






1、配置环境
opencv 4.1.1、python3.6.9、nuimpy1.16.1、
扩大内存 ,tx2中修改mem是一样的
1、下载
git clone https://github.com/JetsonHacksNano/installSwapfile
2、安装
./installSwapfile/installSwapfile.sh3、重启

2、下载人脸识别包dlib 和 face-recognition
无法安装人脸检测dlib库的解决方法_dlib安装失败-优快云博客
验证是否安装成功
python3
import dlib
dlib.DLIB_USE_CUDA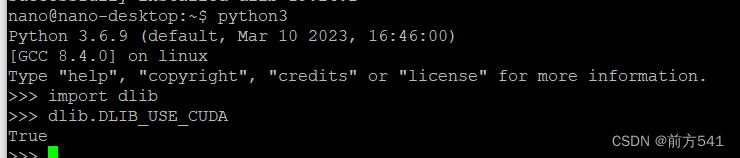
3、训练与测试
训练数据链接:https://pan.baidu.com/s/1Dr--LZN3-SD7e8LdfJTBpw?pwd=q2t1
提取码:q2t1
训练+单张测试
import face_recognition
import cv2
import os
Encodings=[]
Names=[]
image_dir = '/home/nano/faceRecognizer/known'
#遍历文件夹里面文件,进行训练并存储对应的编码数据
for root, dirs, files in os.walk(image_dir):
print(files)#得到文件夹里所有图片并生成一个数组
for file in files:#遍历数组
path = os.path.join(root, file)#得到训练图片的根目录
print(path)
name = os.path.splitext(file)[0]
print(name)
person = face_recognition.load_image_file(path)
encoding = face_recognition.face_encodings(person)[0]
Encodings.append(encoding)
Names.append(name)
print(Names)
#定义测试图片及输出文字字体
font = cv2.FONT_HERSHEY_SIMPLEX
testImage=face_recognition.load_image_file('/home/nano/faceRecognizer/unknown/u12.jpg')
#找到目标位置
facePositions=face_recognition.face_locations(testImage)
#将测试的所有图片进行编码
allEncodings=face_recognition.face_encodings(testImage,facePositions)
#将测试的的rgb图像转成bgr
testImage=cv2.cvtColor(testImage,cv2.COLOR_RGB2BGR)
#匹配数据库是不是有测试图片相同的编码
for (top,right,bottom,left),face_encoding in zip(facePositions,allEncodings):
name='Unknown Person'
matches=face_recognition.compare_faces(Encodings,face_encoding)
if True in matches:
first_match_index=matches.index(True)#找到匹配的索引
name=Names[first_match_index]#用找到的索引传给name列表,找到人名
cv2.rectangle(testImage,(left,top),(right,bottom),(0,0,255),2)
cv2.putText(testImage,name,(left,top-6),font,.75,(0,255,255),2)
cv2.imshow('mywindow',testImage)
if cv2.waitKey(0)==ord('q'):
cv2.destroyAllWindows()
训练+检测文件夹所有目标
import face_recognition
import cv2
import os
Encodings=[]
Names=[]
image_dir = '/home/nano/faceRecognizer/known'
#遍历文件夹里面文件,进行训练并存储对应的编码数据
for root, dirs, files in os.walk(image_dir):
print(files)#得到文件夹里所有图片并生成一个数组
for file in files:#遍历数组
path = os.path.join(root, file)#得到训练图片的根目录
print(path)
name = os.path.splitext(file)[0]
print(name)
person = face_recognition.load_image_file(path)
encoding = face_recognition.face_encodings(person)[0]
Encodings.append(encoding)
Names.append(name)
print(Names)
#定义测试图片及输出文字字体
font = cv2.FONT_HERSHEY_SIMPLEX
for root,dirs,files in os.walk(image_dir):
for file in files:
print(root)
print(file)
testImagePath=os.path.join(root,file)
testImage=face_recognition.load_image_file(testImagePath)
#testImage=face_recognition.load_image_file('/home/nano/faceRecognizer/unknown/u12.jpg')
#找到目标位置
facePositions=face_recognition.face_locations(testImage)
#将测试的所有图片进行编码
allEncodings=face_recognition.face_encodings(testImage,facePositions)
#将测试的的rgb图像转成bgr
testImage=cv2.cvtColor(testImage,cv2.COLOR_RGB2BGR)
#匹配数据库是不是有测试图片相同的编码
for (top,right,bottom,left),face_encoding in zip(facePositions,allEncodings):
name='Unknown Person'
matches=face_recognition.compare_faces(Encodings,face_encoding)
if True in matches:
first_match_index=matches.index(True)#找到匹配的索引
name=Names[first_match_index]#用找到的索引传给name列表,找到人名
cv2.rectangle(testImage,(left,top),(right,bottom),(0,0,255),2)
cv2.putText(testImage,name,(left,top-6),font,.75,(0,255,255),2)
cv2.imshow('mywindow',testImage)
if cv2.waitKey(0)==ord('q'):
cv2.destroyAllWindows()
4、用pickle存储训练好的人脸模型
4.1、train-save.py 训练+保存
import face_recognition
import cv2
import os
import pickle
Encodings=[]
Names=[]
image_dir = '/home/nano/faceRecognizer/known'
#遍历文件夹里面文件,进行训练并存储对应的编码数据
for root, dirs, files in os.walk(image_dir):
print(files)#得到文件夹里所有图片并生成一个数组
for file in files:#遍历数组
path = os.path.join(root, file)#得到训练图片的根目录
print(path)
name = os.path.splitext(file)[0]
print(name)
person = face_recognition.load_image_file(path)
encoding = face_recognition.face_encodings(person)[0]
Encodings.append(encoding)
Names.append(name)
print(Names)
#使用pickle存储训练好的识别模型
with open('train.pkl','wb') as f:
pickle.dump(Names,f)
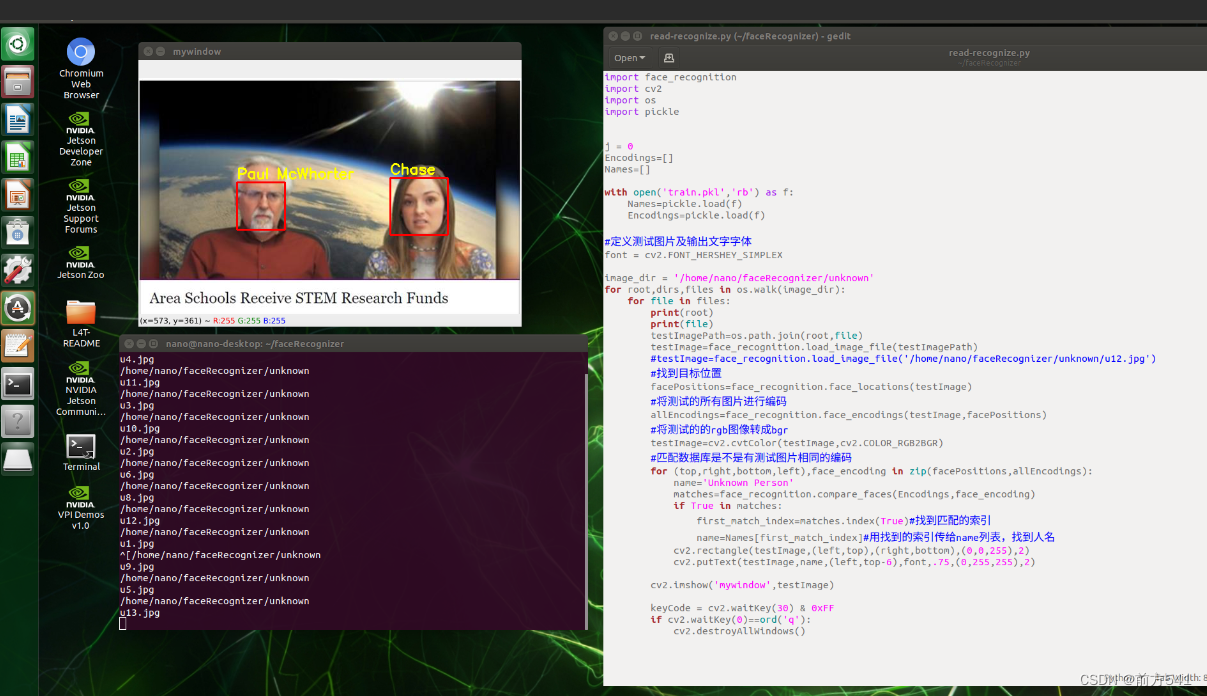
pickle.dump(Encodings,f)4.2、read-recognize.py调用保存的pickle模型进行人脸识别
import face_recognition
import cv2
import os
import pickle
Encodings=[]
Names=[]
with open('train.pkl','rb') as f:
Names=pickle.load(f)
Encodings=pickle.load(f)
#定义测试图片及输出文字字体
font = cv2.FONT_HERSHEY_SIMPLEX
image_dir = '/home/nano/faceRecognizer/unknown'
for root,dirs,files in os.walk(image_dir):
for file in files:
print(root)
print(file)
testImagePath=os.path.join(root,file)
testImage=face_recognition.load_image_file(testImagePath)
#testImage=face_recognition.load_image_file('/home/nano/faceRecognizer/unknown/u12.jpg')
#找到目标位置
facePositions=face_recognition.face_locations(testImage)
#将测试的所有图片进行编码
allEncodings=face_recognition.face_encodings(testImage,facePositions)
#将测试的的rgb图像转成bgr
testImage=cv2.cvtColor(testImage,cv2.COLOR_RGB2BGR)
#匹配数据库是不是有测试图片相同的编码
for (top,right,bottom,left),face_encoding in zip(facePositions,allEncodings):
name='Unknown Person'
matches=face_recognition.compare_faces(Encodings,face_encoding)
if True in matches:
first_match_index=matches.index(True)#找到匹配的索引
name=Names[first_match_index]#用找到的索引传给name列表,找到人名
cv2.rectangle(testImage,(left,top),(right,bottom),(0,0,255),2)
cv2.putText(testImage,name,(left,top-6),font,.75,(0,255,255),2)
cv2.imshow('mywindow',testImage)
if cv2.waitKey(0)==ord('q'):
cv2.destroyAllWindows()
结果
5、调用摄像头人脸识别
帧率8~9,不过识别挺准的
import face_recognition
import cv2
import os
import pickle
import time
fpsReport=0
scaleFactor=.2#图像缩小比例,越小检测速度越快
Encodings=[]
Names=[]
with open('train.pkl','rb') as f:
Names=pickle.load(f)
Encodings=pickle.load(f)
#定义测试图片及输出文字字体
font = cv2.FONT_HERSHEY_SIMPLEX
cam = cv2.VideoCapture(0)
timeStamp=time.time()
while True:
_,frame = cam.read()
#图片缩小scalefactor,加快检测速度
frameSmall = cv2.resize(frame, (0, 0), fx=scaleFactor, fy=scaleFactor)
frameRGB = cv2.cvtColor(frameSmall, cv2.COLOR_BGR2RGB)
facePositions = face_recognition.face_locations(frameRGB, model='cnn')
allEncodings = face_recognition.face_encodings(frameRGB, facePositions)
for (top, right, bottom, left), face_encoding in zip(facePositions, allEncodings):
name = 'Unkown Person'
matches = face_recognition.compare_faces(Encodings, face_encoding)
if True in matches:
first_match_index = matches.index(True)
name = Names[first_match_index]
#将检测框放大scalefactor倍,上面图片是缩小三倍检测的结果,检测框也是缩小三倍的
top = int(top / scaleFactor)
right = int(right / scaleFactor)
bottom = int(bottom / scaleFactor)
left = int(left / scaleFactor)
cv2.rectangle(frame,(left,top),(right,bottom),(0, 0, 255), 2)
cv2.putText(frame, name, (left, top - 6), font, .75, (0, 0, 255), 2)
#计算帧率并显示在右上角
dt = time.time() - timeStamp
fps = 1 / dt
fps = round(fps,2)
#低通滤波,避免fps反复刷新消除噪音
fpsReport = .90 * fpsReport + .1 * fps
# print('fps is:',round(fpsReport,1))
timeStamp = time.time()
cv2.rectangle(frame, (0, 0), (100, 40), (0, 0, 255), -1)
cv2.putText(frame, str(round(fpsReport, 1)) + 'fps', (0, 25), font, .75, (0, 255, 255, 2))
cv2.imshow("cam",frame)
if cv2.waitKey(1)==ord('q'):
break
cam.release()
cv2.destroyAllWindows()

















 468
468

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









