







来自代码随想录的刷题路线:代码随想录
哈希表:
- 哈希表是根据关键码的值而直接进行访问的数据结构。
- 当我们遇到了要快速判断一个元素是否出现集合里的时候,就要考虑哈希法。
- 但是哈希法也是牺牲了空间换取了时间,因为我们要使用额外的数组,set或者是map来存放数据,才能实现快速的查找。
哈希表的三种数据结构使用情况(大体上):
- 数组:数值和范围都比较小
- set:数值较大
- map:每个下标对应一个值
242.有效的字母异位词
给定两个字符串 s 和 t ,编写一个函数来判断 t 是否是 s 的字母异位词。
**注意:**若 s 和 t 中每个字符出现的次数都相同,则称 s 和 t 互为字母异位词。
示例 1: 输入: s = “anagram”, t = “nagaram” 输出: true
示例 2: 输入: s = “rat”, t = “car” 输出: false
说明: 你可以假设字符串只包含小写字母。
思路:
- 定义一个大小为26的数组,用来存放字符串s每个字母出现的次数
- 遍历字符串t,对与s相同的字母位置元素减1操作
- 最后遍历字符串s,如果全部位置的数值都为0,则s和t是字母异位词
class Solution {
public:
bool isAnagram(string s, string t) {
int record[26] = {0};
for (int i = 0; i < s.size(); i++) {
// 并不需要记住字符a的ASCII,只要求出一个相对数值就可以了
record[s[i] - 'a']++;
}
for (int i = 0; i < t.size(); i++) {
record[t[i] - 'a']--;
}
for (int i = 0; i < 26; i++) {
if (record[i] != 0) {
// record数组如果有的元素不为零0,说明字符串s和t 一定是谁多了字符或者谁少了字符。
return false;
}
}
// record数组所有元素都为零0,说明字符串s和t是字母异位词
return true;
}
};
349.两个数组的交集
题意:给定两个数组,编写一个函数来计算它们的交集(元素不重复)。

说明: 输出结果中的每个元素一定是唯一的。 我们可以不考虑输出结果的顺序。

思路:
- 如果新建个数组来存放交集元素的话,难免会存在重复,还需另外处理重复元素,比较麻烦。
- 哈希表最擅长于解决 给你一个元素,判断它是否在集合里是否出现过。
- unordered_set内部有去重操作,即使往unordered_set中存入100个2,也只有1个2
解决方案1:
- 定义两个个unordered_set分别存放nums1和result
- 遍历nums2,如果元素在nums1中出现则插入result
- 返回result的vector
class Solution {
public:
vector<int> intersection(vector<int>& nums1, vector<int>& nums2) {
unordered_set<int> result_set; // 存放结果,之所以用set是为了给结果集去重
unordered_set<int> nums_set(nums1.begin(), nums1.end());
for (int num : nums2) {
// 发现nums2的元素 在nums_set里又出现过
if (nums_set.find(num) != nums_set.end()) {
result_set.insert(num);
}
}
return vector<int>(result_set.begin(), result_set.end());
}
};
- 时间复杂度: O(mn)
- 空间复杂度: O(n)
解决方案2(数组)
class Solution {
public:
vector<int> intersection(vector<int>& nums1, vector<int>& nums2) {
unordered_set<int> result_set; // 存放结果,之所以用set是为了给结果集去重
int hash[1005] = {0}; // 默认数值为0
for (int num : nums1) { // nums1中出现的字母在hash数组中做记录
hash[num] = 1;
}
for (int num : nums2) { // nums2中出现话,result记录
if (hash[num] == 1) {
result_set.insert(num);
}
}
return vector<int>(result_set.begin(), result_set.end());
}
};
- 时间复杂度: O(m + n)
- 空间复杂度: O(n)
350.两个数组的交集||
与上一题差不多,区别就是这题的交集元素不用去重。
class Solution {
public:
vector<int> intersect(vector<int>& nums1, vector<int>& nums2) {
//用哈希表map来存储 key为交集元素 value为出现次数
unordered_map<int, int>map1;
unordered_map<int, int>map2;
vector<int> result;
// 遍历 nums1 存入 map1
for (int num : nums1) {
map1[num]++;
}
// 遍历 nums2 存入 map2
for (int num : nums2) {
map2[num]++;
}
//遍历map1
for (const auto& pair : map1) {
if (map2.find(pair.first) != map2.end()) { // 有相同元素
int intersectionCount = std::min(pair.second, map2[pair.first]);
for (int i = 0; i < intersectionCount; i++) {
result.push_back(pair.first);
}
}
}
return result;
}
};
官方题解:

class Solution {
public:
vector<int> intersect(vector<int>& nums1, vector<int>& nums2) {
if (nums1.size() > nums2.size()) {
return intersect(nums2, nums1);
}
unordered_map <int, int> m;
for (int num : nums1) {
++m[num];
}
vector<int> intersection;
for (int num : nums2) {
if (m.count(num)) {
intersection.push_back(num);
--m[num];
if (m[num] == 0) {
m.erase(num);
}
}
}
return intersection;
}
};


class Solution {
public:
vector<int> intersect(vector<int>& nums1, vector<int>& nums2) {
sort(nums1.begin(), nums1.end());
sort(nums2.begin(), nums2.end());
int length1 = nums1.size(), length2 = nums2.size();
vector<int> intersection;
int index1 = 0, index2 = 0;
while (index1 < length1 && index2 < length2) {
if (nums1[index1] < nums2[index2]) {
index1++;
} else if (nums1[index1] > nums2[index2]) {
index2++;
} else {
intersection.push_back(nums1[index1]);
index1++;
index2++;
}
}
return intersection;
}
};

202. 快乐数
编写一个算法来判断一个数 n 是不是快乐数。
「快乐数」定义为:对于一个正整数,每一次将该数替换为它每个位置上的数字的平方和,然后重复这个过程直到这个数变为 1,也可能是 无限循环 但始终变不到 1。如果 可以变为 1,那么这个数就是快乐数。
如果 n 是快乐数就返回 True ;不是,则返回 False 。
示例:
输入:19
输出:true
解释:
1^2 + 9^2 = 82
8^2 + 2^2 = 68
6^2 + 8^2 = 100
1^2 + 0^2 + 0^2 = 1
#思路
- 判断一个数是否为快乐数,要么数的每一位平方和循环最终为1,要么就在循环中会变回其中一个结果。
- 当我们遇到了要快速判断一个元素是否出现集合里的时候,就要考虑哈希法了。
- 所以这道题目使用哈希法,来判断这个sum是否重复出现,如果重复了就是return false, 否则一直找到sum为1为止。
- 判断sum是否重复出现就可以使用unordered_set。
(set.find != set.end()) - 还有一个难点就是求和的过程,如果对取数值各个位上的单数操作不熟悉的话,做这道题也会比较艰难。因为n的位数并不固定,所以只能循环剃掉个位
class Solution {
public:
int getSum(int n){
int sum = 0;
//求每位数的平方之和
while(n){
sum += (n % 10) * (n % 10);
n /= 10;
}
return sum;
}
bool isHappy(int n) {
unordered_set<int> hash;
//检测sum是否出现过 出现过就意味着无限循环
while(1){
int sum = getSum(n);
if(hash.find(sum) != hash.end()){ //不等于则在其中出现过 会无限循环
return false;
}
if(sum == 1){
return true;
}
hash.insert(sum);
n = sum;
}
}
};
- 时间复杂度: O(logn)
- 空间复杂度: O(logn)
1. 两数之和
给定一个整数数组 nums 和一个目标值 target,请你在该数组中找出和为目标值的那 两个 整数,并返回他们的数组下标。
你可以假设每种输入只会对应一个答案。但是,数组中同一个元素不能使用两遍。
示例:
给定 nums = [2, 7, 11, 15], target = 9
因为 nums[0] + nums[1] = 2 + 7 = 9
所以返回 [0, 1]
思路:
遍历数组,如果当前元素在map中有与其对应数(即相加等于target),那么直接返回这两个数的下标,否则将当前元素插入map。
- 为什么会想到用哈希表:因为要快速查找是否有与其对应的元素
- 哈希表为什么用map:因为要通过元素的值判断返回元素的下标,数组和set都不能做到存储key和value,而map可以。
- 本题map是用来存什么的:存已遍历过的元素。
- map中的key和value用来存什么的:key存元素的值,value存元素对应的下标。
class Solution {
public:
vector<int> twoSum(vector<int>& nums, int target) {
std::unordered_map <int,int> map;
for(int i = 0; i < nums.size(); i++) {
// 遍历当前元素,并在map中寻找是否有匹配的key
auto iter = map.find(target - nums[i]);
if(iter != map.end()) {
return {iter->second, i};
}
// 如果没找到匹配对,就把访问过的元素和下标加入到map中
map.insert(pair<int, int>(nums[i], i));
}
return {};
}
};
454.四数相加 II

与字母异位词的解题思路是一样的 只不过这题一次遍历两个数组
本题解题步骤:
- 首先定义 一个unordered_map,key放a和b两数之和,value 放a和b两数之和出现的次数。
- 遍历大A和大B数组,统计两个数组元素之和,和出现的次数,放到map中。
- 定义int变量count,用来统计 a+b+c+d = 0 出现的次数。
- 在遍历大C和大D数组,找到如果 0-(c+d) 在map中出现过的话,就用count把map中key对应的value也就是出现次数统计出来。
- 最后返回统计值 count 就可以了
class Solution {
public:
int fourSumCount(vector<int>& A, vector<int>& B, vector<int>& C, vector<int>& D) {
unordered_map<int, int> umap; //key:a+b的数值,value:a+b数值出现的次数
// 遍历大A和大B数组,统计两个数组元素之和,和出现的次数,放到map中
for (int a : A) {
for (int b : B) {
umap[a + b]++;
}
}
int count = 0; // 统计a+b+c+d = 0 出现的次数
// 在遍历大C和大D数组,找到如果 0-(c+d) 在map中出现过的话,就把map中key对应的value也就是出现次数统计出来。
for (int c : C) {
for (int d : D) {
if (umap.find(0 - (c + d)) != umap.end()) {
count += umap[0 - (c + d)];
}
}
}
return count;
}
};
383.赎金信

- 需要快速判断ransom中的字符是否在magazine中出现,所以想到用哈希表。
- 考虑到字符串只包含26个小写字母,所以用数组是最优解,map更耗费空间时间。
- 用个整形数组来保存magazine每个字母的出现次数
- 遍历ransom,如果检测到magazine没有当前字母,直接返回false
- 返回true
class Solution {
public:
bool canConstruct(string ransomNote, string magazine) {
int record[26] = {0};
//add
if (ransomNote.size() > magazine.size()) {
return false;
}
for (int i = 0; i < magazine.length(); i++) {
// 通过record数据记录 magazine里各个字符出现次数
record[magazine[i]-'a'] ++;
}
for (int j = 0; j < ransomNote.length(); j++) {
// 遍历ransomNote,在record里对应的字符个数做--操作
record[ransomNote[j]-'a']--;
// 如果小于零说明ransomNote里出现的字符,magazine没有
if(record[ransomNote[j]-'a'] < 0) {
return false;
}
}
return true;
}
};
- 时间复杂度: O(n)
- 空间复杂度: O(1)
15.三数之和


- 这道题难在去重的处理
- 如果用哈希表的话并不合适 去重细节太多
- 可以采用先排序再双指针的做法,因为这道题不用返回下标,无需保留原始顺序
动画效果如下:
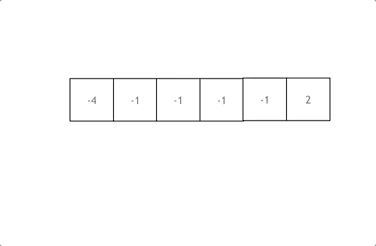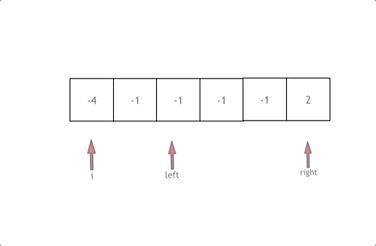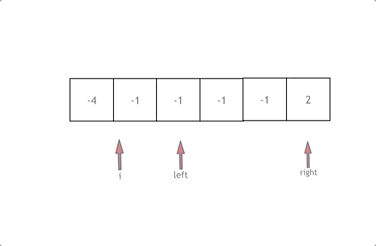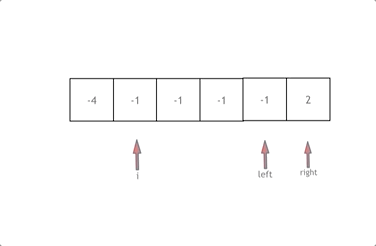
- 首先将数组排序,然后有一层for循环,i从下标0的地方开始,同时定一个下标left 定义在i+1的位置上,定义下标right 在数组结尾的位置上。
- 依然还是在数组中找到 abc 使得a + b + c =0,我们这里相当于 a = nums[i],b = nums[left],c = nums[right]。
- 接下来如何移动left 和right呢, 如果nums[i] + nums[left] + nums[right] > 0 就说明 此时三数之和大了,因为数组是排序后了,所以right下标就应该向左移动,这样才能让三数之和小一些。
- 如果 nums[i] + nums[left] + nums[right] < 0 说明 此时 三数之和小了,left 就向右移动,才能让三数之和大一些,直到left与right相遇为止。
- 时间复杂度:O(n^2)。
class Solution {
public:
vector<vector<int>> threeSum(vector<int>& nums) {
vector<vector<int>> result;
sort(nums.begin(), nums.end());
// 找出a + b + c = 0
// a = nums[i], b = nums[left], c = nums[right]
for (int i = 0; i < nums.size(); i++) {
// 排序之后如果第一个元素已经大于零,那么无论如何组合都不可能凑成三元组,直接返回结果就可以了
if (nums[i] > 0) {
return result;
}
// 错误去重a方法,将会漏掉-1,-1,2 这种情况
/*
if (nums[i] == nums[i + 1]) {
continue;
}
*/
// 正确去重a方法
if (i > 0 && nums[i] == nums[i - 1]) {
continue;
}
int left = i + 1;
int right = nums.size() - 1;
while (right > left) {
// 去重复逻辑如果放在这里,0,0,0 的情况,可能直接导致 right<=left 了,从而漏掉了 0,0,0 这种三元组
/*
while (right > left && nums[right] == nums[right - 1]) right--;
while (right > left && nums[left] == nums[left + 1]) left++;
*/
if (nums[i] + nums[left] + nums[right] > 0) right--;
else if (nums[i] + nums[left] + nums[right] < 0) left++;
else {
result.push_back(vector<int>{nums[i], nums[left], nums[right]});
// 去重逻辑应该放在找到一个三元组之后,对b 和 c去重
while (right > left && nums[right] == nums[right - 1]) right--;
while (right > left && nums[left] == nums[left + 1]) left++;
// 找到答案时,双指针同时收缩
right--;
left++;
}
}
}
return result;
}
};
18.四数之和

- 难点在于去重和剪枝,一级剪枝一级去重二级剪枝二级去重
- 四数之和的双指针解法是两层for循环nums[k] + nums[i]为确定值,依然是循环内有left和right下标作为双指针,找出nums[k] + nums[i] + nums[left] + nums[right] == target的情况,三数之和的时间复杂度是O(n2),四数之和的时间复杂度是O(n3) 。
class Solution {
public:
vector<vector<int>> fourSum(vector<int>& nums, int target) {
vector<vector<int>> result;
sort(nums.begin(), nums.end());
for (int k = 0; k < nums.size(); k++) {
// 剪枝处理
if (nums[k] > target && nums[k] >= 0) {
break; // 这里使用break,统一通过最后的return返回
}
// 对nums[k]去重
if (k > 0 && nums[k] == nums[k - 1]) {
continue;
}
for (int i = k + 1; i < nums.size(); i++) {
// 2级剪枝处理
if (nums[k] + nums[i] > target && nums[k] + nums[i] >= 0) {
break;
}
// 对nums[i]去重
if (i > k + 1 && nums[i] == nums[i - 1]) {
continue;
}
int left = i + 1;
int right = nums.size() - 1;
while (right > left) {
// nums[k] + nums[i] + nums[left] + nums[right] > target 会溢出
if ((long) nums[k] + nums[i] + nums[left] + nums[right] > target) {
right--;
// nums[k] + nums[i] + nums[left] + nums[right] < target 会溢出
} else if ((long) nums[k] + nums[i] + nums[left] + nums[right] < target) {
left++;
} else {
result.push_back(vector<int>{nums[k], nums[i], nums[left], nums[right]});
// 对nums[left]和nums[right]去重
while (right > left && nums[right] == nums[right - 1]) right--;
while (right > left && nums[left] == nums[left + 1]) left++;
// 找到答案时,双指针同时收缩
right--;
left++;
}
}
}
}
return result;
}
};

















 481
481

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









