







来自代码随想录的刷题路线:代码随想录
二叉树:
二叉树理论:
-
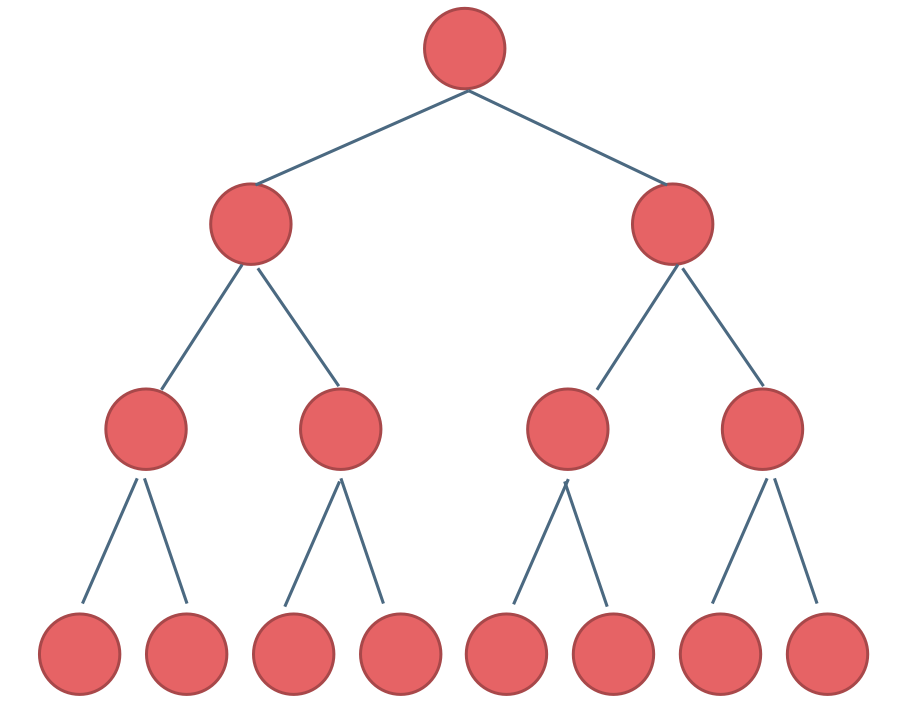
满二叉树:
-
完全二叉树:
完全二叉树的定义:在完全二叉树中,除了最底层节点可能没填满外,其余每层节点数都达到最大值,并且最下面一层的节点都集中在该层最左边的若干位置。若最底层为第 h 层(h从1开始),则该层包含 1~ 2^(h-1) 个节点。
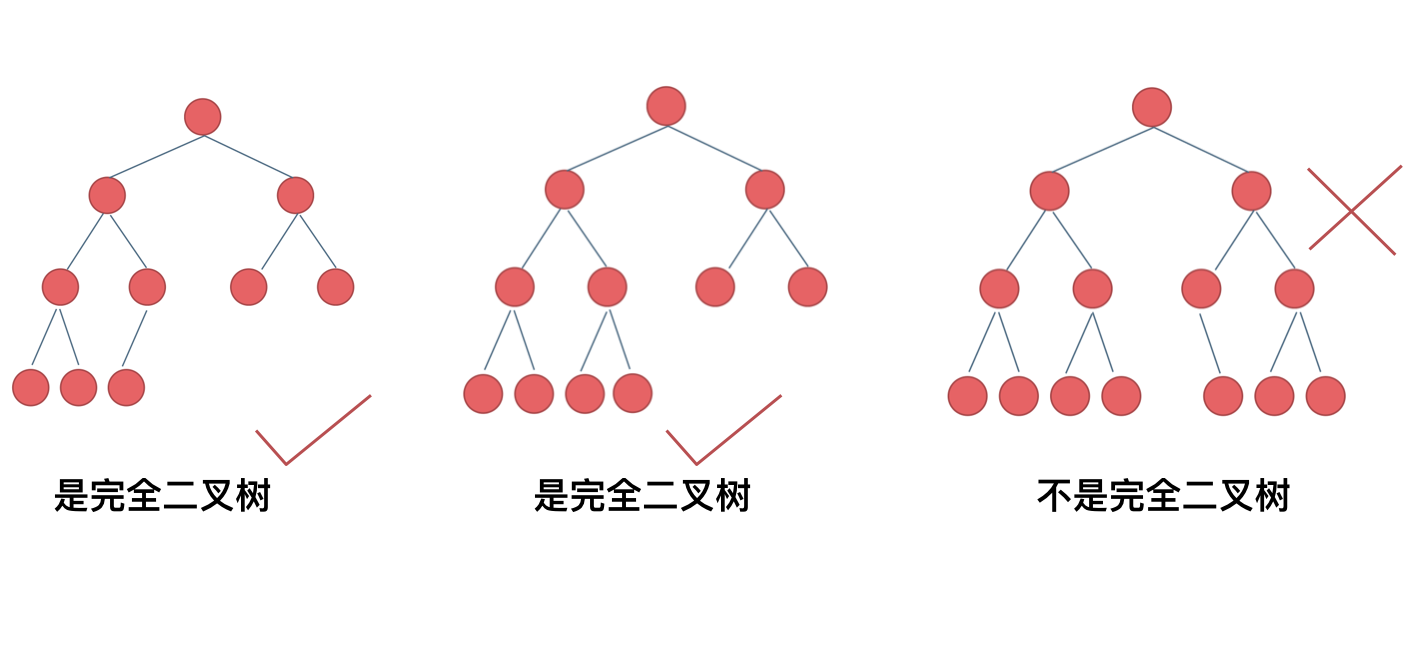
- 满二叉树当然是完全二叉树。
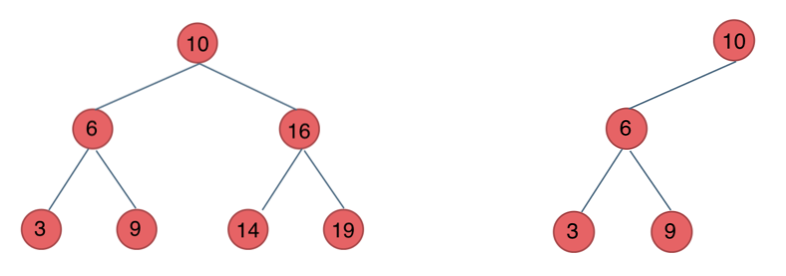
二叉搜索树
前面介绍的树,都没有数值的,而二叉搜索树是有数值的了,二叉搜索树是一个有序树。
- 若它的左子树不空,则左子树上所有结点的值均小于它的根结点的值;
- 若它的右子树不空,则右子树上所有结点的值均大于它的根结点的值;
- 它的左、右子树也分别为二叉排序树
下面这两棵树都是搜索树
#平衡二叉搜索树
平衡二叉搜索树:又被称为AVL(Adelson-Velsky and Landis)树,且具有以下性质:它是一棵空树或它的左右两个子树的高度差的绝对值不超过1,并且左右两个子树都是一棵平衡二叉树。
如图:
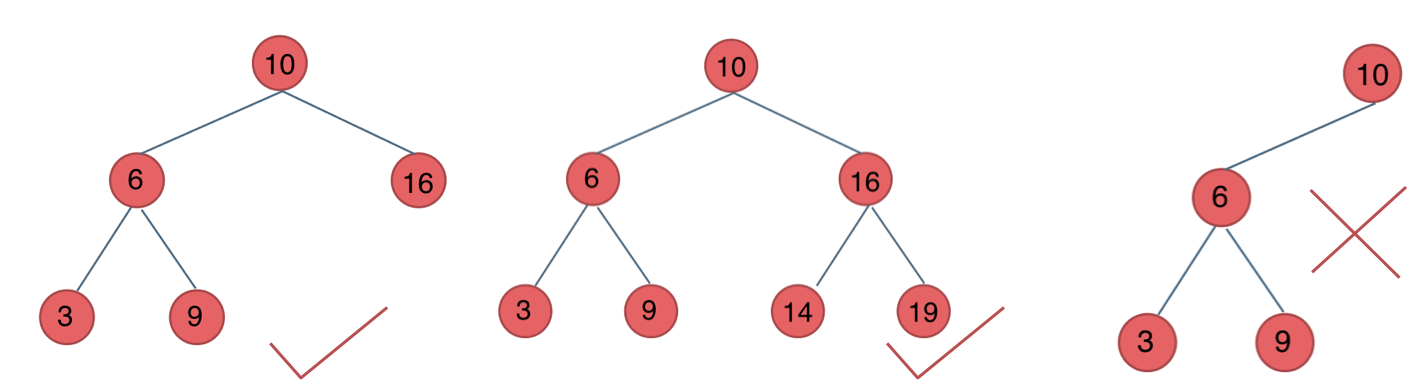
最后一棵 不是平衡二叉树,因为它的左右两个子树的高度差的绝对值超过了1。
C++中map、set、multimap,multiset的底层实现都是平衡二叉搜索树,所以map、set的增删操作时间时间复杂度是logn,注意我这里没有说unordered_map、unordered_set,unordered_map、unordered_set底层实现是哈希表。
所以大家使用自己熟悉的编程语言写算法,一定要知道常用的容器底层都是如何实现的,最基本的就是map、set等等,否则自己写的代码,自己对其性能分析都分析不清楚!
二叉树的存储方式
二叉树可以链式存储,也可以顺序存储。
那么链式存储方式就用指针, 顺序存储的方式就是用数组。
一般都是用链式存储,可以理解成二叉树就是链表。
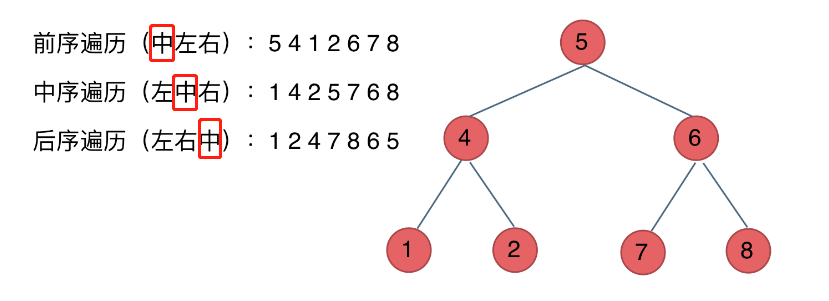
二叉树的遍历方式
-
深度优先遍历
-
- 前序遍历(递归法,迭代法)
- 中序遍历(递归法,迭代法)
- 后序遍历(递归法,迭代法)
-
广度优先遍历
-
- 层次遍历(迭代法)
**迭代:**迭代是重复反馈过程的活动,其目的通常是为了逼近所需目标或结果。
每一次对过程的重复称作一次迭代,而每一次迭代得到的结果会作为下一次迭代的初始值。
递归:解决问题的某一步骤中,又产生新的子问题,并且子问题的解决方式同原来的问题的解决步骤相同。
当新的子问题得到解决时,再回过头来继续解决原来的问题,则会发现问题迎刃而解。
二叉树的递归遍历
递归就是用一个函数处理多种情况,且呈现返回值往上级传递之势(个人理解)。
- 确定递归函数的参数和返回值: 确定哪些参数是递归的过程中需要处理的,那么就在递归函数里加上这个参数, 并且还要明确每次递归的返回值是什么进而确定递归函数的返回类型。
- 确定终止条件: 写完了递归算法, 运行的时候,经常会遇到栈溢出的错误,就是没写终止条件或者终止条件写的不对,操作系统也是用一个栈的结构来保存每一层递归的信息,如果递归没有终止,操作系统的内存栈必然就会溢出。
- 确定单层递归的逻辑: 确定每一层递归需要处理的信息。在这里也就会重复调用自己来实现递归的过程。
前序遍历
class Solution {
public:
//用递归法
void Traversal(TreeNode* node, vector<int>& vec){ //确定参数和返回值
if(node == NULL) return; //确定终止条件
//确定单层递归的逻辑 中左右
vec.push_back(node->val); //将当前节点值存入数组
Traversal(node->left, vec);
Traversal(node->right, vec);
}
vector<int> preorderTraversal(TreeNode* root) {
vector<int> result;
Traversal(root, result);
return result;
}
};
中序遍历
class Solution {
public:
void Traversal(TreeNode* node, vector<int>& vec){
if(node == nullptr) return;
Traversal(node->left, vec);
vec.push_back(node->val);
Traversal(node->right, vec);
}
vector<int> inorderTraversal(TreeNode* root) {
vector<int> vec;
Traversal(root, vec);
return vec;
}
};
后序遍历
什么时候该用后序遍历呢?
需要收集孩子信息往上传递的时候。
class Solution {
public:
void Traversal(TreeNode* node, vector<int>& vec){
if(node == NULL) return;
Traversal(node->left, vec);
Traversal(node->right, vec);
vec.push_back(node->val);
}
vector<int> postorderTraversal(TreeNode* root) {
vector<int> result;
Traversal(root, result);
return result;
}
};
二叉树的非递归遍历
将遍历到的树节点按一定的顺序放进栈中,再按一定的规则弹出栈头元素到数组中。
前序遍历
class Solution {
public:
//非递归(迭代)法模拟前序遍历
vector<int> Traversal(TreeNode* root){
stack<TreeNode*> st;
vector<int> vec;
if(root == NULL) return vec;
st.push(root); //将根结点入栈
while(!st.empty()){
//将栈头元素出栈
TreeNode* node = st.top();
st.pop();
vec.push_back(node->val); //将栈头元素装入数组
//先入右孩子再入左孩子能保证出栈顺序为中左右(前序)
if(node->right) st.push(node->right); //空节点不入栈
if(node->left) st.push(node->left);
}
return vec;
}
vector<int> preorderTraversal(TreeNode* root) {
vector<int> result;
result = Traversal(root);
return result;
}
};
后序遍历
后序遍历可以在前序遍历的基础上小小改动即可:先装左孩子再装右孩子。这样数组中的元素顺序就是中右左,只需反转数组,即可得到想要的左右中的后序遍历。
class Solution {
public:
//非递归(迭代)法模拟后序遍历
//只需要将前序遍历改动为先装左孩子再装右孩子 最后再反转数组即可
vector<int> Traversal(TreeNode* root){
stack<TreeNode*> st;
vector<int> vec;
if(root == NULL) return vec;
st.push(root);
while(!st.empty()){
TreeNode* node = st.top();
st.pop();
vec.push_back(node->val);
if(node->left) st.push(node->left);
if(node->right) st.push(node->right);
}
reverse(vec.begin(), vec.end());
return vec;
}
vector<int> postorderTraversal(TreeNode* root) {
vector<int> result;
result = Traversal(root);
return result;
}
};
中序遍历
中序遍历由于顺序是左中右,即遍历到的节点(中),并不是要处理的节点,也就是遍历顺序与处理顺序不一致,所以不能用与前、后序相似的代码处理。
思路:用指针遍历树节点,用栈记录,按中序顺序出栈到数组
分指针是否为空来处理情况:
- 不为空:将指针所指节点装入栈中,再向左孩子遍历。
- 为空:弹出栈头元素,向右孩子遍历。
class Solution {
public:
//非递归
vector<int> Traversal(TreeNode* root){
//用栈保存指针遍历到的节点,按中序遍历顺序装入数组
stack<TreeNode*> st;
TreeNode* cur = root;
vector<int> result;
while(!st.empty() || cur != NULL){
//对指针所指是否为空而分情况讨论
if(cur != NULL){
//不为空则添加当前节点且向下遍历左节点
st.push(cur);
cur = cur->left;
}
else{
//为空则保存栈头元素到数组 再向下遍历右孩子
cur = st.top();// 从栈里弹出的数据,就是要处理的数据(放进result数组里的数据)
st.pop();
result.push_back(cur->val);
cur = cur->right;
}
}
return result;
}
vector<int> inorderTraversal(TreeNode* root) {
vector<int> result;
result = Traversal(root);
return result;
}
};
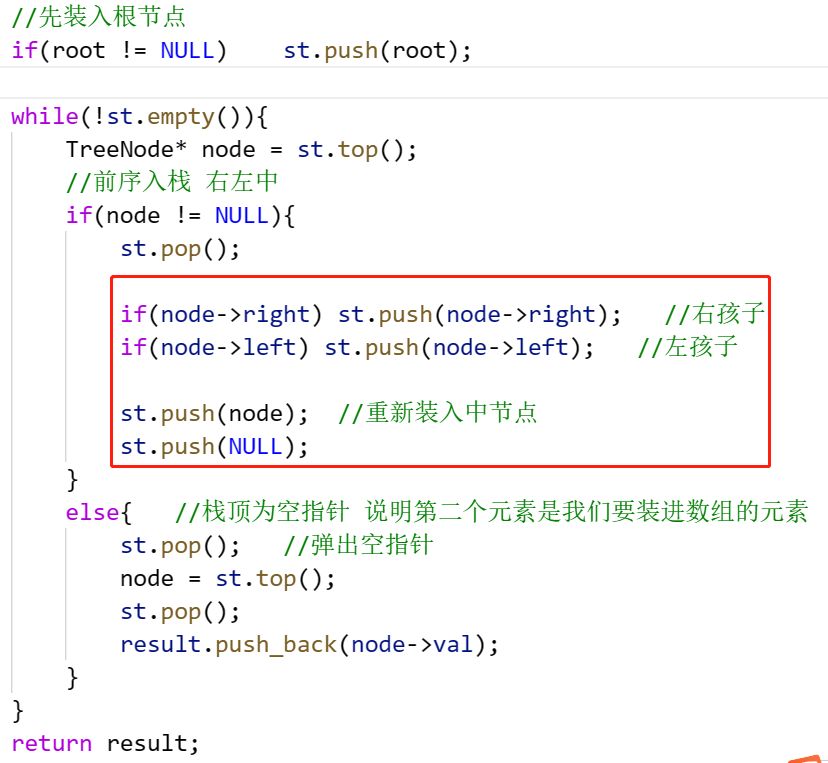
前中后统一写法
将访问的节点放入栈中,把要处理的节点也放入栈中但是要做标记。
如何标记呢,就是要处理的节点放入栈之后,紧接着放入一个空指针作为标记。 这种方法也可以叫做标记法。
中序:
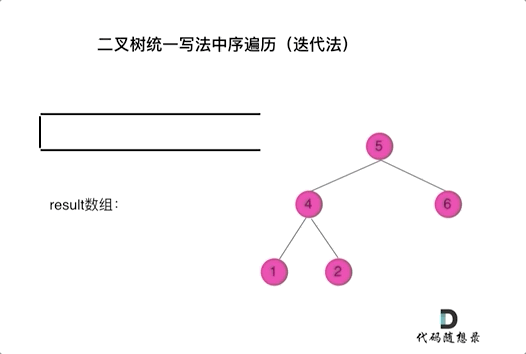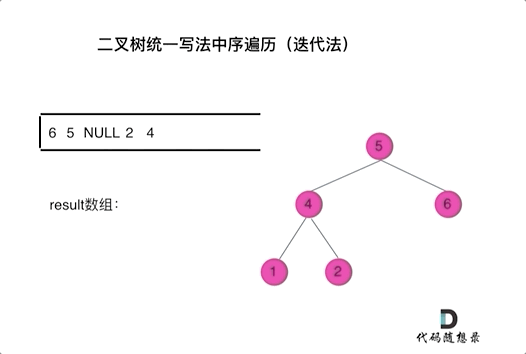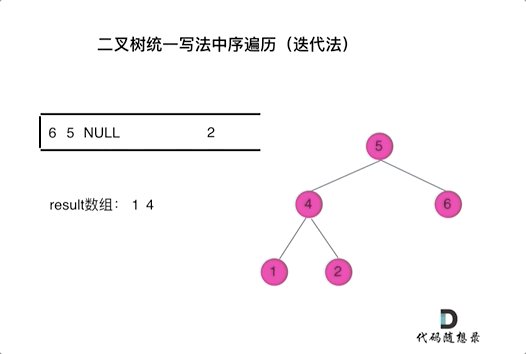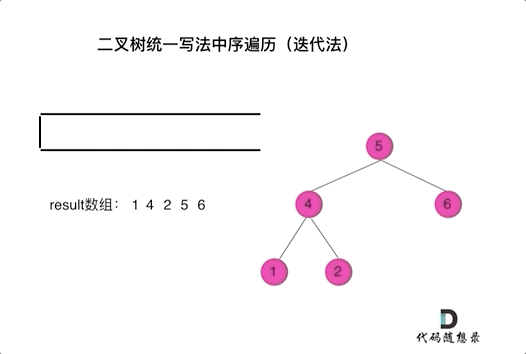
class Solution {
public:
//空指针标记法用于统一前中后序的非迭代算法,解决中序遍历顺序和处理顺序不同的问题
vector<int> Traversal(TreeNode* root){
vector<int> result;
stack<TreeNode*> st;
//先装入根节点
if(root != NULL) st.push(root);
while(!st.empty()){
TreeNode* node = st.top();
if(node != NULL){ //栈顶不为空指针 说明该元素暂时不是我们要处理的
//栈每次新装入一个节点,都得确定是否有右左孩子,有的话就得按右中左的顺序装入
st.pop();
if(node->right) st.push(node->right); //右孩子
st.push(node); //重新装入中节点
st.push(NULL);
if(node->left) st.push(node->left); //左孩子
}
else{ //栈顶为空指针 说明第二个元素是我们要装进数组的元素
st.pop(); //弹出空指针
node = st.top();
st.pop();
result.push_back(node->val);
}
}
return result;
}
vector<int> inorderTraversal(TreeNode* root) {
vector<int> result;
result = Traversal(root);
return result;
}
};
前序:
后序:

二叉树层序遍历
队列先进先出,符合一层一层遍历的逻辑,而用栈先进后出适合模拟深度优先遍历也就是递归的逻辑。
而这种层序遍历方式就是图论中的广度优先遍历,只不过我们应用在二叉树上。

//迭代法
class Solution {
public:
vector<vector<int>> levelOrderFuc(TreeNode* root) {
queue<TreeNode*> que; //利用队列先进先出的特点完成层序遍历
vector<vector<int>> result;
if(root != NULL) que.push(root);
while(!que.empty()){ //队列为空表示已遍历至最底层
//记录每一层初始时的队列大小
int size = que.size();
vector<int> vec; //记录每一层的元素
//遍历每一层的节点
for(int i = 0; i < size; i++){ //这里不能用que.size()因为它不停变化
TreeNode* node = que.front();
que.pop();
vec.push_back(node->val);
//从上至下不断遍历获取下一层
if(node->left) que.push(node->left);
if(node->right) que.push(node->right);
}
result.push_back(vec);
}
return result;
}
vector<vector<int>> levelOrder(TreeNode* root) {
vector<vector<int>> result;
result = levelOrderFuc(root);
return result;
}
};
107.二叉树的层序遍历 II
反转result再返回即可
199.二叉树的右视图
新建一个一维数组,将二维数组每层的最后一个元素(vecTwo.back)放进去返回。
for(const vector<int>& layer : vecTwo){
result.push_back(layer.back());
}
for(const vector<double>& layer : result){
double num = 0;
for(double i : layer){
num += i;
}
double averge = num / layer.size();
result1.push_back(averge);
}
vector<int> LevelOrderFuc(TreeNode* root){
queue<TreeNode*> que;
vector<int> res;
if(root != NULL) que.push(root);
while(!que.empty()){
int size = que.size();
int maxValue = INT_MIN;
while(size--){
TreeNode* node = que.front();
que.pop();
//每次只把最大的数存进数组
maxValue = max(maxValue, node->val);
if(node->left) que.push(node->left);
if(node->right) que.push(node->right);
}
res.push_back(maxValue);
}
return res;
}
Node* levelOrderFuc(Node* root) {
queue<Node*> que;
if(root != NULL) que.push(root);
while(!que.empty()){ //队列为空表示已遍历至最底层
//记录每一层初始时的队列大小
int size = que.size();
//遍历每一层的节点
for(int i = 0; i < size; i++){ //这里不能用que.size()因为它不停变化
Node* node = que.front();
que.pop();
//当前节点不是每层的最后一个节点
if(i < size - 1){
node->next = que.front();
}
//从上至下不断遍历获取下一层
if(node->left) que.push(node->left);
if(node->right) que.push(node->right);
}
}
return root;
}
与116一样
class Solution {
public:
int maxDepth(TreeNode* root) {
queue<TreeNode*> que;
int level = 0;
if(root == NULL)
{
return level;
}
que.push(root);
//遍历每一层
while(!que.empty()){
int size = que.size();
//每一层里面
while(size--){
auto node = que.front();
que.pop();
if(node->left) que.push(node->left);
if(node->right) que.push(node->right);
}
level++;
}
return level;
}
};
class Solution {
public:
int minDepth(TreeNode* root) {
queue<TreeNode*> que;
int minLevel = 0;
if(root == NULL)
{
return minLevel;
}
que.push(root);
//遍历每一层
while(!que.empty()){
int size = que.size();
minLevel++;
//每一层里面
while(size--){
auto node = que.front();
que.pop();
if(node->left) que.push(node->left);
if(node->right) que.push(node->right);
if(!node->left && !node->right)
return minLevel;
}
}
return minLevel;
}
};
226.翻转二叉树
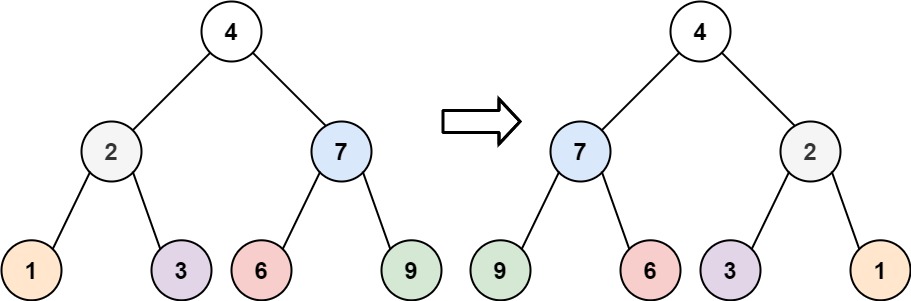
层序遍历:
也就是广度优先,跟上面的类似
class Solution {
public:
//广度优先 也就是层序遍历
TreeNode* invertTree(TreeNode* root) {
queue<TreeNode*> que;
if(root != NULL) que.push(root);
else return root;
while(!que.empty()){
int size = que.size();
//遍历每一层
while(size--){
TreeNode* node = que.front();
que.pop();
swap(node->left, node->right);
if (node->left) que.push(node->left);
if (node->right) que.push(node->right);
}
}
return root;
}
};
class Solution {
public:
//递归法 前序遍历
TreeNode* RecursionPre(TreeNode* node){
if(node == NULL) return node;
swap(node->left, node->right);
RecursionPre(node->left);
RecursionPre(node->right);
return node;
}
TreeNode* invertTree(TreeNode* root) {
root = RecursionPre(root);
return root;
}
};
class Solution {
public:
//迭代法 前序遍历
TreeNode* invertTree(TreeNode* root) {
stack<TreeNode*> sta;
if(root != NULL) sta.push(root);
while(!sta.empty()){
TreeNode* node = sta.top();
//空节点则说明是要处理的节点
if(node == NULL){
sta.pop();
node = sta.top();
sta.pop();
swap(node->left, node->right);
}
else{
sta.pop();
//右左中入栈
if(node->right) sta.push(node->right);
if(node->left) sta.push(node->left);
sta.push(node);
sta.push(NULL);
}
}
return root;
}
};
知识补充:
-
红黑树就是一种二叉平衡搜索树,这两个树不是独立的,所以C++中map、multimap、set、multiset的底层实现机制是二叉平衡搜索树,再具体一点是红黑树。
-
对于二叉树节点的定义,C++代码如下:
struct TreeNode {
int val;
TreeNode *left;
TreeNode *right;
TreeNode(int x) : val(x), left(NULL), right(NULL) {}
};
定义中TreeNode(int x) : val(x), left(NULL), right(NULL) {} 是什么呢?
这是构造函数,C语言中的结构体是C++中类的祖先,所以C++结构体也可以有构造函数。
构造函数也可以不写,但是new一个新的节点的时候就比较麻烦。
例如有构造函数,定义初始值为9的节点:
TreeNode* a = new TreeNode(9);
没有构造函数的话就要这么写:
TreeNode* a = new TreeNode();
a->val = 9;
a->left = NULL;
a->right = NULL;
101. 对称二叉树
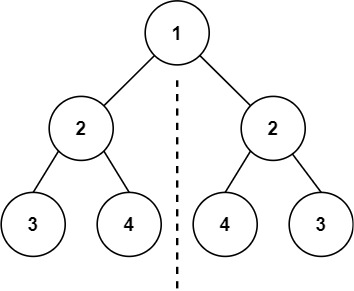
二叉树题目确定遍历顺序很重要。
递归:
由于递归是探到最底层才返回,所以应该是后序遍历实现。
递归三部曲:
- 确定传入参数和返回值类型:其实题目的意思就是比较根节点的左右子树是否对称。所以参数应该是左节点和右节点,返回值直接为bool。
- 确定终止条件:当左右节点有个空有个不空、两个都空、或者数值不相等时终止。
- **确定单层递归逻辑:**单层递归的逻辑就是处理 左右节点都不为空,且数值相同的情况。
- 比较二叉树外侧是否对称:传入的是左节点的左孩子,右节点的右孩子。
- 比较内侧是否对称,传入左节点的右孩子,右节点的左孩子。
- 如果左右都对称就返回true ,有一侧不对称就返回false 。
class Solution {
public:
bool compare(TreeNode* left, TreeNode* right) {
// 首先排除空节点的情况
if (left == NULL && right != NULL) return false;
else if (left != NULL && right == NULL) return false;
else if (left == NULL && right == NULL) return true;
// 排除了空节点,再排除数值不相同的情况
else if (left->val != right->val) return false;
// 此时就是:左右节点都不为空,且数值相同的情况
// 此时才做递归,做下一层的判断
bool outside = compare(left->left, right->right); // 左子树:左、 右子树:右
bool inside = compare(left->right, right->left); // 左子树:右、 右子树:左
bool isSame = outside && inside; // 左子树:中、 右子树:中 (逻辑处理)
return isSame;
}
bool isSymmetric(TreeNode* root) {
if (root == NULL) return true;
return compare(root->left, root->right);
}
};
迭代:队列
class Solution {
public:
bool isSymmetric(TreeNode* root) {
if (root == NULL) return true;
queue<TreeNode*> que;
que.push(root->left); // 将左子树头结点加入队列
que.push(root->right); // 将右子树头结点加入队列
while (!que.empty()) { // 接下来就要判断这两个树是否相互翻转
TreeNode* leftNode = que.front(); que.pop();
TreeNode* rightNode = que.front(); que.pop();
if (leftNode == NULL && rightNode == NULL) { // 左节点为空、右节点为空,此时说明是对称的
continue;
}
// 左右一个节点不为空,或者都不为空但数值不相同,返回false
if ((!leftNode || !rightNode || (leftNode->val != rightNode->val))) {
return false;
}
que.push(leftNode->left); // 加入左节点左孩子
que.push(rightNode->right); // 加入右节点右孩子
que.push(leftNode->right); // 加入左节点右孩子
que.push(rightNode->left); // 加入右节点左孩子
}
return true;
}
};
572. 另一棵树的子树
在对称二叉树的基础上又加了个递归,很烦 有点绕
class Solution {
public:
bool isSameTree(TreeNode* p, TreeNode* q){
if(!p && !q) return true;
if((!p && q) || (p && !q) || (p->val != q->val)) return false;
return isSameTree(p->left, q->left) && isSameTree(p->right, q->right);
}
//判断当前结点与另一棵树当前节点是否相等
bool isSubtree(TreeNode* root, TreeNode* subRoot) {
if(!subRoot) return true; //空节点是任和树的子节点
if(!root) return false; //sub不为空而root为空 不相等
//两节点为根的树相等
if(isSameTree(root, subRoot)) return true;
//不相等则 检查其左右节点是否各自相等(有一个相等就行)
bool left = isSubtree(root->left, subRoot);
bool right = isSubtree(root->right, subRoot);
return left || right;
}
};
104. 二叉树的最大深度
确定递归函数的参数和返回值:参数就是传入树的根节点,返回就返回这棵树的深度,所以返回值为int类型。
确定终止条件:如果为空节点的话,就返回0,表示高度为0。
确定单层递归的逻辑:先求它的左子树的深度,再求右子树的深度,最后取左右深度最大的数值 再+1 (加1是因为算上当前中间节点)就是目前节点为根节点的树的深度。
所以整体c++代码如下:
class solution {
public:
int getdepth(TreeNode* node) {
if (node == NULL) return 0;
int leftdepth = getdepth(node->left); // 左
int rightdepth = getdepth(node->right); // 右
int depth = 1 + max(leftdepth, rightdepth); // 中
return depth;
}
int maxDepth(TreeNode* root) {
return getdepth(root);
}
};
559. N 叉树的最大深度
与上面类似:多画图推演,别懒。
class Solution {
public:
int maxDepth(Node* root) {
if(!root) return 0;
int depth = 0;
//遍历每个节点下一层的所有子树
for(int i = 0; i < root->children.size(); i++){
//比较现今的深度与原先深度 谁更大
depth = max(depth, maxDepth(root->children[i]));
}
return depth + 1;
}
};
111. 二叉树的最小深度
与二叉树的最大深度不同的是:最大深度是只要那一层有结点,那深度就包括那一层。最小深度是从根节点到最近叶子节点的最短路径上的节点数量。
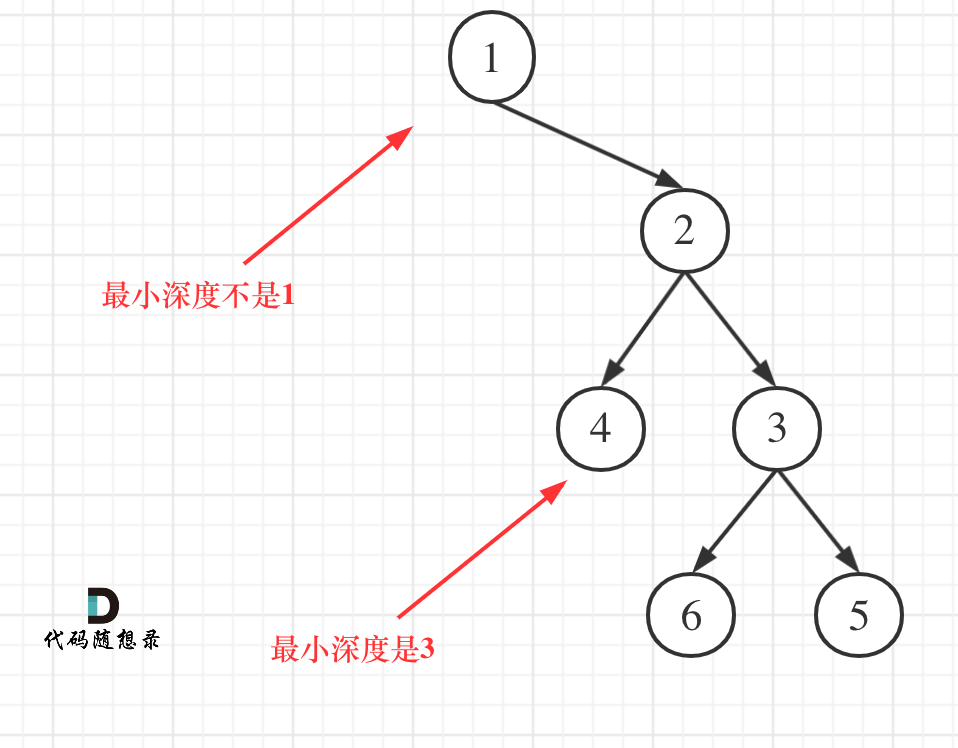
class Solution {
public:
int getDepth(TreeNode* node) {
if (node == NULL) return 0; //最低点的下一层
int leftDepth = getDepth(node->left); // 左
int rightDepth = getDepth(node->right); // 右
// 中
// 当一个左子树为空,右不为空,这时并不是叶子节点
if (node->left == NULL && node->right != NULL) {
return 1 + rightDepth;
}
// 当一个右子树为空,左不为空,这时并不是叶子节点
if (node->left != NULL && node->right == NULL) {
return 1 + leftDepth;
}
//左右子树都不为空 或者都为空
int result = 1 + min(leftDepth, rightDepth);
return result;
}
int minDepth(TreeNode* root) {
return getDepth(root);
}
};
class Solution {
public:
//用队列实现迭代法 层序遍历
int minDepth(TreeNode* root) {
queue<TreeNode*> que;
int depth = 0;
if(root != NULL) que.push(root);
while(!que.empty()){
int size = que.size(); //记录每一层的节点个数
depth++; //遍历每层时 更新深度
for(int i = 0; i < size; i++){ //遍历每层的子节点
TreeNode* node = que.front();
que.pop();
if(node->left) que.push(node->left);
if(node->right) que.push(node->right);
// 当左右孩子都为空的时候,说明是最低点的一层了,退出
if(!node->left && !node->right) return depth;
}
}
return depth;
}
};
222. 完全二叉树的节点个数
class Solution {
public:
int countNodes(TreeNode* root) {
//递归 直接当作普通二叉树
if(root == NULL) return 0;
int nums = 0;
int leftNums = 0;
int rightNums = 0;
if(root->left) leftNums = countNodes(root->left);
if(root->right) rightNums = countNodes(root->right);
nums = 1 + leftNums + rightNums;
return nums;
}
};
class Solution {
public:
int countNodes(TreeNode* root) {
//层序遍历
queue<TreeNode*> que;
if(root != NULL) que.push(root);
int nums = 0;
while(!que.empty()){
int size = que.size();
for(int i = 0; i < size; i++){
TreeNode* node = que.front();
nums++;
que.pop();
if(node->left) que.push(node->left);
if(node->right) que.push(node->right);
}
}
return nums;
}
};
110. 平衡二叉树
求高度:后序遍历; 求深度:前序遍历
class Solution {
public:
//递归 后序 当某个节点的左右子树高度差大于1时返回值标为-1 当检测到左右子树返回的是-1时,直接向上传递-1 因为此时一定不是平衡二叉树 否则 求当前结点的最大高度
int getHeigt(TreeNode* node){
if(node == NULL) return 0;
int leftHeight = getHeigt(node->left);
int rightHeight = getHeigt(node->right);
//-1标志不是平衡二叉树
if(leftHeight == -1 || rightHeight == -1){
return -1;
}
int result = 0;
if(abs(leftHeight - rightHeight) > 1) result = -1;
else{ //该节点是平衡二叉树 所以得向上传递当前的高度 好让父节点与另一子树比较
result = 1 + max(leftHeight, rightHeight);
}
return result;
}
bool isBalanced(TreeNode* root) {
int result = getHeigt(root);
if(result == -1) return false;
else return true;
}
};
257. 二叉树的所有路径

递归:
因为要求的是根节点到叶子的路径,所以肯定用的是前序遍历。当我们遍历到叶子节点后要回退一个(或者多个,取决于当前节点下还有没有其他路径)节点再去找其他路径,这时候就得用到回溯,注意回溯肯定是永远和递归在一起的,需要包含在同一个花括号内。
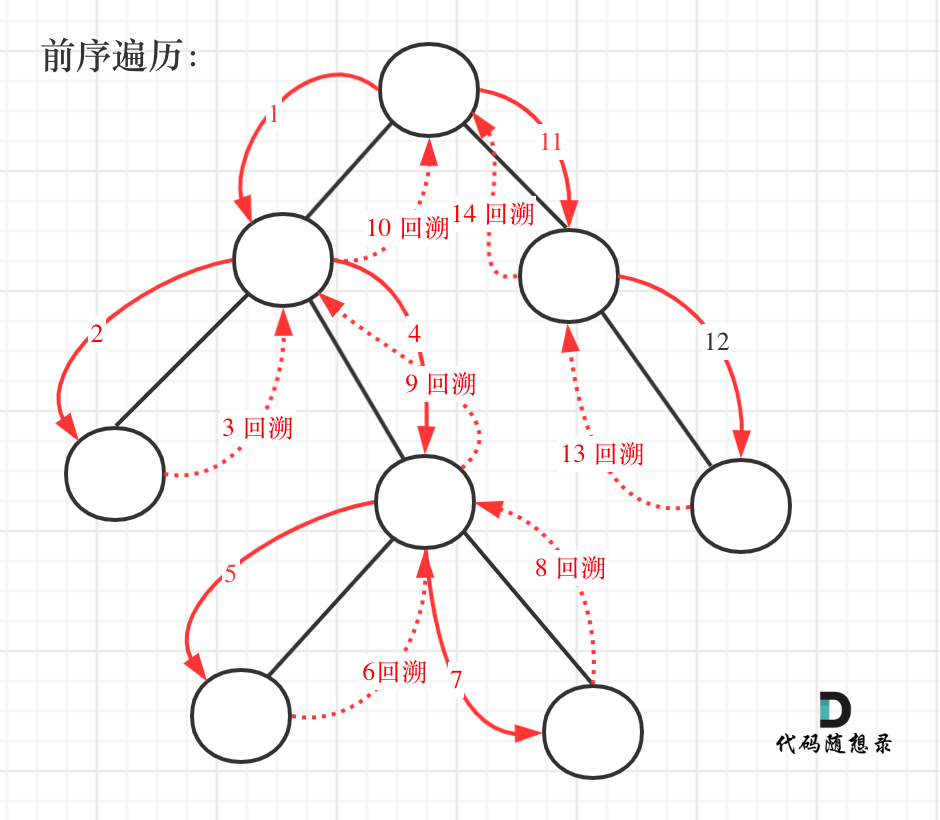
class Solution {
public:
//递归和回溯 前序遍历
void traversal(TreeNode* node, vector<int>& path, vector<string>& result){
path.push_back(node->val); //每次递归第一件事先把节点的值装进数组(中)
//遇到叶子结点时终止递归 将数组里的路径保存到结果数组中
if(node->left == NULL && node->right == NULL){ //这里没对当前节点进行空节点的判断 而是放到了后面单层递归逻辑中
string sPath;
int i = 0;
for(; i < path.size() - 1; i++){ //循环内-1是因为最后一个节点不需要箭头
sPath += to_string(path[i]);
sPath += "->";
}
//单独添加最后一个节点
sPath += to_string(path[i]);
result.push_back(sPath);
return;
}
//单层递归逻辑 (左右)
if(node->left){ //非空才递归
//每次递归后都向上回溯一层 回溯和递归要永远绑定在一起的
traversal(node->left, path, result);
path.pop_back();
}
if(node->right){
traversal(node->right, path, result);
path.pop_back();
}
}
vector<string> binaryTreePaths(TreeNode* root) {
vector<string> result;
if(root == NULL) return result;
vector<int> path;
traversal(root, path, result);
return result;
}
};
迭代:
至于非递归的方式,我们可以依然可以使用前序遍历的迭代方式来模拟遍历路径的过程。
这里除了模拟递归需要一个栈,同时还需要一个栈来存放对应的遍历路径。
C++代码如下:
class Solution {
public:
vector<string> binaryTreePaths(TreeNode* root) {
stack<TreeNode*> treeSt;// 保存树的遍历节点
stack<string> pathSt; // 保存遍历路径的节点
vector<string> result; // 保存最终路径集合
if (root == NULL) return result;
treeSt.push(root);
pathSt.push(to_string(root->val));
while (!treeSt.empty()) {
TreeNode* node = treeSt.top(); treeSt.pop(); // 取出节点 中
string path = pathSt.top();pathSt.pop(); // 取出该节点对应的路径
if (node->left == NULL && node->right == NULL) { // 遇到叶子节点
result.push_back(path);
}
if (node->right) { // 右
treeSt.push(node->right);
pathSt.push(path + "->" + to_string(node->right->val));
}
if (node->left) { // 左
treeSt.push(node->left);
pathSt.push(path + "->" + to_string(node->left->val));
}
}
return result;
}
};
404. 左叶子之和
从节点自身无法判断其是否为左叶子,只能从其父节点判断,如果是左节点且没有子节点(叶子)的话就是左叶子
class Solution {
public:
int result = 0;
int sumOfLeftLeaves(TreeNode* root) {
//后序递归
if(!root->left && !root->right){ //叶子结点
return 0;
}
//从父节点找左叶子
if(root->left && !root->left->left && !root->left->right){
result += root->left->val;
}
//单层逻辑 往下遍历
if(root->left) sumOfLeftLeaves(root->left);
if(root->right) sumOfLeftLeaves(root->right);
return result;
}
};
class Solution {
public:
int sumOfLeftLeaves(TreeNode* root) {
//层序
queue<TreeNode*> que;
int result = 0;
if(root != NULL) que.push(root);
while(!que.empty()){
TreeNode* node = que.front(); que.pop();
if(!node->left && !node->right) continue; //叶子节点
//从父节点找左叶子
if(node->left && !node->left->left && !node->left->right){
result += node->left->val;
}
//分支节点
if(node->left) que.push(node->left);
if(node->right) que.push(node->right);
}
return result;
}
};
513. 找树左下角的值
//层序遍历 只需要记录每一行的第一个元素值就行 被下一层覆盖 所以最后得到的肯定是最底层的最左边元素
class Solution {
public:
int findBottomLeftValue(TreeNode* root) {
queue<TreeNode*> que;
if (root != NULL) que.push(root);
int result = 0;
while (!que.empty()) {
int size = que.size();
for (int i = 0; i < size; i++) {
TreeNode* node = que.front();
que.pop();
if (i == 0) result = node->val; // 记录最后一行第一个元素
if (node->left) que.push(node->left);
if (node->right) que.push(node->right);
}
}
return result;
}
};
//递归与回溯
class Solution {
public:
int maxDepth = -1;
int curDepth = 0;
int result;
void traversal(TreeNode* node){
//终止条件 :叶子节点
if(node->left == NULL && node->right == NULL){
if(curDepth > maxDepth){ //当深度更新时 将新层的值保留
maxDepth = curDepth;
result = node->val;
}
return;
}
//单层逻辑:本题没有 中 的处理逻辑
//先遍历左再遍历右即可
//因为这样就能保证这一层保留的值是最左边节点的值 因为本层的其他节点会因为深度没有刷新而不保留值
if(node->left){
curDepth++;
traversal(node->left);
curDepth--; //回溯
}
if(node->right){
curDepth++;
traversal(node->right);
curDepth--; //回溯
}
return;
}
int findBottomLeftValue(TreeNode* root) {
traversal(root);
return result;
}
};
还可以精简写法:
if (root->left) {
traversal(root->left, depth + 1); // 隐藏着回溯
}
if (root->right) {
traversal(root->right, depth + 1); // 隐藏着回溯
}
depth+1并不改变depth的值,相当于将回溯的过程隐藏。
112. 路径总和
class Solution {
public:
bool hasPathSum(TreeNode* root, int targetSum) {
int num = 0; //记录过程值
if(!root) return false;
num += root->val;
if(!root->left && !root->right){ //叶子节点
if(num == targetSum) return true;
else return false;
}
bool leftPath = false;
bool rightPath = false;
//单层逻辑 递归子节点时要减去当前节点值
if(root->left){
leftPath = hasPathSum(root->left, targetSum - root->val);
num -= root->val; //回溯
}
if(root->right){
rightPath = hasPathSum(root->right, targetSum - root->val);
num -= root->val;
}
return leftPath || rightPath;
}
};
//代码随想录:
class Solution {
private:
bool traversal(TreeNode* cur, int count) {
if (!cur->left && !cur->right && count == 0) return true; // 遇到叶子节点,并且计数为0
if (!cur->left && !cur->right) return false; // 遇到叶子节点直接返回
if (cur->left) { // 左
count -= cur->left->val; // 递归,处理节点;
if (traversal(cur->left, count)) return true;
count += cur->left->val; // 回溯,撤销处理结果
}
if (cur->right) { // 右
count -= cur->right->val; // 递归,处理节点;
if (traversal(cur->right, count)) return true;
count += cur->right->val; // 回溯,撤销处理结果
}
return false;
}
public:
bool hasPathSum(TreeNode* root, int sum) {
if (root == NULL) return false;
return traversal(root, sum - root->val);
}
};
113. 路径总和 II
跟上面那题类似,只是这里需要求路径,不需要返回值
class Solution {
public:
vector<vector<int>> result;
vector<int> path;
//记录路径 所以不需要返回值
void findPath(TreeNode* node, int count){
//当遇到叶子结点 且路径积累值与目标值相等时 存入当前路径
if(!node->left && !node->right && count == 0){
result.push_back(path);
return;
}
if(!node->left && !node->right) return; //值不相等时不存入路径
//单层逻辑
if(node->left){
count -= node->left->val;
path.push_back(node->left->val);
findPath(node->left, count);
//回溯
count += node->left->val;
path.pop_back();
}
if(node->right){
count -= node->right->val;
path.push_back(node->right->val);
findPath(node->right, count);
//回溯
count += node->right->val;
path.pop_back();
}
return;
}
vector<vector<int>> pathSum(TreeNode* root, int targetSum) {
if(root == NULL) return result;
path.push_back(root->val); //根节点别忘了
findPath(root, targetSum - root->val); //隐藏回溯了这里
return result;
}
};
106. 从中序与后序遍历序列构造二叉树
tips:
遇到这种题要学会打日志去调试结果,脑中模拟很容易越想越乱
前序和中序可以唯一确定一棵二叉树。后序和中序可以唯一确定一棵二叉树。前序和后序不可以唯一确定一棵二叉树。
理论知识:
- 以 后序数组的最后一个元素为切割点。
- 先以后序数组的最后一个元素也就是中间节点切中序数组为左右两个数组。
- 根据中序数组的左右部分长度,反过来再切后序数组。
- 一层一层切下去,每次后序数组最后一个元素就是节点元素。
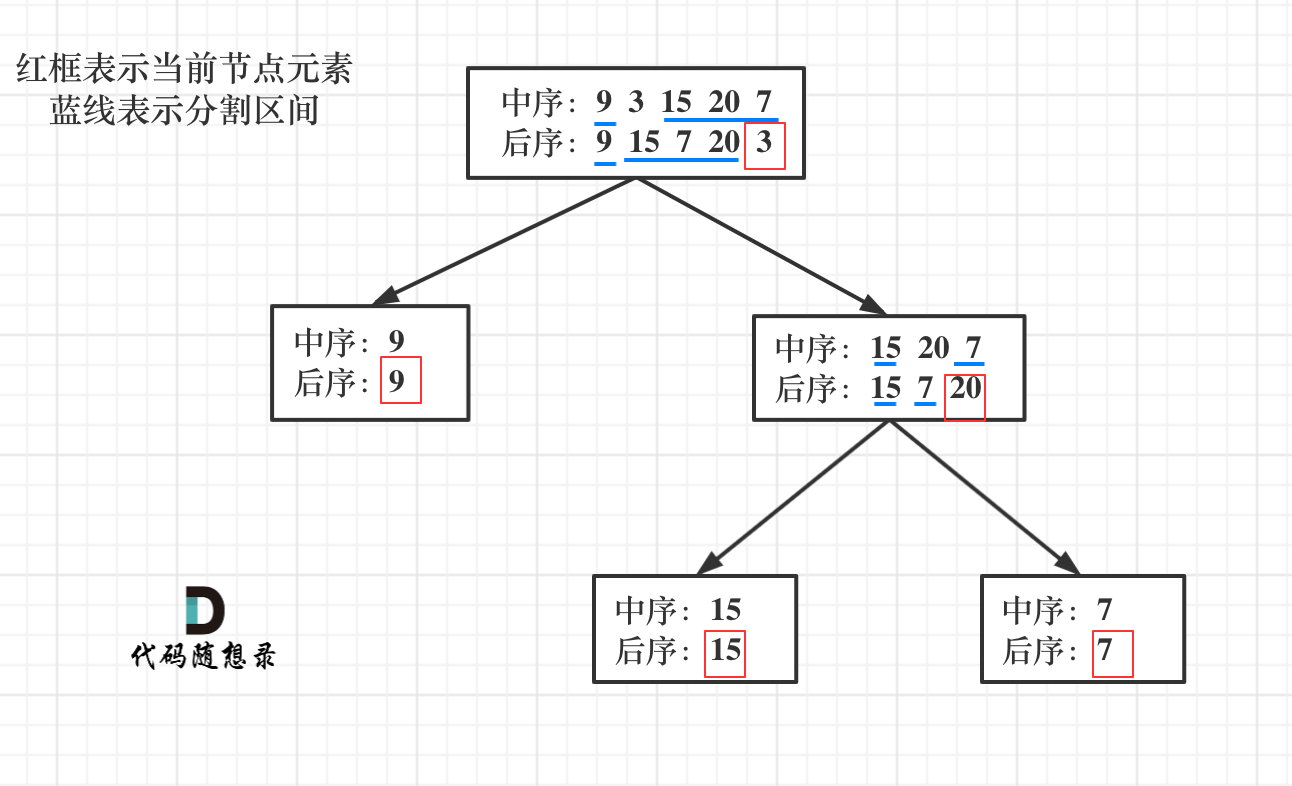
class Solution {
public:
TreeNode* traversal(vector<int>& inorder, vector<int>& postorder) {
if(postorder.size() == 0) return NULL;
//找后序最后一个元素值:中节点的值
int rootValue = postorder[postorder.size() - 1];
TreeNode* root = new TreeNode(rootValue);
//从中序数组里找到中节点的位置
int rootPosOfInorder;
for(rootPosOfInorder = 0; rootPosOfInorder < inorder.size(); rootPosOfInorder++){
if(inorder[rootPosOfInorder] == rootValue) break;
}
//将数组切割成左右中序数组 遵循左闭右开原则 不包含中节点
//[0, rootPosInorder)
vector<int> leftInorder(inorder.begin(), inorder.begin() + rootPosOfInorder);
//[rootPosInorder + 1, end)
vector<int> rightInorder(inorder.begin() + rootPosOfInorder + 1, inorder.end());
//舍弃后序的最后一个元素 也就是中节点值
postorder.resize(postorder.size() - 1);
//通过左右中序数组的大小 分割左右后序数组
// 依然左闭右开,使用了左中序数组大小作为切割点
// [0, leftInorder.size)
vector<int> leftPostorder(postorder.begin(), postorder.begin() + leftInorder.size());
// [leftInorder.size(), end)
vector<int> rightPostorder(postorder.begin() + leftInorder.size(), postorder.end());
//递归启动!
root->left = traversal(leftInorder, leftPostorder);
root->right = traversal(rightInorder, rightPostorder);
return root;
}
TreeNode* buildTree(vector<int>& inorder, vector<int>& postorder) {
if(inorder.size() == 0 || postorder.size() == 0) return NULL;
return traversal(inorder, postorder);
}
};
此时应该发现了,如上的代码性能并不好,因为每层递归定义了新的vector(就是数组),既耗时又耗空间,但上面的代码是最好理解的。
下面给出用下标索引来分割的版本:同时打上日志
class Solution {
private:
TreeNode* traversal (vector<int>& inorder, int inorderBegin, int inorderEnd, vector<int>& postorder, int postorderBegin, int postorderEnd) {
if (postorderBegin == postorderEnd) return NULL;
int rootValue = postorder[postorderEnd - 1];
TreeNode* root = new TreeNode(rootValue);
if (postorderEnd - postorderBegin == 1) return root;
int delimiterIndex;
for (delimiterIndex = inorderBegin; delimiterIndex < inorderEnd; delimiterIndex++) {
if (inorder[delimiterIndex] == rootValue) break;
}
// 切割中序数组
// 左中序区间,左闭右开[leftInorderBegin, leftInorderEnd)
int leftInorderBegin = inorderBegin;
int leftInorderEnd = delimiterIndex;
// 右中序区间,左闭右开[rightInorderBegin, rightInorderEnd)
int rightInorderBegin = delimiterIndex + 1;
int rightInorderEnd = inorderEnd;
// 切割后序数组
// 左后序区间,左闭右开[leftPostorderBegin, leftPostorderEnd)
int leftPostorderBegin = postorderBegin;
int leftPostorderEnd = postorderBegin + delimiterIndex - inorderBegin; // 终止位置是 需要加上 中序区间的大小size
// 右后序区间,左闭右开[rightPostorderBegin, rightPostorderEnd)
int rightPostorderBegin = postorderBegin + (delimiterIndex - inorderBegin);
int rightPostorderEnd = postorderEnd - 1; // 排除最后一个元素,已经作为节点了
cout << "----------" << endl;
cout << "leftInorder :";
for (int i = leftInorderBegin; i < leftInorderEnd; i++) {
cout << inorder[i] << " ";
}
cout << endl;
cout << "rightInorder :";
for (int i = rightInorderBegin; i < rightInorderEnd; i++) {
cout << inorder[i] << " ";
}
cout << endl;
cout << "leftpostorder :";
for (int i = leftPostorderBegin; i < leftPostorderEnd; i++) {
cout << postorder[i] << " ";
}
cout << endl;
cout << "rightpostorder :";
for (int i = rightPostorderBegin; i < rightPostorderEnd; i++) {
cout << postorder[i] << " ";
}
cout << endl;
root->left = traversal(inorder, leftInorderBegin, leftInorderEnd, postorder, leftPostorderBegin, leftPostorderEnd);
root->right = traversal(inorder, rightInorderBegin, rightInorderEnd, postorder, rightPostorderBegin, rightPostorderEnd);
return root;
}
public:
TreeNode* buildTree(vector<int>& inorder, vector<int>& postorder) {
if (inorder.size() == 0 || postorder.size() == 0) return NULL;
return traversal(inorder, 0, inorder.size(), postorder, 0, postorder.size());
}
};
105. 从前序与中序遍历序列构造二叉树
与上面一题类似,需要注意左闭右开的区间原则即可,输出错误可以打日志将每个小数组的值都打印出来
class Solution {
public:
TreeNode* buildTree(vector<int>& preorder, vector<int>& inorder) {
if(preorder.size() == 0 || inorder.size() == 0) return NULL;
TreeNode* root = new TreeNode(preorder[0]); //中节点
if(preorder.size() == 1) return root;
//根据前序的中节点切割中序
int index = 0;
for(; index < inorder.size(); index++){
if(preorder[0] == inorder[index]) break;
}
//[0, index)
vector<int> leftOfInOrder(inorder.begin(), inorder.begin() + index);
//[index + 1, end)
vector<int> rightOfInOrder(inorder.begin() + index + 1, inorder.end());
//去掉前序的第一个元素后 根据中序左数组的长度切割前序数组
for(int i = 1; i < preorder.size(); i++){
preorder[i - 1] = preorder[i];
}
preorder.resize(preorder.size() - 1); //更新数组长度
//[0, leftOfInSize)
vector<int> leftOfPreOrder(preorder.begin(), preorder.begin() + leftOfInOrder.size());
//[leftOfInSize, end)
vector<int> rightOfPreOrder(preorder.begin() + leftOfInOrder.size(), preorder.end());
//递归 向下构建树
root->left = buildTree(leftOfPreOrder, leftOfInOrder);
root->right = buildTree(rightOfPreOrder, rightOfInOrder);
return root;
}
};
class Solution {
private:
TreeNode* traversal (vector<int>& inorder, int inorderBegin, int inorderEnd, vector<int>& preorder, int preorderBegin, int preorderEnd) {
if (preorderBegin == preorderEnd) return NULL;
int rootValue = preorder[preorderBegin]; // 注意用preorderBegin 不要用0
TreeNode* root = new TreeNode(rootValue);
if (preorderEnd - preorderBegin == 1) return root;
int delimiterIndex;
for (delimiterIndex = inorderBegin; delimiterIndex < inorderEnd; delimiterIndex++) {
if (inorder[delimiterIndex] == rootValue) break;
}
// 切割中序数组
// 中序左区间,左闭右开[leftInorderBegin, leftInorderEnd)
int leftInorderBegin = inorderBegin;
int leftInorderEnd = delimiterIndex;
// 中序右区间,左闭右开[rightInorderBegin, rightInorderEnd)
int rightInorderBegin = delimiterIndex + 1;
int rightInorderEnd = inorderEnd;
// 切割前序数组
// 前序左区间,左闭右开[leftPreorderBegin, leftPreorderEnd)
int leftPreorderBegin = preorderBegin + 1;
int leftPreorderEnd = preorderBegin + 1 + delimiterIndex - inorderBegin; // 终止位置是起始位置加上中序左区间的大小size
// 前序右区间, 左闭右开[rightPreorderBegin, rightPreorderEnd)
int rightPreorderBegin = preorderBegin + 1 + (delimiterIndex - inorderBegin);
int rightPreorderEnd = preorderEnd;
cout << "----------" << endl;
cout << "leftInorder :";
for (int i = leftInorderBegin; i < leftInorderEnd; i++) {
cout << inorder[i] << " ";
}
cout << endl;
cout << "rightInorder :";
for (int i = rightInorderBegin; i < rightInorderEnd; i++) {
cout << inorder[i] << " ";
}
cout << endl;
cout << "leftPreorder :";
for (int i = leftPreorderBegin; i < leftPreorderEnd; i++) {
cout << preorder[i] << " ";
}
cout << endl;
cout << "rightPreorder :";
for (int i = rightPreorderBegin; i < rightPreorderEnd; i++) {
cout << preorder[i] << " ";
}
cout << endl;
root->left = traversal(inorder, leftInorderBegin, leftInorderEnd, preorder, leftPreorderBegin, leftPreorderEnd);
root->right = traversal(inorder, rightInorderBegin, rightInorderEnd, preorder, rightPreorderBegin, rightPreorderEnd);
return root;
}
public:
TreeNode* buildTree(vector<int>& preorder, vector<int>& inorder) {
if (inorder.size() == 0 || preorder.size() == 0) return NULL;
return traversal(inorder, 0, inorder.size(), preorder, 0, preorder.size());
}
};
654. 最大二叉树
与上一题思路差不多,都是通过切割数组(或下标)来实现递归
自己做的跟卡尔几乎一致 真滴C
class Solution {
public:
//递归
TreeNode* traversal(vector<int>& nums, int begin, int end){
//终止条件
if(begin >= end) return nullptr;
//单层遍历
//找最大值以及下标
int max = INT_MIN;
int index = begin;
int maxIndex;
for(; index < end; index++){
if(nums[index] > max){
max = nums[index];
maxIndex = index;
}
}
TreeNode* node = new TreeNode(max); //将最大值赋给根节点
//根据最大值下标切分数组 区间左闭右开
node->left = traversal(nums, begin, maxIndex);
node->right = traversal(nums, maxIndex + 1, end);
return node;
}
TreeNode* constructMaximumBinaryTree(vector<int>& nums) {
return traversal(nums, 0, nums.size());
}
};
617. 合并二叉树
终止条件要绕一下 不能只判断两个都为空的终止情况
class Solution {
public:
//递归
TreeNode* mergeTrees(TreeNode* root1, TreeNode* root2) {
if(!root1) return root2; // 如果t1为空,合并之后就应该是t2
if(!root2) return root1; // 如果t2为空,合并之后就应该是t1
//两个都不为空
TreeNode* root = new TreeNode(root1->val + root2->val);
root->left = mergeTrees(root1->left, root2->left);
root->right = mergeTrees(root1->right, root2->right);
return root;
}
};
700. 二叉搜索树中的搜索
用普通二叉树的搜索方式(自己做的):
class Solution {
public:
TreeNode* searchBST(TreeNode* root, int val) {
if(!root) return nullptr;
if(root->val == val) return root;
TreeNode* leftNode = nullptr;
TreeNode* rightNode = nullptr;
if(root->left)
leftNode = searchBST(root->left, val);
if(root->right)
rightNode = searchBST(root->right, val);
if(leftNode) return leftNode;
if(rightNode) return rightNode;
return nullptr;
}
};
注意的是 题目说的是二叉搜索树
二叉搜索树是一个有序树:
- 若它的左子树不空,则左子树上所有结点的值均小于它的根结点的值;
- 若它的右子树不空,则右子树上所有结点的值均大于它的根结点的值;
- 它的左、右子树也分别为二叉搜索树
这就决定了,二叉搜索树,递归遍历和迭代遍历和普通二叉树都不一样。
class Solution {
public:
TreeNode* searchBST(TreeNode* root, int val) {
if (root == NULL || root->val == val) return root;
if (root->val > val) return searchBST(root->left, val);
if (root->val < val) return searchBST(root->right, val);
return NULL;
}
};
二叉搜索树因其有序性,迭代法无需用栈或者队列进行模拟:
class Solution {
public:
TreeNode* searchBST(TreeNode* root, int val) {
while (root != NULL) {
if (root->val > val) root = root->left;
else if (root->val < val) root = root->right;
else return root;
}
return NULL;
}
};
98. 验证二叉搜索树
踩坑:只判断了当前分支的结点值递增关系,应该是左子树所有节点小于中间节点,右子树所有节点大于中间节点, 我对遍历顺序以及何时返回还没有形成比较规整的体系。
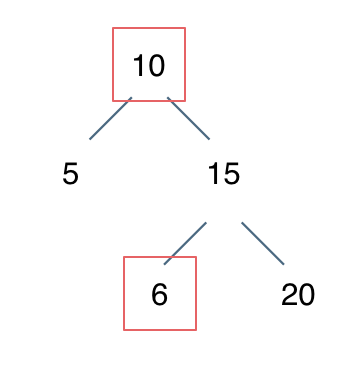
方法1:记录前一个节点 与当前节点比较
class Solution {
public:
//中序 声明一个新节点去记录上一个节点,使其与当前节点做比较
TreeNode* pre = nullptr;
bool isValidBST(TreeNode* root) {
if(!root) return true; //空节点不违反定义
//左
bool leftBST = isValidBST(root->left); //上面右空指针判定 所以空节点也可以进入递归
//中
if(pre != nullptr && pre->val >= root->val) return false; //如果是最左边的节点则必不可能执行这行 会直接到下一行的赋值
pre = root; //更新前一节点为当前节点
//右
bool rightBST = isValidBST(root->right);
return leftBST && rightBST;
}
};
方法2:将二叉搜索树转换成一个有序数组,如果不是有序则不是二叉搜索树
class Solution {
private:
vector<int> vec;
//将二叉树转换成数组,若是二叉搜索树 则数组肯定是有序的
void traversal(TreeNode* root){
if(root == NULL) return;
traversal(root->left); //左
//从最左下往数组里装节点
vec.push_back(root->val); //中
traversal(root->right); //右
return;
}
public:
bool isValidBST(TreeNode* root) {
vec.clear(); //加上最好
traversal(root);
for(int i = 1; i < vec.size(); i++){
// 注意要小于等于,搜索树里不能有相同元素
if(vec[i - 1] >= vec[i]) return false;
}
return true;
}
};
530. 二叉搜索树的最小绝对差
class Solution {
private:
//遍历树的所有节点 全部装进数组中 在数组中比较最小差值
vector<int> vec;
void traversal(TreeNode* root){
if(!root) return;
//二叉搜索树 直接左中右就是有序数组
traversal(root->left);
vec.push_back(root->val);
traversal(root->right);
return;
}
public:
int getMinimumDifference(TreeNode* root) {
traversal(root);
int min = INT_MAX;
//遍历数组 比较每两个相邻的元素的差值
for(int i = 1; i < vec.size(); i++){
int temp = abs(vec[i] - vec[i - 1]);
if(temp < min) min = temp;
}
return min;
}
};
class Solution {
public:
TreeNode* pre = NULL;
int result = INT_MAX;
//在遍历过程中就比较相邻节点的差值
void traversal(TreeNode*root){
if(!root) return;
traversal(root->left);
if(pre){
result = min(result, root->val - pre->val);
}
pre = root;
traversal(root->right);
return;
}
int getMinimumDifference(TreeNode* root) {
traversal(root);
return result;
}
};
501. 二叉搜索树中的众数
定义一个前节点来中序遍历,在遍历过程中统计数字出现的频率,实时得出最大频率并装进result数组
当最大频率刷新时,应该清空之前数组中的所有元素,这一步很关键
也可以用map来记录数值的出现次数,但是开销较大
class Solution {
private:
int maxCount = 0; // 最大频率
int count = 0; // 统计频率
TreeNode* pre = NULL;
vector<int> result;
void searchBST(TreeNode* cur) {
if (cur == NULL) return ;
searchBST(cur->left); // 左
// 中
if (pre == NULL) { // 第一个节点
count = 1;
} else if (pre->val == cur->val) { // 与前一个节点数值相同
count++;
} else { // 与前一个节点数值不同
count = 1;
}
pre = cur; // 更新上一个节点
if (count == maxCount) { // 如果和最大值相同,放进result中
result.push_back(cur->val);
}
if (count > maxCount) { // 如果计数大于最大值频率
maxCount = count; // 更新最大频率
result.clear(); // 很关键的一步,不要忘记清空result,之前result里的元素都失效了
result.push_back(cur->val);
}
searchBST(cur->right); // 右
return;
}
public:
vector<int> findMode(TreeNode* root) {
count = 0;
maxCount = 0;
pre = NULL; // 记录前一个节点
result.clear();
searchBST(root);
return result;
}
};
class Solution {
private:
TreeNode* pre = NULL; //指向前一个节点
unordered_map<int, int> map; //数字对应出现次数
void traversal(TreeNode* root){
if(!root) return; //终止条件
//中序遍历 左中右
traversal(root->left);
if(pre == NULL){
map[root->val] = 1;
}
else if(pre->val == root->val){
map[root->val]++;
}
else{
map[root->val] = 1;
}
pre = root; //刷新pre
traversal(root->right);
return;
}
public:
vector<int> findMode(TreeNode* root) {
traversal(root);
vector<int> result;
//result.push_back(root->val);
int max = 0;
for(auto i = map.begin(); i != map.end(); i++){
if(i->second > max){ //次数比max更多就刷新max和result
max = i->second;
result.clear(); //清空原来的旧众数
result.push_back(i->first);
}
else if(i->second == max){
result.push_back(i->first);
}
}
return result;
}
};
236. 二叉树的最近公共祖先
思路:
找公共祖先得自顶向上查找,首先想到后序遍历,把结果一层一层的往上送
-
情况一:当一个节点的左右子树分别出现p和q时,那他就是最近公共祖先
-
情况二:就是节点本身p(q),它拥有一个子孙节点q§
终止条件:
当前节点为空或者等于p或者q时,返回当前节点(NULL、p、q)。即当遇到空节点则返回空,如果提前遇到p或者q则无需再向下遍历,直接返回当前值即可
单层逻辑:
- 分别左右子树往下遍历
- 当左右都不为空,说明p和q分别在两侧,这时直接返回当前节点即可
- 当其中一个为空另一个不为空,说明要么p或q其中一个在一侧,要么p和q都在同一侧,需要将结果往上传递
class Solution {
public:
//后序递归 将值不断向上传递
TreeNode* lowestCommonAncestor(TreeNode* root, TreeNode* p, TreeNode* q) {
//当遇到空节点则返回空,如果提前遇到p或者q则无需再向下遍历,直接返回当前值即可
if(root == NULL || root == p || root == q) return root; //这个很关键
//单层逻辑
TreeNode* left = lowestCommonAncestor(root->left, p, q);
TreeNode* right = lowestCommonAncestor(root->right, p, q);
//两个都不为空直接返回当前节点
if(left && right) return root;
//如果其中一个为空一个不为空 则向上传递不为空的那个
else if(!left && right) return right;
else if(left && !right) return left;
//两个都为空
else return NULL;
}
};
235. 二叉搜索树的最近公共祖先
当我们从上向下去递归遍历,第一次遇到 cur节点是数值在[p, q]区间中,那么cur就是 p和q的最近公共祖先。
class Solution {
public:
TreeNode* lowestCommonAncestor(TreeNode* root, TreeNode* p, TreeNode* q) {
if(root == NULL) return root;
//比两个都小 说明祖先在左子树
if(root->val > p->val && root->val > q->val){
TreeNode* left = lowestCommonAncestor(root->left, p, q);
if(left != NULL){
return left;
}
}
//比两个都大 说明祖先在右子树
if(root->val < p->val && root->val < q->val){
TreeNode* right = lowestCommonAncestor(root->right, p, q);
if(right != NULL){
return right;
}
}
//在中间 就是最近共同祖先
return root;
}
};
701. 二叉搜索树中的插入操作
利用二叉搜索树的性质可知,其实无需改变树的结构,每个数欲插入树中,一定都能找到对应的空节点位置插入,明白了这一点后,这题就变成简单题了
递归法:
当遇到空节点时,就声明一个新节点,再向上返回给父节点的左或者右孩子即可
这题没有中节点的处理方式 只在终止条件中处理,但是个人理解上还是前序遍历的样子
class Solution {
public:
TreeNode* insertIntoBST(TreeNode* root, int val) {
//遇到空节点则终止遍历 创建新节点并返回给父节点的左或右孩子
if(root == NULL){
TreeNode* node = new TreeNode(val);
return node;
}
//利用二叉搜索树的特性
if(root->val > val) root->left = insertIntoBST(root->left, val);
if(root->val < val) root->right = insertIntoBST(root->right, val);
return root;
}
};
迭代法:
迭代法并不只是队列或者栈
声明parent指针保存要插入的节点的父节点和cur记录当前节点
class Solution {
public:
TreeNode* insertIntoBST(TreeNode* root, int val) {
if(root == NULL){
TreeNode* node = new TreeNode(val);
return node;
}
//记录当前位置和当前位置的父节点
TreeNode* cur = root;
TreeNode* parent = cur;
//定位到需要插入的位置
while(cur){
parent = cur;
if(cur->val > val) cur = cur->left;
else cur = cur->right;
}
//插入
TreeNode* node = new TreeNode(val);
if(parent->val > val) parent->left = node;
if(parent->val < val) parent->right = node;
return root;
}
};
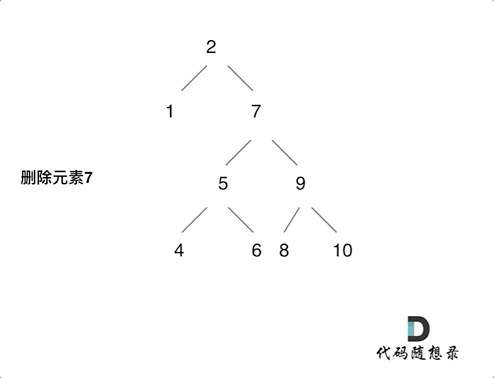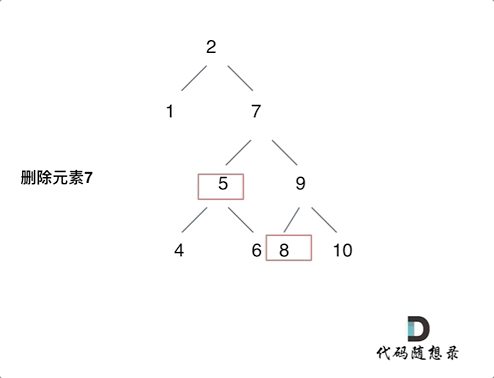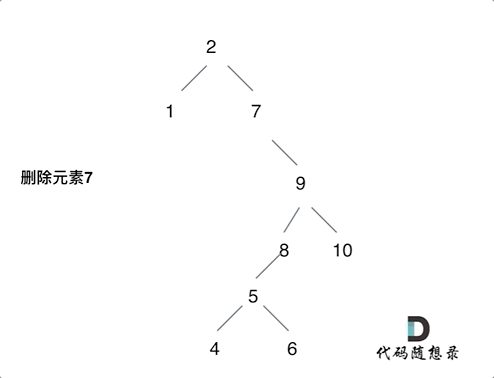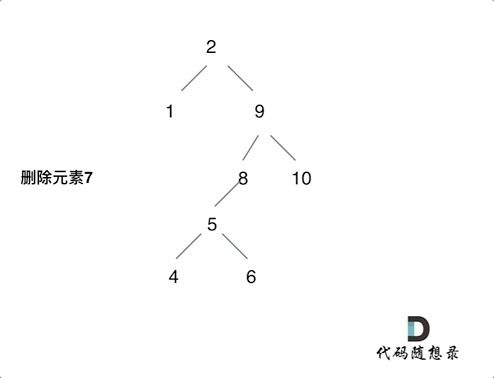
450. 删除二叉搜索树中的节点
有以下五种情况:
- 第一种情况:没找到删除的节点,遍历到空节点直接返回了
- 找到删除的节点
- 第二种情况:左右孩子都为空(叶子节点),直接删除节点, 返回NULL为根节点
- 第三种情况:删除节点的左孩子为空,右孩子不为空,删除节点,右孩子补位,返回右孩子为根节点
- 第四种情况:删除节点的右孩子为空,左孩子不为空,删除节点,左孩子补位,返回左孩子为根节点
- 第五种情况:左右孩子节点都不为空,则将左子树放到右子树的最左面节点的左孩子上,返回右孩子为新的根节点。
第五种情况有点难以理解,看下面动画:
class Solution {
public:
//递归
TreeNode* deleteNode(TreeNode* root, int key) {
if(root == NULL) return root;
//递归寻找key值对应的节点
if(root->val == key){
//左右都为空
if(root->left == NULL && root->right == NULL){
delete root;
return NULL;
}
//左右一个为空 不为空的取代之
else if(root->left == NULL){
TreeNode* node = root->right;
delete root;
return node;
}
else if(root->right == NULL){
TreeNode* node = root->left;
delete root;
return node;
}
//都不为空 将左子树放到右子树的最左面节点的左孩子上,返回右孩子为新的根节点
else{
//找右子树的最左孩子
TreeNode* cur = root->right;
while(cur->left != NULL){
cur = cur->left;
} //cur->left == NULL
cur->left = root->left;
TreeNode* node = root->right;
delete root;
return node;
}
}
//遍历左右边 返回值用于更新树的结构
else if(root->val > key) root->left = deleteNode(root->left, key);
else if(root->val < key) root->right = deleteNode(root->right, key);
return root;
}
};
669. 修剪二叉搜索树
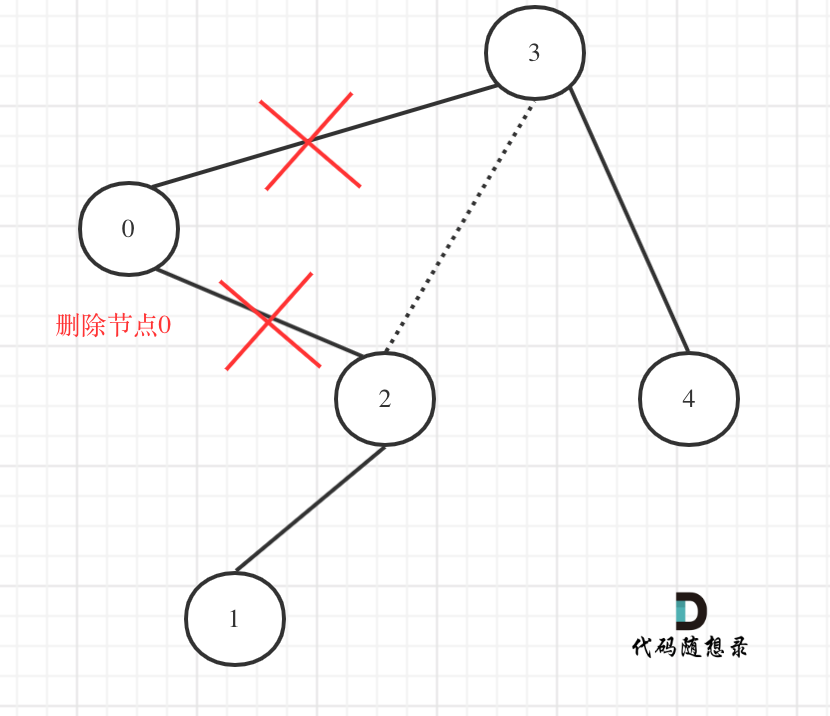
class Solution {
public:
//隐藏了删除节点的步骤 其实就是取而代之
TreeNode* trimBST(TreeNode* root, int low, int high) {
if (root == nullptr) return nullptr;
if (root->val < low) {
TreeNode* right = trimBST(root->right, low, high); //右子树中可能有符合区间的值(左子树不可能)
return right;
}
if (root->val > high) {
TreeNode* left = trimBST(root->left, low, high); //左子树可能有符合区间的值
return left;
}
//更新左右子树
root->left = trimBST(root->left, low, high);
root->right = trimBST(root->right, low, high);
return root;
}
};
108. 将有序数组转换为二叉搜索树
如果要分割的数组长度为偶数的时候,中间元素为两个,是取左边元素 就是树1,取右边元素就是树2。
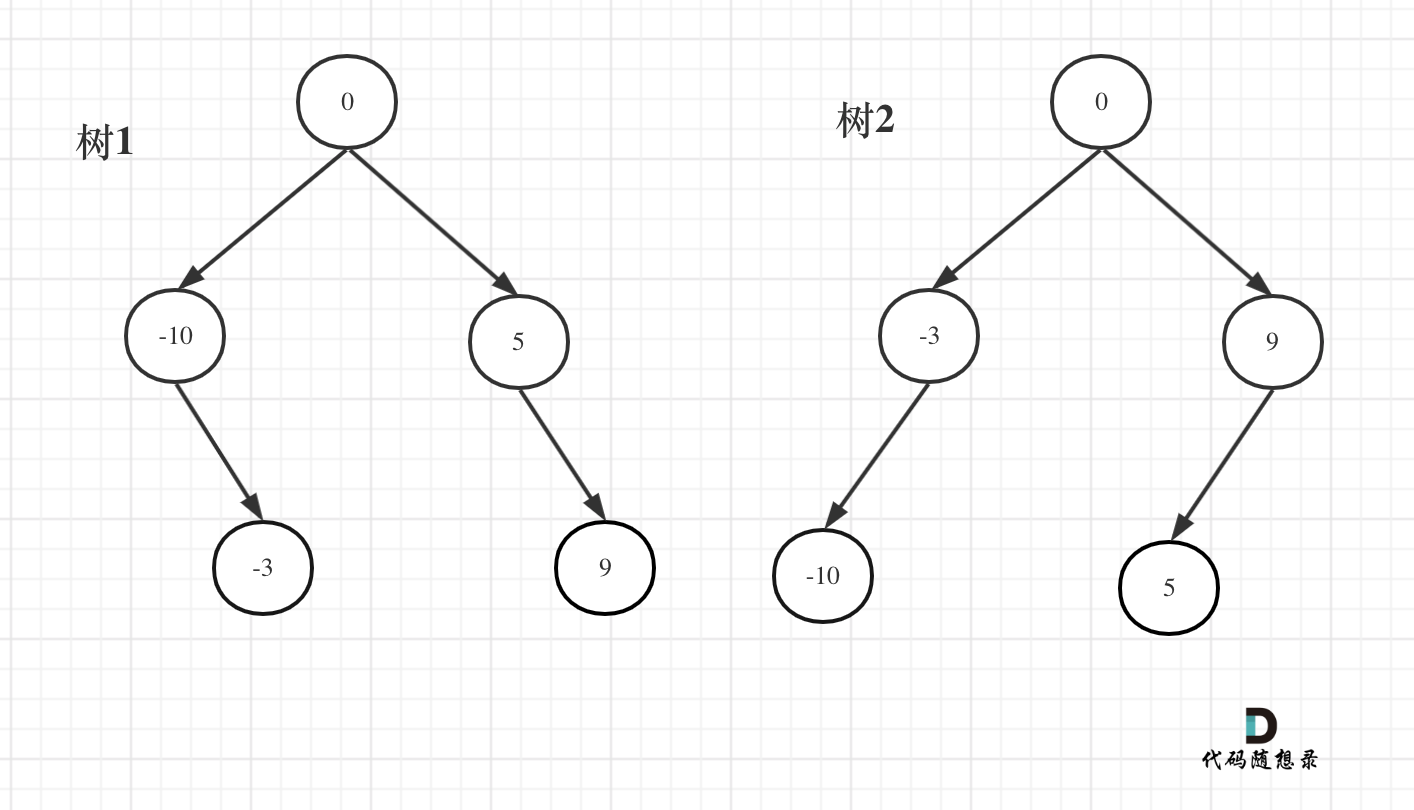
删除二叉树节点,增加二叉树节点,都是用递归函数的返回值来完成,这样是比较方便的。
采用左闭右闭区间
踩坑:
int mid = begin + (end - begin) / 2;或者int mid = (left + right) / 2;而不是int mid = (end - begin) / 2;
traversal(nums, begin, mid - 1);而不是traversal(nums, begin, mid);
class Solution {
public:
//二分法递归的选择中间元素作为根节点
TreeNode* traversal(vector<int>& nums, int begin, int end) {
if(end < begin) return NULL; //区间无元素
//偶数时取中间左边的数
int mid = begin + (end - begin) / 2; //不要忘记加begin+
TreeNode* root = new TreeNode(nums[mid]);
//左闭右闭
root->left = traversal(nums, begin, mid - 1);
root->right = traversal(nums, mid + 1, end);
return root;
}
TreeNode* sortedArrayToBST(vector<int>& nums) {
TreeNode* root = traversal(nums, 0, nums.size() - 1);
return root;
}
};
538. 把二叉搜索树转换为累加树
右中左来遍历二叉树
直接AC(真的帅)
class Solution {
public:
//累加树:每个节点的新值等于原树中大于或等于 node.val 的值之和。
//直接利用搜索树的特性:最右下角的节点一定是最大值
//从右往左 从下往上递归累加值 同时更改当前节点的值
int sum = 0;
void traversal(TreeNode* root){
if(root == NULL) return;
traversal(root->right);
sum += root->val;
root->val = sum;
traversal(root->left);
return;
}
TreeNode* convertBST(TreeNode* root) {
traversal(root);
return root;
}
};
二叉树:总结篇!
力扣二叉树大总结!
不知不觉二叉树已经和我们度过了三十三天,「代码随想录」 (opens new window)里已经发了三十三篇二叉树的文章,详细讲解了30+二叉树经典题目,一直坚持下来的录友们一定会二叉树有深刻理解了。
在每一道二叉树的题目中,我都使用了递归三部曲来分析题目,相信大家以后看到二叉树,看到递归,都会想:返回值、参数是什么?终止条件是什么?单层逻辑是什么?
而且几乎每一道题目我都给出对应的迭代法,可以用来进一步提高自己。
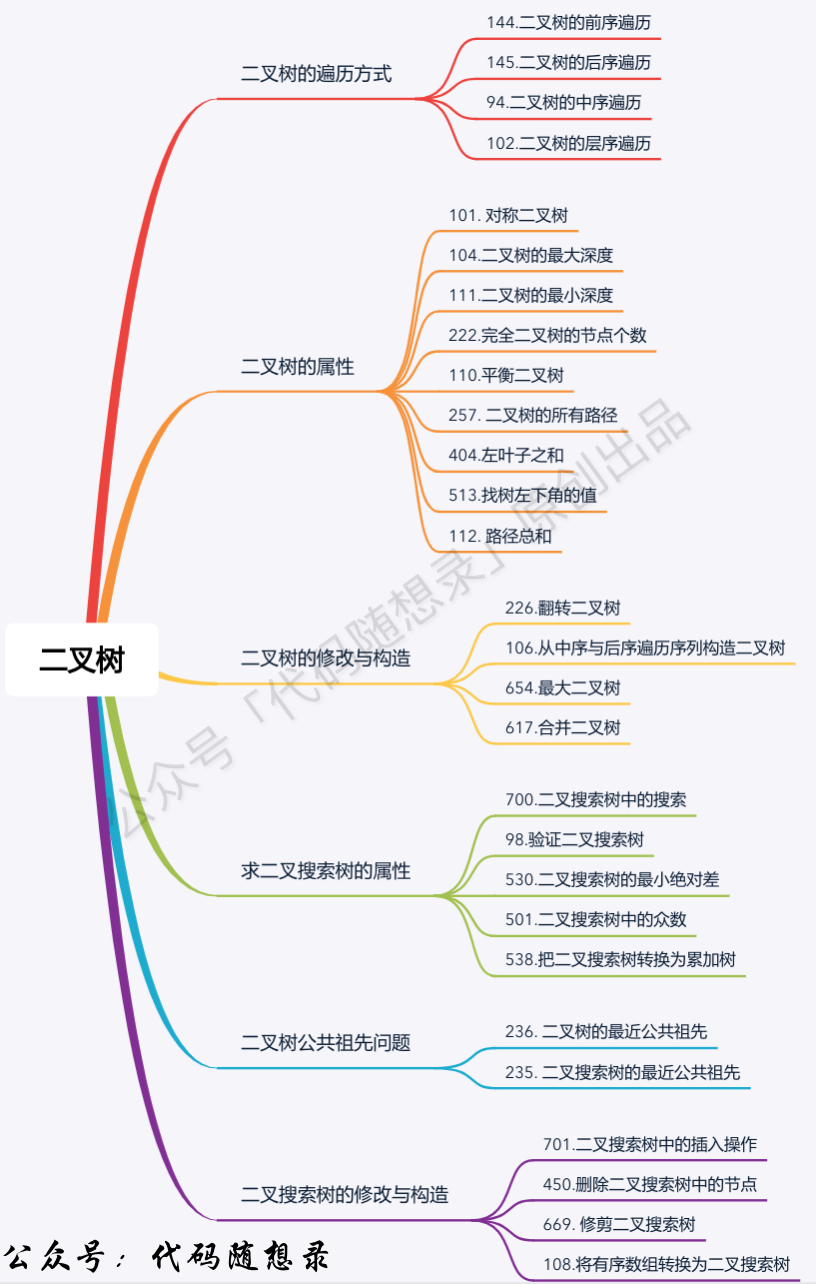
下面Carl把分析过的题目分门别类,可以帮助新录友循序渐进学习二叉树,也方便老录友面试前快速复习,看到一个标题,就回想一下对应的解题思路,这样很快就可以系统性的复习一遍二叉树了。
公众号的发文顺序,就是循序渐进的,所以如下分类基本就是按照文章发文顺序来的,我再做一个系统性的分类。
#二叉树的理论基础
- 关于二叉树,你该了解这些! (opens new window):二叉树的种类、存储方式、遍历方式、定义方式
#二叉树的遍历方式
- 深度优先遍历
- 广度优先遍历
- 二叉树的层序遍历 (opens new window):通过队列模拟
#求二叉树的属性
- 二叉树:是否对称(opens new window)
- 递归:后序,比较的是根节点的左子树与右子树是不是相互翻转
- 迭代:使用队列/栈将两个节点顺序放入容器中进行比较
- 二叉树:求最大深度(opens new window)
- 递归:后序,求根节点最大高度就是最大深度,通过递归函数的返回值做计算树的高度
- 迭代:层序遍历
- 二叉树:求最小深度(opens new window)
- 递归:后序,求根节点最小高度就是最小深度,注意最小深度的定义
- 迭代:层序遍历
- 二叉树:求有多少个节点(opens new window)
- 递归:后序,通过递归函数的返回值计算节点数量
- 迭代:层序遍历
- 二叉树:是否平衡(opens new window)
- 递归:后序,注意后序求高度和前序求深度,递归过程判断高度差
- 迭代:效率很低,不推荐
- 二叉树:找所有路径(opens new window)
- 递归:前序,方便让父节点指向子节点,涉及回溯处理根节点到叶子的所有路径
- 迭代:一个栈模拟递归,一个栈来存放对应的遍历路径
- 二叉树:递归中如何隐藏着回溯(opens new window)
- 详解二叉树:找所有路径 (opens new window)中递归如何隐藏着回溯
- 二叉树:求左叶子之和(opens new window)
- 递归:后序,必须三层约束条件,才能判断是否是左叶子。
- 迭代:直接模拟后序遍历
- 二叉树:求左下角的值(opens new window)
- 递归:顺序无所谓,优先左孩子搜索,同时找深度最大的叶子节点。
- 迭代:层序遍历找最后一行最左边
- 二叉树:求路径总和(opens new window)
- 递归:顺序无所谓,递归函数返回值为bool类型是为了搜索一条边,没有返回值是搜索整棵树。
- 迭代:栈里元素不仅要记录节点指针,还要记录从头结点到该节点的路径数值总和
#二叉树的修改与构造
- 翻转二叉树(opens new window)
- 递归:前序,交换左右孩子
- 迭代:直接模拟前序遍历
- 构造二叉树(opens new window)
- 递归:前序,重点在于找分割点,分左右区间构造
- 迭代:比较复杂,意义不大
- 构造最大的二叉树(opens new window)
- 递归:前序,分割点为数组最大值,分左右区间构造
- 迭代:比较复杂,意义不大
- 合并两个二叉树(opens new window)
- 递归:前序,同时操作两个树的节点,注意合并的规则
- 迭代:使用队列,类似层序遍历
#求二叉搜索树的属性
- 二叉搜索树中的搜索(opens new window)
- 递归:二叉搜索树的递归是有方向的
- 迭代:因为有方向,所以迭代法很简单
- 是不是二叉搜索树(opens new window)
- 递归:中序,相当于变成了判断一个序列是不是递增的
- 迭代:模拟中序,逻辑相同
- 求二叉搜索树的最小绝对差(opens new window)
- 递归:中序,双指针操作
- 迭代:模拟中序,逻辑相同
- 求二叉搜索树的众数(opens new window)
- 递归:中序,清空结果集的技巧,遍历一遍便可求众数集合
- 二叉搜索树转成累加树(opens new window)
- 递归:中序,双指针操作累加
- 迭代:模拟中序,逻辑相同
#二叉树公共祖先问题
- 二叉树的公共祖先问题(opens new window)
- 递归:后序,回溯,找到左子树出现目标值,右子树节点目标值的节点。
- 迭代:不适合模拟回溯
- 二叉搜索树的公共祖先问题(opens new window)
- 递归:顺序无所谓,如果节点的数值在目标区间就是最近公共祖先
- 迭代:按序遍历
#二叉搜索树的修改与构造
- 二叉搜索树中的插入操作(opens new window)
- 递归:顺序无所谓,通过递归函数返回值添加节点
- 迭代:按序遍历,需要记录插入父节点,这样才能做插入操作
- 二叉搜索树中的删除操作(opens new window)
- 递归:前序,想清楚删除非叶子节点的情况
- 迭代:有序遍历,较复杂
- 修剪二叉搜索树(opens new window)
- 递归:前序,通过递归函数返回值删除节点
- 迭代:有序遍历,较复杂
- 构造二叉搜索树(opens new window)
- 递归:前序,数组中间节点分割
- 迭代:较复杂,通过三个队列来模拟
#阶段总结
大家以上题目都做过了,也一定要看如下阶段小结。
每周小结都会对大家的疑问做统一解答,并且对每周的内容进行拓展和补充,所以一定要看,将细碎知识点一网打尽!
- 本周小结!(二叉树系列一)(opens new window)
- 本周小结!(二叉树系列二)(opens new window)
- 本周小结!(二叉树系列三)(opens new window)
- 本周小结!(二叉树系列四)(opens new window)
#最后总结
在二叉树题目选择什么遍历顺序是不少同学头疼的事情,我们做了这么多二叉树的题目了,Carl给大家大体分分类。
- 涉及到二叉树的构造,无论普通二叉树还是二叉搜索树一定前序,都是先构造中节点。
- 求普通二叉树的属性,一般是后序,一般要通过递归函数的返回值做计算。
- 求二叉搜索树的属性,一定是中序了,要不白瞎了有序性了。
注意在普通二叉树的属性中,我用的是一般为后序,例如单纯求深度就用前序,二叉树:找所有路径 (opens new window)也用了前序,这是为了方便让父节点指向子节点。
所以求普通二叉树的属性还是要具体问题具体分析。
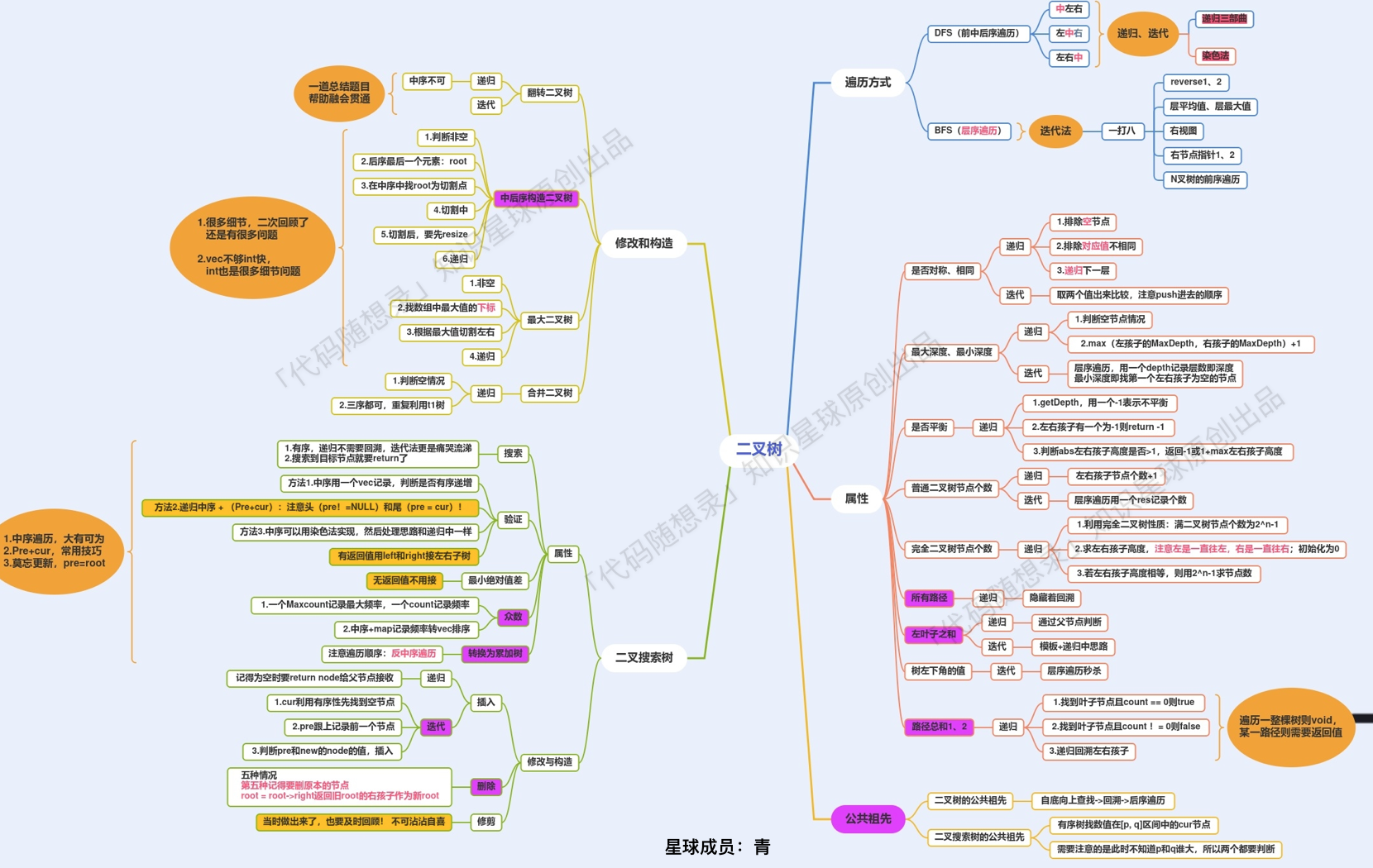
二叉树专题汇聚为一张图:


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言










{kind=link}