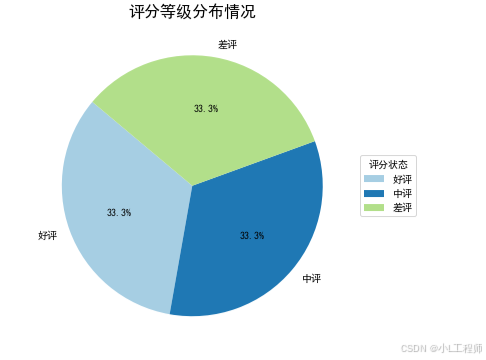
4. 客户评分等级分布情况
5. 评论词云图

6. 可视化代码
#1.评论数量中国分布情况
from pyecharts.charts import Map
from pyecharts import options as opts
region_counts = df['地区1'].value_counts().reset_index()
region_counts.columns = ['地区', '评论数量']
data_pair = [(row['地区'], row['评论数量']) for index, row in region_counts.iterrows()]
map_chart = (
Map()
.add("", data_pair, maptype="china", is_map_symbol_show=False) # 不显示标记点
.set_series_opts(label_opts=opts.LabelOpts(font_size=7)) # 调节省份字体大小
.set_global_opts(
title_opts=opts.TitleOpts(title="评论数量中国分布情况"),
visualmap_opts=opts.VisualMapOpts(
is_piecewise=True, # 分段映射
pieces=[
{"max": 49, "label": "50以下", "color": "#E0FFD8"},
{"min": 50, "max": 100, "label": "50-100", "color": "#C0FFC0"},
{"min": 101, "label": "100以上", "color": "#326632"}
]
)
)
)
map_chart.render_notebook()
#2 评论数量排行榜top7
region_top7 = region_counts[:7
plt.figure(figsize=(12,8))
sns.barplot(data=region_top7,y='地区',x='评论数量', palette="viridis")
plt.title('各省份评论数量排行榜top7',fontsize=15)
plt.xlabel('')
plt.ylabel('')
plt.show()
#3 基于星期的用户活跃度变化趋势(按小时统计)
result = df.groupby(["周几", "小时"]).size().reset_index(name="评论数量")
plt.figure(figsize=(12, 6))
sns.lineplot(data=result, x="小时", y="评论数量", hue="周几", marker="o")
plt.title("基于星期的用户活跃度变化趋势(按小时统计)", fontsize=16, fontweight="bold")
plt.xlabel("", fontsize=12)
plt.ylabel("", fontsize=12)
plt.xticks(range(24))
plt.legend(title="", bbox_to_anchor=(1.05, 1), loc="upper left") #将图例放在右侧
plt.grid(True, linestyle="--", alpha=0.5)
plt.tight_layout() #自动调整布局
plt.show()
#4 客户评分等级分布情况
status_counts = df['评分等级'].value_counts(
plt.figure(figsize=(12, 6))
plt.pie(status_counts, labels=status_counts.index, autopct='%1.1f%%', startangle=140,
colors=plt.cm.Paired.colors[:len(status_counts)])
plt.title('评分等级分布情况', fontsize=16, fontweight='bold')
plt.legend(title='评分状态',loc='center left', bbox_to_anchor=(1, 0.5))
plt.show()
#5评论词云图
from wordcloud import WordCloud
from wordcloud.wordcloud import STOPWORDS
import re
import jieba
stopwords = set(STOPWORDS)
custom_stopwords = {"的", "和", "是", "了", "在", "有", "不",
"我", "你", "他", "它", "很", "都", "很", "这",
"那",'这个','还','还是','电影','一个','就是','自己',
'没有','什么','不是','真的','最后','这种','看到',
'但是','可以','觉得'}
stopwords.update(custom_stopwords)
all_text = ''
for text in df['评论内容']:
text = re.sub(r'[^\w\s]', '', text)
words = jieba.cut(text)
filtered_words = [word for word in words if word not in stopwords and len(word) > 1]
all_text += " ".join(filtered_words) + " "
wordcloud = WordCloud(
font_path="simhei.ttf", #字体
background_color="white", #背景颜色
width=800, # 宽度
height=600, # 高度
max_words=200, # 最大显示词汇数
stopwords=stopwords # 停用词
).generate(all_text)
plt.figure(figsize=(10, 8))
plt.imshow(wordcloud, interpolation="bilinear")
plt.axis("off") # 关闭坐标轴
plt.title("")
plt.show()

















 1258
1258

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









