




在爬取网页数据时,我们经常会遇到一些网站为了防止数据被爬取,采用字体加密的方式来隐藏关键信息。猫眼电影票房数据就是其中的一个典型例子。本文将详细介绍如何通过Python代码破解猫眼票房数据中的加密字体,获取真实的票房数字。
> 本文章中所有内容仅供学习交流使用,不用于其他任何目的,严禁用于商业用途和非法用途,否则由此产生的一切后果均与作者无关!
1. 什么是字体反爬?
字体反爬是指网站使用自定义字体来渲染页面上的关键数据,使得爬虫无法直接获取正确的文本内容。通常,这些字体文件会动态生成,并且每个字符的映射关系也会不断变化。因此,爬虫需要解析这些字体文件,才能正确获取页面上的数据。
2. 环境准备
在本案例需要用到以下Python库:
-
requests:用于发送HTTP请求。 -
fontTools:用于解析字体文件。 -
re(内置库):用于正则表达式操作。 -
html(内置库):用于处理HTML转义字符。
pip install requests fontTools3. 破解字体反爬的基本思路
破解字体反爬的基本思路如下:
-
获取目标数据:发送请求获取页面或接口数据。
-
提取字体文件URL:从页面或接口数据中提取字体文件的URL。
-
下载字体文件:下载字体文件到本地。
-
解析字体文件:使用字体解析工具解析字体文件,获取字符映射关系。
-
构建映射规则:根据解析结果,手动构建字符到实际数字或字母的映射规则。
-
解码数据:使用映射规则将加密字符解码为实际数据。
4. 本案例实现步骤
(1)第一步:获取猫眼票房数据的JSON接口
猫眼票房数据通常是通过API接口动态加载的。我们需要找到这个接口,并通过requests库发送HTTP请求获取数据。
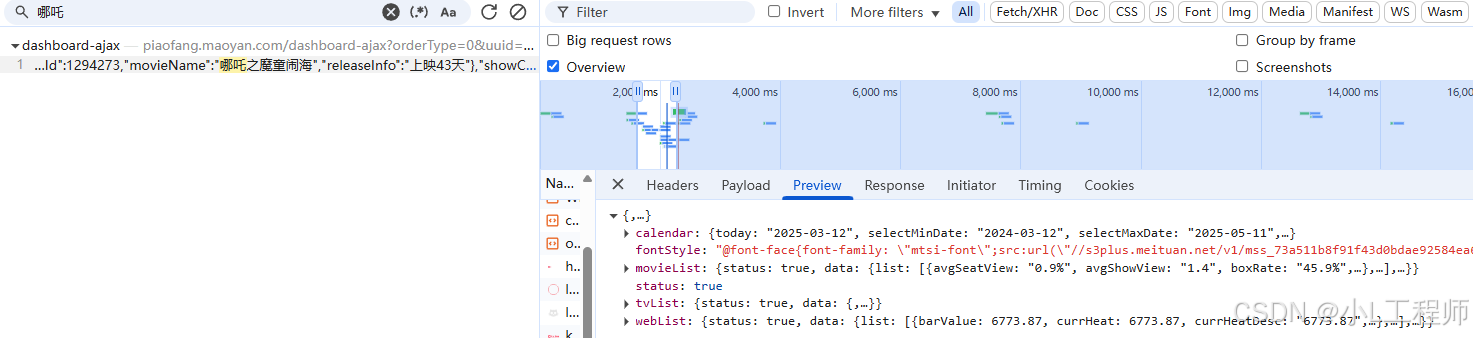
(2)第二步:提取字体文件链接,并下载字体
字体文件通过在在网页的 font-family 的标签中
但在本项目中,字体文件的在返回的json数据的 fontStyle 标签中。通过发包获取json数据,然后提取fontStyle的内容,再通过正则进行提取拼接 字体文件的链接即可。主要代码如下:
fontStyle = json_data['fontStyle']
pattern = r'embedded-opentype.*url\(\"(.*?)\.woff\"\)'
match = re.search(pattern, fontStyle)
result = match.group(1) + ".woff"
font_url = 'https:' + result
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/91.0.4472.124 Safari/537.36'
}
response1 = requests.get(font_url, headers=headers,stream=True)
with open('font.woff', 'wb') as f:
f.write(response1.content)(3)第三步:解析字体文件
-
fontTools库:使用
TTFont类解析字体文件 -
字符映射:通过
getBestCmap方法获取Unicode码与实际字符的映射关系 -
手动构建映射规则: 根据解析结果,手动构建字符到实际数字的映射规则。
--------------------------根据已知的信息,了解到该项目的字体加密有5套----------------------


本项目中,读取字体输出的映射规则 类似 58335: 'uniE3DF'
58335-----加密字体的unicode编码下的码点值
uniE3DF --- 字体文件中看到的上标
7 ---- (字体文件打开 上标为uniE3DF 的值)--实际的值
需要构建的就是 通过先对加密字体还原对于的字符(html.unescape),然后读取码点值(ord()),通过码点值(58335)+读取字体的映射规则来映射出 字体文件的上标(uniE3DF),接着通过手动构建的映射规助来映射具(7)
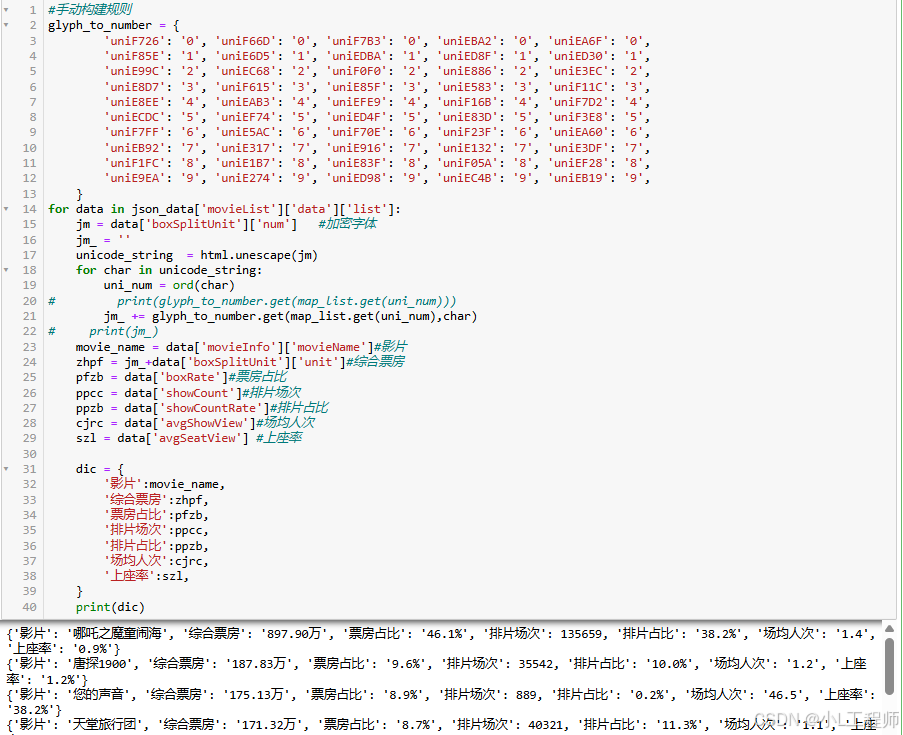
5. 完整代码
import requests
from fontTools.ttLib import TTFont
import html
import re
import os
import warnings
warnings.filterwarnings("ignore", message="2 extra bytes in post.stringData array")
def fetch_json_data(showDate_):
"""
发送请求获取猫眼实时票房的JSON数据。
参数:
showDate_ (str): 查询日期,格式为YYYYMMDD。 比如 showDate="20250312"
返回:
dict: 返回的JSON数据。
"""
headers = {
"Accept": "application/json, text/plain, */*",
"Accept-Language": "en-US,en;q=0.9,zh-CN;q=0.8,zh;q=0.7",
"Cache-Control": "no-cache",
"Connection": "keep-alive",
"Referer": "https://piaofang.maoyan.com/dashboard",
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/133.0.0.0 Safari/537.36",
}
url = "https://piaofang.maoyan.com/dashboard-ajax"
params = {
"showDate": showDate_,
"orderType": "0",
"uuid": "191a1418cebc8-099b06863d1e18-26001151-144000-191a1418cebc8",
"timeStamp": "1741682694759",
"User-Agent": "TW9aWxsYS81LjAgKFdpbmRvd3MgTlQgMTAuMDsgV2luNjQ7IHg2NCkgQXBwbGVXZWJLaXQvNTM3LjM2IChLSFRNTCwgbGlrZSBHZWNrbykgQ2hyb21lLzEzMy4wLjAuMCBTYWZhcmkvNTM3LjM2",
"index": "23",
"channelId": "40009",
"sVersion": "2",
"signKey": "d001a3899eccaa8ef3ae0f123c074516",
"WuKongReady": "h5"
}
response = requests.get(url, headers=headers, params=params)
json_data = response.json()
return json_data
def decode_data(font_url, encoded_box_office, save_path="font.woff"):
"""
破解加密字体函数
参数:
font_url (str): 字体文件的URL。
encoded_box_office (str): 加密的字体
save_path (str): 字体文件保存路径,默认为当前目录下的font.woff。
"""
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/91.0.4472.124 Safari/537.36'
}
response = requests.get(font_url, headers=headers, stream=True)
with open(save_path, 'wb') as f:
f.write(response.content)
'''字体解密'''
base_font = TTFont(save_path) #读取字体文件
map_list = base_font.getBestCmap() # 字体文件映射规则
#手动构建规则
glyph_to_number = {
'uniF726': '0', 'uniF66D': '0', 'uniF7B3': '0', 'uniEBA2': '0', 'uniEA6F': '0',
'uniF85E': '1', 'uniE6D5': '1', 'uniEDBA': '1', 'uniED8F': '1', 'uniED30': '1',
'uniE99C': '2', 'uniEC68': '2', 'uniF0F0': '2', 'uniE886': '2', 'uniE3EC': '2',
'uniE8D7': '3', 'uniF615': '3', 'uniE85F': '3', 'uniE583': '3', 'uniF11C': '3',
'uniE8EE': '4', 'uniEAB3': '4', 'uniEFE9': '4', 'uniF16B': '4', 'uniF7D2': '4',
'uniECDC': '5', 'uniEF74': '5', 'uniED4F': '5', 'uniE83D': '5', 'uniF3E8': '5',
'uniF7FF': '6', 'uniE5AC': '6', 'uniF70E': '6', 'uniF23F': '6', 'uniEA60': '6',
'uniEB92': '7', 'uniE317': '7', 'uniE916': '7', 'uniE132': '7', 'uniE3DF': '7',
'uniF1FC': '8', 'uniE1B7': '8', 'uniE83F': '8', 'uniF05A': '8', 'uniEF28': '8',
'uniE9EA': '9', 'uniE274': '9', 'uniED98': '9', 'uniEC4B': '9', 'uniEB19': '9',
}
unicode_string = html.unescape(encoded_box_office) #转unicode
decoded_box_office = ''
for char in unicode_string:
uni_num = ord(char)
decoded_box_office += glyph_to_number.get(map_list.get(uni_num),char)
return decoded_box_office
def parsel_data(showDate_):
"""
解析猫眼票房数据,并使用字体映射规则解码加密的数字。
参数:
showDate_ (str): 查询日期,格式为YYYYMMDD。 比如 showDate="20250312"
"""
json_data = fetch_json_data(showDate_)
'''提取字体链接'''
fontStyle = json_data['fontStyle']
pattern = r'embedded-opentype.*url\(\"(.*?)\.woff\"\)'
match = re.search(pattern, fontStyle)
result = match.group(1) + ".woff"
font_url = 'https:' + result
for data in json_data['movieList']['data']['list']:
movie_name = data['movieInfo']['movieName'] # 影片名称
encoded_box_office = data['boxSplitUnit']['num'] # 加密的票房数字
decoded_box_office = decode_data(font_url, encoded_box_office) # 解码票房数字
box_office = decoded_box_office + data['boxSplitUnit']['unit'] # 综合票房
box_office_rate = data['boxRate'] # 票房占比
show_count = data['showCount'] # 排片场次
show_count_rate = data['showCountRate'] # 排片占比
avg_show_view = data['avgShowView'] # 场均人次
avg_seat_view = data['avgSeatView'] # 上座率
movie_data = {
'影片': movie_name,
'综合票房': box_office,
'票房占比': box_office_rate,
'排片场次': show_count,
'排片占比': show_count_rate,
'场均人次': avg_show_view,
'上座率': avg_seat_view,
}
print(movie_data)
if __name__ == '__main__':
parsel_data(showDate_='20250312')


















 394
394

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









