







来自代码随想录的刷题路线:代码随想录
回溯算法:
理论篇:
- 回溯是一种搜索的方式,回溯是递归的副产品,只有有递归就会有回溯。
- 回溯很难理解,但是性能并不好,因为回溯的本质是穷举所有可能。最多加一些剪枝的操作。
- 用它解决的都是一些只能暴力的题目(在集合中递归寻找子集)。
- 回溯算法不用分析时间复杂度了,都是一样的爆搜,就看谁剪枝厉害了。
- 一般说道回溯算法的复杂度,都说是指数级别的时间复杂度
能解决的问题:
用更简便的方法避免使用k层for循环嵌套,都是在集合中递归查找子集:
- 组合问题:N个数里面按一定规则找出k个数的集合
- 切割问题:一个字符串按一定规则有几种切割方式
- 子集问题:一个N个数的集合里有多少符合条件的子集
- 排列问题:N个数按一定规则全排列,有几种排列方式
- 棋盘问题:N皇后,解数独等等
组合无序,排列有序
解决的问题都可以抽象为树形结构
-
集合的大小构成树的宽度,递归的深度构成树的深度。
-
递归就要有终止条件,所以必然是一棵高度有限的N叉树
回溯法模板
在讲二叉树的递归中我们说了递归三部曲,这里我再给大家列出回溯三部曲。
- 回溯函数模板返回值以及参数:
在回溯算法中,我的习惯是函数起名字为backtracking,这个起名大家随意。
回溯算法中函数返回值一般为void。
再来看一下参数,因为回溯算法需要的参数可不像二叉树递归的时候那么容易一次性确定下来,所以一般是先写逻辑,然后需要什么参数,就填什么参数。
但后面的回溯题目的讲解中,为了方便大家理解,我在一开始就帮大家把参数确定下来。
- 回溯函数终止条件:
既然是树形结构,就知道遍历树形结构一定要有终止条件。
树中就可以看出,一般来说搜到叶子节点了,也就找到了满足条件的一条答案,把这个答案存放起来,并结束本层递归。
- 回溯搜索的遍历过程
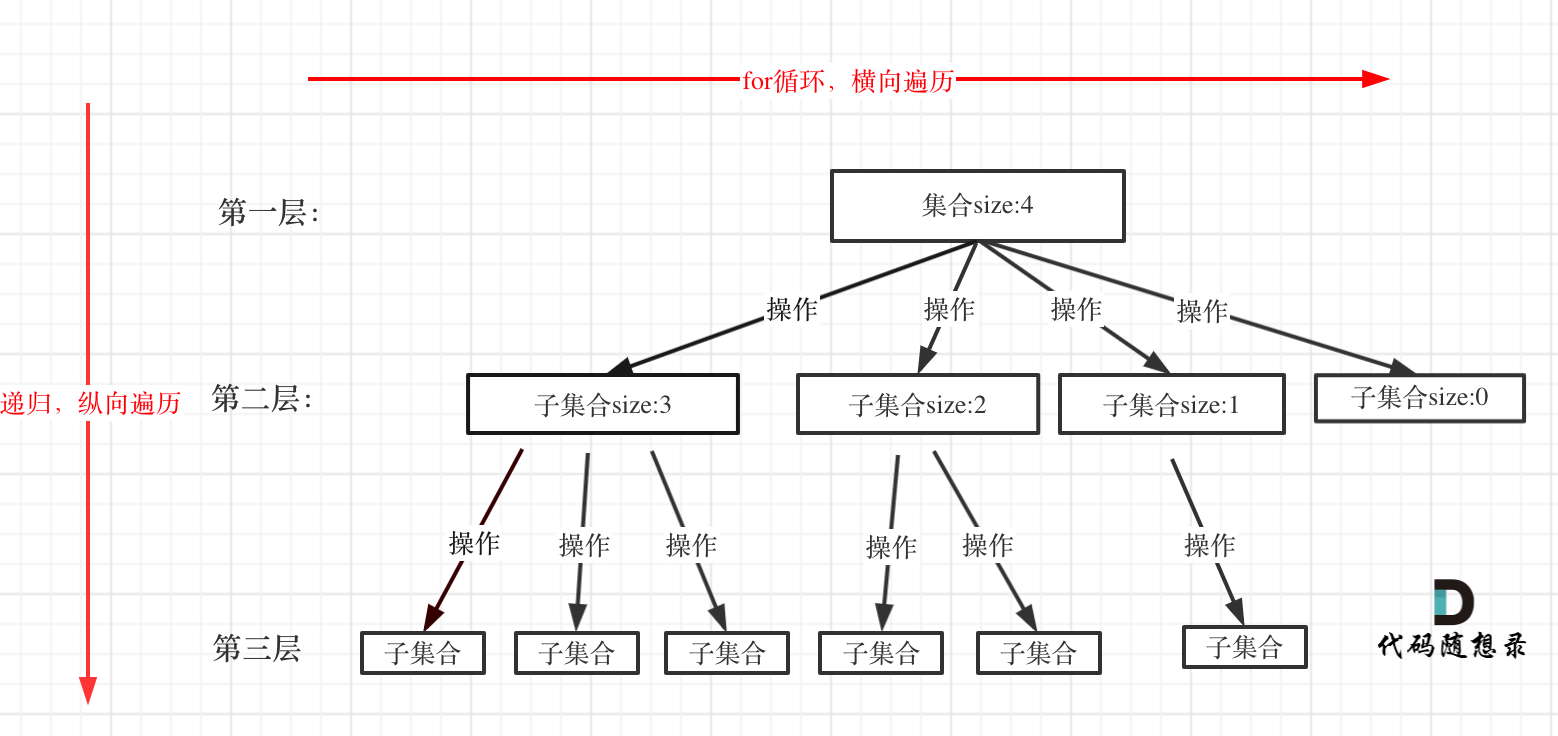
注意图中,我特意举例集合大小和孩子的数量是相等的!
for循环就是遍历集合区间,可以理解一个节点有多少个孩子,这个for循环就执行多少次。
backtracking这里自己调用自己,实现递归。
for循环可以理解是横向遍历,backtracking(递归)就是纵向遍历,这样就把这棵树全遍历完了,一般来说,搜索叶子节点就是找的其中一个结果了。
- 回溯算法模板框架如下:
void backtracking(参数) { //返回值以及参数
//终止条件
if (终止条件) {
存放结果;
return;
}
//遍历过程
for (选择:本层集合中元素(树中节点孩子的数量就是集合的大小)) {
处理节点;
backtracking(路径,选择列表); // 递归
回溯,撤销处理结果;
}
}
这份模板很重要,后面做回溯法的题目都靠它了!
77. 组合
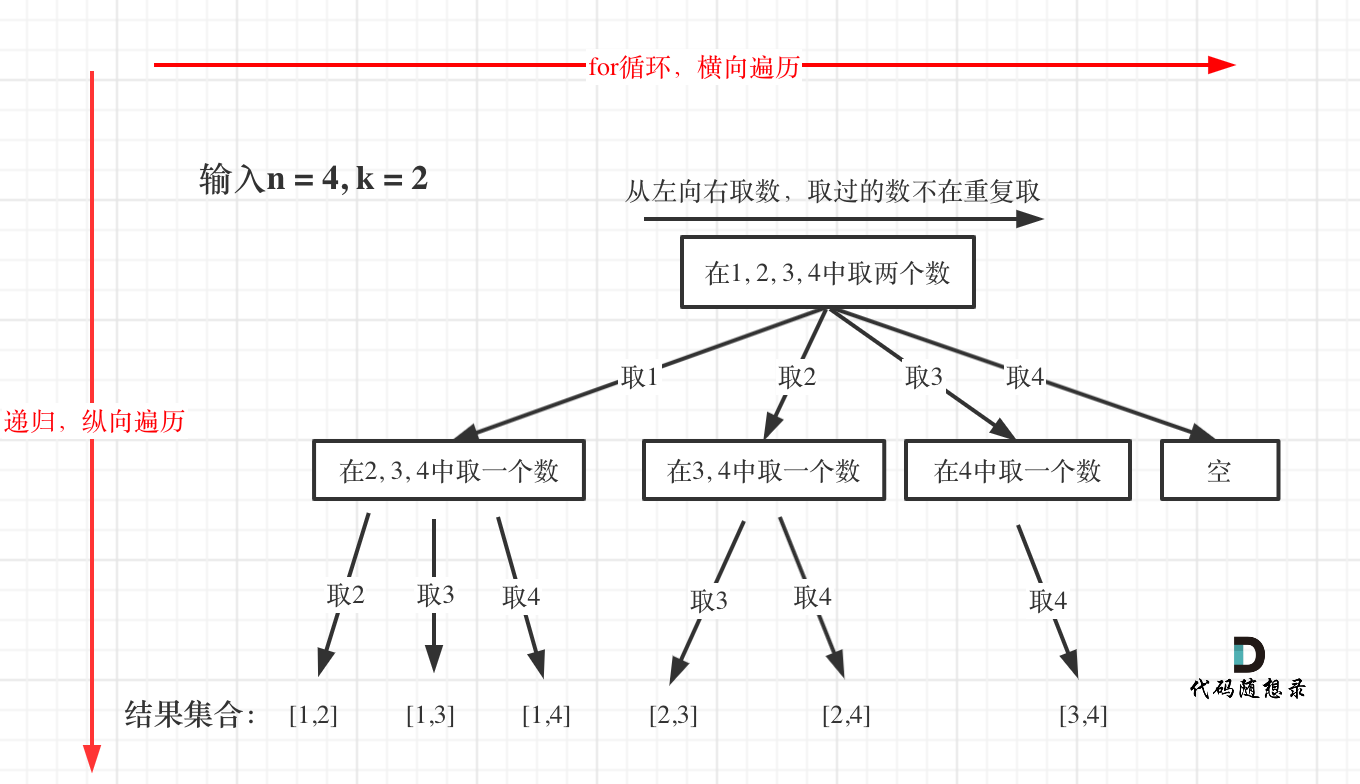
n相当于树的宽度,k相当于树的深度
踩坑犯错:

正确题解:
class Solution {
private:
vector<int> vec; //单个组合
vector<vector<int>> result;
void backtracking(int n, int k, int begin){ //begin用来记录下一层递归,搜索的起始位置
if(vec.size() == k){ //终止条件
result.push_back(vec); //保存结果
return; //这里return则无需进行下面的递归和回溯
}
//遍历过程
for(int i = begin; i <= n; i++){ //第一层是全部数 数字递增,逐层减少数字总数
vec.push_back(i);
backtracking(n, k, i + 1); //不要写成begin + 1
vec.pop_back(); //回溯撤销当前数
}
return;
}
public:
vector<vector<int>> combine(int n, int k) {
if(k > n) return result; //剪枝
backtracking(n, k, 1);
return result;
}
};
- 时间复杂度: O(n * 2^n)
- 空间复杂度: O(n)
剪枝优化:
我们说过,回溯法虽然是暴力搜索,但也有时候可以有点剪枝优化一下的。
在遍历的过程中有如下代码:
for (int i = startIndex; i <= n; i++) {
path.push_back(i);
backtracking(n, k, i + 1);
path.pop_back();
}
这个遍历的范围是可以剪枝优化的,怎么优化呢?
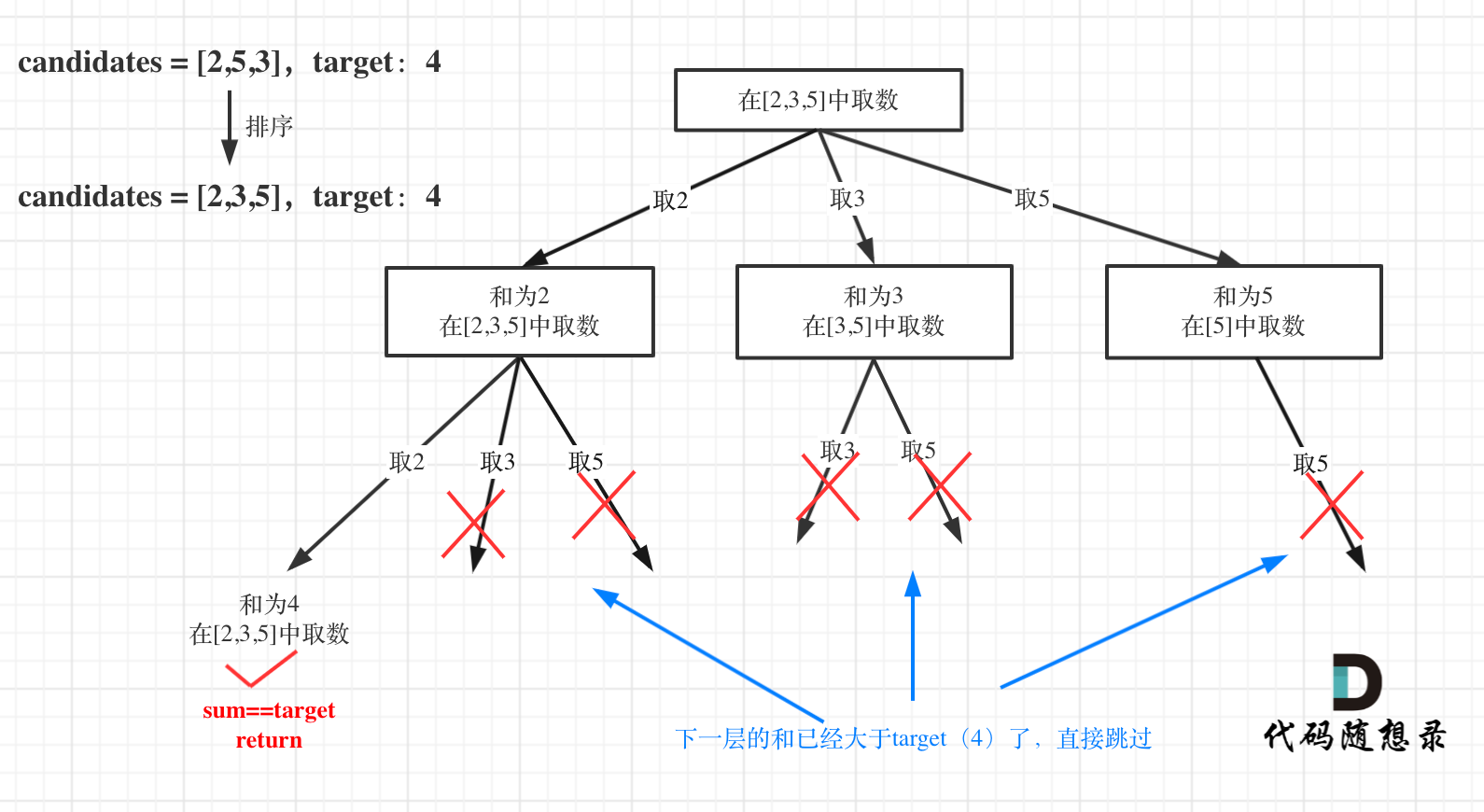
来举一个例子,n = 4,k = 4的话,那么第一层for循环的时候,从元素2开始的遍历都没有意义了。 在第二层for循环,从元素3开始的遍历都没有意义了。
这么说有点抽象,如图所示:
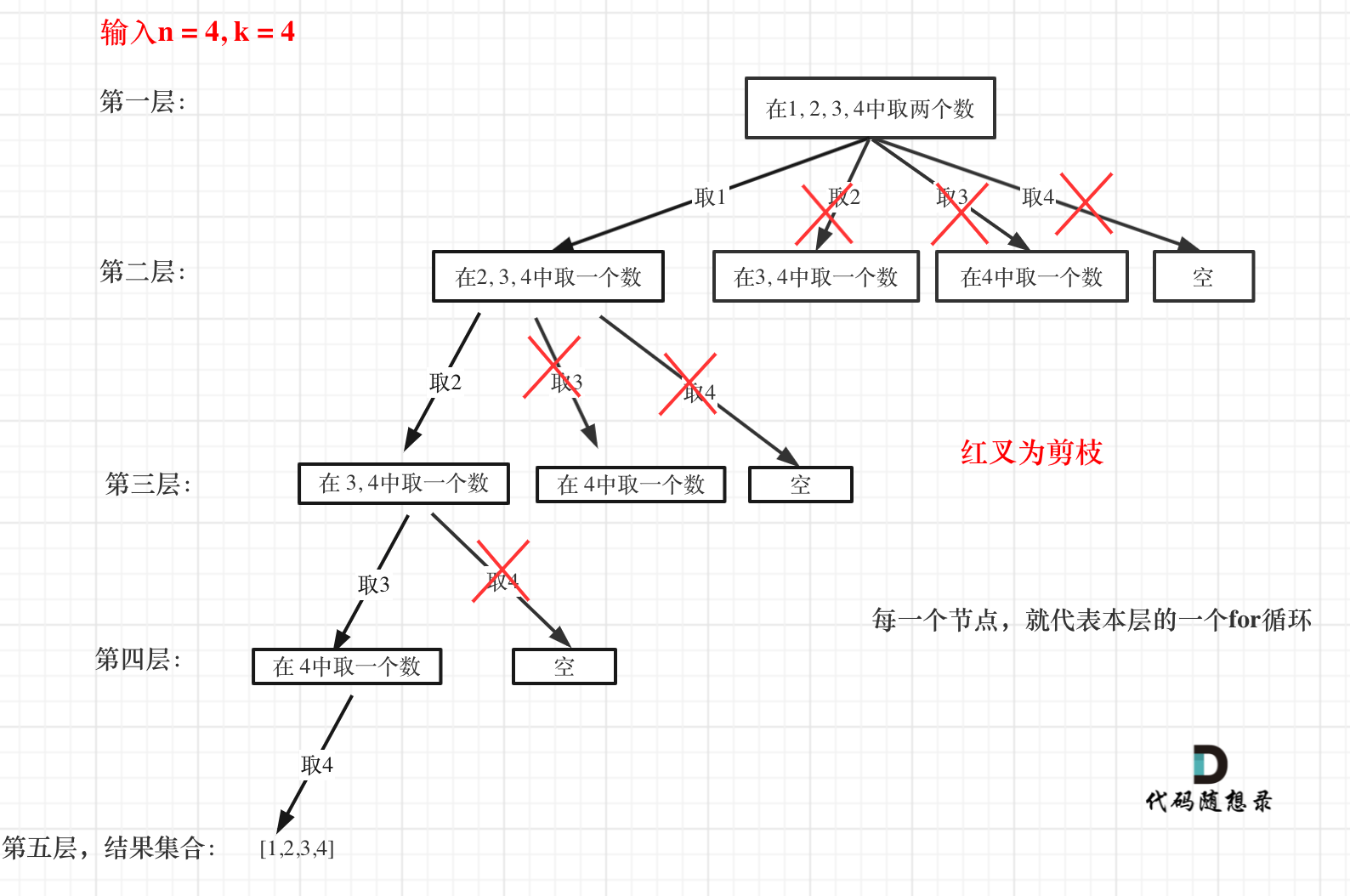
图中每一个节点(图中为矩形),就代表本层的一个for循环,那么每一层的for循环从第二个数开始遍历的话,都没有意义,都是无效遍历。
所以,可以剪枝的地方就在递归中每一层的for循环所选择的起始位置。
我的踩坑犯错,就是错在终止位置去剪枝
结论是:如果for循环选择的起始位置之后的元素个数 已经不足 我们需要的元素个数了,那么就没有必要搜索了。
注意代码中i,就是for循环里选择的起始位置。
for (int i = startIndex; i <= n; i++) {
接下来看一下优化过程如下:
- 已经选择的元素个数:path.size();
- 还需要的元素个数为: k - path.size();
- 在集合n中至多要从该起始位置 : n - (k - path.size()) + 1,开始遍历
为什么有个+1呢,因为包括起始位置,我们要是一个左闭的集合。
举个例子,n = 4,k = 3, 目前已经选取的元素为0(path.size为0),n - (k - 0) + 1 即 4 - ( 3 - 0) + 1 = 2。
从2开始搜索都是合理的,可以是组合[2, 3, 4]。
这里大家想不懂的话,建议也举一个例子,就知道是不是要+1了。
所以优化之后的for循环是:
for (int i = startIndex; i <= n - (k - path.size()) + 1; i++) // i为本次搜索的起始位置
216. 组合总和 III
class Solution {
private:
vector<vector<int>> result; // 存放结果集
vector<int> path; // 符合条件的结果
void backtracking(int targetSum, int k, int sum, int startIndex) {
if (sum > targetSum) { // 剪枝操作
return;
}
if (path.size() == k) {
if (sum == targetSum) result.push_back(path);
return; // 如果path.size() == k 但sum != targetSum 直接返回
}
for (int i = startIndex; i <= 9 - (k - path.size()) + 1; i++) { // 剪枝
sum += i; // 处理
path.push_back(i); // 处理
backtracking(targetSum, k, sum, i + 1); // 注意i+1调整startIndex
sum -= i; // 回溯
path.pop_back(); // 回溯
}
}
public:
vector<vector<int>> combinationSum3(int k, int n) {
result.clear(); // 可以不加
path.clear(); // 可以不加
backtracking(n, k, 0, 1);
return result;
}
};
- 应该是
i <= 9而不是跟上题那样i <= n- 注意剪枝操作
17. 电话号码的字母组合
问题依旧是,不知道会输入几个按键,也就是不知道得用几层for循环去遍历输出组合
需要解决的问题有:
数字和字母如何映射:
可以使用map或者定义一个二维数组,例如:string letterMap[10],来做映射,我这里定义一个二维数组,以此对应按键号码,代码如下:
const string letterMap[10] = {
"", // 0
"", // 1
"abc", // 2
"def", // 3
"ghi", // 4
"jkl", // 5
"mno", // 6
"pqrs", // 7
"tuv", // 8
"wxyz", // 9
};
两个字符就两个for循环,三个字符我就三个for循环??:
对他使用回溯吧!
这题依然可以抽象为树形结构,但是明显跟上面两题的结构不同
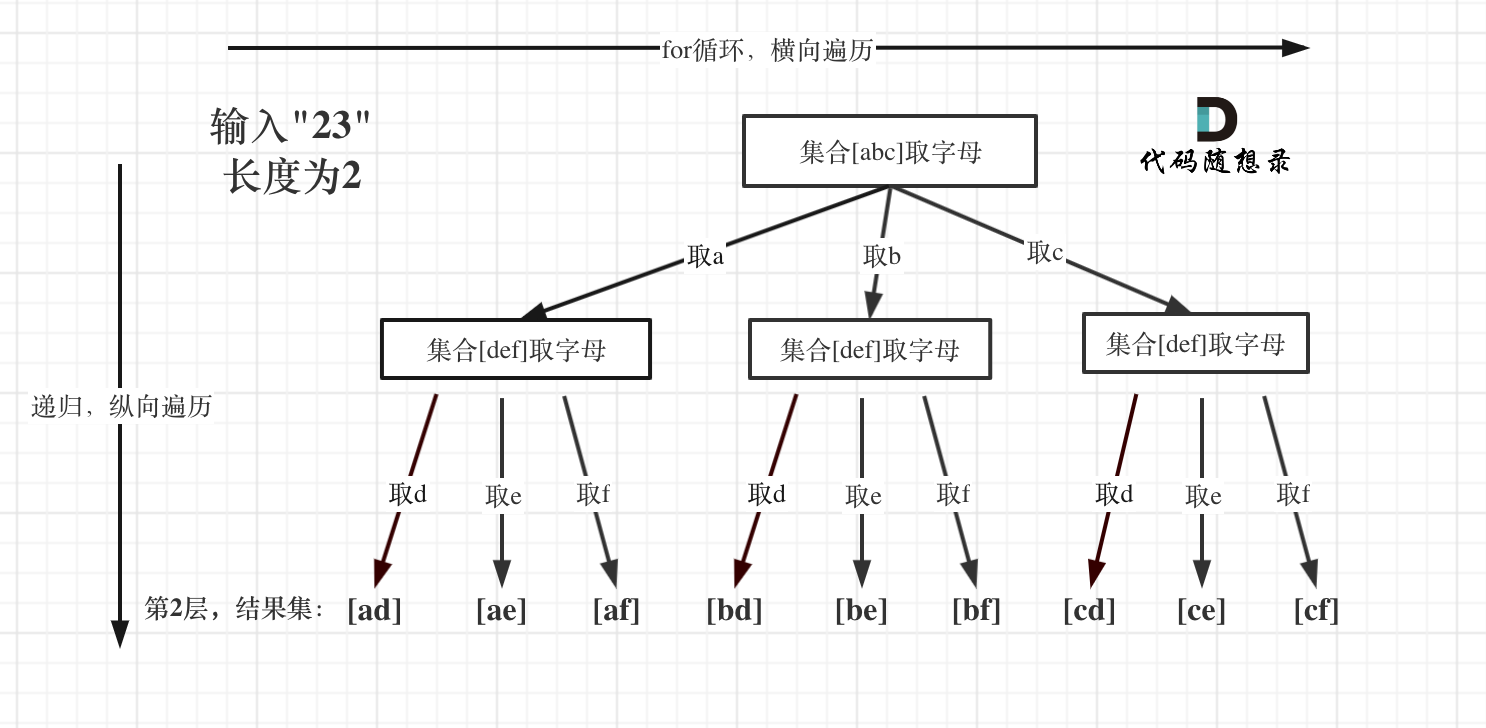
图中可以看出:
-
遍历的深度,就是输入"23"的长度;
-
叶子节点就是我们要收集的结果,输出[“ad”, “ae”, “af”, “bd”, “be”, “bf”, “cd”, “ce”, “cf”]。
输入1 * #按键等等异常情况
测试数据中并没有这些特殊情况,所以不加特殊情况处理了,但是面试时得注意!
代码如下:
class Solution {
private:
const string letterMap[10] = { //电话号码按键对字母的映射
"", // 0
"", // 1
"abc", // 2
"def", // 3
"ghi", // 4
"jkl", // 5
"mno", // 6
"pqrs", // 7
"tuv", // 8
"wxyz", // 9
};
public:
vector<string> result;
string s;
void backtracking(const string& digits, int index) { //index是记录遍历第几个数字
if(index == digits.size()){ //终止条件
result.push_back(s);
return;
}
int digit = digits[index] - '0'; //提取index指向的数字
string letters = letterMap[digit]; //找到这个数字对应的字母集
for(int i = 0; i < letters.size(); i++){
s.push_back(letters[i]); //处理
backtracking(digits, index + 1); //这里是index + 1,指已经存储的数增加了一个,也是下一层遍历对应的号码按键序号
s.pop_back(); //回溯
}
return;
}
public:
vector<string> letterCombinations(string digits) {
if(digits.size() == 0) return result;
backtracking(digits, 0);
return result;
}
};
- 时间复杂度: O(3^m * 4^n),其中 m 是对应四个字母的数字个数,n 是对应三个字母的数字个数
- 空间复杂度: O(3^m * 4^n)
39. 组合总和
十分钟秒了,有什么好说的
与前面的216题大题一致,除了:
组合没有数量要求
元素可无限重复选取
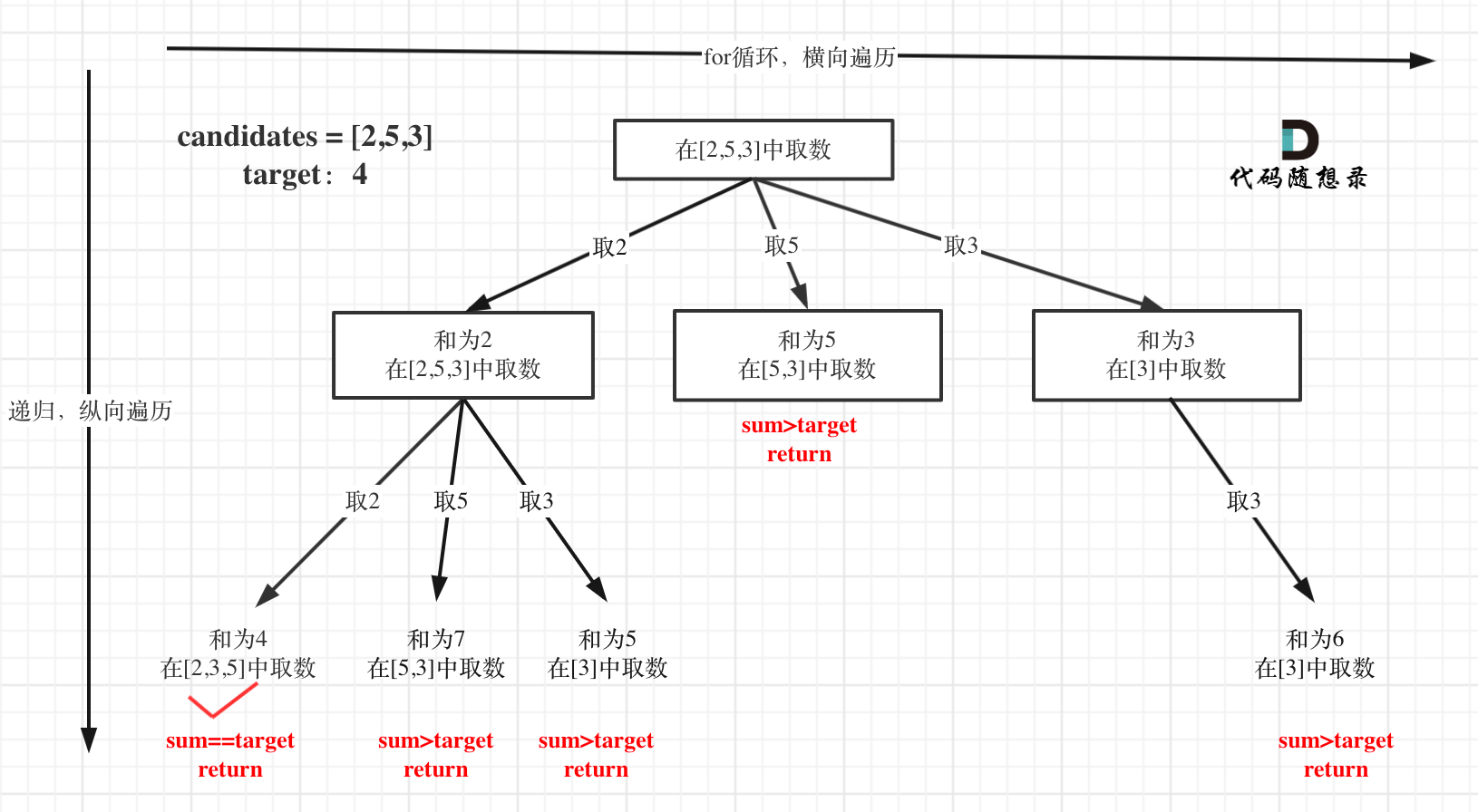
剪枝优化:
先给取数数组排个序sort(candidates.begin(), candidates.end());,当下一层的总和已经大于target时,直接结束本轮循环。也就是只有当sum + candidates[i]时才进入循环:
class Solution {
private:
vector<vector<int>> result;
vector<int> path;
void backtracking(vector<int>& candidates, int target, int sum, int startIndex) {
if (sum == target) {
result.push_back(path);
return;
}
// 如果 sum + candidates[i] > target 就终止遍历
for (int i = startIndex; i < candidates.size() && sum + candidates[i] <= target; i++) {
sum += candidates[i];
path.push_back(candidates[i]);
backtracking(candidates, target, sum, i);
sum -= candidates[i];
path.pop_back();
}
}
public:
vector<vector<int>> combinationSum(vector<int>& candidates, int target) {
result.clear();
path.clear();
sort(candidates.begin(), candidates.end()); // 需要排序
backtracking(candidates, target, 0, 0);
return result;
}
};
40. 组合总和 II
这道题目39题不同的是:
- 本题candidates 中的每个数字在每个组合中只能使用一次。
- 本题数组candidates的元素是有重复的,而39题是无重复元素的数组candidates
自己做的,在结果处去重,有几个案例会超时。
还可以用set或者map去重,但也会超
class Solution {
public:
int curSum = 0;
vector<int> path;
vector<vector<int>> result;
void backtracking(vector<int>& candidates, int target, int begin){
if(curSum > target) return;
if(curSum == target){
bool repeat = false;
for(vector<int> i : result){
if(i == path)
repeat = true;
}
if(!repeat)
result.push_back(path);
return;
}
for(int i = begin; i < candidates.size() && curSum + candidates[i] <= target; i++){
curSum += candidates[i];
path.push_back(candidates[i]);
backtracking(candidates, target, i + 1);
curSum -= candidates[i];
path.pop_back();
}
return;
}
vector<vector<int>> combinationSum2(vector<int>& candidates, int target) {
sort(candidates.begin(), candidates.end());
backtracking(candidates, target, 0);
return result;
}
};
所以应该在遍历过程中去重(要对数组排序):
去重,其实就是使用过的元素不能重复选取,使用过又分为在树枝上使用过和树层上使用过。其中树枝指的是往下遍历的路径。
元素在同一个组合内是可以重复的,怎么重复都没事,但两个组合不能相同。
往下遍历到相同的数都是一个组合里的元素,并不是曾使用过的数,故无需去重;也就是树枝上无需去重。
所以我们要去重的是同一树层上的“使用过”,也就是说,在同一树层中不能有存在重复元素,也就是for循环中要去重。因为在for循环中,前面分支的某个数的遍历,肯定包含了后面的相同数的组合。详细可以看下面视频:
如何判断同一树层上元素(相同的元素)是否使用过了呢?代码如下
// 要对同一树层使用过的元素进行跳过
if (i > startIndex && candidates[i] == candidates[i - 1]) { //不是分割的头个元素且与上一个元素相等 说明是重复元素 直接跳过即可
continue;
}
class Solution {
private:
vector<vector<int>> result;
vector<int> path;
void backtracking(vector<int>& candidates, int target, int sum, int startIndex) {
if (sum == target) {
result.push_back(path);
return;
}
for (int i = startIndex; i < candidates.size() && sum + candidates[i] <= target; i++) {
// 要对同一树层使用过的元素进行跳过
if (i > startIndex && candidates[i] == candidates[i - 1]) {
continue;
}
sum += candidates[i];
path.push_back(candidates[i]);
backtracking(candidates, target, sum, i + 1); // 和39.组合总和的区别1,这里是i+1,每个数字在每个组合中只能使用一次
sum -= candidates[i];
path.pop_back();
}
}
public:
vector<vector<int>> combinationSum2(vector<int>& candidates, int target) {
path.clear();
result.clear();
// 首先把给candidates排序,让其相同的元素都挨在一起。
sort(candidates.begin(), candidates.end());
backtracking(candidates, target, 0, 0);
return result;
}
};
131. 分割回文串
本题这涉及到两个关键问题:
- 切割问题,有不同的切割方式
- 判断回文
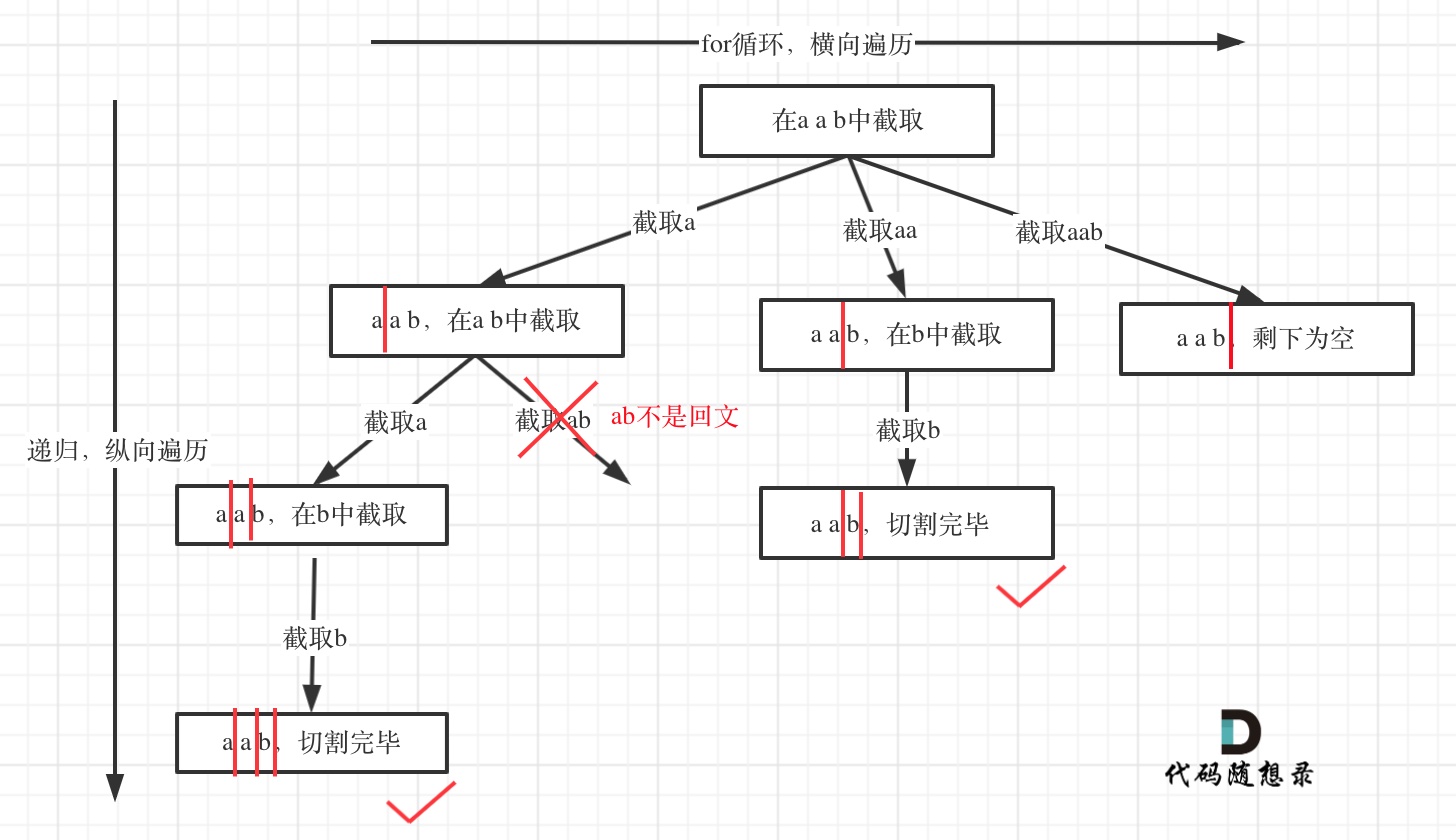
从树形结构的图中可以看出:切割线切到了字符串最后面,说明找到了一种切割方法,此时就是本次递归的终止条件。
切割线(就是图中的红线)切割到字符串的结尾位置,说明找到了一个切割方法。
那么在代码里什么是切割线呢?
在处理组合问题的时候,递归参数需要传入startIndex,表示下一轮递归遍历的起始位置,这个startIndex就是切割线。
在递归循环中如何截取子串呢?
在for (int i = startIndex; i < s.size(); i++)循环中,我们 定义了起始位置startIndex,那么 [startIndex, i] 就是要截取的子串。
首先判断这个子串是不是回文,如果是回文,就加入在vector<string> path中,path用来记录切割过的回文子串。
判断回文子串:
可以使用双指针法,一个指针从前向后,一个指针从后向前,如果前后指针所指向的元素是相等的,就是回文字符串了。
整体代码:
class Solution {
public:
vector<string> path;
vector<vector<string>> result;
void backtracking(string s, int startIndex){
//当startIndex超过s尾部时说明切割完成
if(startIndex == s.size()){
result.push_back(path); //在遍历中处理是否符合题目要求 这里直接装就行
return;
}
//从分割线startIndex开始往下遍历
for(int i = startIndex; i < s.size(); i++){
if(isPalindrome(s, startIndex, i)){ //如果是回文子串就装进path
//子串的范围是[startIndex, i]
//substr(起始位置, 子串长度);
string str = s.substr(startIndex, i - startIndex + 1);
path.push_back(str);
}
else continue; //如果不是回文的话,就将切割线往后移,而不进入回溯
//当前子串已经是回文串 则往后回溯寻找新的回文串
backtracking(s, i + 1); // 寻找i+1为起始位置的子串
path.pop_back(); //回溯:把装入的子串弹出,i往右移找其他切割方案
}
return;
}
//判断回文串
bool isPalindrome(string s, int start, int end){
//双指针法
for(int i = start, j = end; i < j; i++, j--){
if(s[i] != s[j]) return false;
}
return true;
}
vector<vector<string>> partition(string s) {
backtracking(s, 0);
return result;
}
};
难点分析:
- 如何模拟那些切割线
- 切割问题中递归如何终止
- 在递归循环中如何截取子串
- 如何判断回文
93. 复原 IP 地址
本题可以说是131.分割回文串的加强版
我们还需要一个变量pointNum,记录添加点号的数量。
- 递归终止条件
终止条件和131.分割回文串情况就不同了,本题明确要求只会分成4段,所以不能用切割线切到最后作为终止条件,而是分割的段数作为终止条件。
pointNum表示逗点数量,pointNum为3说明字符串分成了4段了。
然后验证一下第四段是否合法,如果合法就加入到结果集里。
- 单层搜索的逻辑
在131.分割回文串中已经讲过在循环遍历中如何截取子串。
在for (int i = startIndex; i < s.size(); i++)循环中 [startIndex, i] 这个区间就是截取的子串,需要判断这个子串是否合法。
如果合法就在字符串后面加上符号.表示已经分割。
如果不合法就结束本层循环,如图中剪掉的分支:
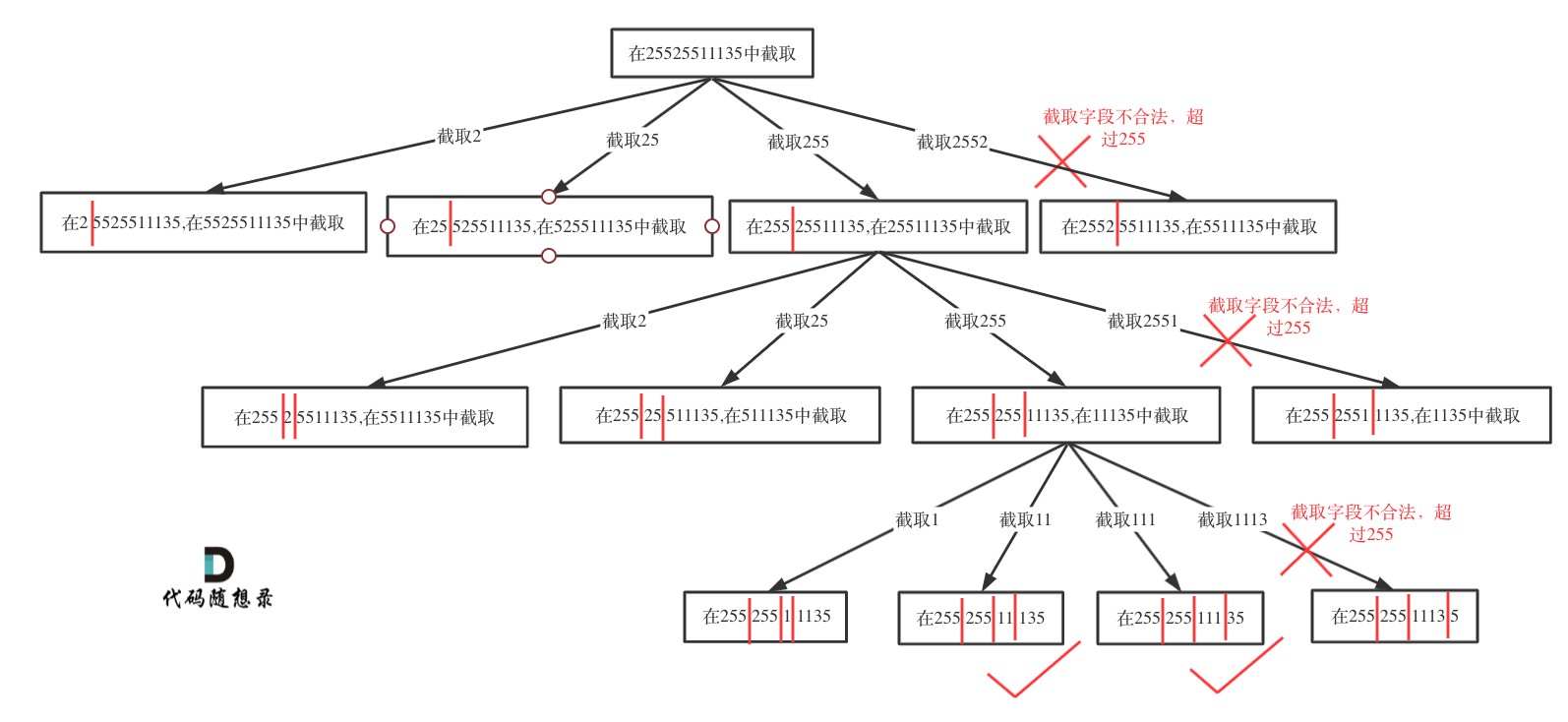
判断子串是否合法:
最后就是在写一个判断段位是否是有效段位了。
主要考虑到如下三点:
- 段位以0为开头的数字不合法
- 段位里有非正整数字符不合法
- 段位如果大于255了不合法
代码如下:
class Solution {
public:
string numStr;
vector<string> result;
int pointNum; //用来记录result中存了几个点
// startIndex: 搜索的起始位置
void backtracking(string s, int startIndex){
if(pointNum == 3){
// 判断第四段子字符串是否合法,如果合法就放进result中
if (isValid(s, startIndex, s.size() - 1)) {
result.push_back(s);
}
return;
}
for(int i = startIndex; i < s.size(); i++){
if(isValid(s, startIndex, i)){// 判断 [startIndex,i] 这个区间的子串是否合法
s.insert(s.begin() + i + 1, '.'); //合法的话就在i(分割线)后面插入.
pointNum++;
backtracking(s, i + 2); //插入了.所以下一个子串的起始位置是i + 2
pointNum--;
s.erase(s.begin() + i + 1); //删掉.
}
else break; //如果当前都不是合法数字的话,往后数字只会更大,更不可能合法,所以直接排除这个切割方案
}
}
// 判断字符串s在左闭又闭区间[start, end]所组成的数字是否合法
bool isValid(const string& s, int start, int end) {
if (start > end) {
return false;
}
if (s[start] == '0' && start != end) { // 0开头的数字不合法
return false;
}
int num = 0;
for (int i = start; i <= end; i++) {
if (s[i] > '9' || s[i] < '0') { // 遇到非数字字符不合法
return false;
}
num = num * 10 + (s[i] - '0'); //循环加数字
if (num > 255) { // 如果大于255了不合法
return false;
}
}
return true;
}
vector<string> restoreIpAddresses(string s) {
backtracking(s, 0);
return result;
}
};
- 时间复杂度: O(3^4),IP地址最多包含4个数字,每个数字最多有3种可能的分割方式,则搜索树的最大深度为4,每个节点最多有3个子节点。
- 空间复杂度: O(n)
在131.分割回文串中我列举的分割字符串的难点,本题都覆盖了。
而且本题还需要操作字符串添加逗号作为分隔符,并验证区间的合法性。
78. 子集
组合问题、分割问题是收集树形结构中叶子节点的结果。
子集是收集树形结构中树的所有节点的结果。
回溯的过程,集合不存在重复元素,那么肯定不会取重复的path
class Solution {
public:
vector<int> path;
vector<vector<int>> result;
void backtracking(vector<int>& nums, int startIndex){
result.push_back(path); //直接收集子集
//无需终止条件(return) 因为遍历到每个节点都需要收集子集 且结果不会重复
//因为每次递归的下一层就是从i+1开始的 所以不会无限递归
for(int i = startIndex; i < nums.size(); i++){
path.push_back(nums[i]);
backtracking(nums, i + 1);
path.pop_back();
}
return;
}
vector<vector<int>> subsets(vector<int>& nums) {
backtracking(nums, 0);
return result;
}
};
组合小结
什么时候需要startIndex?(组合问题)
如果是一个集合来求组合的话,就需要startIndex。
如果是多个集合取组合,各个集合之间相互不影响,那么就不用startIndex,例如:回溯算法:电话号码的字母组合
常用剪枝:
for (int i = startIndex; i < candidates.size() && sum + candidates[i] <= target; i++)
意思是如果当前积累的总和and下一个数之和大于target的话,再往后也是大于target(有序数组),所以可以剪枝。
两个维度的“使用过”:
“使用过”在这个树形结构上是有两个维度的,一个维度是同一树枝上“使用过”,一个维度是同一树层上“使用过”。
90. 子集 II
与上一题的区别是这里有重复元素
别忘记当集合里有重复元素时,同一树层的去重需要先对集合进行有序排序。
class Solution {
public:
//关键在于对同一树层的相同元素去重
vector<int> path;
vector<vector<int>> result;
void backtracking(vector<int>& nums, int startIndex){
//每个节点都需要收集结果
result.push_back(path);
for(int i = startIndex; i < nums.size(); i++){
if(i != startIndex && nums[i] == nums[i - 1]){ //同一树层重复元素
continue;
}
path.push_back(nums[i]);
backtracking(nums, i + 1);
path.pop_back();
}
return;
}
vector<vector<int>> subsetsWithDup(vector<int>& nums) {
sort(nums.begin(), nums.end()); //别忘了
backtracking(nums, 0);
return result;
}
};
- 时间复杂度: O(n * 2^n)
- 空间复杂度: O(n)
使用set去重的版本。
class Solution {
private:
vector<vector<int>> result;
vector<int> path;
void backtracking(vector<int>& nums, int startIndex) {
result.push_back(path);
unordered_set<int> uset;
for (int i = startIndex; i < nums.size(); i++) {
if (uset.find(nums[i]) != uset.end()) {
continue;
}
uset.insert(nums[i]);
path.push_back(nums[i]);
backtracking(nums, i + 1);
path.pop_back();
}
}
public:
vector<vector<int>> subsetsWithDup(vector<int>& nums) {
result.clear();
path.clear();
sort(nums.begin(), nums.end()); // 去重需要排序
backtracking(nums, 0);
return result;
}
};
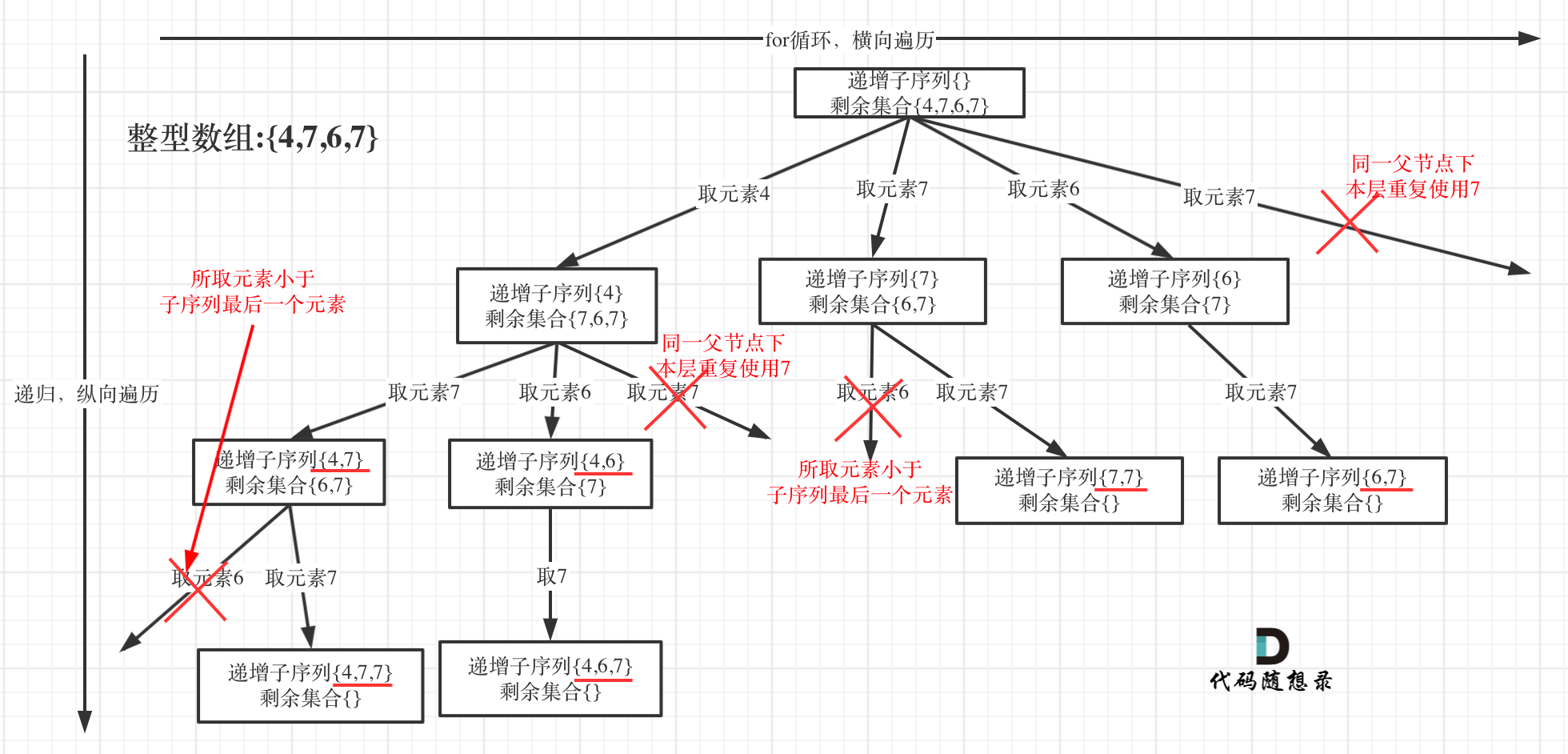
491. 递增子序列
要求的是递增子序列,所以不能给数组排序
这题不仅要在树层上做去重操作,还得保证树枝上的当前数要大于等于上一个数。
这里用哈希表对树层进行去重,也可用数组(且更高效),但是哈希表比较容易理解。
class Solution {
public:
//子序列要求:递增、至少两个元素
//不能给数组排个序
//同一树层上:不能有重复元素 同一树枝上:当前元素要大于等于上一个元素
vector<int> path;
vector<vector<int>> result;
void backtracking(vector<int>& nums, int startIndex){
if(path.size() >= 2){
result.push_back(path);
// 注意这里不要加return,要取树上的节点
}
unordered_set<int> uset; //uset在树层中声明 每一层都是同一个uset
for(int i = startIndex; i < nums.size(); i++){
//小于上一个元素或者同一树层出现过 都跳过当前数
if(!path.empty() && nums[i] < path.back() ||
uset.find(nums[i]) != uset.end()){
continue;
}
uset.insert(nums[i]);
path.push_back(nums[i]);
backtracking(nums, i + 1);
path.pop_back();
//uset不需要pop,因为每一层都是新的uset
}
return;
}
vector<vector<int>> findSubsequences(vector<int>& nums) {
backtracking(nums, 0);
return result;
}
};
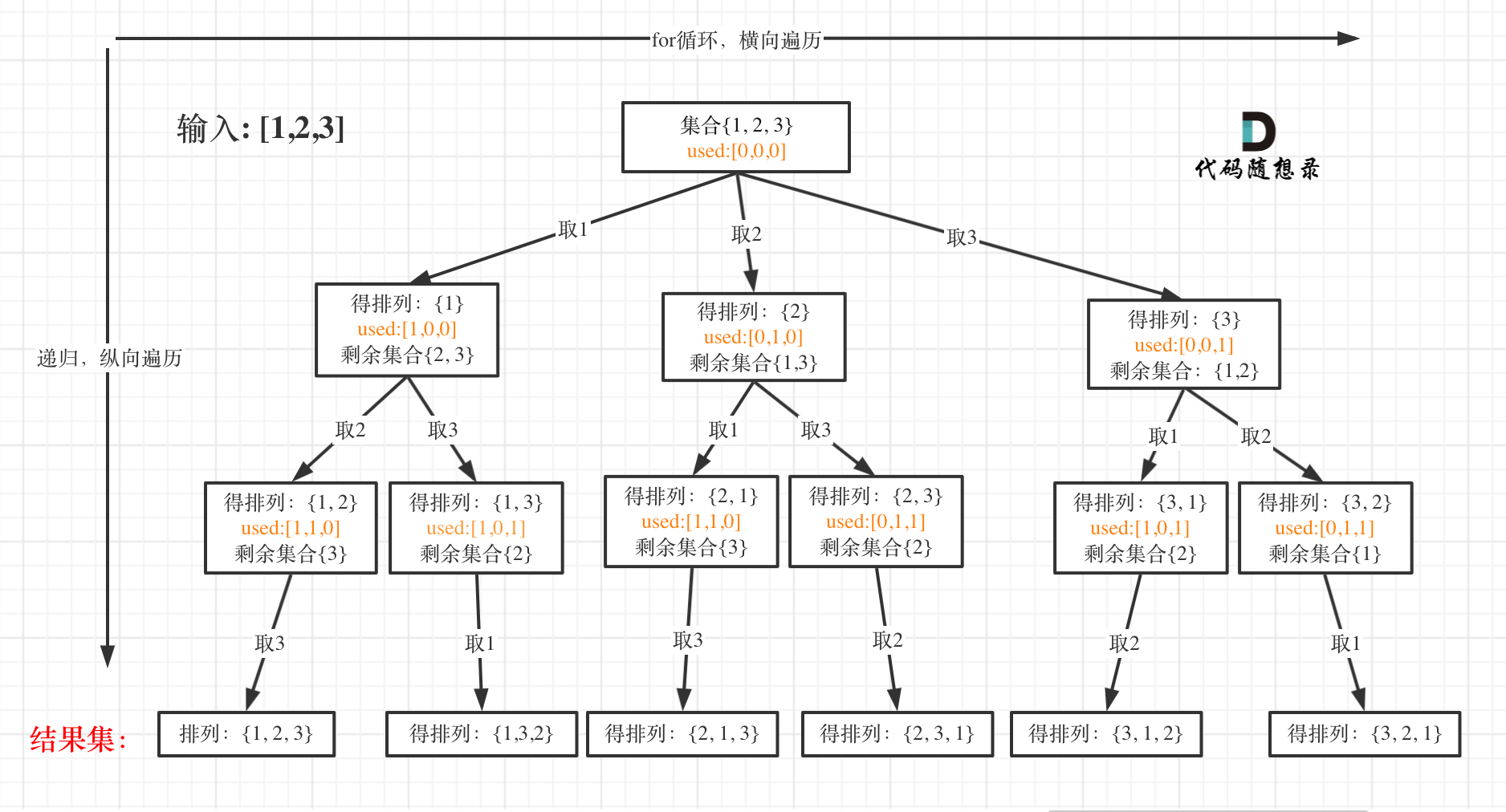
46. 全排列
排列是有序的,也就是说 [1,2] 和 [2,1] 是两个集合
可以看出元素1在[1,2]中已经使用过了,但是在[2,1]中还要在使用一次1,所以处理排列问题就不用使用startIndex了。
需要一个used数组,其实就是记录此时path里都有哪些元素使用了,一个排列里一个元素只能使用一次,如图橘黄色部分所示:
class Solution {
public:
vector<vector<int>> result;
vector<int> path;
void backtracking (vector<int>& nums, vector<bool>& used) {
// 此时说明找到了一组
if (path.size() == nums.size()) {
result.push_back(path);
return;
}
//每次都是从0开始 而不是startIndex
for (int i = 0; i < nums.size(); i++) {
if (used[i] == true) continue; // path里已经收录的元素,直接跳过
used[i] = true;
path.push_back(nums[i]);
backtracking(nums, used);
path.pop_back();
used[i] = false;
}
}
vector<vector<int>> permute(vector<int>& nums) {
result.clear();
path.clear();
vector<bool> used(nums.size(), false);
backtracking(nums, used);
return result;
}
};
- 时间复杂度: O(n!)
- 空间复杂度: O(n)
总结:
排列问题的不同:
- 每层都是从0开始搜索而不是startIndex
- 需要used数组记录path里都放了哪些元素了
47. 全排列 II
只需要在46题的基础上加上树层去重即可。
怎么进行树层去重呢?两种方法:
方法一:
每层都声明一个哈希表set记录使用过的元素,参考491.递增子序列
class Solution {
public:
//在46题的基础上加上一个树层去重
vector<int> path;
vector<vector<int>> result;
void backtracking(vector<int>& nums, vector<bool>& used){
if(path.size() == nums.size()){
result.push_back(path);
return;
}
unordered_set<int> uset; //uset在树层中声明 每一层都是同一个uset
for(int i = 0; i < nums.size(); i++){
if(used[i] || uset.find(nums[i]) != uset.end())
continue;
used[i] = true;
uset.insert(nums[i]);
path.push_back(nums[i]);
backtracking(nums, used);
used[i] = false;
path.pop_back();
}
return;
}
vector<vector<int>> permuteUnique(vector<int>& nums) {
vector<bool> used(nums.size(), false);
backtracking(nums, used);
return result;
}
};
方法二:
先对数组进行排序,使得相同元素挨在一起。
使用used数组标记已经使用过的元素。
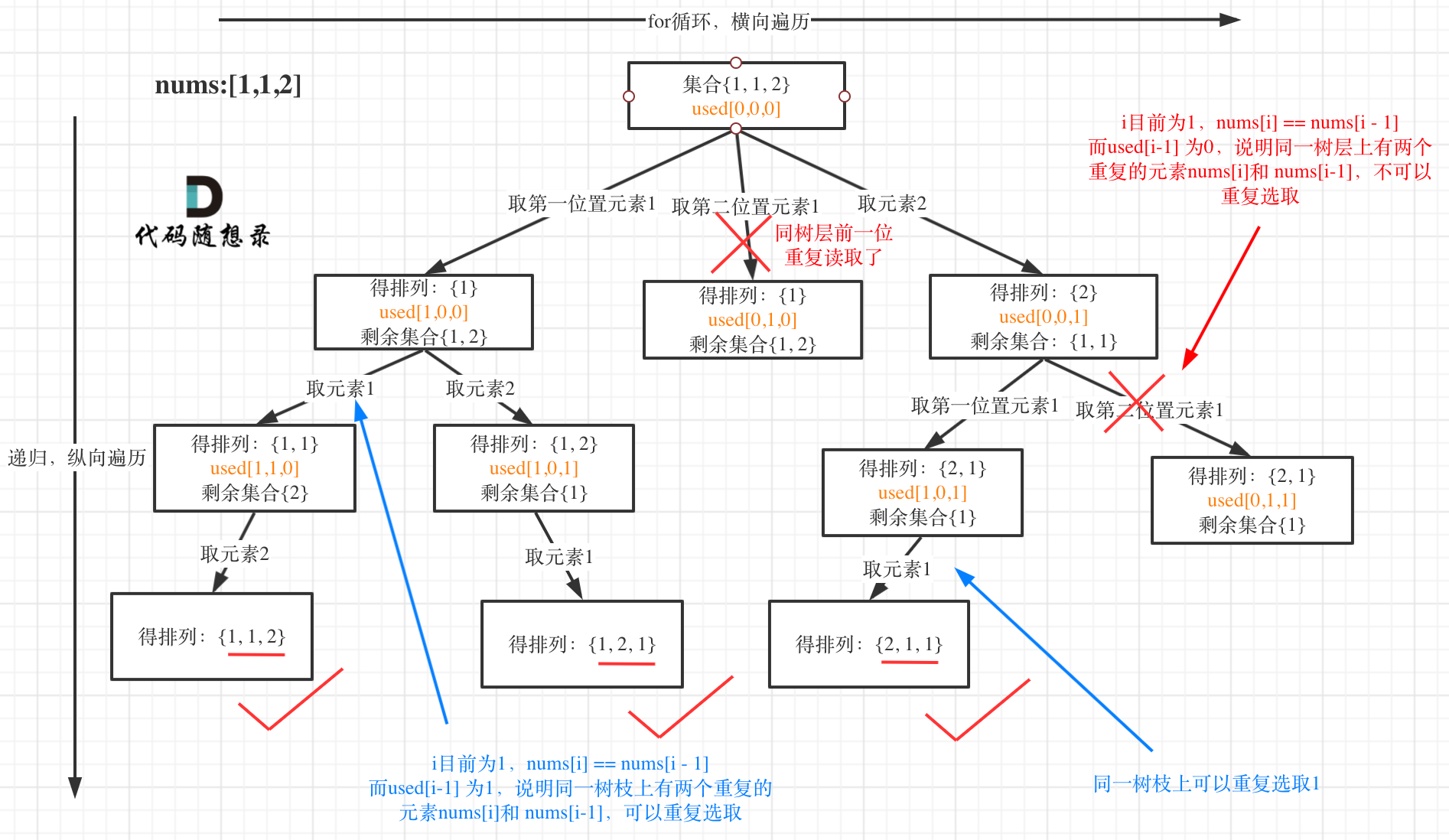
根据图像可知,我们需要进行树层去重的话,就需要判断num[i] == num[i - 1]。但是!在树枝上,当前节点的下一个节点也有可能出现num[i] == num[i - 1];所以还需要加上判定used[i - 1] == false,这样就说明了一定是在树层上。
为什么呢?因为树枝上,两个相同的节点,遍历到后一个时,前一个节点一定是
used[i - 1] == true,而树层上因为是回溯完才到后一个相同元素,所以used[i - 1] == false。卡尔牛逼。
class Solution {
private:
vector<vector<int>> result;
vector<int> path;
void backtracking (vector<int>& nums, vector<bool>& used) {
// 此时说明找到了一组
if (path.size() == nums.size()) {
result.push_back(path);
return;
}
for (int i = 0; i < nums.size(); i++) {
// used[i - 1] == true,说明同一树枝nums[i - 1]使用过
// used[i - 1] == false,说明同一树层nums[i - 1]使用过
// 如果同一树层nums[i - 1]使用过则直接跳过
if (i > 0 && nums[i] == nums[i - 1] && used[i - 1] == false) {
continue;
}
if (used[i] == false) {
used[i] = true;
path.push_back(nums[i]);
backtracking(nums, used);
path.pop_back();
used[i] = false;
}
}
}
public:
vector<vector<int>> permuteUnique(vector<int>& nums) {
result.clear();
path.clear();
sort(nums.begin(), nums.end()); // 排序
vector<bool> used(nums.size(), false);
backtracking(nums, used);
return result;
}
};
// 时间复杂度: 最差情况所有元素都是唯一的。复杂度和全排列1都是 O(n! * n) 对于 n 个元素一共有 n! 中排列方案。而对于每一个答案,我们需要 O(n) 去复制最终放到 result 数组
// 空间复杂度: O(n) 回溯树的深度取决于我们有多少个元素
扩展:
对于排列问题,树层上去重和树枝上去重,都是可以的,但是树层上去重效率更高!
如果要对树层中前一位去重,就用used[i - 1] == false,如果要对树枝前一位去重用used[i - 1] == true。
所以说上面的代码,used[i - 1] == false or true都是可以的。
举个例子:
树层上去重(used[i - 1] == false),的树形结构如下:
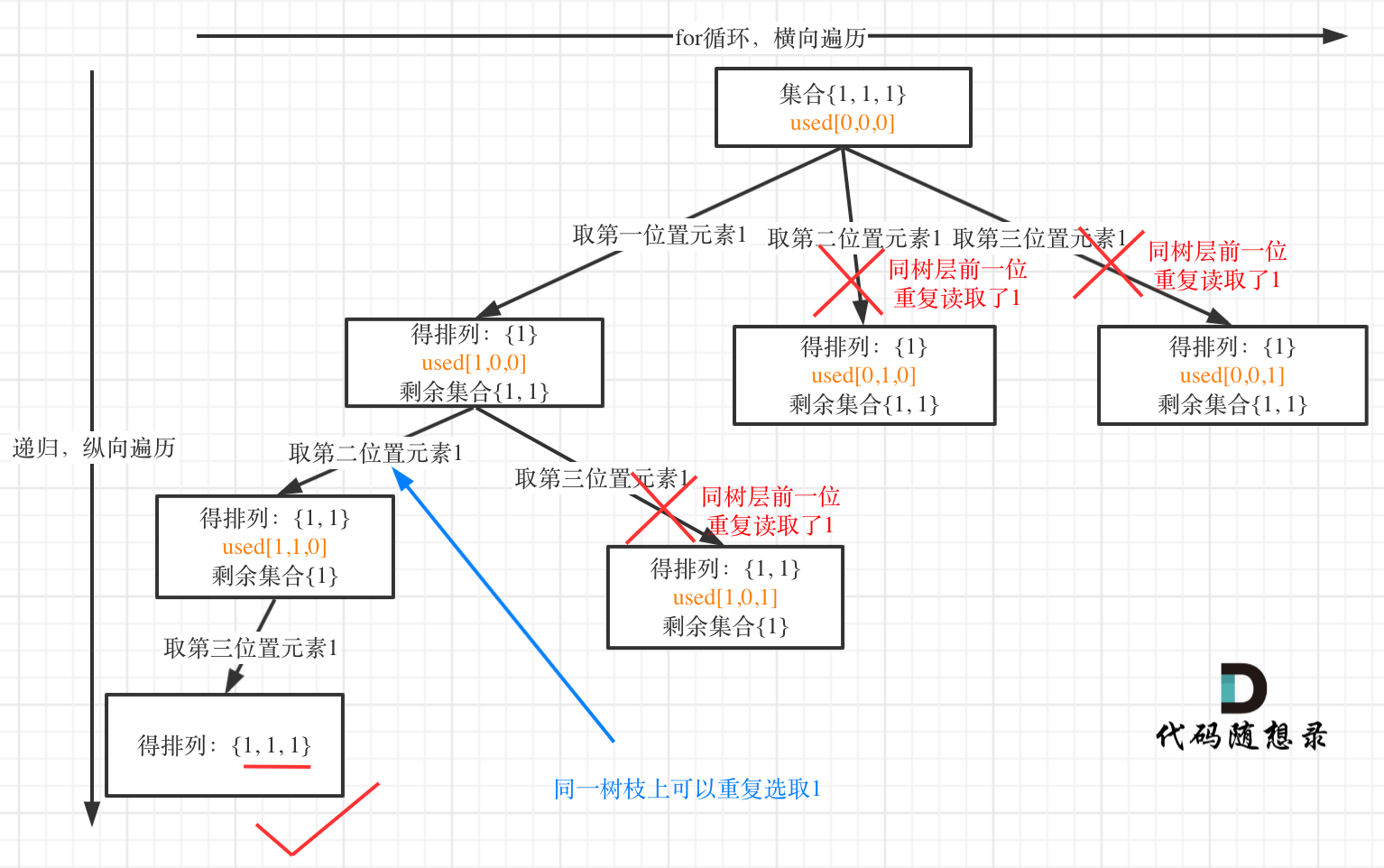
树枝上去重(used[i - 1] == true)的树型结构如下:
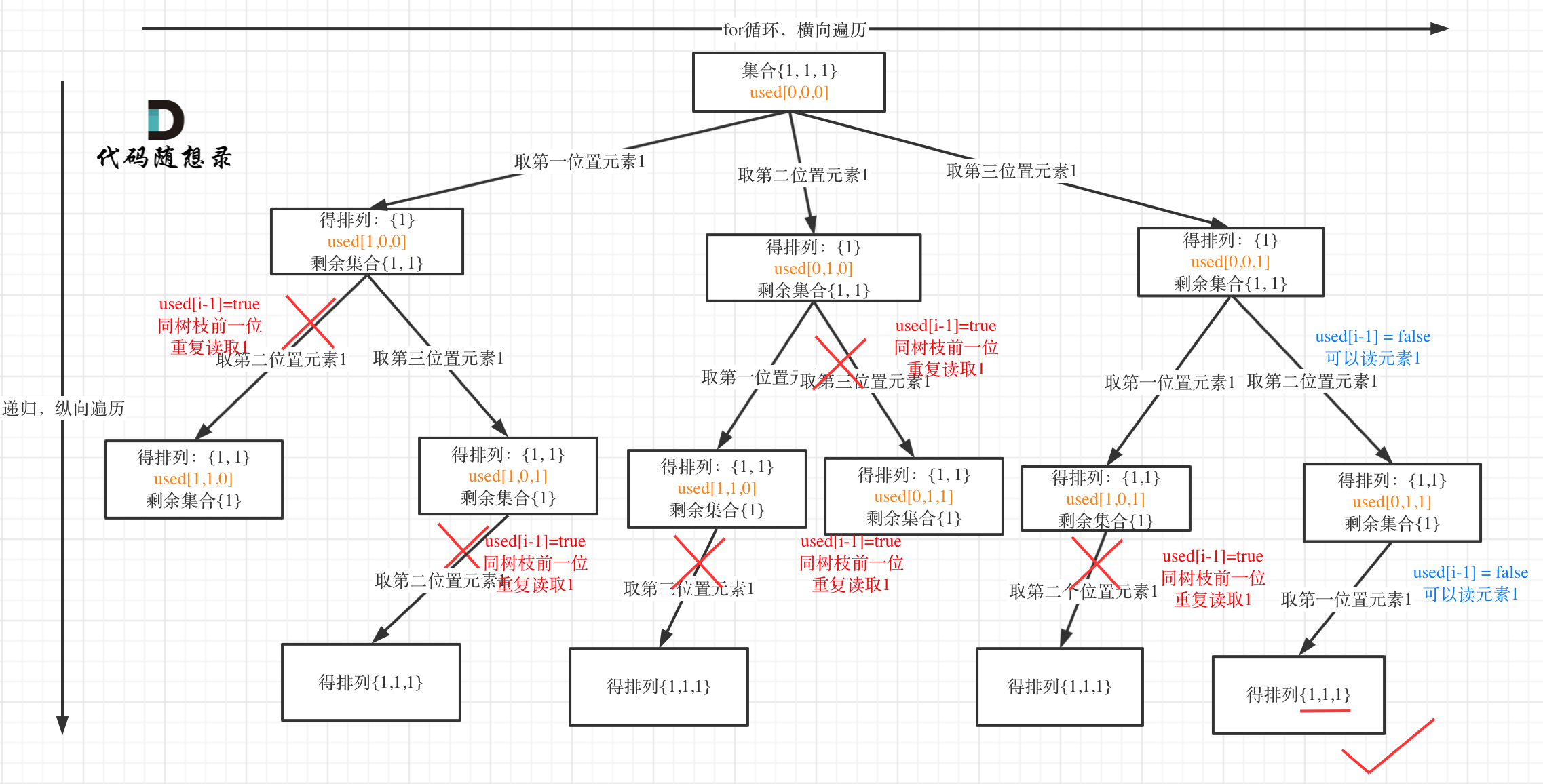
大家应该很清晰的看到,树层上对前一位去重非常彻底,效率很高,树枝上对前一位去重虽然最后可以得到答案,但是做了很多无用搜索。
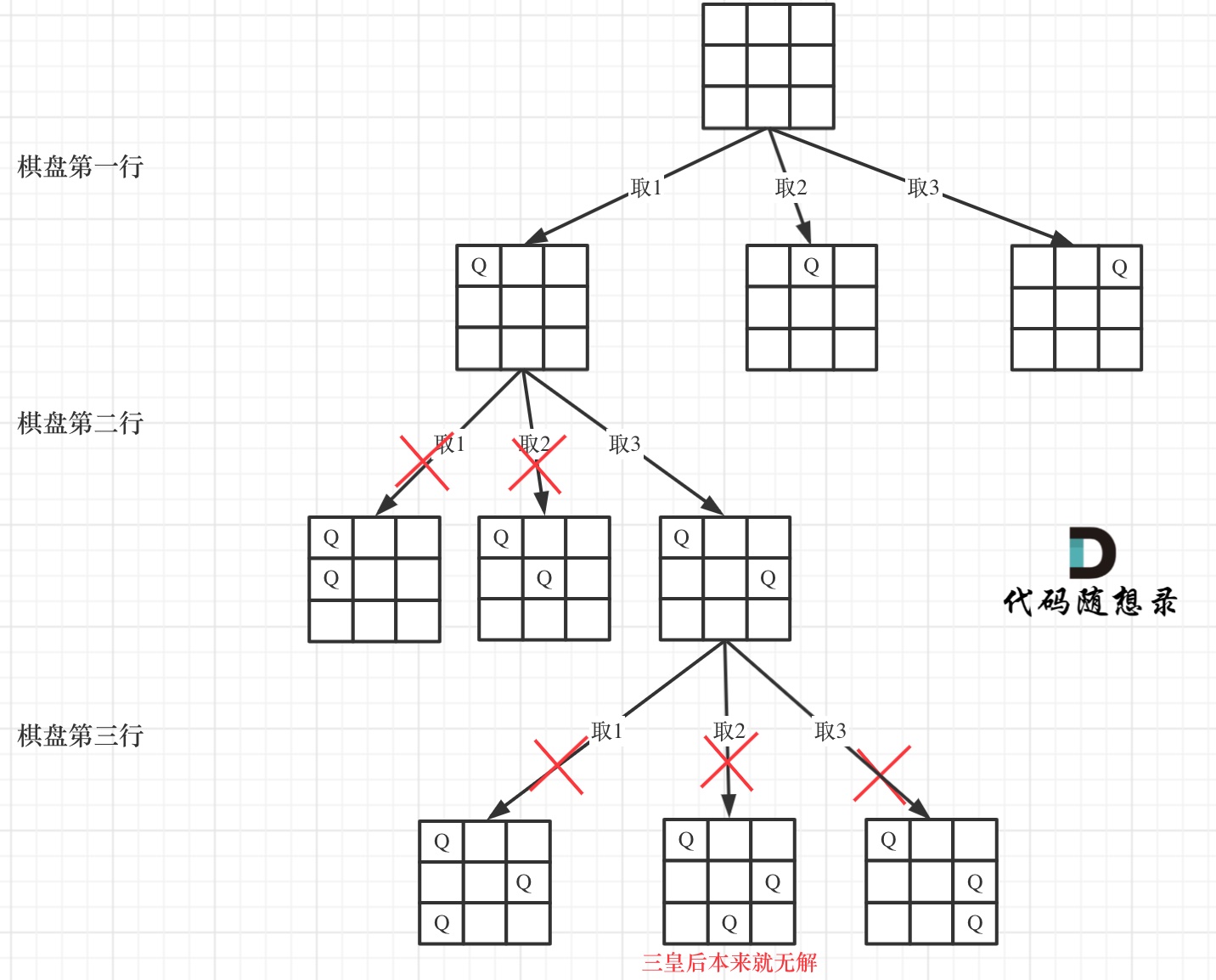
51. N 皇后
皇后们的约束条件:
- 不能同行
- 不能同列
- 不能同斜线
可以把棋盘抽象成一棵树,行就是树高(递归的深度),列就是树宽(for循环的长度)
只要搜索到了树的叶子节点,说明就找到了皇后们的合理位置了。
class Solution {
public:
vector<vector<string>> result;
//n表示n*n 且n个皇后、row表示第几行、chessboard每一种棋子摆放方案
void backtracking(int n, int row, vector<string>& chessboard){
if(row == n){
result.push_back(chessboard);
return;
}
//col代表列
for(int col = 0; col < n; col++){ //每一行都是从0开始
if(isValid(row, col, chessboard, n)){ //验证合法性
chessboard[row][col] = 'Q';
backtracking(n, row + 1, chessboard);
chessboard[row][col] = '.';
}
}
return;
}
bool isValid(int row, int col, vector<string>& chessboard, int n){
//检查列
for(int i = 0; i < row; i++){ //只搜当前行以上的
if(chessboard[i][col] == 'Q'){
return false;
}
}
//检查左斜线 从当前行的上一行不断向上搜索
for(int i = row - 1, j = col - 1; i >= 0 && j >= 0; i--, j--){
if(chessboard[i][j] == 'Q') return false;
}
//检查右斜线 注意i、j的取值判断
for(int i = row - 1, j = col + 1; i >= 0 && j < n; i--, j++){
if(chessboard[i][j] == 'Q') return false;
}
return true;
//为什么没有在同行进行检查呢?
//因为在单层搜索的过程中,每一层递归,只会选for循环(也就是同一行)里的一个元素,所以不用去重了。
}
vector<vector<string>> solveNQueens(int n) {
vector<string> chessboard(n, string(n, '.'));
backtracking(n, 0, chessboard);
return result;
}
};
37. 解数独
这道题水有点深,看不懂的话多看看视频。
本题中棋盘的每一个位置都要放一个数字(而N皇后是一行只放一个皇后),并检查数字是否合法,解数独的树形结构要比N皇后更宽更深。
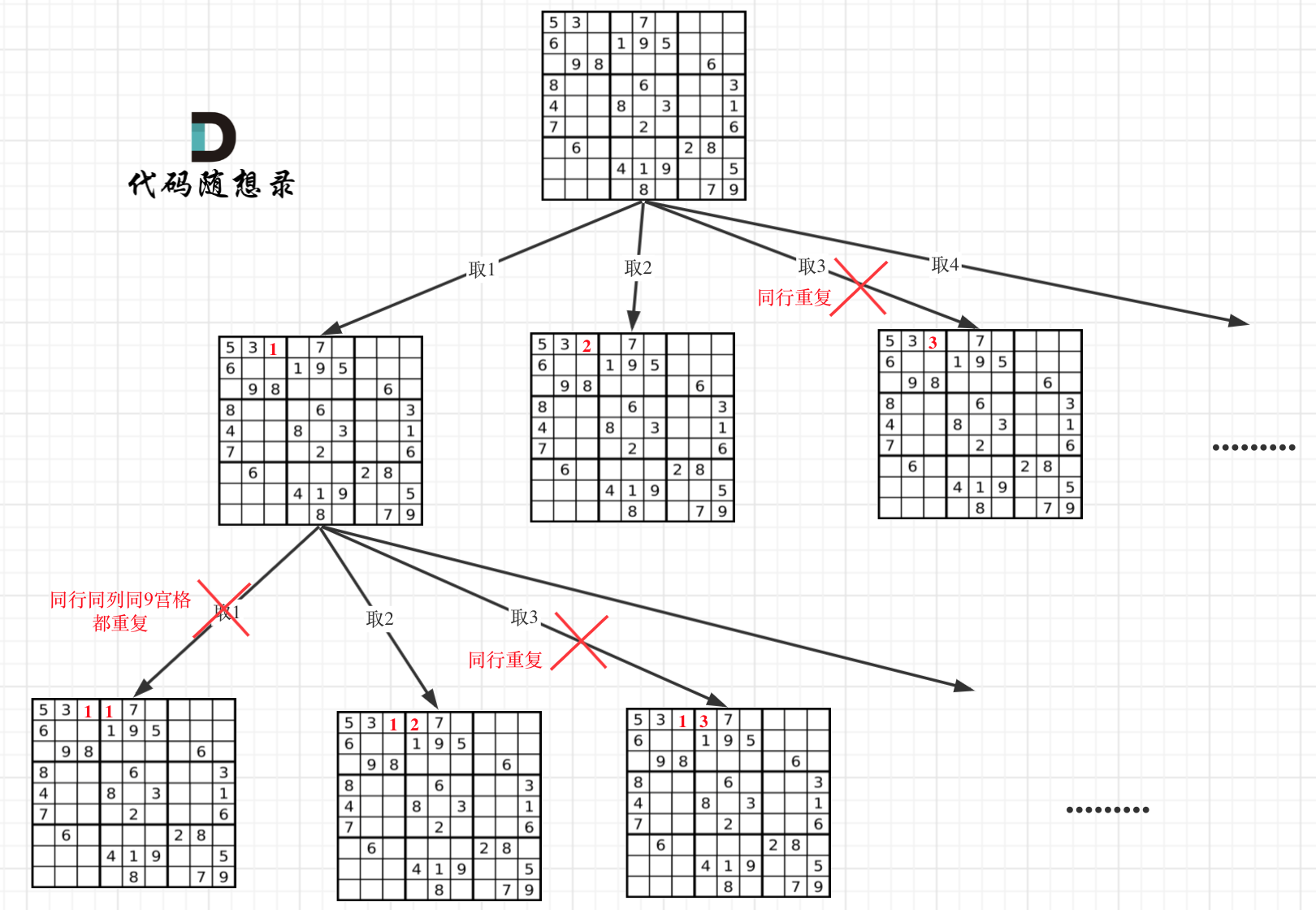
在树形图中可以看出我们需要的是一个二维的递归(也就是两个for循环嵌套着递归)
一个for循环遍历棋盘的行,一个for循环遍历棋盘的列,一行一列确定下来之后,递归遍历这个位置放9个数字的可能性
class Solution {
public:
//每行一次 每列一次 九宫格内一次
//只找.号 1-9进行递归
bool backtracking(vector<vector<char>>& board){
//i、j遍历行列每个位置
for(int i = 0; i < board.size(); i++){
for(int j = 0; j < board[0].size(); j++){
if(board[i][j] != '.') continue;
//遇到.就试着放1-9进去,再递归遍历棋盘看看行不行
for(char k = '1'; k <= '9'; k++){ // (i, j) 这个位置放k是否合适
if(isValid(i, j, k, board)){
board[i][j] = k;
//如果发现这个结果可行就一直向上传递true,不用再往下看其他分支
if(backtracking(board)) return true;
board[i][j] = '.';
}
}
return false; //如果1-9试了都不行,说明这个棋盘没有解
}
}
return true; // 遍历完没有返回false,说明找到了合适棋盘位置了
}
bool isValid(int row, int col, char val, vector<vector<char>>& board) {
for (int i = 0; i < 9; i++) { // 判断行里是否重复
if (board[row][i] == val) {
return false;
}
}
for (int j = 0; j < 9; j++) { // 判断列里是否重复
if (board[j][col] == val) {
return false;
}
}
int startRow = (row / 3) * 3;
int startCol = (col / 3) * 3;
for (int i = startRow; i < startRow + 3; i++) { // 判断9方格里是否重复
for (int j = startCol; j < startCol + 3; j++) {
if (board[i][j] == val ) {
return false;
}
}
}
return true;
}
void solveSudoku(vector<vector<char>>& board) {
backtracking(board);
}
};
递归函数的返回值需要是bool类型,为什么呢?
因为解数独找到一个符合的条件(就在树的叶子节点上)立刻就返回,相当于找从根节点到叶子节点一条唯一路径,所以需要使用bool返回值。
本题递归不用终止条件,解数独是要遍历整个树形结构寻找可能的叶子节点就立刻返回。
不用终止条件会不会死循环?
递归的下一层的棋盘一定比上一层的棋盘多一个数,等数填满了棋盘自然就终止(填满当然好了,说明找到结果了),所以不需要终止条件
总结
历时21天,14道经典题目分析,20张树形图,21篇回溯法精讲文章,从组合到切割,从子集到排列,从棋盘问题到最后的复杂度分析,至此收尾了。
这里的每一种问题,讲解的时候我都会和其他问题作对比,做分析,确保每一个问题都讲的通透。
可以说方方面面都详细介绍到了。
例如:
- 如何理解回溯法的搜索过程?
- 什么时候用startIndex,什么时候不用?
- 如何去重?如何理解“树枝去重”与“树层去重”?
- 去重的几种方法?
- 如何理解二维递归?
这里的每一个问题,网上几乎找不到能讲清楚的文章,这也是直击回溯算法本质的问题。
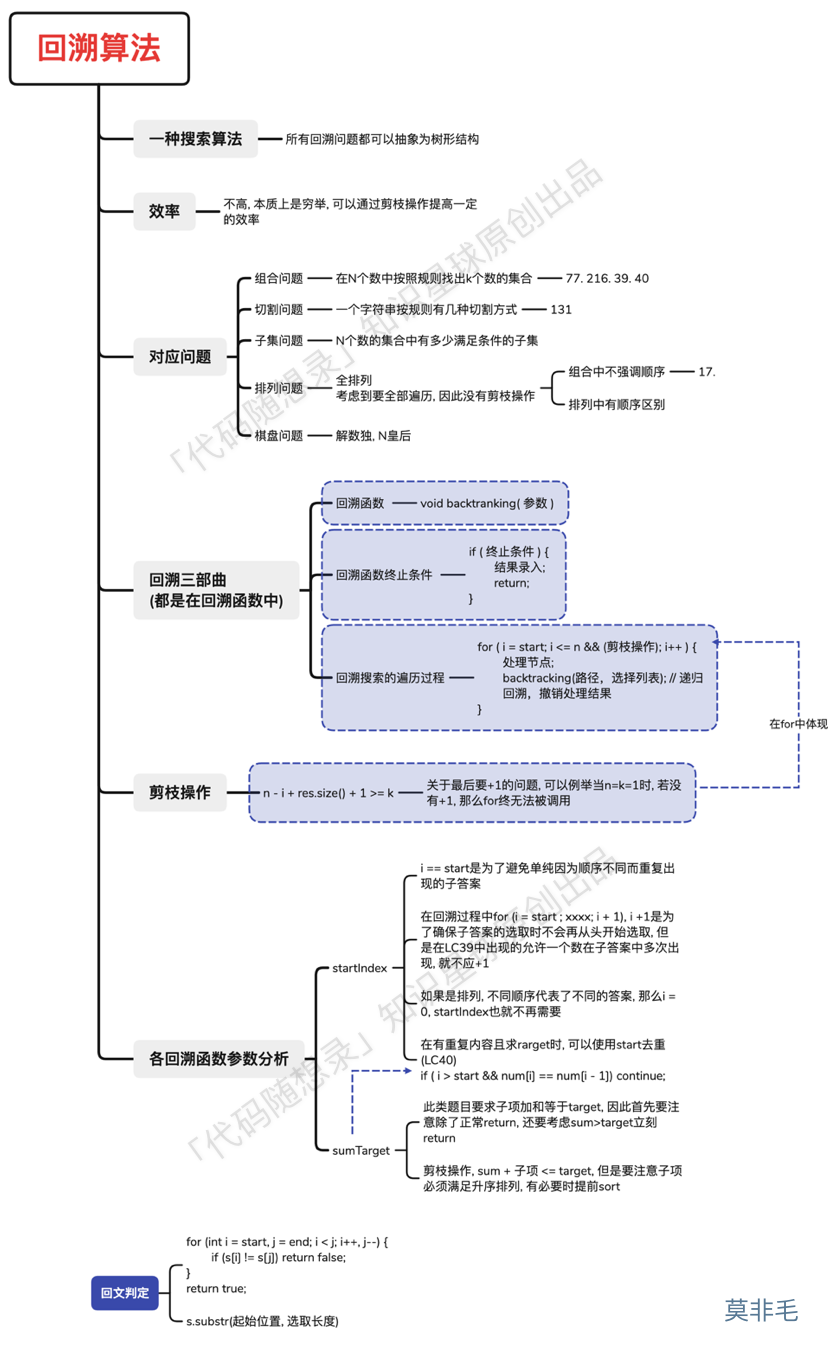
回溯专题汇聚为一张图:


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









